


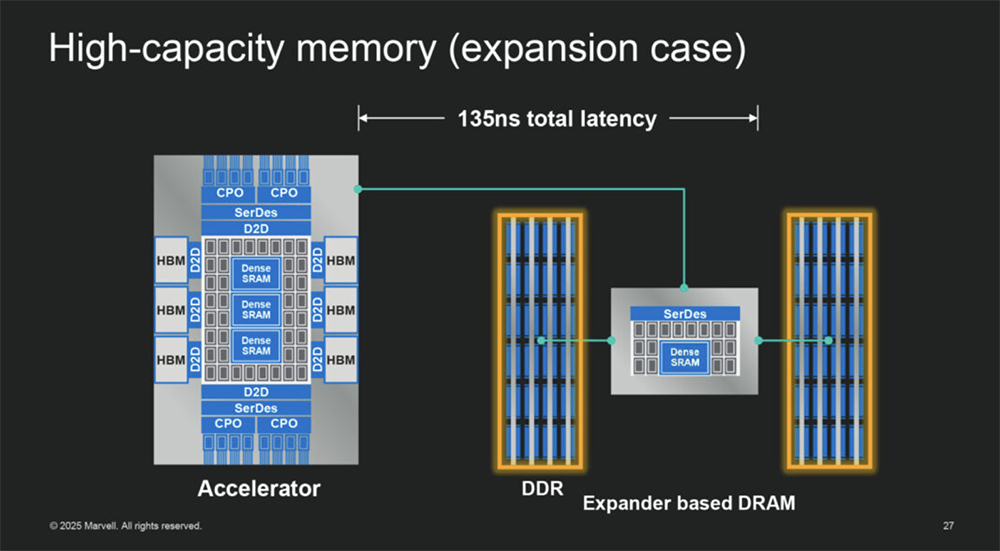

















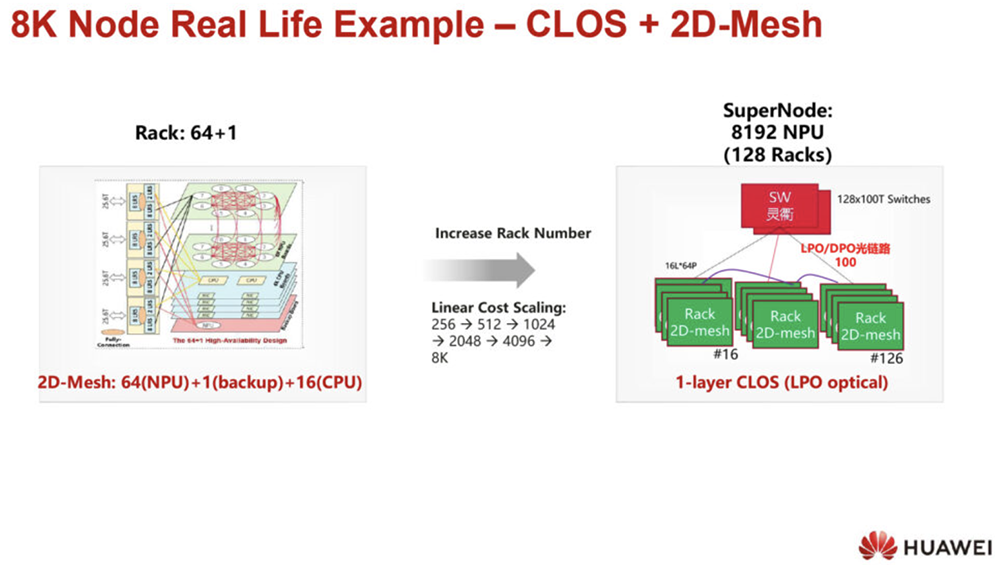
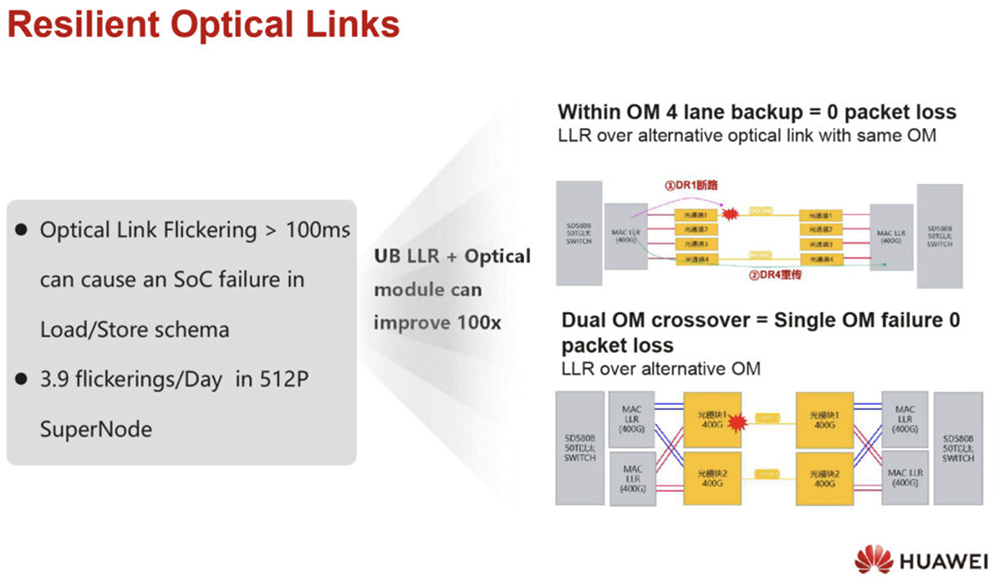
CLOS=多功能+可靠,适用于低带宽的顶级网络(1M)
nD mesh =高本地带宽+减少的远程带宽,适用于机架(~64)大Pod (128~8192)
nD sparse mesh=低成本+高带宽(16~128),适合更小的本地部署
























