

专为具身认知任务设计的视频多模态大语言模型
在具身智能的演进中,多模态大语言模型(MLLMs)虽能“看懂图像”,却仍像是被困在屏幕中的“数字大脑”——
它们擅长描述,却难以指向一个具体物体;
能生成语句,却摸不透物体的材质、功能和真实尺度;
缺乏对物理世界的连续感知与空间理解,因而难以真正指导机器人完成精细任务。
针对这些痛点,阿里达摩院与浙江大学团队提出了RynnEC —— 专为具身认知设计的视频多模态大语言模型。它不局限于对现有MLLMs的小修小补,而是从架构层面重新思考模型应如何对接具身环境。

让大模型真正走进具身
RynnEC在通用 VLM 的基础上,引入了区域编码器(Region Encoder)和掩码解码器(Mask Decoder),让模型具备区域级别的视频交互能力,从而能在动态场景中进行更精确的物体识别与空间理解。
不仅如此,作者还构建了RynnEC-Bench——覆盖 22 项物体与空间认知任务的细粒度基准,用于系统化评测 MLLMs 的具身认知能力。
接下来,我们将解读 RynnEC 的核心设计:
如何构建大规模具身认知数据、如何定义细粒度评测、模型架构的独特之处。
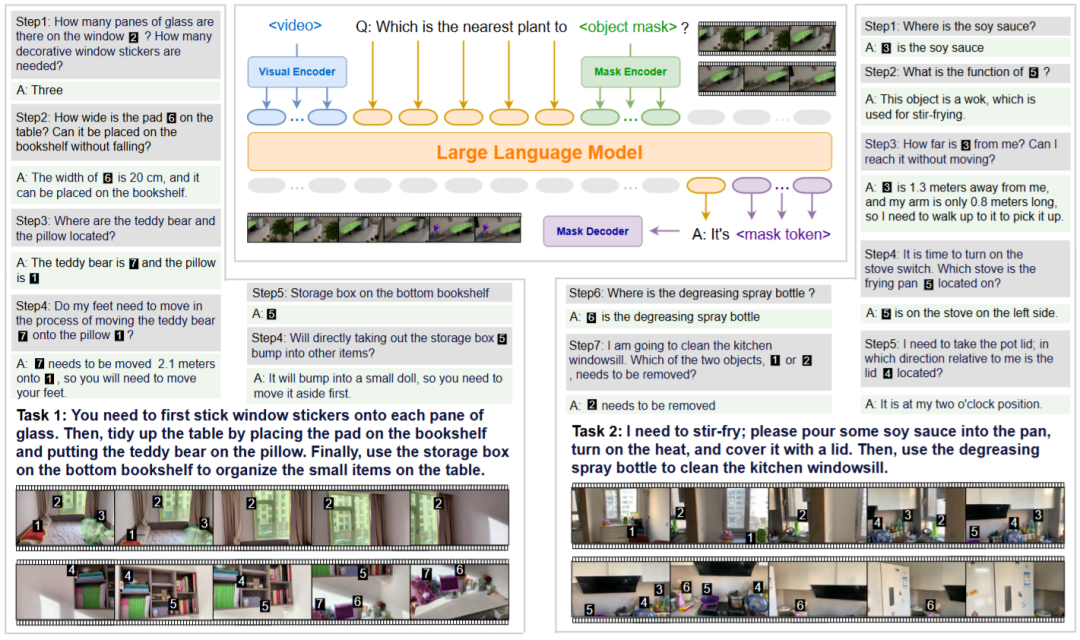
▲图1|RynnEC 是一款专为具身认知任务设计的视频多模态大语言模型(MLLM)。它能够接收由视频、区域掩码和文本交织而成的输入,并根据问题输出文本或掩码结果。RynnEC 能够处理具身场景中多样化的物体与空间问题,在室内具身任务中发挥着重要作用©️【深蓝具身智能】编译

