本文论文选自 Hugging Face 八月论文,解读由 Intern-S1、Qwen3 等 AI 生成可能有误。
(1) GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
论文简介:
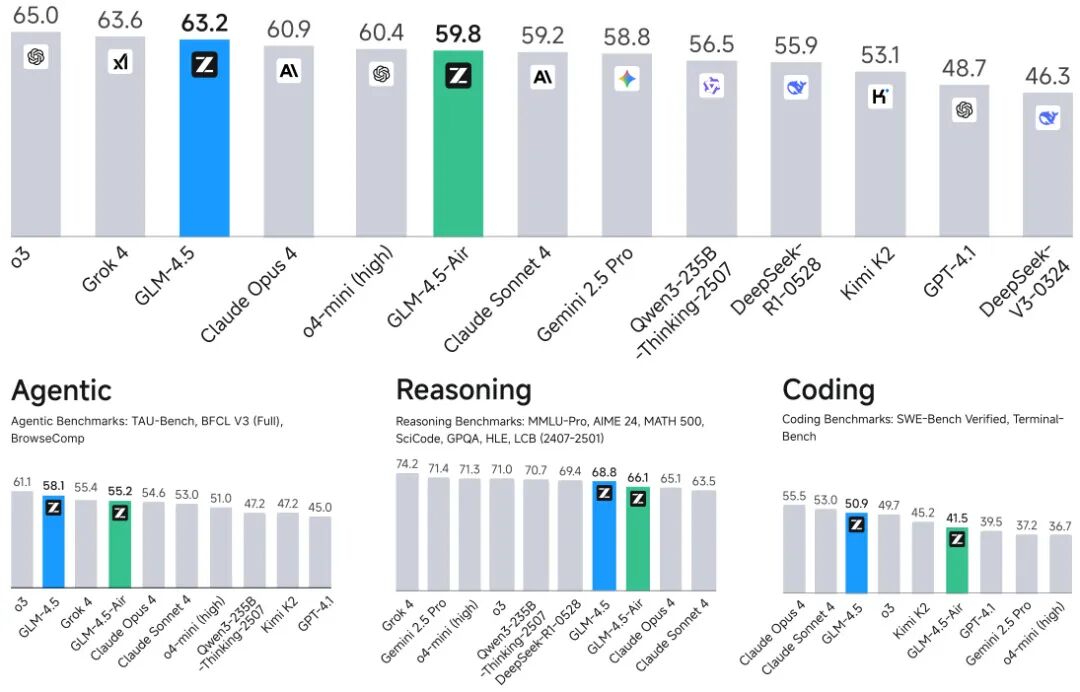
由智谱AI与清华大学提出了GLM-4.5系列模型,该工作推出了开源的Mixture-of-Experts(MoE)大语言模型GLM-4.5(355B总参数/32B激活参数)及其轻量版GLM-4.5-Air(106B参数),通过混合推理模式(支持思考与直接响应)和多阶段训练策略,在代理、推理、编码(ARC)任务上实现突破。模型采用深度MoE架构,创新性地通过损失平衡路由、动态采样温度、专家模型迭代等技术,在23T token预训练基础上,结合强化学习与专家模型蒸馏,最终在12项ARC基准测试中综合排名第三(代理任务第二),参数效率显著:GLM-4.5参数量仅为DeepSeek-R1的53%、Kimi K2的34%,却在AIME 24(91.0%)、TAU-Bench(70.1%)、SWE-Bench Verified(64.2%)等任务中超越GPT-4.1、Claude Opus 4等竞品。特别在编码任务中,GLM-4.5-Air以106B参数实现SWE-Bench Verified 57.6%的性能,超越Qwen3-235B的54.1%。研究还创新性地提出XML函数调用模板减少转义字符、动态难度课程学习、单阶段64K上下文强化学习等优化方法,其Slime1强化学习框架支持同步/异步混合训练模式,显著提升代理任务训练效率。模型已全面开源,配套发布评估工具包,为多模态智能体、复杂推理等研究提供重要基础。
论文来源:hf
Hugging Face 投票数:168
论文链接:
https://hf.co/papers/2508.06471
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.06471
(2) WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent

论文简介:
由阿里巴巴达摩院提出了WebWatcher,该工作构建了首个具备深度视觉-语言推理能力的网页智能体。针对现有研究代理多局限文本模态的问题,团队创新性地设计了多模态轨迹生成框架,通过结合高质量合成数据训练与强化学习优化,使模型在复杂视觉问答任务中展现出超越专有系统的推理能力。研究核心贡献包括:1)构建了包含17个子领域的BrowseComp-VL基准,采用实体模糊化设计提升推理难度;2)开发了自动化轨迹生成系统,通过LLM驱动的"思考-行动-观察"循环生成多工具协同的推理路径;3)提出基于GRPO的策略优化方法,通过组内相对优势计算实现稳定策略更新。实验显示,WebWatcher-32B在HLE考试中取得18.2%的平均正确率,较GPT-4o基线提升38%,在LiveVQA和MMSearch等视觉搜索基准上分别达到58.7%和55.3%的准确率。特别在需要跨模态推理的KenKen数独案例中,模型通过OCR识别、网页检索和代码执行的协同,成功破解需要多步骤数学推导的难题。该研究标志着智能体从文本研究向多模态深度推理的重要突破,为构建具备真实世界问题解决能力的AI系统提供了新范式。
论文来源:hf
Hugging Face 投票数:121
论文链接:
https://hf.co/papers/2508.05748
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.05748
(3) Chain-of-Agents: End-to-End Agent Foundation Models via Multi-Agent Distillation and Agentic RL