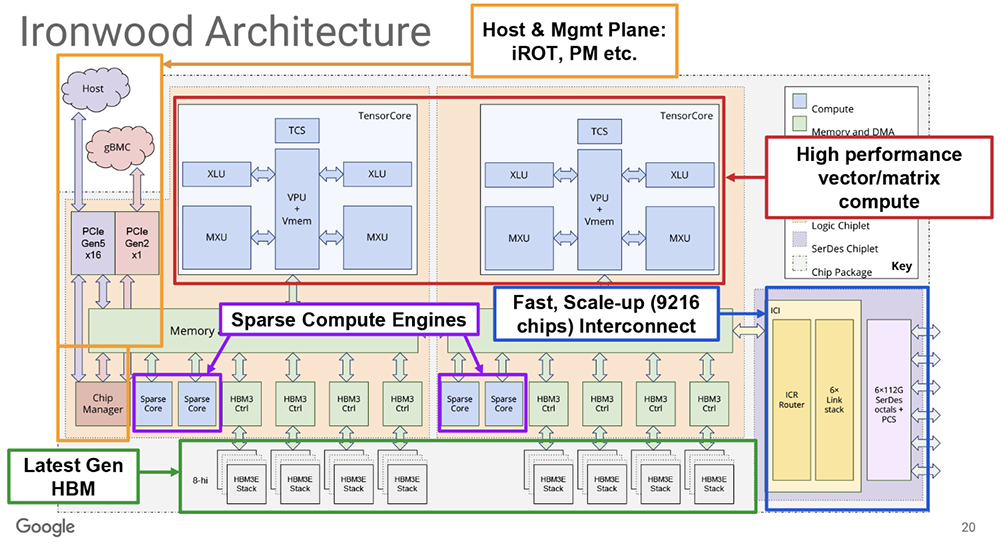
单SuperPod节点最多可容纳9216颗芯片,使用OCS(光电路交换机)共享内存 可直接寻址的共享HBM内存容量为1.77PB FP8精度下,单SuperPod性能可扩展至42.5EFLOPS 强调RAS(可靠性、可用性、可服务性) 每瓦性能是上一代谷歌TPU Trillium的2倍 第三代液冷基础设施 用于嵌入和集体卸载的第四代SparseCore 超大规模部署正在进行中























