大家好,我是刘聪NLP。
8月31号,美团开源一个大模型,LongCat,560B的MoE模型,是一个非推理模型。看完他们的技术报告,感觉真在infra和模型结构研究上做了很多,里面真有不少细节!
PS:当天就有群友在群里催,别急别急,这不就来了吗

当然,群里还有群友抖机灵,是的,外卖大战没打完,大模型大战美团先发起来,看你如何应对,哈哈哈!

PS:最近很卷,来看看8月开源了哪些大模型!。
回归正题,我们来看看LongCat的相关技术细节,
LongCat的MoE模式与常规的MoE不同,
因为现在大模型预测下一个Token的特性,在直觉上,我们会觉得,难的Token应该耗费更多的计算才能预测准确,而简单的Token,可能极少的计算就能预测。
那对MoE专家来说,就是有的Token可能不需要那么专家来解决问题,
LongCat对此引入了零计算专家(Zero-Computation Experts),
零计算专家,是直接返回输入内容作为输出,没有不引入任何额外计算,所以当路由器选中零计算专家时,相当于跳过一次 Expert FFN 计算,实现不同Token消耗不同算了的需求。

在LongCat里,标准专家512个,零计算专家256个,激活专家12个, 这里你就能理解为啥官方说,激活参数是18.6B~31.3B,
12个专家都选了零计算专家,那就是18.6B激活参数(因为还有一些embedding、MLA等计算),
12个专家都选了标准专家,那就是31.3B激活参数

防止模型过度使用标准专家,忽略零计算专家,还设计了PID控制器来调节专家偏置项,同时加入设备级负载均衡损失,确保平均激活专家数稳定。
Token使用标准专家示例如下,可以发现一些连词、标点等,需要的专家计算就比较少。

还有,我真没想到,美团可以在infra上做这么多优化,
在大规模分布式训练中,MoE模型的瓶颈往往在通信,LongCat提出快捷连接MoE(Shortcut-Connected MoE),让前一层Dense FFN的计算 与 当前MoE层的通信并行执行,扩大了计算-通信重叠窗口,提升系统吞吐量。

推理阶段,采用支持Single Batch Overlap(SBO)策略,设计了四阶段流水线,将All-to-All通信与计算MLA、FFN重叠在一起,相比DeepSeek-V3的TBO(Two Batch Overlap),显著降低延迟。

LongCat的输出可以达到100+ tokens/s,很快,当然还有MTP提速,还有就是矮胖型(28层)也发挥了作用。
当然模型在训练上,也有一些细节点,除了对MLA进行尺度修正之外,还有超参数迁移,训练参数初始化上的优化。先训练一个14层的模型,然后将层数堆砌,得到28层的模型,相比随机初始化收敛更快,效果更优。
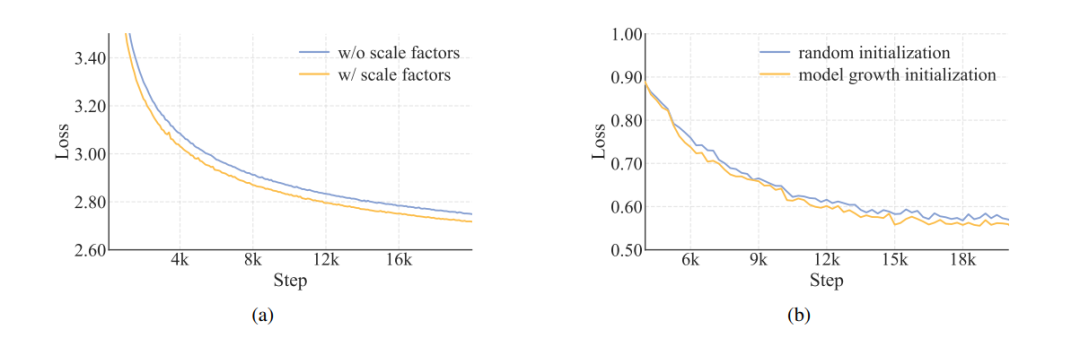
训练数据上倒是没有过多的内容,预训练数据约20T Tokens,先用通用数据训练,然后增加STEM和代码数据,长度从8K先扩展到32K,再到128K。
不过后训练,对Agent工具使用做了专门的优化,这也是榜单上Agent能力出众的地方。
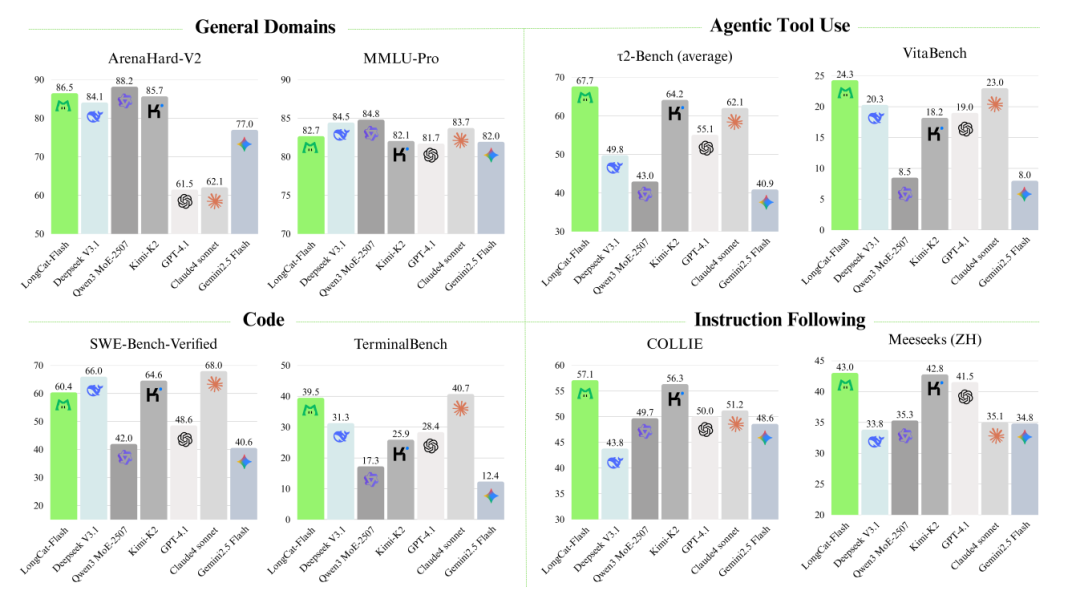
细节讲完,咱们进入到实测环节,
整体测试感受,
第一反应,回答速度也太快了吧 数学上还行,但是不知道是不是回答长度有限制,回答数学问题的时候,我遇到几次超长,强制停止输出的现象,同时过程之后,结尾会出现中英文夹杂的情况 指令遵循效果不错,能准确理解意图信息 不过现在还没有API放出来,所以没有测试agent能力,简单模拟了几个,还不错,但没有进行太复杂的测试 它们这个联网搜索也是蛮有意思,即使选择了联网搜索,模型也会自己判断一次,如果不需要检索,那么就不会去检索; 总体上基本上跟榜单的趋势一致。
常规测试
Promtp:将“I love LongCat”这句话的所有内容反过来写
结果:回答正确
知识理解
Prompt:如何理解“但丁真不会说中国话,但丁真会说中国话”
结果:回答不正确,没有理解但丁和丁真是两个人