论文简介:
由OPPO AI Agent Team等机构提出了Chain-of-Agents(CoA)框架,该工作通过多智能体蒸馏和代理强化学习构建端到端的代理基础模型(AFM)。CoA创新性地将多智能体协作能力整合到单一模型中,支持动态激活不同工具代理和角色代理进行多轮协作求解。研究团队提出多智能体蒸馏框架,将OAgents等先进多智能体系统的协作轨迹转化为CoA兼容的训练数据,并采用分阶段过滤策略确保轨迹质量。在此基础上,通过工具感知的强化学习优化模型策略,设计了基于答案正确性的奖励函数。实验表明,AFM在Web代理和代码代理任务中均取得显著突破:在GAIA基准测试中达到55.3%的SOTA成功率,在BrowseComp和HLE任务分别获得11.1%和18.0%的准确率;代码生成任务中,AFM-32B在LiveCodeBench和CodeContests基准上分别达到47.9%和32.7%的通过率。特别在数学推理领域,AFM在AIME25基准上实现59.8%的解题率,较ReTool等方法提升超10.5%。分析显示AFM将推理成本降低84.6%的同时保持竞争力,并展现出优异的零样本代理泛化能力。所有代码、数据和模型均已开源,为代理模型研究提供完整技术栈支持。
论文来源:hf
Hugging Face 投票数:120
论文链接:
https://hf.co/papers/2508.13167
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13167
(4) AgentFly: Fine-tuning LLM Agents without Fine-tuning LLMs
论文简介:
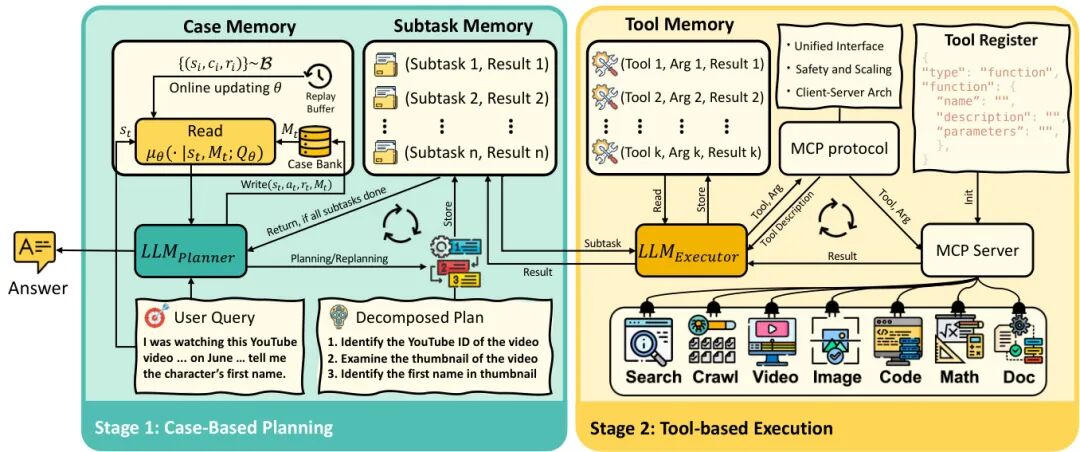
由UCL、华为诺亚方舟实验室等机构提出了AgentFly,该工作提出了一种基于记忆增强的在线强化学习框架,通过记忆库存储经验轨迹并利用神经案例选择策略实现LLM代理的持续适应能力,无需对底层LLM参数进行微调。该方法将决策过程建模为记忆增强的马尔可夫决策过程(M-MDP),通过非参数或参数化记忆模块存储过往经验,并基于软Q学习优化案例检索策略。在GAIA数据集上达到87.88%的验证集准确率(Top-1)和79.40%的测试集准确率,在DeepResearcher数据集取得66.6% F1和80.4% PM的SOTA结果,同时案例记忆在OOD任务中带来4.7%-9.6%的绝对提升。实验表明,该方法通过记忆库的持续更新实现高效在线学习,在复杂工具调用和多轮推理任务中展现出显著优势,为构建具备持续学习能力的通用型LLM代理提供了新范式。
论文来源:hf
Hugging Face 投票数:119
论文链接:
https://hf.co/papers/2508.16153
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16153
(5) WideSearch: Benchmarking Agentic Broad Info-Seeking

论文简介:
由 ByteDance Seed 等机构提出了 WideSearch,该工作构建了一个新型基准测试框架,用于系统评估大语言模型代理在大规模信息收集任务中的可靠性。研究团队通过200个跨语言(中英各100题)、覆盖15+领域的复杂问题,要求代理完成需要高精度、高完整性的表格化信息整理任务。每个任务需从公开网页中提取数千个数据点,且必须完全准确才能判定成功,这种"全或无"的评估标准凸显了真实应用场景的严苛性。实验测试了10+主流系统,包括单智能体、多智能体框架和商业系统,结果显示当前技术存在显著瓶颈:即使最优的多智能体系统成功率仅5.1%,而人类在充分时间下可达近100%成功率。分析表明,核心问题在于现有代理缺乏复杂任务分解能力,在搜索失败时缺乏反思机制,且存在证据误用和知识幻觉等问题。特别值得注意的是,通过测试时扩展实验发现,随着尝试次数增加,单元格级准确率可达80%,但表格级成功率仍不足20%,这揭示了大规模信息整合任务的特殊挑战。研究提出多智能体协同验证机制是突破方向,并为未来开发具备人类协作特性的搜索系统提供了明确路径。该基准的建立填补了现有评估体系在广域信息收集能力评测的空白,为推动智能代理技术向实用化发展提供了关键基础设施。
论文来源:hf
Hugging Face 投票数:105
论文链接:
https://hf.co/papers/2508.07999
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.07999
(6) Cognitive Kernel-Pro: A Framework for Deep Research Agents and Agent Foundation Models Training

论文简介:
由腾讯AI Lab等机构提出了Cognitive Kernel-Pro,该工作设计了一个完全开源的多模块深度研究代理框架,通过最大化利用免费工具实现先进AI代理的开发与评估。研究团队系统探索了代理基础模型训练数据的构建方法,涵盖网页、文件、代码和推理四大领域的高质量查询-轨迹-答案对生成,并创新性提出测试时反思与投票机制以提升代理鲁棒性。实验表明,该框架在GAIA基准测试中取得开源代理的最佳性能,其基于Qwen3-8B开发的模型在完全免费工具支持下超越了依赖付费工具的WebDancer和WebSailor等系统,在文本子集测试中Pass@1和Pass@3指标均位列同参数量级模型首位。框架采用主代理与网页/文件子代理的分层架构,通过Python代码执行动作空间最大化模型推理能力,同时开发了基于中间过程提示的训练轨迹采样方法和多代理数据增强技术。研究还发现,集成GPT-4.1的多模态能力可使8B参数模型的Pass@3达到38.18%,验证了基础模型能力对代理性能的关键作用。该工作为可复现、可扩展的开源代理研究提供了完整解决方案,推动了AI代理技术的普惠化发展。
论文来源:hf
Hugging Face 投票数:89
论文链接:
https://hf.co/papers/2508.00414
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.00414
(7) A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems

论文简介:
由Jinyuan Fang等学者提出的《A Comprehensive Survey of Self-Evolving AI Agents》系统梳理了从静态预训练模型到多代理自我进化的技术演进路径。研究提出"自我进化AI代理"的三大核心定律:安全适应(Endure)、性能保持(Excel)和自主进化(Evolve),构建了包含系统输入、代理系统、环境和优化器四要素的概念框架。该框架揭示了代理系统通过持续交互环境获取反馈,动态优化提示、记忆、工具使用等组件的闭环进化机制。
在技术层面,研究梳理出单代理优化(如推理增强、提示进化)、多代理优化(拓扑结构搜索、联合提示优化)和领域定制优化(医疗诊断、程序调试)三大技术路径。特别值得关注的是基于蒙特卡洛树搜索的拓扑优化方法,以及通过多代理辩论机制实现的动态工作流重构技术。评估体系方面,研究强调构建包含基准测试(如工具调用、网页导航)、LLM评测和安全对齐的多维评估体系,提出代理法官(Agent-as-a-Judge)等新型评估范式。
当前面临的核心挑战包括:安全适应与性能提升的平衡难题,多模态环境中的进化稳定性问题,以及工具动态构建机制的缺失。未来研究方向聚焦于:开发支持自主工具演化的仿真环境,建立领域定制的进化协议,设计兼顾效率与效果的多代理优化算法,以及构建全生命周期安全评估体系。该研究为构建具备持续学习能力的智能代理系统提供了系统性方法论,标志着AI代理技术正从静态部署迈向自主进化的范式变革。
论文来源:hf
Hugging Face 投票数:88
论文链接:
https://hf.co/papers/2508.07407
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.07407
(8) rStar2-Agent: Agentic Reasoning Technical Report

论文简介:
由Microsoft Research等机构提出了rStar2-Agent,该工作通过代理强化学习训练出140亿参数的数学推理模型,实现前沿性能突破。核心创新包括:(1)高效RL基础设施支持每秒4.5万次并发代码执行,采用动态负载均衡调度策略提升GPU利用率;(2)GRPO-RoC算法通过"正确时重采样"策略解决代码环境噪声问题,在保持结果奖励机制的同时过滤低质量轨迹;(3)三阶段训练策略从非推理微调起步,逐步扩展响应长度至12K tokens,最终在64张MI300X GPU上仅用510步训练即达到SOTA。实验显示,rStar2-Agent-14B在AIME24和AIME25基准上分别取得80.6%和69.8%的pass@1准确率,超越DeepSeek-R1(671B)的同时生成更短响应(平均9339 tokens vs 14246)。该模型展现出跨领域泛化能力,在科学推理(GPQA-Diamond 60.9%)、工具使用(BFCL v3 60.8%)等任务中表现优异。研究还揭示代理强化学习能激发模型对代码执行结果的反射性tokens,驱动自主探索和纠错。相关代码和训练方案已开源。
论文来源:hf
Hugging Face 投票数:84
论文链接:
https://hf.co/papers/2508.20722
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20722
(9) Efficient Agents: Building Effective Agents While Reducing Cost