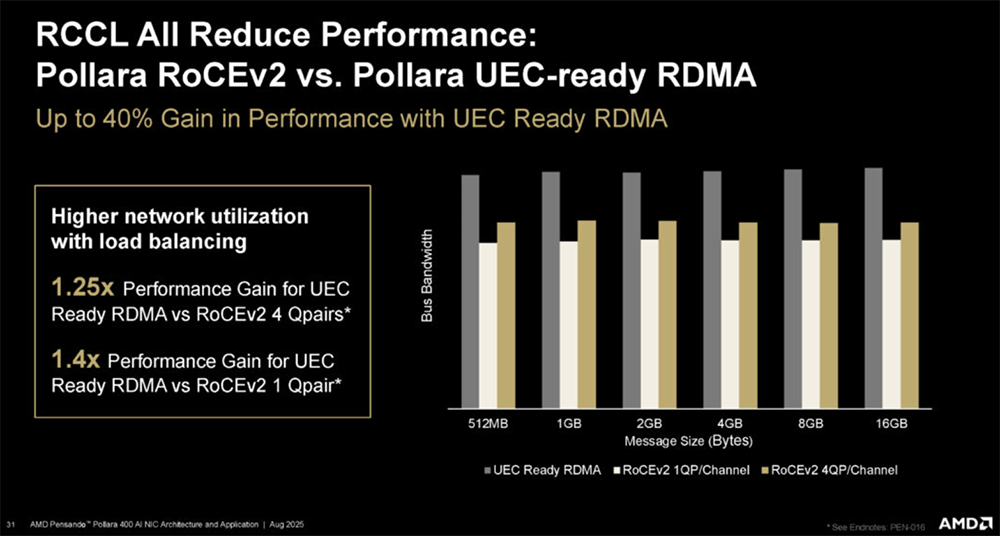







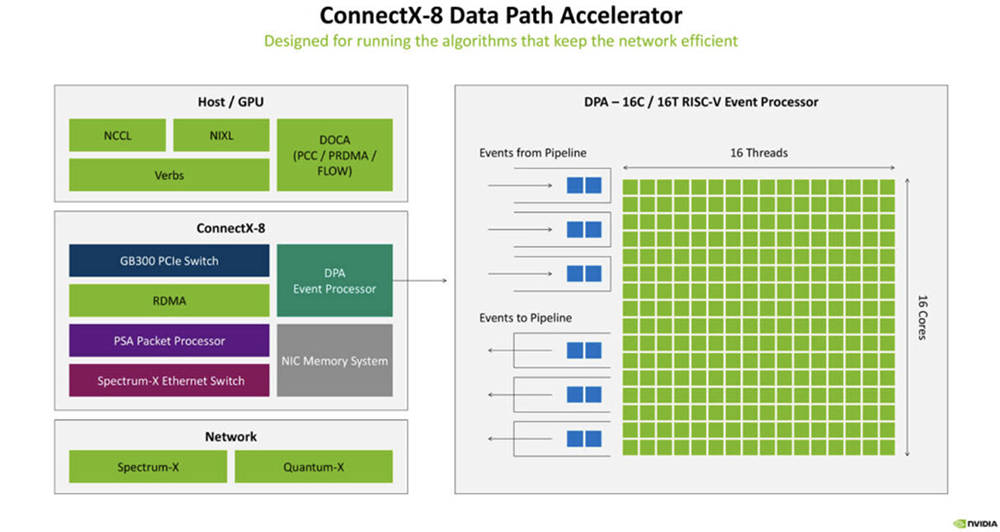



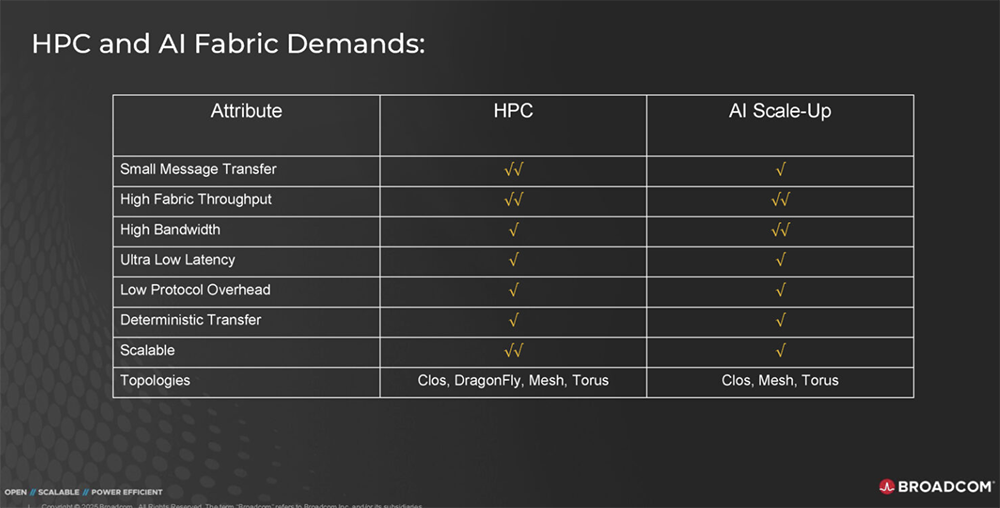