RynnEC 的四大核心设计航
RynnEC 的方法框架,可以从数据生成→评测基准→模型架构→训练范式四个环节来理解。
数据生成
构建具身认知模型的第一步,是要有贴近真实世界的数据。RynnEC 的数据生成pipeline非常系统(见下图):
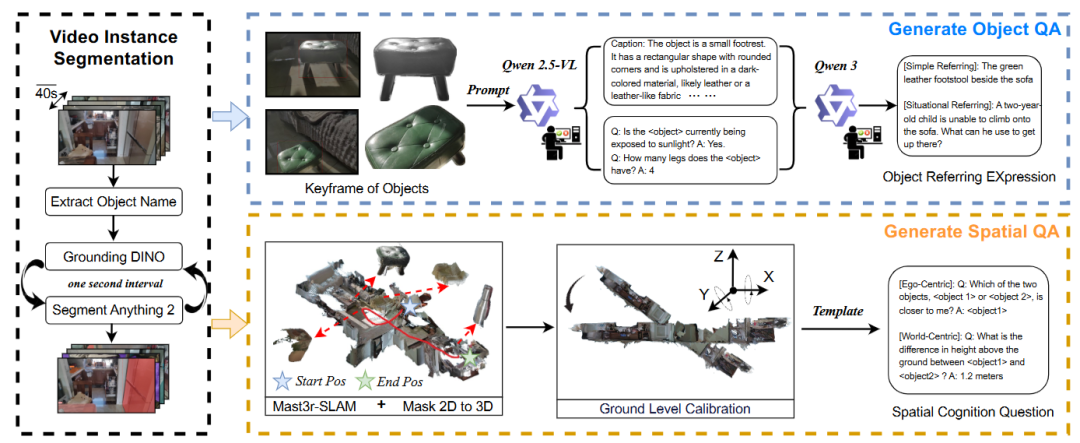
▲图2|数据生成的整体pipeline©️【深蓝具身智能】编译
视频采集:
(1)从 200 多个家庭环境中收集了超过 2 万条自我视角视频,每条视频 1080p/30fps,时长被切分为 40 秒片段。
(2)采集过程中刻意加入了多样性:不同照明条件、不同相机高度、跨房间拍摄路径等,模拟机器人在真实环境中的视觉体验。
实例分割与跟踪:
(1)使用 Qwen2.5-VL 输出场景物体清单;
(2)Grounding DINO 1.5 在关键帧中检测物体;
(3)SAM2 辅助跨帧分割与跟踪,最终得到 114 万个实例掩码,覆盖物体的完整生命周期。
两类认知问答数据:
(1)物体认知(Object Cognition):包括物体属性(颜色、材质、功能、状态等)、数量统计、直接/情境指代问答。
(2)空间认知(Spatial Cognition):基于单目 3D 重建生成问题模板,涉及距离、高度、相对方位、轨迹回顾、空间想象等任务。
通过这一流程,团队构建了一个统一的大规模具身认知数据集,同时支持物体和空间两方面的训练。
RynnEC-Bench
光有模型还不够,还要有一套衡量体系来验证它是否真的具备“理解物理世界”的能力。

▲图3|RynnEC-Bench的总览;其包含两个子集:object认知能力和空间认知能力,共评估22种具身认知能力©️【深蓝具身智能】编译
能力划分:
(1)物体认知:包括物体属性识别(如功能、表面细节、数量)和指代分割(直接指代 + 情境指代)。
(2)空间认知:分为自我中心(ego-centric) 和世界中心(world-centric)两类,覆盖方向、距离、大小、相对位置、轨迹回顾、空间想象等 22 项任务。
数据平衡:
视频采集自 10 个未出现在训练集的家庭,避免过拟合;并按照现实家庭环境的物体分布(来自 39,000 个家庭 50 万张图片统计)进行采样,让评测结果更贴近真实应用。
评测指标:
(1)数值问题:用平均相对准确率(MRA)衡量;
(2)角度问题:引入旋转准确率(RoA),考虑方向的循环性;
(3)分割问题:提出全局 IoU,更合理地评估视频分割质量。