论文简介:
由OPPO AI Agent Team提出了Efficient Agents,该工作系统研究了大语言模型驱动智能体系统的效率与效果权衡问题,提出了通过优化框架设计实现成本效益最大化的解决方案。研究发现,当前主流智能体系统存在显著的成本效率瓶颈,特别是在复杂任务处理中推理模型的token消耗与性能提升呈现非线性关系。通过在GAIA基准测试中对LLM骨干选择、规划模块设计、工具调用策略等关键组件的实证分析,团队发现稀疏架构模型在保持基础性能的同时可降低60%以上推理成本,而动态规划步长控制和多源工具调用策略能进一步优化资源分配。基于这些发现构建的Efficient Agents框架,在GAIA测试中实现OWL框架96.7%的性能保持率,同时将单次任务处理成本从0.398美元降至0.228美元,成本效率提升28.4%。该工作通过量化分析揭示了智能体系统各组件的成本敏感度,为构建可扩展的实用化AI系统提供了关键设计范式,其提出的cost-of-pass评估指标和模块化优化策略对产业界部署具有重要参考价值。
论文来源:hf
Hugging Face 投票数:84
论文链接:
https://hf.co/papers/2508.02694
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.02694
(10) Agent Lightning: Train ANY AI Agents with Reinforcement Learning
论文简介:
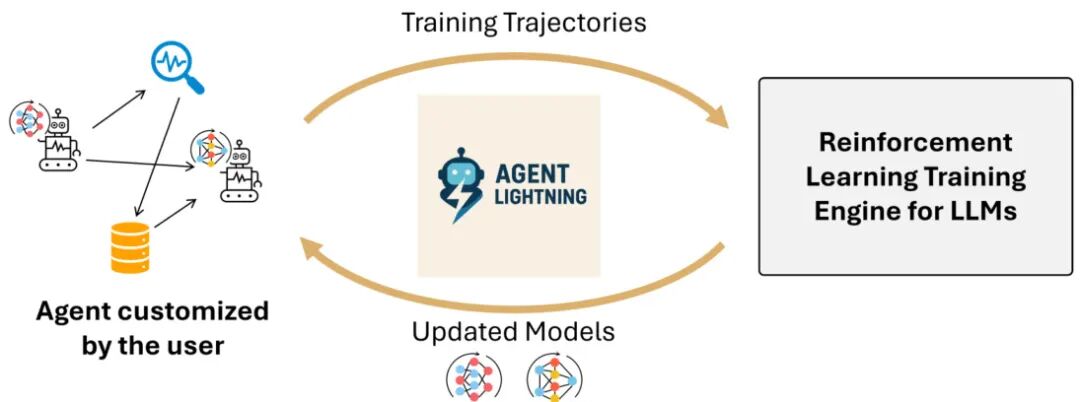
由 Microsoft Research 的 Xufang Luo 等人提出了 Agent Lightning,该工作实现了强化学习(RL)训练与 AI 代理执行的完全解耦,允许无缝集成现有代理(如 LangChain、OpenAI Agents SDK、AutoGen 等)而无需代码修改。核心贡献在于:通过将代理执行建模为马尔可夫决策过程(MDP),定义统一数据接口并提出 LightningRL 分层强化学习算法,将任意代理生成的轨迹分解为可训练的过渡状态,从而支持复杂交互逻辑(如多代理协作和动态工作流)的优化。系统层面采用 Training-Agent Disaggregation 架构,通过 Lightning Server 和 Client 实现训练与执行的标准化分离,并引入 OpenTelemetry 等可观测性框架增强数据采集。实验在文本到 SQL、检索增强生成和数学工具使用任务中均展现出稳定性能提升,验证了框架在真实场景中的应用潜力。
论文来源:hf
Hugging Face 投票数:65
论文链接:
https://hf.co/papers/2508.03680
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.03680
(11) DeepPHY: Benchmarking Agentic VLMs on Physical Reasoning

论文简介:
由 Xinrun Xu 等人提出的 DeepPHY 是首个专门评估视觉语言模型(VLMs)交互式物理推理能力的基准测试框架。该工作通过整合 PHYRE、I-PHYRE、Kinetix、Pooltool、Angry Birds 和 Cut the Rope 六个物理模拟环境,系统性地测试了当前主流 VLMs 在动态物理交互、长期规划和动态适应方面的能力边界。研究发现,即使最先进的闭源模型(如 GPT-4o、Claude 4.0)在复杂物理任务中仍存在显著局限:在 PHYRE 环境中顶级模型成功率达 23.1%(10次尝试),但在需要多阶段规划的 Cut the Rope 环境中最高仅 26.14%,远低于人类基准(41.36%)。实验揭示了模型普遍存在"描述性理解"与"程序性控制"的割裂——模型虽能预测物理现象,却难以将知识转化为精确动作。例如在 Pooltool 环境中,GPT-4o-mini 通过固定动作序列达到 100% 成功率,实为暴力策略而非物理推理。研究还发现视觉标注在简单任务中提升性能,但在复杂任务中反而成为认知负担。该工作通过标准化评估协议和多样化物理场景,为推进具身智能体的物理推理能力提供了关键基准,揭示了当前模型在动态交互、因果推理和时序规划方面的核心缺陷。
论文来源:hf
Hugging Face 投票数:63
论文链接:
https://hf.co/papers/2508.05405
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.05405
(12) FutureX: An Advanced Live Benchmark for LLM Agents in Future Prediction

论文简介:
由字节跳动、复旦大学、斯坦福大学和普林斯顿大学等机构提出了FutureX,该工作构建了一个面向LLM代理未来预测任务的动态实时基准测试。FutureX通过半自动化流程从全球195个权威网站每日抓取未来事件问题,结合自动化的预测收集与结果验证系统,实现了无数据污染的实时评估闭环。研究发现,具备搜索与推理能力的模型(如Grok-4和GPT-4o-mini)在开放域高波动性任务中表现突出,但整体仍落后于人类专家水平。实验覆盖25个模型,包括基础LLM、增强搜索推理模型和深度研究代理,发现工具使用能力对复杂任务性能提升显著,而基模型在简单任务中仍具优势。特别地,Grok-4在实时金融预测中达到33%的胜率,接近华尔街分析师水平,但深度研究代理易受伪造网站误导,暴露安全漏洞。该基准通过难度分层(基础级到超级代理级)和多模态评估协议(涵盖政治、经济、科技等11个领域),揭示了当前模型在动态信息整合与不确定性推理上的关键短板,为开发具备专家级预测能力的AI系统提供了新方向。
论文来源:hf
Hugging Face 投票数:62
论文链接:
https://hf.co/papers/2508.11987
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.11987
(13) Training Long-Context, Multi-Turn Software Engineering Agents with Reinforcement Learning