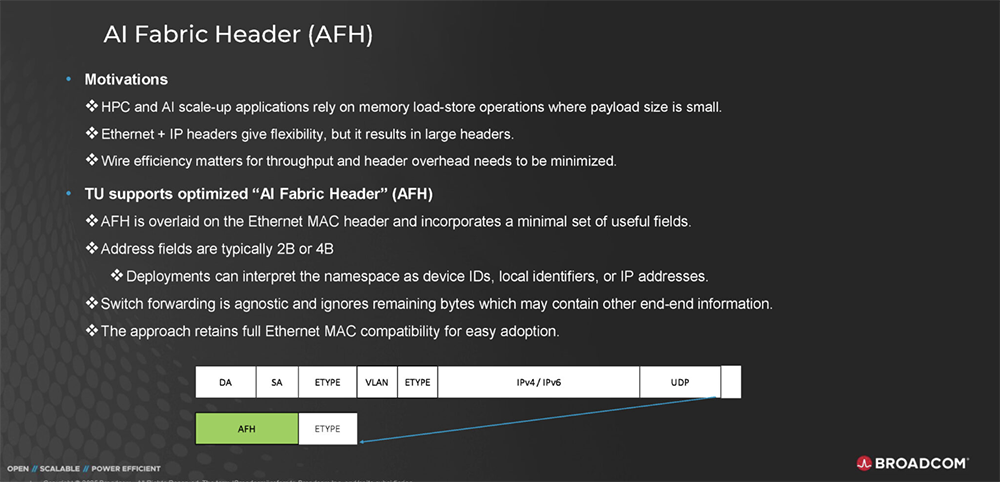

















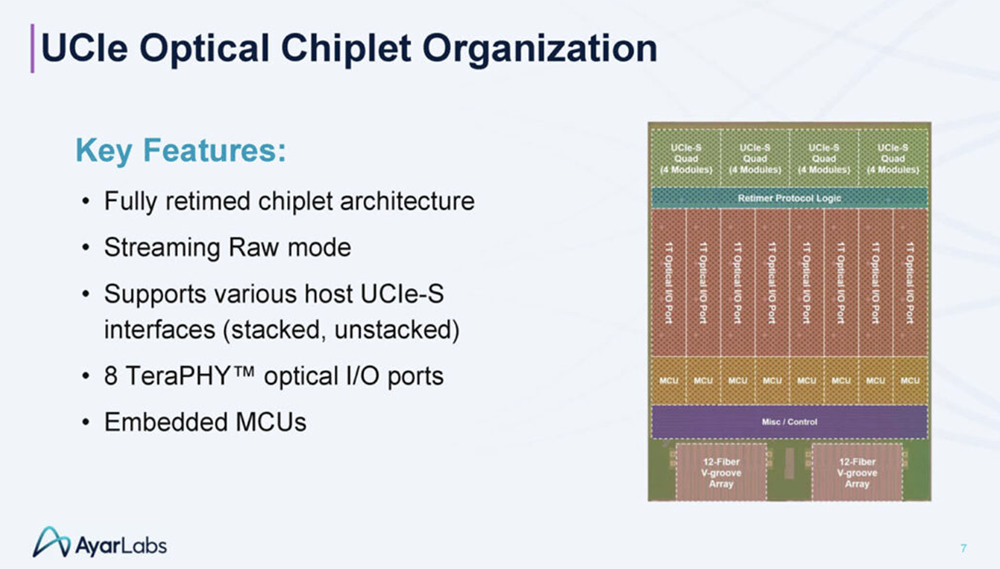
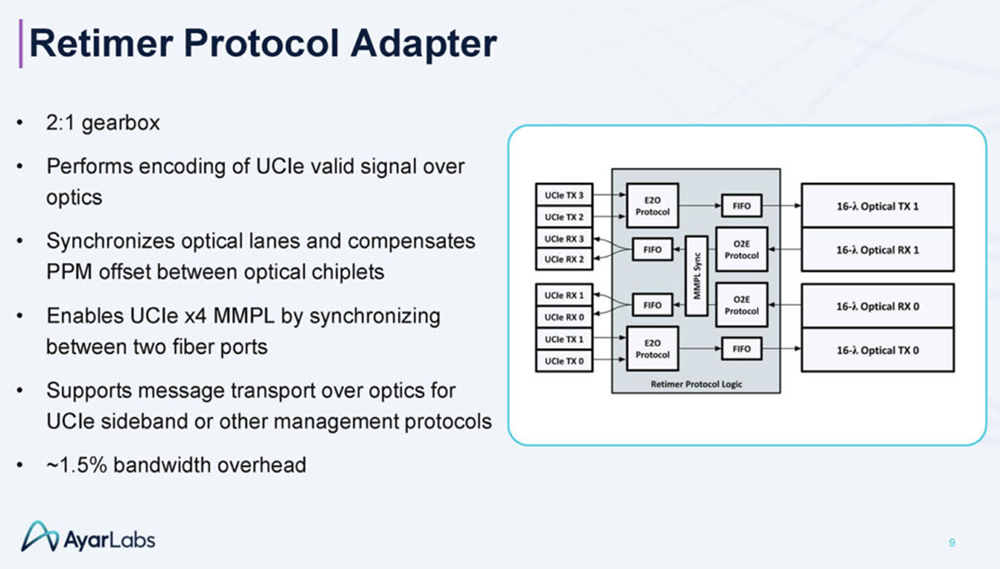


