如您有工作需要分享,欢迎联系:aigc_to_future
作者:En Ci等

文章链接:https://arxiv.org/abs/2508.20505
项目链接:https://twinkle-ce.github.io/DescriptiveEdit/
亮点直击:
基于描述的图像编辑新范式:与现有方法依赖指令(instruction)表达编辑意图不同,本文提出描述(description)直接引导的语义编辑框架DescriptiveEdit。 参考图控制策略:DescriptiveEdit在去噪过程中实现参考图控制,并通过零初始化的线性层学习自适应权重,有效缓解了图像编辑中精准编辑与结构保真的冲突。 兼容良好且编辑性能卓越:DescriptiveEdit不仅可以同时支持全局与局部编辑,还可以直接兼容在基础文生图模型上训练的ControlNet、IP-Adapter、LoRA等生态扩展。

总结速览
解决的问题
本文主要想解决基于指令的图像编辑范式的以下三个问题:
指令编辑数据瓶颈:基于指令的方法需要(参考图,编辑指令,目标图)三元组数据,但现有数据集在规模与多样性上远不及T2I训练数据,限制了模型的泛化能力。 架构兼容难:现有基于训练的方法通常需修改扩散模型主干结构,不仅带来高昂的微调成本,还影响与社区扩展模型(如ControlNet,LoRA)的兼容性。 编辑灵活性与结构保真的权衡困境:现有方法难以同时兼顾指令遵循度和编辑一致性,经常导致无法遵循编辑指令或者修改非编辑区域的问题。
提出的方案
针对上述问题,本文提出了以下解决方案:
建立描述(description)直接引导的语义图像编辑框架DescriptiveEdit,在保留扩散模型原本生成能力、降低训练开销的同时,避免了构造高质量指令编辑三元组数据(参考图,编辑指令,编辑图)的问题。 引入Attention Bridge在去噪过程中进行参考图控制,并结合零初始化的可学习线性层实现参考图与目标图特征的自适应融合。同时,通过LoRA微调减少了可训练参数量,从而实现高效模型训练。 推理阶段引入双系数可控机制,通过参考图保真度系数和文本描述影响力系数调节编辑幅度。
应用的技术
DescriptiveEdit框架包含两个技术核心:
参考图控制策略:在并行Unet(CrossAttentive Unet和Ref-Unet)之间引入 Attention Bridge进行参考图控制,通过零初始化的线性层逐步学习最优融合系数避免早期冲突, 并结合 LoRA 微调保证训练效率。 可控推理策略:通过调整参考图保真度系数和文本描述影响力系数,可在结构保真与语义修改之间灵活切换。
达到的效果
全局和局部编辑均表现优异,编辑结果在指令遵循度和编辑一致性上取得了最佳平衡。在 Emu Edit test基准测试集上,多个关键指标上领先现有方法。 用户可根据需求在“轻微修改”与“大幅变更”之间自由切换,且在不同编辑场景下均保持稳定表现。 该架构可扩展至DiT架构,并可与 ControlNet、IP-Adapter 等社区扩展模型良好兼容。
方法概述
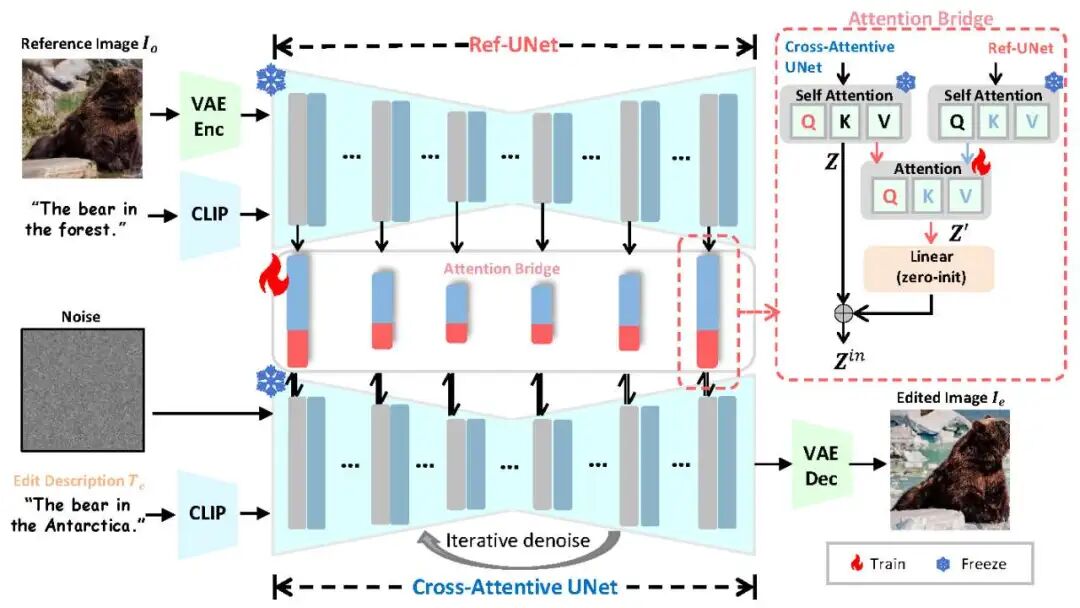
传统指令驱动的语义图像编辑以“参考图 + 编辑指令 → 编辑图像”为核心流程(如“在天空中添加烟花”)。我们将其重构为“两阶段”:指令 → 编辑描述 → 编辑图像,其中编辑描述(如“天空中烟花绽放”)可由用户直接提供,或由视觉语言模型根据参考图与指令自动生成。于是核心挑战就在于:如何设计高效的参考图控制机制?