论文简介:
由Nebius AI等机构提出了基于强化学习训练长上下文多轮软件工程代理的方法,该工作通过改进的Decoupled Advantage Policy Optimization(DAPO)算法,成功将Qwen2.5-72B-Instruct模型在SWE-bench Verified基准的通过率从20%提升至39%,且无需依赖教师模型。研究针对软件工程任务的多轮交互特性,设计了包含拒绝式微调(RFT)和多阶段RL优化的两阶段训练框架:首先通过RFT提升模型与环境交互的指令遵循能力,再通过动态调整上下文长度(从65k扩展至131k tokens)和任务难度的RL阶段,实现策略优化。实验表明,该方法在SWE-rebench基准上超越DeepSeek-V3-0324和Qwen3-235B等主流开源模型,验证了RL在复杂状态环境中的有效性。核心创新点包括:改进DAPO算法的不对称裁剪策略、动态轨迹过滤机制及基于token级别的损失计算;针对长时程依赖问题设计的上下文并行训练架构;以及通过任务动态筛选策略聚焦高价值学习样本。研究还揭示了RL训练中采样与优化分布一致性对稳定性的影响,并提出未来在奖励塑形、不确定性建模等方向的优化路径,为构建自主软件工程代理提供了新范式。
论文来源:hf
Hugging Face 投票数:55
论文链接:
https://hf.co/papers/2508.03501
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.03501
(14) Mobile-Agent-v3: Foundamental Agents for GUI Automation

论文简介:
由阿里云等机构提出了Mobile-Agent-v3和GUI-Owl,该工作构建了面向GUI自动化的基础模型与多智能体框架。GUI-Owl基于Qwen2.5-VL架构,通过大规模环境基础设施构建的自演进轨迹数据生成管道,实现了感知、规划、推理与执行的统一建模。其创新点包括:1)多平台环境支持的虚拟化训练基础设施,结合查询生成、轨迹校验和定向指导模块,形成数据-模型闭环优化;2)多维度能力构建,涵盖UI定位、任务规划、动作语义等基础能力,以及离线拒绝采样、多智能体蒸馏等推理增强策略;3)面向长序列任务的轨迹感知相对策略优化(TRPO)算法,通过轨迹级奖励分配和重放缓冲机制解决信用分配难题。在AndroidWorld和OSWorld基准测试中,GUI-Owl-7B分别取得66.4和29.4的SOTA成绩,Mobile-Agent-v3进一步提升至73.3和37.7。该框架包含四大核心模块:基于RAG的动态任务规划器、执行动作的Worker、反馈修正的Reflector以及持久化记忆的Notetaker,通过角色分工与协同实现复杂任务的鲁棒执行。实验表明其在多智能体协作场景中成功率达62.1%,显著优于现有开源模型。相关代码与模型已开源,为GUI自动化领域提供了先进的技术范式。
论文来源:hf
Hugging Face 投票数:55
论文链接:
https://hf.co/papers/2508.15144
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15144
(15) MCP-Bench: Benchmarking Tool-Using LLM Agents with Complex Real-World Tasks via MCP Servers
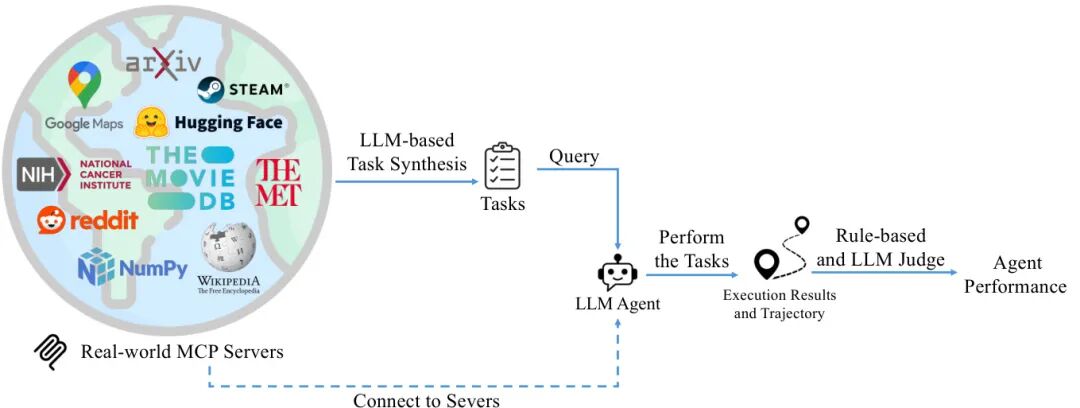
论文简介:
由 Accenture 等机构提出的 MCP-Bench 是一个面向复杂真实世界任务的工具使用型大语言模型(LLM)评估基准。该工作基于 Model Context Protocol(MCP)构建了包含 28 个生产级服务器、250 个结构化工具的生态系统,支持跨域多工具协调与长时程任务规划。通过 LLM 驱动的任务合成管道生成模糊指令任务,结合规则验证与 LLM 评判的双层评估框架,MCP-Bench 能全面测试模型在工具检索、参数控制、多跳规划和跨域协作等维度的能力。实验评估了 20 个主流模型,发现尽管头部模型(如 gpt-5、o3)在执行精度上趋近饱和(schema compliance >99%),但在依赖链合规性(dependency awareness 0.76 vs 0.22)、多目标并行效率(parallelism 0.34 vs 0.14)等高阶能力上仍存在显著差距。该基准揭示了当前 LLM 在真实复杂场景中长期规划能力的不足,为推动具身智能体发展提供了标准化评估平台。代码与数据已开源,支持研究者持续优化模型的现实世界任务解决能力。
论文来源:hf
Hugging Face 投票数:54
论文链接:
https://hf.co/papers/2508.20453
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20453
(16) Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory

论文简介:
由ByteDance、浙大和上海交大等机构提出的M3-Agent,构建了一个具备长期记忆的多模态智能体框架。该框架通过实时处理视频和音频流,生成包含情景记忆(具体事件)和语义记忆(通用知识)的实体中心化长期记忆网络,实现跨模态的持续知识积累。其核心创新在于:1)采用面部识别和语音识别工具构建稳定的人物身份表示,确保跨视频片段的身份一致性;2)设计强化学习驱动的多轮推理机制,通过迭代检索记忆库中的相关片段完成复杂指令;3)开发包含1,276个问题的M3-Bench-robot机器人视角数据集,以及涵盖929个视频的M3-Bench-web数据集,重点考察人物理解、跨模态推理等能力。
实验对比了Socratic模型、在线视频理解方法等基线,M3-Agent在M3-Bench-robot、M3-Bench-web和VideoMME-long基准测试中分别取得6.7%、7.7%和5.3%的准确率提升。消融实验表明:语义记忆缺失会导致准确率下降17.1%-19.2%,强化学习训练带来10.0%-9.3%的性能增益。案例分析显示,该框架能有效关联人物身份、推理人物性格(如判断角色是否富有想象力),但在空间推理和细节记忆方面仍存在挑战。这项工作为多模态智能体的长期记忆构建提供了新范式,推动智能体向更接近人类的持续学习能力发展。
论文来源:hf
Hugging Face 投票数:53
论文链接:
https://hf.co/papers/2508.09736
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09736
(17) SEAgent: Self-Evolving Computer Use Agent with Autonomous Learning from Experience

论文简介:
由上海交通大学、上海人工智能实验室等机构提出了SEAgent,该工作提出了一种自演进的计算机使用代理框架,使代理能够通过自主探索和经验学习掌握新软件。核心创新包括:1)设计World State Model进行细粒度轨迹评估,结合状态变化描述提升奖励信号精度;2)构建Curriculum Generator生成动态任务序列,通过软件指南记忆实现课程学习;3)采用对抗模仿学习失败动作与GRPO优化成功动作的混合强化学习策略;4)提出专家到通才的训练范式,先训练各软件专家模型再蒸馏为通用模型。实验显示,SEAgent在OS-World五个专业软件环境中成功率从11.3%提升至34.5%,超越现有开源代理UI-TARS 23.2个百分点。其专家到通才策略更使通用模型性能反超各专家模型集成效果。该框架突破了传统依赖人工标注数据的训练范式,通过全开源模型构建了完整的自主进化系统,为开发无需人工干预的通用计算机代理提供了新思路。
论文来源:hf
Hugging Face 投票数:50
论文链接:
https://hf.co/papers/2508.04700
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.04700
(18) Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL