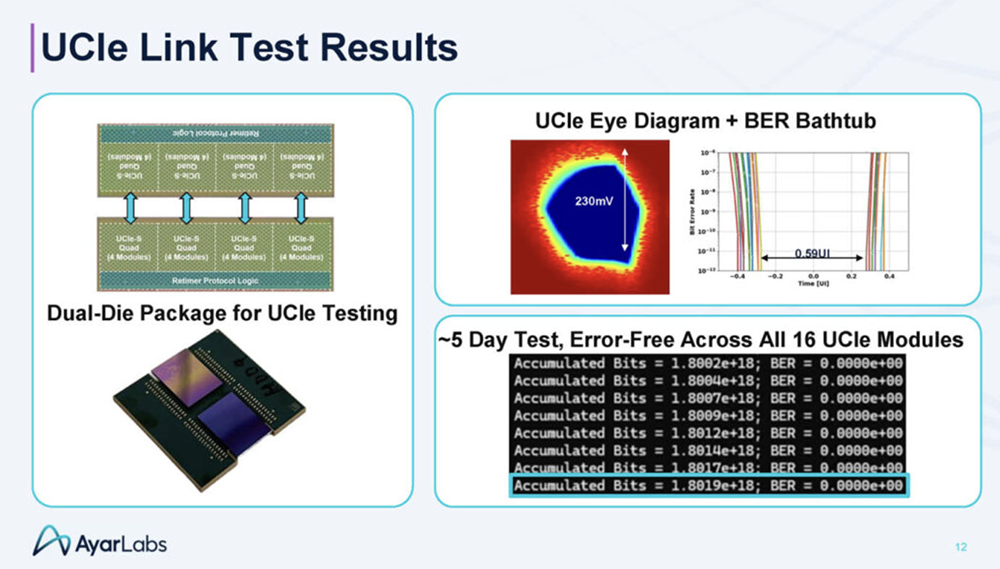
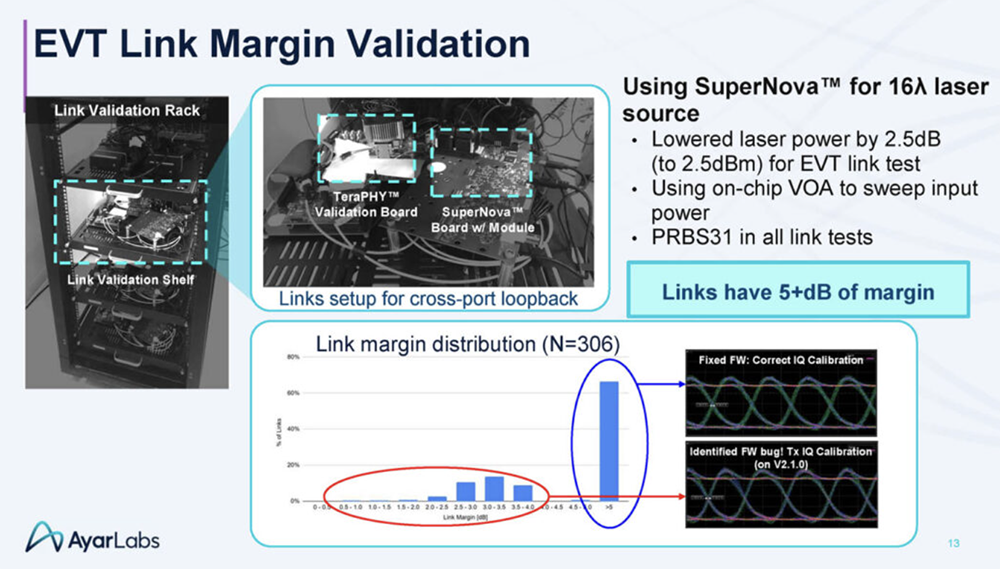


