由于 T2I 模型本身并不支持图像条件,我们需引入参考图控制机制,同时避免对架构和预训练权重的改动。潜空间扩散模型常用两种条件控制方式:(1)交叉注意力(cross attention):轻量高效,仅编码高层语义(如 Stable Diffusion, IP-Adapter)(2)Unet特征提取:低层对齐好,但需通道拼接并大规模微调(如 ControlNet)。我们结合两者优势,设计了并行Unet网络,其中Cross-Attentive UNet负责去噪,Ref-Unet负责提取条件特征。然后,我们在两者的自注意力层中引入Attention Bridge负责高效条件控制,其中 Query 来自 Ref-UNet,Key和Value 来自Cross-Attentive UNet。我们将Attention Bridge输出的参考特征 Z' 与原自注意力输出 Z 融合,从而在不改变主干结构的前提下实现参考图控制。
然而我们发现直接将 Z 与 Z' 相加易导致参考特征过强、削弱生成效果。为此,我们引入零初始化的可学习线性映射:Zout=Z+Linear(Z′) ,初始时 Linear(Z')=0,保留生成先验;训练中逐步学习平衡生成与参考,引导效果可控。
在训练时,我们采取了以下策略:(1)参考 classifier-free guidance,随机置空编辑描述或参考图(概率 5%);(2)仅对编辑图像加噪(参考图不加噪);(3)Attention Bridge 权重初始化自预训练 Self-Attention,并用 LoRA 微调;可学习映射层采用 ControlNet 零初始化策略。推理时,我们引入两个可调系数 与 控制参考图条件与文本条件权重,实现从轻微修改到大幅变更的灵活编辑。
实验
实验设置
训练细节:为了确保公平比较,我们与大多数基于训练的方法保持一致,采用 Stable Diffusion v1.5 作为基础模型。模型使用 AdamW 优化器进行训练,学习率设为1e-5。为了实现参数高效微调,我们对 Attention Bridge 层应用 LoRA ,并将rank设置为 64,α设置为 64。
数据集: DescriptiveEdit在 UltraEdit 数据集上进行训练,该数据集包含约 400 万对文本-图像样本。在评估阶段,我们使用 Emu Edit test 基准测试集。然而我们发现该基准测试集存在不一致性,例如源图像与目标图像可能具有相同的文本描述(如 "a train station in a city")。为保证评估的公平性与合理性,我们在计算指标前对这些样本进行了过滤。
对比方法:我们将DescriptiveEdit与两类具有代表性的基线方法进行比较:(1)Training-free 方法:包括 MasaCtrl、RF-Edit、PnPInversion、FPE和 TurboEdit。(2)Training-based 方法:包括 InstructPix2Pix、MagicBrush、EmuEdit、AnyEdit和BrushEdit。
评估指标: 我们从三个维度评估语义图像编辑模型的性能:(1)指令遵循度:使用 CLIP-T 衡量编辑描述与生成图像的一致性。(2)图像一致性:通过 L1 与 L2 距离衡量参考图与编辑图的差异;采用 CLIP-I与 DINO-I特征相似度评估;使用 SSIM评估结构保真度;采用 LPIPS衡量感知质量。(3)图像质量:使用 PSNR 评估像素级重建精度。
定量比较
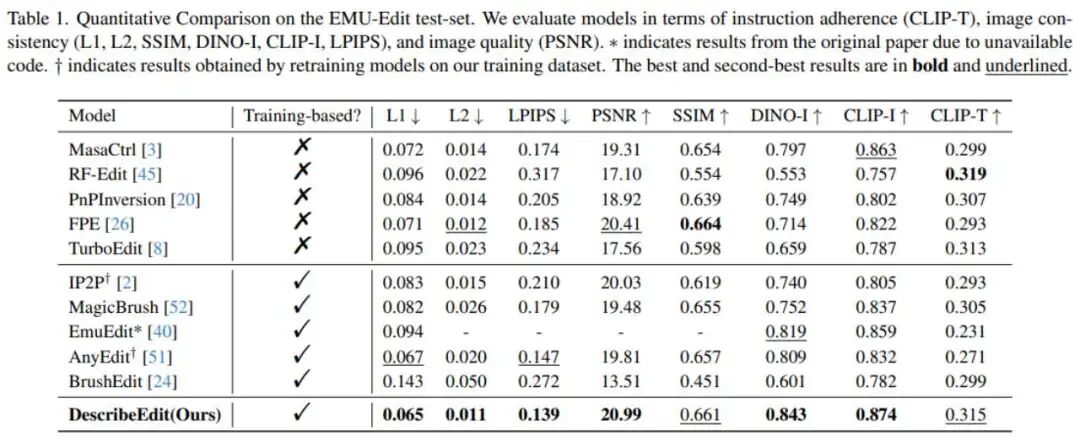
DescriptiveEdit在图像一致性上表现出色,生成结果在结构和语义上都与参考图像高度对齐,确保编辑后的内容与参考图保持合理关联。同时,在指令遵循度方面,生成图像能够精准反映文本描述的意图,无论是局部细节修改还是整体风格调整,都能与指令紧密匹配。整体来看,编辑效果兼顾细节与视觉效果,使得该方法在实际语义图像编辑任务中具有较高的实用价值。
定性比较