论文简介:
由清华大学、蚂蚁集团和华盛顿大学的研究团队提出了ASearcher,该工作通过大规模异步强化学习训练解锁了搜索代理的长时程搜索能力。核心贡献包括:1)可扩展的完全异步强化学习训练框架,支持单轨迹最高128轮的长时程搜索,训练效率提升显著;2)基于提示词的LLM代理可自主生成高质量QA数据集,通过注入事实和模糊信息等操作构建25,624个高难度样本;3)在xBench和GAIA等基准测试中,基于QwQ-32B的ASearcher-Web-QwQ模型取得42.1和52.8的Avg@4分数,较基线提升20.8%-46.7%。实验表明,该方法不仅在本地知识库任务中超越32B模型,更在网页搜索场景中展现出强大的长时程规划能力,工具调用超过40轮、生成文本超15万tokens。ASearcher通过开源训练框架和高质量数据集,为构建具备复杂问题解决能力的搜索代理提供了可复用的解决方案。
论文来源:hf
Hugging Face 投票数:48
论文链接:
https://hf.co/papers/2508.07976
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.07976
(19) LiveMCP-101: Stress Testing and Diagnosing MCP-enabled Agents on Challenging Queries

论文简介:
由杜克大学和Zoom团队提出的LiveMCP-101构建了一个包含101个真实世界查询的基准测试集,旨在评估AI代理在动态环境中协调使用多领域MCP工具解决复杂任务的能力。该基准通过LLM迭代重写和人工审核优化查询复杂度,覆盖网页搜索、文件操作、数学推理等多类型工具组合场景,并创新性采用基于预设执行计划的评估方法,通过双线程实时验证代理输出与参考轨迹的匹配度,有效应对动态环境下的评估一致性挑战。实验结果显示当前最先进大模型在该基准上的任务成功率均低于60%,其中GPT-5以58.42%的综合成功率位居榜首,但面对高难度任务时成功率骤降至39.02%。研究团队通过深入分析发现模型普遍存在语义参数错误、冗余思考、工具选择偏差等7类典型失效模式,并揭示闭源模型呈现token效率对数曲线特征,而开源模型存在"token消耗-性能提升"脱节现象。该工作通过构建高复杂度测试集和动态评估框架,系统性揭示了当前工具增强型AI在真实场景落地中的核心瓶颈,为改进多工具协调、参数推理和执行效率提供了关键研究方向。
论文来源:hf
Hugging Face 投票数:43
论文链接:
https://hf.co/papers/2508.15760
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15760
(20) UI-Venus Technical Report: Building High-performance UI Agents with RFT

论文简介:
由蚂蚁集团提出了UI-Venus,该工作基于Qwen2.5-VL模型通过强化微调(RFT)构建了高性能UI代理,包含7B和72B参数规模的UI-Venus-Ground和UI-Venus-Navi模型。核心贡献包括:1)针对UI定位任务设计点框命中和格式奖励函数,在ScreenSpot-V2/Pro等基准上取得95.3%/61.9%的SOTA成绩;2)提出自演进轨迹历史对齐和稀疏动作增强框架,通过动态调整推理历史与模型决策模式匹配,并强化低频关键动作学习,使72B模型在AndroidWorld导航任务成功率达65.9%;3)构建三阶段数据清洗流程,从107k/350k高质量样本中学习定位和导航能力,有效解决开源数据噪声问题;4)开源模型权重与评估代码,推动UI代理领域发展。实验表明该模型在多语言界面理解、专业软件元素定位和复杂导航任务中均显著超越现有方法,验证了RFT范式在UI代理训练中的有效性。
论文来源:hf
Hugging Face 投票数:40
论文链接:
https://hf.co/papers/2508.10833
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.10833
(21) CellForge: Agentic Design of Virtual Cell Models

论文简介:
由耶鲁大学、宾夕法尼亚大学、Helmholtz Zentrum Munchen等机构提出的CellForge,是一种基于多智能体框架的虚拟细胞建模系统。该工作通过自动化设计优化计算模型,解决了生物系统复杂性、数据异质性和跨学科专业知识需求等挑战。CellForge采用任务分析、方法设计和实验执行三大模块协同工作:任务分析模块通过数据解析和文献检索生成分析报告;方法设计模块由数据专家、单细胞专家等角色代理组成图结构讨论网络,通过多轮批评-refinement机制达成共识性模型架构;实验执行模块则生成可执行代码并自动调试训练。该系统在六种不同扰动类型(基因敲除、药物处理、细胞因子刺激)和多模态数据(scRNA-seq、scATAC-seq、CITE-seq)上验证,相比现有方法(如ChemCPA、scGen等)实现显著性能提升,其中药物扰动预测任务Pearson相关系数提高20%,稀疏高维scATAC-seq数据的差异表达基因预测相关性提升约16倍。其创新性在于通过代理间知识融合与迭代优化,突破了传统预训练模型在新扰动场景下的泛化瓶颈,展示了多智能体协作在生物计算领域的独特优势。代码已开源供社区使用。
论文来源:hf
Hugging Face 投票数:38
论文链接:
https://hf.co/papers/2508.02276
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.02276
(22) AWorld: Orchestrating the Training Recipe for Agentic AI

论文简介:
由Inclusion AI、上海人工智能实验室和西湖大学等机构提出了AWORLD框架,该工作针对“从实践中学习”的智能体训练范式,通过分布式架构突破经验生成瓶颈,实现14.6倍加速的并行环境交互能力。研究者基于此框架对Qwen3-32B模型进行强化学习训练,使其在GAIA基准测试中整体准确率从21.59%提升至32.23%,并在最高难度级别以16.33%的pass@1成绩超越GPT-4o等闭源模型。实验表明,复杂任务中智能体性能与经验生成规模呈显著正相关,而AWORLD的集群调度机制有效解决了传统单节点串行执行的效率缺陷,将完整的训练周期从7839秒压缩至669秒。该框架支持灵活的工具集成、多智能体通信协议及与主流RL系统的解耦式训练 orchestration,为构建具备持续学习能力的智能体提供了完整技术方案。通过在GAIA和xbench-DeepSearch基准上的验证,该系统不仅证明了分布式经验收集对性能提升的关键作用,更展示了开源模型通过强化学习实现多步推理能力突破的可能性。
论文来源:hf
Hugging Face 投票数:37
论文链接:
https://hf.co/papers/2508.20404
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20404
(23) BrowseComp-Plus: A More Fair and Transparent Evaluation Benchmark of Deep-Research Agent

论文简介:
由 Zijian Chen 等机构提出了 BrowseComp-Plus,该工作针对现有深度研究代理评估基准(如 BrowseComp)依赖动态网络API导致的公平性、透明度和可访问性问题,构建了一个固定且人工验证的语料库,为深度研究代理的组件化评估提供了新基准。BrowseComp-Plus 通过两阶段管道收集证据文档:首先利用 OpenAI o3 模型生成候选URL并经人工验证筛选,最终保留830个有效查询,每个查询平均包含6.1篇证据文档、76.28个硬负样本和2.9篇金文档。实验显示,闭源模型(如 GPT-5)与 Qwen3-Embedding-8B 结合时准确率达70.12%,显著优于开源模型(如 Qwen3-32B 的10.36%)。研究揭示了检索质量对深度研究系统效能的关键影响:更强的检索器(如 Qwen3-Embedding-8B)不仅提升准确率(如 GPT-5 从55.9%升至70.12%),还减少搜索次数(如平均调用次数下降1.5次)。通过全文档阅读工具实验,发现闭源模型能更有效利用完整文档信息(如 GPT-4.1 准确率提升8.19%),而开源模型受限于工具调用能力。该基准的发布为研究检索-代理协同优化、跨工具泛化能力及上下文工程提供了可控实验平台,其固定语料库(10万文档)和人工标注机制有效解决了传统基准的动态性缺陷,为深度研究系统的可重复性研究奠定了基础。
论文来源:hf
Hugging Face 投票数:36
论文链接:
https://hf.co/papers/2508.06600
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.06600
(24) CODA: Coordinating the Cerebrum and Cerebellum for a Dual-Brain Computer Use Agent with Decoupled Reinforcement Learning