RynnEC-Bench 不只是一个评测集,它相当于为“具身大模型”定制了一套系统的考试流程。
模型架构
RynnEC 的模型主体在 VideoLLaMA3 基础上扩展,形成三部分:
第一部分:基础 VLM
视觉编码器:VL3-SigLIP-NaViT,支持任意分辨率输入;
语言模型:Qwen2.5-Instruct(1.5B 或 7B),可在性能与计算成本之间灵活取舍。
第二部分:Region Encoder
通过 MaskPooling 将目标区域特征抽取并投射到语言空间;
这样,模型不仅能“整体看图”,还能“锁定局部”,实现更精准的跨模态对齐。
第三部分:Mask Decoder:
基于 SAM2,专门负责目标物体的掩码生成;
在输入指令中加入特殊 token [SEG],触发掩码预测,从而完成自然语言驱动的物体分割。
这种架构的独特之处在于:它真正把“物体级别的操作”纳入 MLLM 的交互方式,让模型具备了更接近人类的视觉指向能力。
四阶段训练范式
为了让模型学到稳定的物体与空间理解,RynnEC 采用了一个“课程学习式”的四阶段训练(见下图):
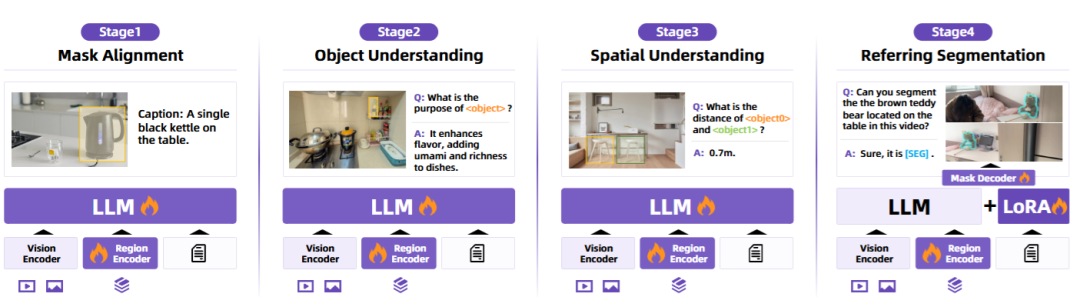
▲图4|RynnEC的训练范式©️【深蓝具身智能】编译
(1)掩码对齐(Mask Alignment):学习把物体掩码和语言描述对应起来;
(2)物体理解(Object Understanding):注入颜色、材质、功能等物体属性知识;
(3)空间理解(Spatial Understanding):学习距离、方向、方位等空间推理能力;
(4)指代分割(Referring Segmentation):在 LoRA 微调下加入分割能力,避免遗忘已有认知。
这种渐进式训练策略,避免了“一次性塞进所有任务”带来的灾难性遗忘,让模型能稳步积累多维度的认知能力。

RynnEC 的认知能力验证
RynnEC 的实验主要围绕三个方面展开:基准测试结果、泛化与扩展性、真实任务应用。
RynnEC-Bench 测试结果
在 RynnEC-Bench 上,研究团队对比了5类模型:
通用大模型(如 GPT-4o、Gemini-2.5 Pro)、开源 MLLM(Qwen2.5-VL、InternVL3)、视频理解模型(VideoLLaMA3)、以及专门的具身 MLLM(RoboBrain)。
实验结果显示:
综合能力领先:RynnEC-7B 的整体得分比 Gemini-2.5 Pro 高 10.7 分,在对象认知和空间认知两大类任务上都全面超越。
轻量模型表现突出:RynnEC-2B 仅有 20 亿参数,推理延迟更低,但性能与 7B 版本相差不到 2 个百分点,适合机器人端部署。
空间认知大幅提升:在 notoriously 难的空间推理任务上,RynnEC 的分数比 Gemini-2.5 Pro 高出 44.2%。
这一点证明了:相比“看图说话”的通用 MLLMs,RynnEC 在“理解空间与操作物体”上更贴近真实需求。