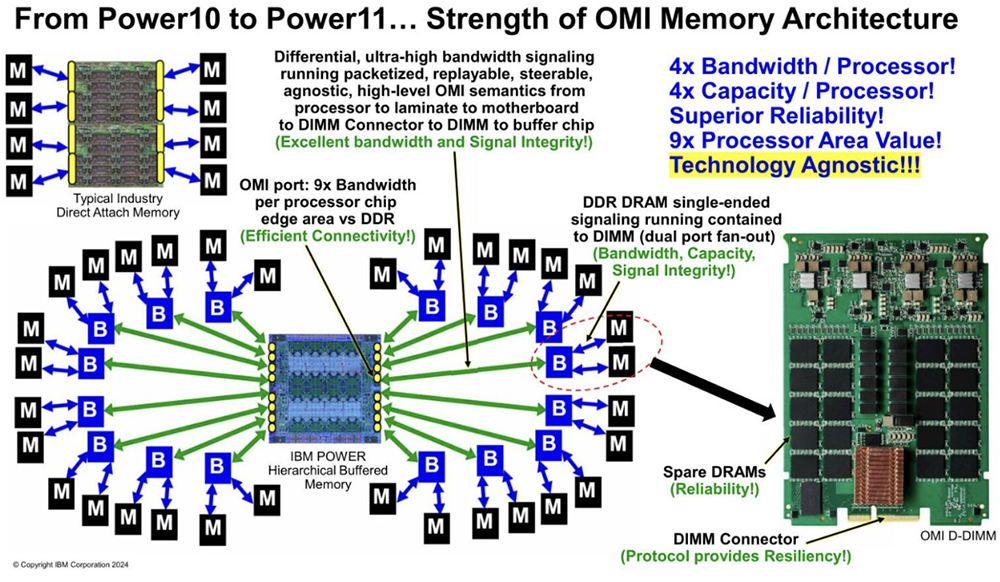





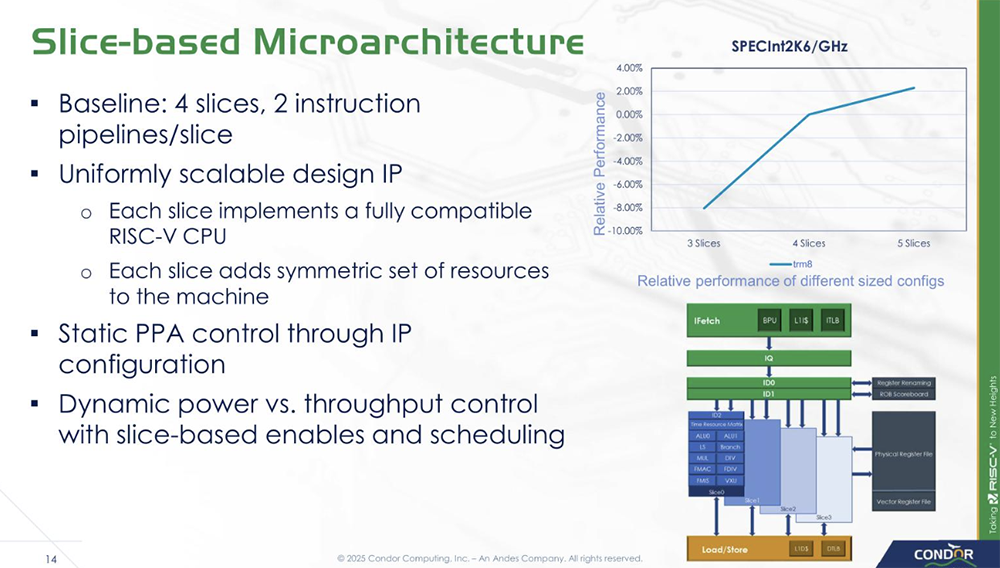








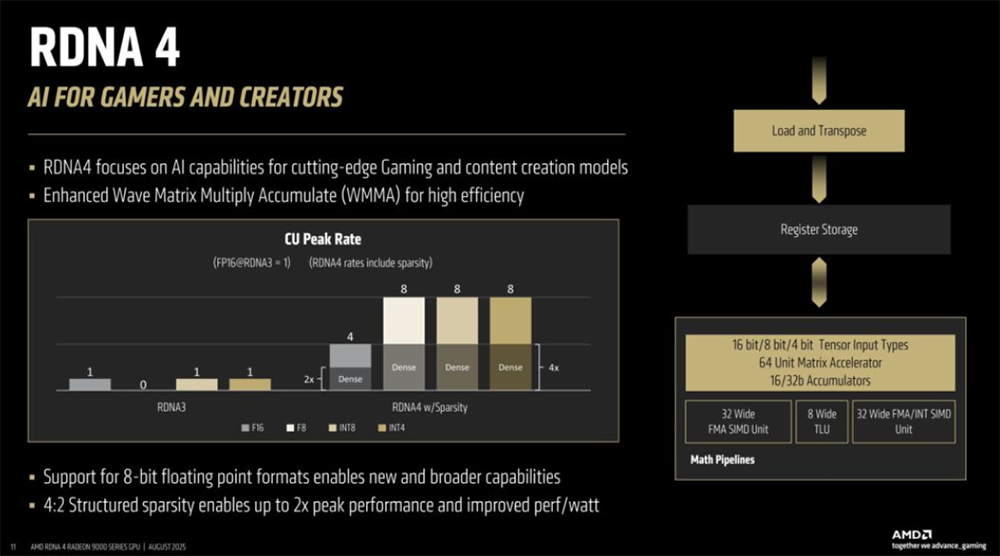
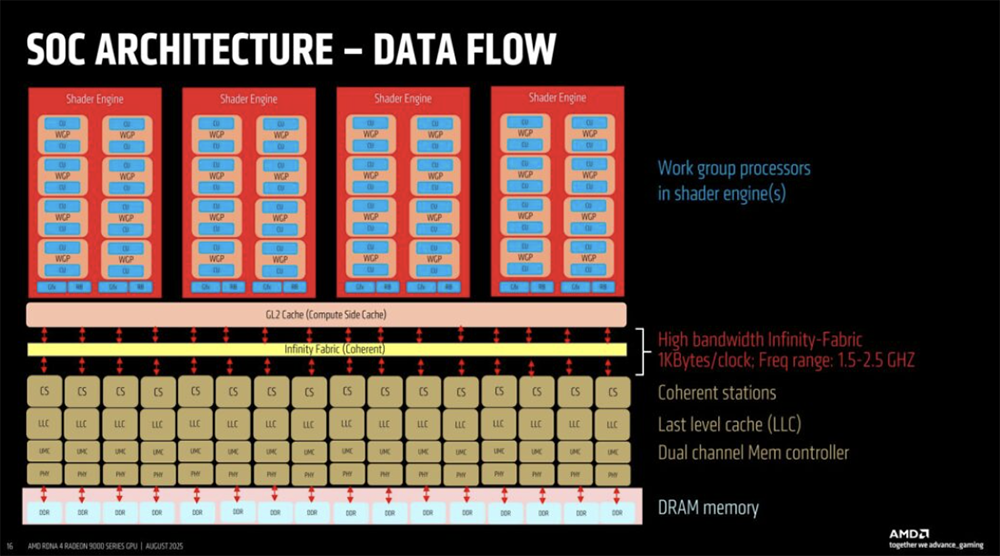