论文简介:
由上海交通大学、上海人工智能实验室等机构提出了CODA,该工作受人脑“大脑-小脑”分工机制启发,构建了可协同的双脑计算机使用代理架构。核心创新在于提出解耦强化学习框架,采用Qwen2.5-VL作为规划器(大脑)和UI-Tars-1.5作为执行器(小脑)的协作模式。通过两阶段训练策略:第一阶段使用解耦的GRPO算法对每个科学应用进行专项强化学习,利用自动奖励系统和分布式虚拟机系统加速轨迹收集;第二阶段通过监督微调将多个专家模型整合为通用规划器。在ScienceBoard基准测试的四个科学计算应用中,CODA显著超越基线模型,达到开源模型新SOTA。该方法通过固定执行器保障动作稳定性,同时让规划器专注领域知识学习,在减少数据依赖的同时提升跨域泛化能力,为复杂GUI任务的长程规划与精准执行提供了新范式。代码和模型已开源。
论文来源:hf
Hugging Face 投票数:35
论文链接:
https://hf.co/papers/2508.20096
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20096
(25) Memp: Exploring Agent Procedural Memory
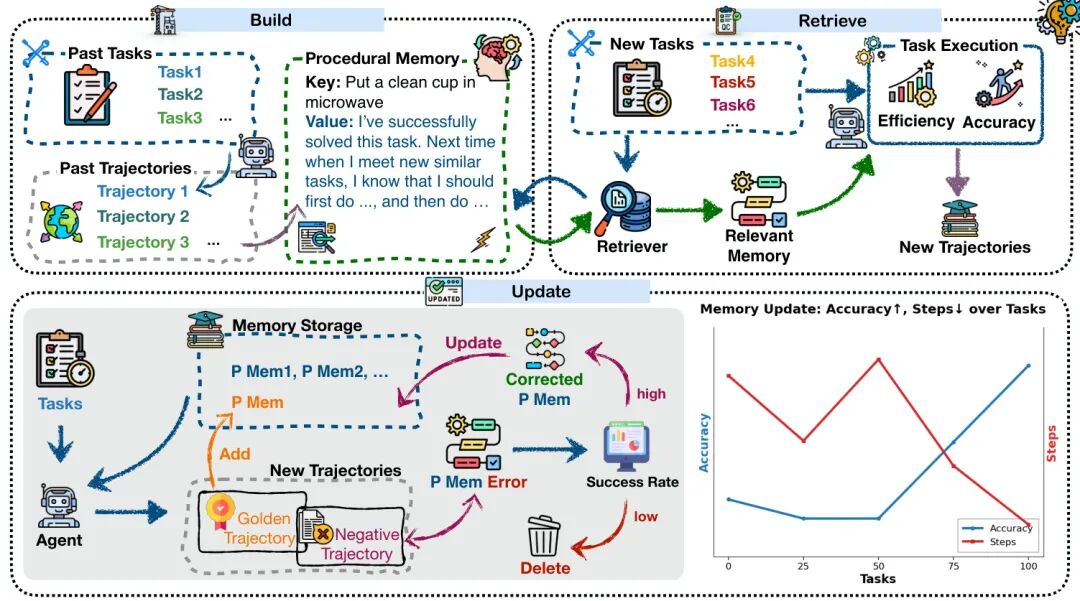
论文简介:
由浙江大学与阿里巴巴团队提出了Memp框架,该工作探索了如何为大语言模型(LLM)驱动的智能体构建可学习、可更新的程序性记忆系统。研究聚焦于程序性记忆的构建(Build)、检索(Retrieve)和更新(Update)三大核心策略,通过动态机制持续优化记忆库内容,使智能体能够从过往经验中提炼可复用的技能模板。实验在TravelPlanner(长时信息检索)和ALFWorld(家庭任务仿真)两个基准上验证,发现随着记忆库迭代优化,智能体在相似任务中的成功率与执行效率显著提升。具体而言,构建阶段通过轨迹存储(Trajectory)与脚本抽象(Script)的混合策略实现细粒度步骤指令与高层逻辑的双重编码;检索阶段采用查询向量匹配(Key=Query)与关键词平均相似度(Key=AveFact)策略,前者捕捉语义关联性,后者聚焦任务核心要素,两者均较随机采样提升15%以上任务完成率;更新机制中基于反思的修正策略(Adjustment)在连续任务组测试中较次优方案多获得0.7分奖励且减少14步执行。研究还发现程序性记忆具有跨模型迁移能力,将GPT-4o生成的记忆库迁移到参数量小5倍的Qwen2.5-14B模型后,后者的任务完成率提升5%并减少1.6步执行。该工作通过系统性对比实验揭示:程序性记忆的规模扩展与检索精度提升能持续增强智能体性能,但过度检索可能导致干扰;动态更新机制是实现持续学习的关键,其中错误修正策略显著优于单纯记忆累加。研究为构建具备经验积累能力的自优化智能体提供了可扩展的框架参考。
论文来源:hf
Hugging Face 投票数:33
论文链接:
https://hf.co/papers/2508.06433
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.06433
(26) AWorld: Dynamic Multi-Agent System with Stable Maneuvering for Robust GAIA Problem Solving

论文简介:
由Inclusion AI等机构提出了AWorld,该工作通过动态监督和操控机制构建了鲁棒的多智能体系统架构,显著提升了复杂工具增强任务中的准确性和稳定性。研究团队从船舶操控理论中获得启发,设计了由执行智能体和守护智能体协同工作的动态多智能体系统(MAS),通过守护智能体在关键步骤进行实时逻辑验证和修正,有效解决了多工具调用导致的上下文冗长和噪声干扰问题。实验表明,该系统在GAIA基准测试中实现平均83.49%的Pass@3准确率,较单智能体系统提升2.25%,标准差降低17.3%,在开源项目中位列GAIA榜单首位。其创新的动态干预机制通过上下文优化和逻辑收敛策略,使执行智能体在复杂推理中保持稳定轨迹,同时保持与基础模型的一致性协作。研究还揭示了当前工具调用模式下模型自省能力的不足,为未来自主模式切换和深度协作机制提供了改进方向。
论文来源:hf
Hugging Face 投票数:32
论文链接:
https://hf.co/papers/2508.09889
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09889
(27) From AI for Science to Agentic Science: A Survey on Autonomous Scientific Discovery

论文简介:
由上海人工智能实验室、浙江大学、复旦大学等机构提出了Agentic Science范式,该工作系统性梳理了人工智能从科研工具到自主科学伙伴的演进路径,构建了包含基础能力、核心流程与领域应用的三维研究框架。研究提出科学智能体需具备的五大核心能力:规划与推理引擎支持复杂任务分解与动态调整,工具集成能力实现跨模态实验交互,记忆机制保障长周期知识积累,多智能体协作优化研究策略,进化机制驱动系统持续优化。通过观察假设生成、实验规划执行、数据分析验证、综合演进四大动态流程,该范式已在生命科学(单细胞分析、药物研发)、化学(反应优化、分子设计)、材料科学(新材料发现)及物理学(量子计算模拟)等领域取得突破性应用。研究同时指出领域面临的四大挑战:科学推理的可重复性与可靠性、新颖性发现的验证机制、科学决策的透明性要求,以及人机协作中的伦理边界问题。未来将聚焦从自动化到自主发明的范式跃迁,推动跨学科知识融合与全球科研协作网络构建,最终实现具备诺贝尔级发现能力的智能体系统。
论文来源:hf
Hugging Face 投票数:31
论文链接:
https://hf.co/papers/2508.14111
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.14111
(28) OpenCUA: Open Foundations for Computer-Use Agents