图3展示了全局与局部编辑任务的对比结果。与训练型和非训练型基线方法相比,DescriptiveEdit在语义一致性与高保真度上均表现出显著优势。全局编辑中,模型能够自然改变图像风格或替换背景,同时保持关键前景元素完整;局部编辑中,模型能平滑修改目标物体,如替换或添加细节,而整体结构与语义保持连贯,这些都是现有方法难以兼顾的。
消融实验

描述(Description) vs. 指令(Instruction): 为了验证在图像编辑任务中,使用描述引导的编辑是否比指令引导的编辑更有效,我们设计了可控实验:保持其他条件一致,仅将文本输入类型从指令改为描述。图4结果表明,基于描述的方法能更准确传达编辑意图,避免非编辑区域的改变从而提升编辑效果。

对图像编辑的影响:为了分析 对编辑结果的影响,我们通过改变 强度进行消融实验。从图5中,我们可以观察到较小的 强度增强了编辑效果但降低了参考图像相似度,而较大的 保留更多细节但编辑能力减弱。实验结果表明,将 设在 1~2.5 范围内可以在编辑强度与参考保真度之间取得良好平衡,并可根据需求灵活调整。

自适应注意力融合:我们通过与直接替换或直接相加参考特征的策略比较,验证了自适应注意力融合的有效性。表2中的实验结果显示,直接替换会破坏图像保真与结构一致性,直接相加虽有所改善但缺乏平衡控制。DescriptiveEdit通过可学习的线性层动态调节参考特征融合,实现了图像保真与生成能力的最佳平衡,验证了自适应特征融合在高质量图像编辑中的作用。
与社区扩展的兼容性