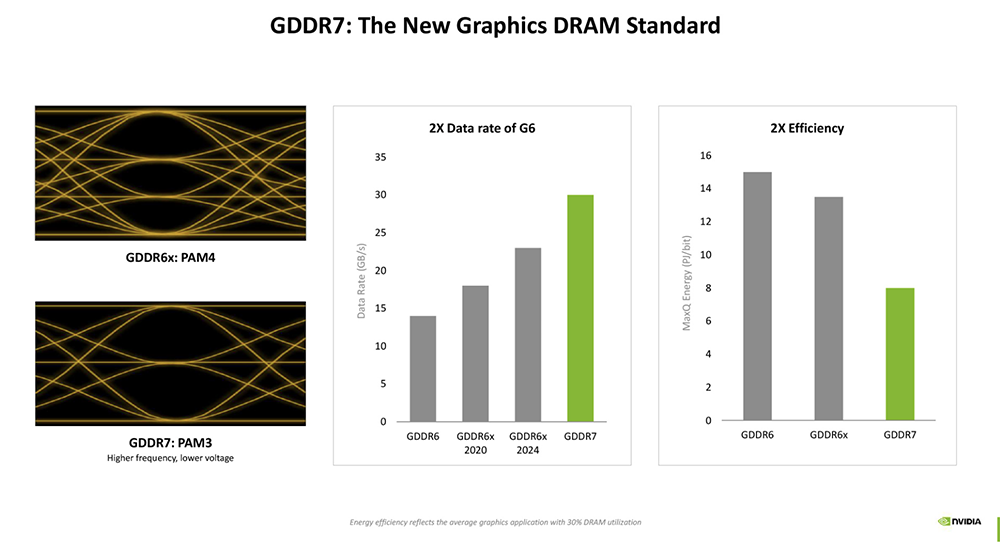

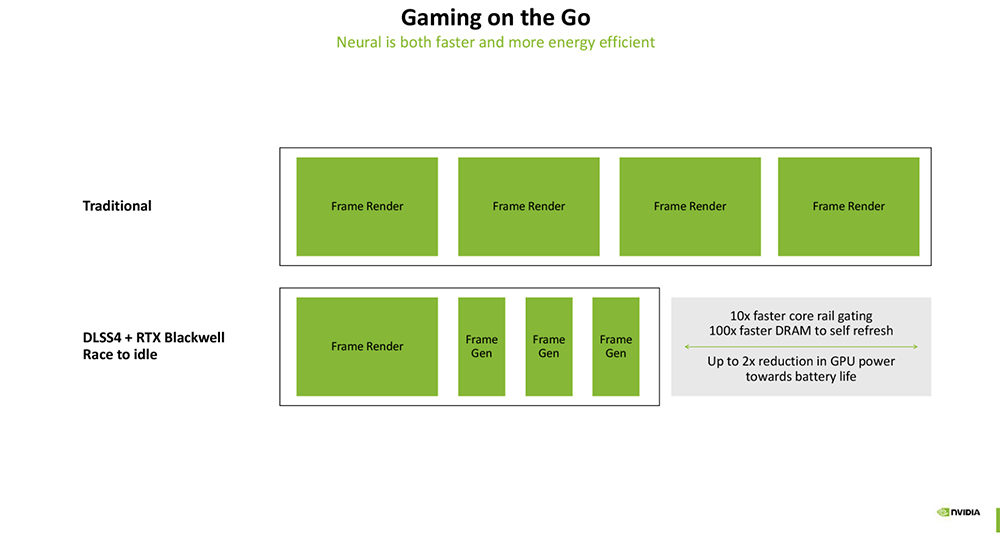





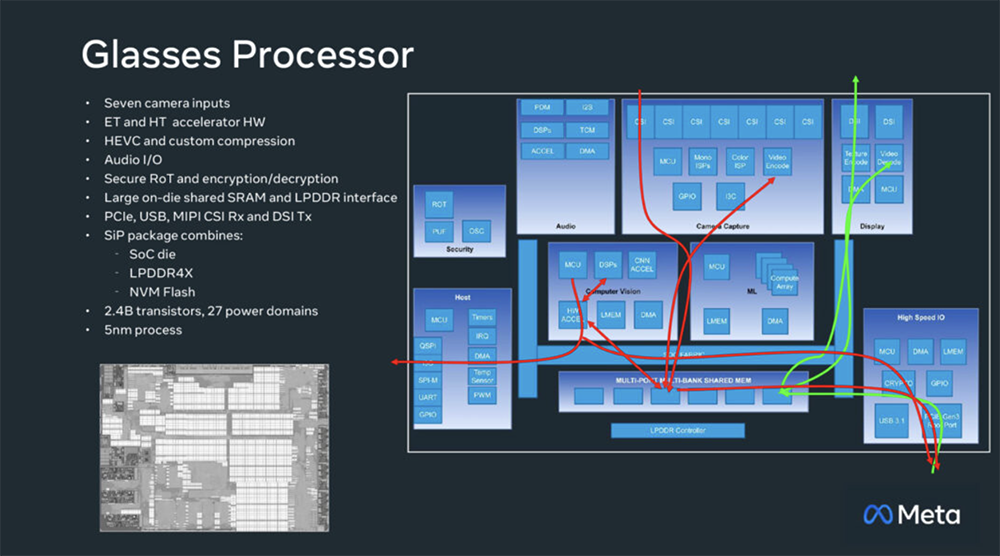





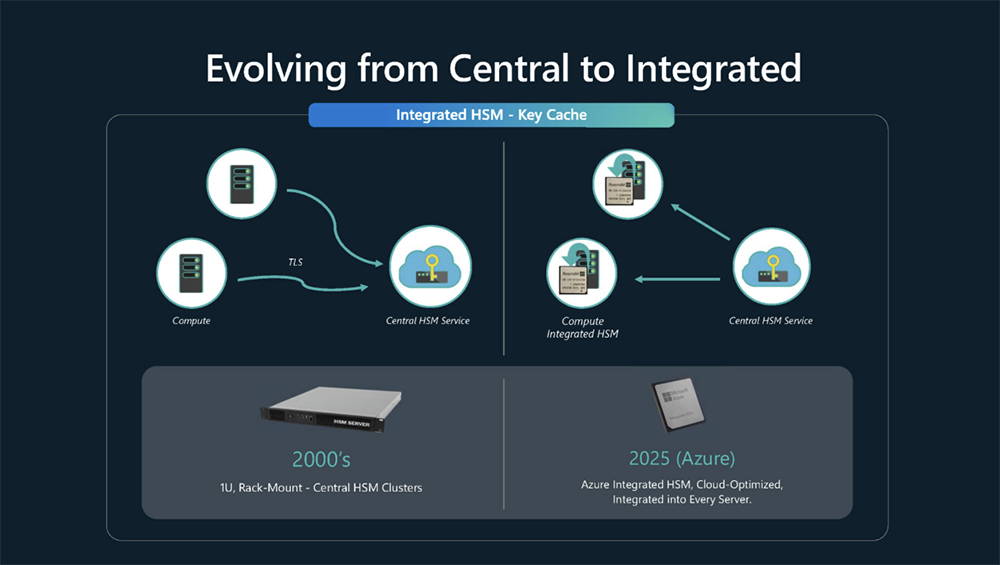