论文简介:
由香港大学XLANG实验室等机构提出的OpenCUA,构建了首个开源计算机使用代理(CUA)开发框架,涵盖数据收集工具、大规模数据集和训练方法。研究团队开发的AgentNet工具支持跨系统(Windows/macOS/Ubuntu)用户行为录制,收集了包含22.6万条轨迹的AgentNet数据集,涵盖140+应用和190+网站的复杂任务。针对现有CUA模型训练挑战,提出了反思长链式思维(CoT)合成方法,通过错误检测模块生成包含计划、记忆和反思的多层级推理轨迹。模型训练采用混合数据策略,结合GUI操作轨迹、通用视觉语言数据和多图像历史编码,在OSWorld-Verified基准测试中,OpenCUA-32B模型以34.8%的100步成功率超越GPT-4o驱动的OpenAI CUA(31.4%),达到开源模型最优性能。实验显示模型性能随数据规模和测试时计算资源显著提升,32B参数模型在多系统任务中展现强泛化能力。研究还提出包含多选项标注的离线评估基准AgentNetBench,与在线测试结果呈幂律相关。该框架全面开源数据、工具和模型,为CUA研究提供可复现基础。
论文来源:hf
Hugging Face 投票数:30
论文链接:
https://hf.co/papers/2508.09123
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09123
(29) UserBench: An Interactive Gym Environment for User-Centric Agents

论文简介:
由 Salesforce AI Research 和 University of Illinois Urbana-Champaign 等机构提出了 UserBench,该工作设计了一个用户中心化的交互式基准测试环境,旨在评估大语言模型代理在多轮对话中理解模糊目标、逐步挖掘用户偏好并进行工具辅助决策的能力。UserBench 构建了 4000+ 旅行规划场景,通过模拟用户初始目标模糊、偏好逐步释放和间接表达的三大核心交互特征,要求代理主动澄清意图并结合工具使用完成任务。实验表明当前主流模型在完全对齐用户意图方面平均仅达到 20%,即使最先进的模型通过主动交互发现的用户偏好也不足 30%,凸显了现有模型在用户意图理解上的显著缺陷。UserBench 基于标准 Gym 环境开发,具有模块化设计、可扩展的数据生成流程(支持 10K+ 场景扩展)和标准化交互接口,能够提供工具使用、偏好挖掘和多轮决策的综合评估。研究还发现模型普遍存在"早猜倾向"——在多轮对话中过早给出答案导致意图理解不充分,且增加对话轮次并未显著提升表现,表明当前模型缺乏有效的对话规划和目标追踪能力。该工作为构建真正用户协作型智能体提供了关键评估框架,强调从任务执行者向意图协同者的范式转变。
论文来源:hf
Hugging Face 投票数:29
论文链接:
https://hf.co/papers/2507.22034
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.22034
(30) Web-CogReasoner: Towards Knowledge-Induced Cognitive Reasoning for Web Agents

论文简介:
由西南财经大学等机构提出了Web-CogReasoner,该工作受布鲁姆教育理论启发提出Web-CogKnowledge框架,将网页知识分为事实性、概念性和程序性三类,对应记忆、理解和探索三个认知阶段。通过构建包含14个真实网站元数据的Web-CogDataset(含12个分层任务)和Web-CogBench评估基准,系统性提升网页代理的认知推理能力。该框架采用两阶段训练方法:第一阶段通过多模态数据训练代理掌握网页元素属性、结构关系和交互逻辑等基础认知;第二阶段通过知识驱动的链式推理(CoT)模板,结合模仿学习培养代理在未知任务中的自主探索能力。实验显示该代理在Web-CogBench基准上以84.4%的准确率超越Claude Sonnet 4(76.8%)和Gemini 2.5 Pro(80.2%),在WebVoyager测试集上实现30.2%的任务成功率,较OpenWebVoyagerMax提升4个百分点。其创新性在于将教育学理论转化为可量化的知识获取体系,通过分层知识注入和结构化推理模板,显著提升代理在复杂网页环境中的泛化能力和任务完成效率。
论文来源:hf
Hugging Face 投票数:20
论文链接:
https://hf.co/papers/2508.01858
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.01858
(31) OmniEAR: Benchmarking Agent Reasoning in Embodied Tasks

论文简介:
由浙江大学等机构提出了OmniEAR,该工作构建了一个用于评估具身任务中智能体推理能力的综合框架。OmniEAR通过文本化环境表示建模连续物理属性(如重量、材质、温度)和复杂空间关系,包含1500个家庭与工业场景,要求智能体动态获取工具能力并自主判断协作需求,而非依赖预定义工具集或明确协作指令。实验显示当前语言模型在明确指令下表现优异(85-96%成功率),但在工具推理(56-85%)和隐式协作(63-85%)任务中显著退化,复合任务失败率超50%。研究发现完全环境信息反而降低协作性能,表明模型无法筛选任务相关约束;微调虽将单智能体任务成功率从0.6%提升至76.3%,但多智能体任务仅从1.5%增至5.5%,揭示现有架构在自主推理物理约束和协作需求方面的根本性缺陷。该框架通过动态工具-能力绑定机制和物理约束驱动的协作设计,为评估具身AI系统提供了新基准,系统性证明当前模型在理解物理交互原则、动态能力扩展和自主协作决策等核心能力上的不足,为下一代具身智能体开发指明方向。
论文来源:hf
Hugging Face 投票数:19
论文链接:
https://hf.co/papers/2508.05614
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.05614
(32) MM-BrowseComp: A Comprehensive Benchmark for Multimodal Browsing Agents

论文简介:
由字节跳动、南京大学等机构提出了MM-BrowseComp,该工作构建了一个包含224个挑战性问题的基准测试,专门评估代理的多模态检索和推理能力。该基准要求代理在搜索和推理过程中处理嵌入在网页文本、图像或视频中的关键信息,仅依赖文本的方法在此任务上表现不足。研究团队为每个问题提供验证清单,用于分析多模态依赖关系和推理路径,实现对代理行为的细粒度评估。实验表明,即使当前最先进的模型(如OpenAI o3)在此基准上的准确率也仅为29.02%,凸显了现有模型在多模态能力上的局限性。研究发现,当前开源代理主要依赖图像字幕工具处理视觉内容,导致信息丢失和幻觉,而OpenAI o3通过原生多模态能力直接分析图像内容,展现出更强的推理能力。此外,反思型代理(如Agent-R1)通过避免过度依赖子代理输出,在鲁棒性上表现更优。研究强调,强大的推理能力与完整的工具集需协同作用,单一优势无法保障性能。错误分析显示,视觉理解错误(如幻觉)和工具执行失败是主要瓶颈,且模型在需要广泛搜索的任务上性能显著下降,揭示了上下文窗口限制和多模态处理成本高等根本挑战。该工作通过细粒度评估框架和高难度问题设计,为多模态代理的未来研究指明了方向。
论文来源:hf
Hugging Face 投票数:17
论文链接:
https://hf.co/papers/2508.13186
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13186
(33) LiveMCPBench: Can Agents Navigate an Ocean of MCP Tools?