角色扮演&创作
Prompt:用甄嬛体吐槽地铁早高峰
结果:有那味儿了

Prompt:帮小学生写一篇“我最讨厌的动物”作文,不能是猫狗
结果:写的还行,文笔有点像小学生,但是就是有点长了,我记得小学生作文一般300-450字,这有个800字了。

Prompt:写一个关于猫的故事,但不能出现‘猫’这个字。

弱智吧
Prompt:生蚝煮熟了叫什么?
结果:正确

Prompt:用水来兑水,得到的是浓水还是稀水
结果:正确,但是我发现一个问题,就是回答的时候,有时候特别喜欢带上引用,这个应该是训练数据导致的。

依旧小红,依旧老鹰
Prompt:小红有2个兄弟,3个姐妹,那么小红的兄弟有几个姐妹
结果:回答正确

Prompt:未来的某天,李同学在实验室制作超导磁悬浮材料时,意外发现实验室的老鼠在空中飞,分析发现,是因为老鼠不小心吃了磁悬浮材料。第二天,李同学又发现实验室的蛇也在空中飞,分析发现,是因为蛇吃了老鼠。第三天,李同学又发现实验室的老鹰也在空中飞,你认为其原因是
结果:回答错误,感觉能分析老鹰本来就会飞的模型很少~

数学
Prompt:一个长五点五米的竹竿,能否穿过一扇高四米,宽三米的门?请考虑立体几何
结果:回答正确

Prompt:2025年高考全国一卷数学试题

结果:前两问对了,最后一问错了

代码
Prompt:可爱风格五子棋游戏界面,画面有两个模式按钮“人人对战”和“人机对战”,界面整体采用马卡龙色调,棋盘简洁清晰,棋子设计成卡通小动物(如猫咪和小熊),背景带有轻微渐变和星星点缀,界面边缘圆润,按钮Q萌,整体风格温馨可爱,适合儿童或休闲玩家使用,2D插画风,用html呈现
结果:整体风格很好,而且棋盘还可能根据下棋之后,动态变化,有点意思
最后想说,
测试完之后,让我更加觉得LongCat在模型整体架构上做了很多,这输出速度也太快了吧,经常使用deepseek的我,都有点不适应。
美团这波开源,真不是那种随便搞个模型,随便开开,
从LongCat,让我们看到了国内大模型研发,已经不是能跑这么简单,是涉及基础设施、训练方法论、系统优化,越来越多的公司,像DeepSeek一样,走出了自己的风采。
这波LongCat,美团确实把科技公司的身份坐实了!
Respect!
-- 完 --
机智流推荐阅读:
2. 开源多模态大模型新突破,书生·万象3.5发布,通用能力、推理能力与部署效率全面升级
3. 工具调用推理只是花瓶,还是真的让大模型更聪明?腾讯清华团队揭秘工具集成推理的奥秘
4. CVPR2025 | g3D-LF让机器人“看懂”3D空间、“听懂”复杂语言,无需LLM,但导航、问答一气呵成
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群