DescriptiveEdit核心优势之一是与社区扩展方法无缝兼容,可在不修改基础模型或重新训练的情况下灵活集成外部控制信号。通过在 IP-Adapter、ControlNet 和 RealCartoon3D 等三种代表性模型上验证,图6中的结果显示DescriptiveEdit始终能保持结构一致性,同时实现风格转换且无明显伪影,证明了DescriptiveEdit具备即插即用的适应性,提高了模型通用性与实用性。
跨架构鲁棒性

为了验证DescriptiveEdit在不同扩散架构上的鲁棒性,我们将其应用到 Flux中。结果显示,DescriptiveEdit在保持结构完整性的同时,始终能生成高保真编辑结果。这表明DescriptiveEdit在不同扩散模型框架中均具有可靠性能,消除了对特定架构的依赖,进一步强化了其实用价值。
结论
本文提出了一种基于描述(description)的语义图像编辑方法 —— DescriptiveEdit,将语义图像编辑统一到文生图框架中。通过引入 Attention Bridge 实现高效参考图控制,并结合 LoRA 微调保证了训练效率与兼容性。实验结果表明,该方法在指令遵循度与编辑一致性等方面均优于现有方案,建立了一个可扩展、即插即用的语义图像编辑新范式。
参考文献
[1] Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xiaohu Qie, and Yinqiang Zheng. Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing. In ICCV, pages 22560–22570, 2023. 2, 5, 6
[2] Jiangshan Wang, Junfu Pu, Zhongang Qi, Jiayi Guo, Yue Ma, Nisha Huang, Yuxin Chen, Xiu Li, and Ying Shan. Taming rectified flow for inversion and editing. CoRR:2411.04746, 2024. 1, 2, 5, 6
[3] Xuan Ju, Ailing Zeng, Yuxuan Bian, Shaoteng Liu, and Qiang Xu. Pnp inversion: Boosting diffusion-based editing with 3 lines of code. International Conference on Learning Representations (ICLR), 2024. 5, 6
[4] Bingyan Liu, Chengyu Wang, Tingfeng Cao, Kui Jia, and Jun Huang. Towards understanding cross and self-attention in stable diffusion for text-guided image editing, 2024. 5, 6
[5] Gilad Deutch, Rinon Gal, Daniel Garibi, Or Patashnik, and Daniel Cohen-Or. Turboedit: Text-based image editing using few-step diffusion models, 2024. 5, 6
[6] Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. In CVPR, pages 18392–18402, 2023. 2, 4, 5, 6
[7] Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction-guided image editing. NeurIPS, pages 31428–31449, 2023. 2, 5, 6
[8] Shelly Sheynin, Adam Polyak, Uriel Singer, Yuval Kirstain, Amit Zohar, Oron Ashual, Devi Parikh, and Yaniv Taigman. Emu edit: Precise image editing via recognition and generation tasks. In CVPR, pages 8871–8879, 2024. 2, 5, 6
[9] Qifan Yu, Wei Chow, Zhongqi Yue, Kaihang Pan, Yang Wu, Xiaoyang Wan, Juncheng Li, Siliang Tang, Hanwang Zhang, and Yueting Zhuang. Anyedit: Mastering unified high-quality image editing for any idea. CoRR, 2024. 2, 5, 6
[10] Yaowei Li, Yuxuan Bian, Xuan Ju, Zhaoyang Zhang, Ying Shan, Yuexian Zou, and Qiang Xu. Brushedit: All-in-one image inpainting and editing. CoRR, abs/2412.10316, 2024. 5, 6
[11] Describe, Don't Dictate: Semantic Image Editing with Natural Language Intent
致谢
如果您觉得这篇文章对你有帮助或启发,请不吝点赞、在看、转发,让更多人受益。同时,欢迎给个星标⭐,以便第一时间收到我的最新推送。每一个互动都是对我最大的鼓励。让我们携手并进,共同探索未知,见证一个充满希望和伟大的未来!
技术交流
加入「AI生成未来社区」群聊,一起交流讨论,涉及 图像生成、视频生成、3D生成、具身智能等多个不同方向,备注不同方向邀请入群!可添加小助手备注方向加群!