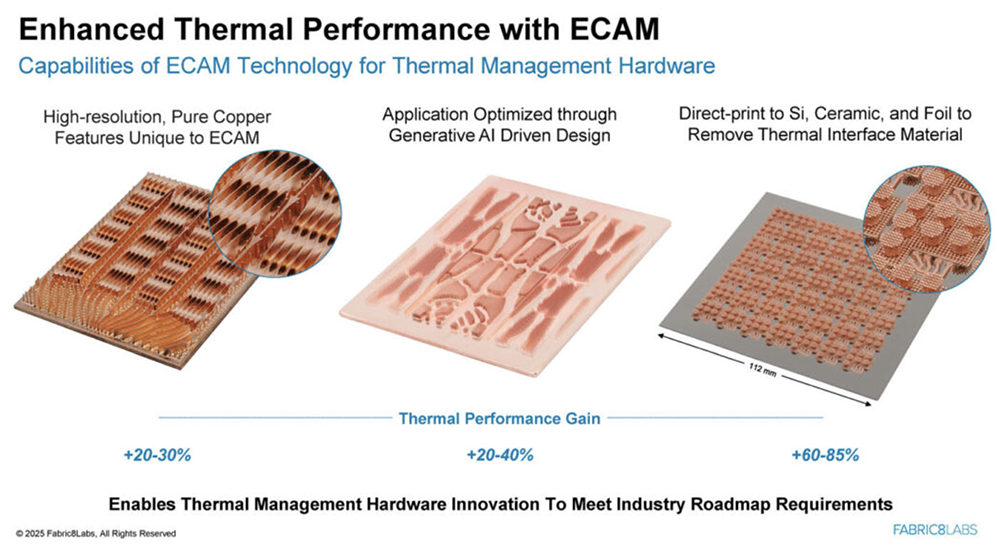



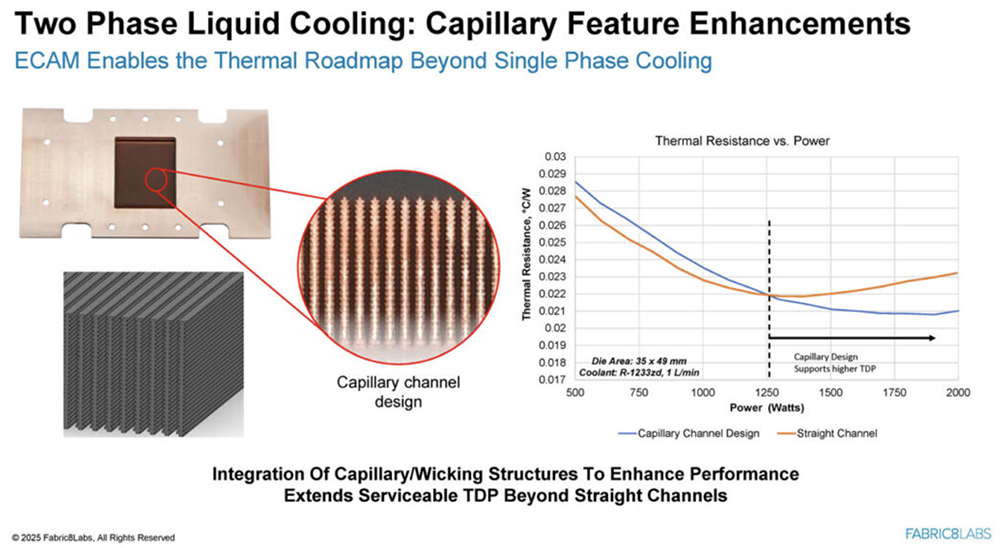

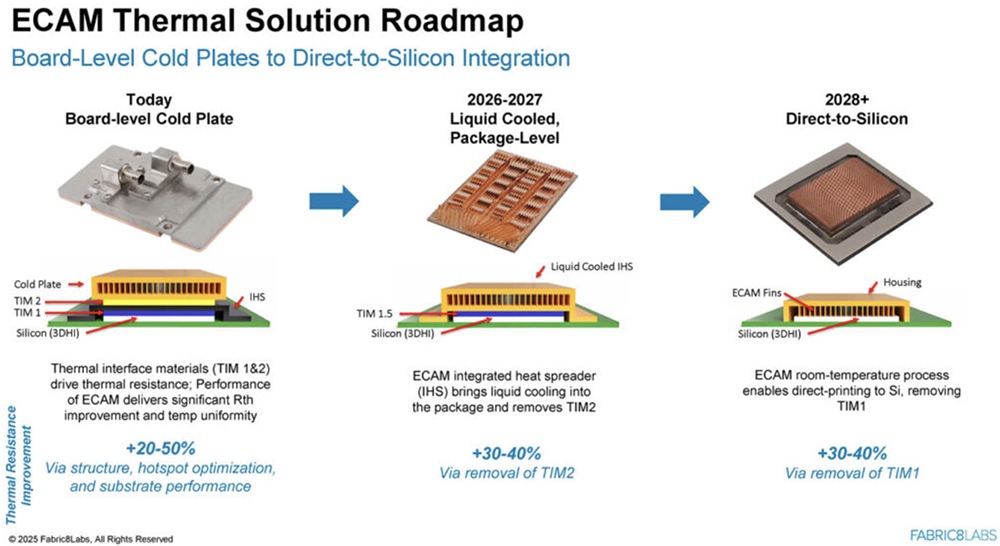

2025全球AI芯片峰会预告