▲图5|对比实验数值结果©️【深蓝具身智能】编译
此外,RynnEC在物体认知和空间认知上也表现出了强大的能力:
在物体属性上(颜色、表面细节、状态),RynnEC-2B/7B 表现与甚至超过 Gemini-2.5 Pro;
在物体指代分割上,RynnEC 相比现有最佳分割模型提升 30.9%(直接指代) 和 57.7%(情境指代)。
RynnEC 展现了此前大模型几乎缺失的能力,如轨迹回顾、运动想象、空间想象;
这让机器人能够推理“我刚刚走过哪里”、“前方未见区域可能是什么”,这些都是高层任务规划的关键
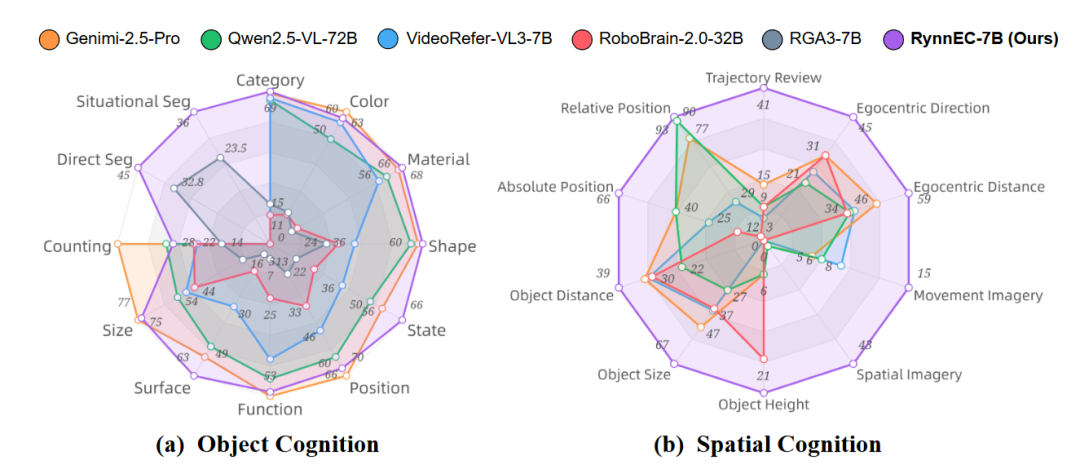
▲图6|物体认知与空间认知实验结果雷达图©️【深蓝具身智能】编译
泛化与扩展性
在纯文本空间推理基准 VSI-Bench 上,RynnEC 依旧超越了基底模型 VideoLLaMA3。
这说明 RynnEC 学到的 空间认知能力可以跨模态迁移 ——即便换成纯文本问题,它依旧能做出更精准的空间推理。
此外,作者还分析了数据规模对性能的影响:随着训练数据量从 20% 增长到 100%,RynnEC 的表现持续提升,但边际收益逐渐递减,提示未来需要在数据多样性上进一步突破。

▲图7|VSI-Bench上的性能表现。左图:与 RynnEC 的基础模型 VideoLLaMA3 在各子任务上的对比。右图:与通用型 MLLM 以及未显式引入 3D 编码的具身 MLLM 的整体对比©️【深蓝具身智能】编译
真实任务应用:机器人长时序执行
在 RoboTHOR 模拟环境中,RynnEC 驱动的机器人完成了两个复杂任务:
任务一:
“把篮球放进网球拍旁边的白盒子里” → 涉及物体定位、方位推理、尺寸估计;
任务二:
“把餐桌上的盘子减少到 5 个,并把多余的盘子放到笔记本电脑旁” → 涉及计数、抓取、空间位置理解。

▲图8|RynnEC 协助机器人执行长程任务的示例。机器人在 RoboTHOR 模拟器 中完成了两个指定任务。RynnEC 在整个任务执行过程中帮助机器人实现了细粒度的环境认知©️【深蓝具身智能】编译
在执行过程中,RynnEC 提供了:
精细物体定位与属性识别,加快目标物体识别速度;方向与距离感知,提升导航效率;空间尺度估计,保证放置动作合理;计数与推理能力,完成带条件约束的任务。
这些案例显示,RynnEC 不只是能“答题”,而是真正能帮助机器人执行复杂的长时序任务。
▲RynnEC视频演示©️【深蓝具身智能】编译

总结
RynnEC 让多模态大语言模型从“看视频答题”走向“真正理解并操作世界”。
它通过区域级别的视频理解,让模型能更细致地识别物体、推理空间关系,并在真实任务中帮助机器人完成复杂操作。
相比以往的大模型,RynnEC 不仅在评测基准上全面领先,还保持了轻量化设计,更接近实际落地的需求。
未来,当这类模型不断增强推理和规划能力时,机器人或许就能像人一样理解环境、制定计划,并执行完整任务。
Ref:
论文题目:RynnEC: Bringing MLLMs into Embodied World
论文地址:https://arxiv.org/pdf/2508.14160
编辑|阿豹
审编|具身君
工作投稿|商务合作|转载:SL13126828869(微信号)
>>>第三届自主机器人技术研讨会早鸟报名中<<<
ABOUT US|关于ARTS

为促进自主机器人领域一线青年学者和工程师的交流,推动学术界与企业界的深度交融与产学研合作,中国自动化学会主办了自主机器人技术研讨会(Autonomous Robotic Technology Seminar,简称ARTS)。
基于前两届大会的成功经验和广泛影响,第三届ARTS将继续深化技术交流与创新,定于2025年10月18日-19日在浙江大学(杭州)举办。我们诚挚邀请您参加,并欢迎您对大会组织提供宝贵意见和建议!

我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇


【深蓝具身智能】的内容均由作者团队倾注个人心血制作而成,希望各位遵守原创规则珍惜作者们的劳动成果。
工作投稿|商务合作|转载:SL13126828869(微信号)

点击❤收藏并推荐本文