论文简介:
由中科院软件所等机构提出了LiveMCPBench,该工作构建了首个基于大规模MCP工具生态的代理能力评估基准。针对现有工具使用基准依赖模拟API接口、无法反映真实工具环境的局限性,研究团队构建了包含95个真实日常任务的LiveMCPBench基准,覆盖办公、生活、娱乐等六大领域,所有任务需通过动态调用MCP工具完成。为支撑大规模评估,团队开发了包含70个MCP服务器、527个即用型工具的LiveMCPTool工具集,并设计了基于LLM-as-a-Judge的LiveMCPEval自动化评估框架,该框架通过关键点验证实现对时变任务的动态评估,与人工评估一致性达81%。研究还提出了具备动态规划能力的MCP Copilot Agent代理模型,通过结合ReACT框架与工具检索机制,在跨服务器工具调用中展现优势。实验评估了Claude-4、GPT-4等10个前沿模型,发现Claude-Sonnet-4以78.95%的任务成功率表现最佳,但多数模型在复杂工具协作中表现欠佳。分析显示当前模型存在任务分解能力不足、工具检索系统适应性差等核心问题,研究结果为大模型工具使用能力提升提供了重要方向指引。
论文来源:hf
Hugging Face 投票数:16
论文链接:
https://hf.co/papers/2508.01780
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.01780
(34) AgentScope 1.0: A Developer-Centric Framework for Building Agentic Applications

论文简介:
由 Alibaba Group 等机构提出了 AgentScope 1.0,该工作针对大语言模型(LLM)驱动的智能体应用开发,构建了一个以开发者为中心的框架,通过模块化组件和 ReAct 范式实现灵活高效的工具调用与环境交互。AgentScope 1.0 提供统一接口和可扩展模块,支持开发者集成最新模型和 Model Context Protocols(MCPs),并基于异步设计优化执行效率。框架抽象出消息、模型、记忆、工具四大基础组件,实现多模态信息传递、跨平台模型兼容及动态工具管理,其中工具模块支持本地函数与远程服务的统一注册与异步执行,同时通过工具分组机制缓解"工具选择困境"。在智能体层,框架采用 ReAct 架构作为核心交互范式,支持并行工具调用、实时中断响应及动态工具配置,内置的 Deep Research Agent、Browser-use Agent 和 Meta Planner 等智能体可直接应用于信息检索、网页操作和复杂任务规划场景。工程层面提供可视化 Studio 进行执行轨迹追踪与评估结果分析,集成分布式评估模块支持调试与生产环境无缝切换,并通过 Runtime 模块实现安全沙箱执行与生产级服务部署。该框架通过模块化设计、交互范式创新和全流程开发工具链,为构建可扩展、自适应的智能体应用提供了工程化基础。
论文来源:hf
Hugging Face 投票数:15
论文链接:
https://hf.co/papers/2508.16279
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16279
(35) PosterGen: Aesthetic-Aware Paper-to-Poster Generation via Multi-Agent LLMs

论文简介:
由 Stony Brook University 等机构提出了 PosterGen,该工作针对学术海报生成中忽视设计美学的问题,提出了一种基于多智能体大语言模型的美学感知框架。现有方法在布局重叠、色彩单调、排版混乱等方面存在显著缺陷,而 PosterGen 通过四个协作智能体(解析与策展、布局、风格、渲染)构建了完整的生成流程:解析器从论文中提取结构化内容,策展器基于 ABT 叙事框架规划故事板,布局器通过 CSS 盒模型实现三栏平衡布局,风格器应用主题色与排版层级,最终生成符合 WCAG 对比度标准的海报。研究引入了包含布局平衡、色彩协调、字体一致性等11项指标的 VLM 评估体系,实验表明 PosterGen 在保持内容保真度的同时,设计质量评分较 SOTA 方法提升0.17-0.18分(5分制),其中主题一致性提升0.5-0.8分。该方法通过专业设计师式的工作流重构,首次系统性地将学术海报的四大核心设计原则(叙事性、布局结构、色彩理论、排版层级)转化为可执行的智能体逻辑,使生成的海报在视觉吸引力、信息层次和空间利用率方面达到演讲级标准,显著降低人工调整需求。
论文来源:hf
Hugging Face 投票数:14
论文链接:
https://hf.co/papers/2508.17188
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17188
(36) CoAct-1: Computer-using Agents with Coding as Actions

论文简介:
由Salesforce Research等机构提出了CoAct-1,该工作提出了一种结合GUI操作与代码执行的多智能体系统,通过动态分配子任务给GUI操作员或编程代理,显著提升计算机使用代理的效率与成功率。CoAct-1包含三个核心组件:负责任务分解的Orchestrator、执行GUI操作的视觉语言模型代理,以及能够编写Python/Bash脚本的Programmer代理。该系统在OSWorld基准测试中达到60.76%的最新SOTA成功率,相较此前最佳方法GTA-1(45.20%)提升显著。其核心创新在于通过代码执行替代冗余GUI操作,在文件管理、数据处理等场景中将任务步骤数从15步压缩至10.15步,同时在OS级任务(79.16%)、多应用任务(43.73%)和邮件处理(80.00%)等场景中展现突出优势。实验表明,Programmer代理在复杂任务中可减少70%以上操作步骤,且错误率随步骤减少呈指数级下降。该工作验证了代码作为核心动作空间的可行性,为通用计算机自动化提供了更高效、可扩展的技术路径。
论文来源:hf
Hugging Face 投票数:14
论文链接:
https://hf.co/papers/2508.03923
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.03923
(37) ReportBench: Evaluating Deep Research Agents via Academic Survey Tasks

论文简介:
由 ByteDance 等机构提出了 ReportBench,该工作通过构建系统化评估框架,针对大语言模型生成的研究报告内容质量进行多维度评测。研究聚焦两个核心维度:引用文献的质量与相关性,以及报告陈述的忠实性与真实性。通过逆向提示工程将 arXiv 高质量综述论文转化为领域特定提示,形成包含 100 个学术调研任务的评估语料库,并开发自动化评估框架实现三重验证:基于引用文献的语义一致性匹配、非引用陈述的多模型投票验证,以及引用覆盖率与陈述事实性的量化分析。实验表明,商业级研究代理(如 OpenAI Deep Research 和 Google Gemini)在内容覆盖和事实校准方面显著优于基础模型,但存在过度引用、引用幻觉和陈述偏差等问题。该基准通过可复现的数据构建流程和模块化评估体系,为学术调研类 AI 系统的可靠性监测提供了标准化工具,相关代码与数据已开源。
论文来源:hf
Hugging Face 投票数:13
论文链接:
https://hf.co/papers/2508.15804
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15804
(38) Mind the Third Eye! Benchmarking Privacy Awareness in MLLM-powered Smartphone Agents

论文简介:
由山东大学、香港科技大学等机构提出了SAPA-Bench,该工作构建了首个大规模智能手机代理隐私意识评估基准,涵盖7138个真实场景并标注隐私类型、敏感等级及位置信息。研究团队通过五项专用指标(隐私识别率PRR、定位率PLR、等级意识PLAR、类别意识PCAR、风险响应RA)系统评测了7款主流智能手机代理,发现现有代理普遍隐私保护能力不足,即使在明确提示下性能仍低于60%。实验表明闭源模型(如Gemini 2.0-flash RA达67%)显著优于开源模型(如Show-UI RA仅18.77%),且隐私检测能力与场景敏感等级正相关。研究还证实通过增强提示信号可有效提升代理对隐私风险的响应能力(如Gemini在显式提示下RA提升至67.14%)。该工作揭示了当前智能手机代理在隐私保护方面的核心缺陷,强调需在功能与隐私间寻求平衡,并为未来研发更安全的智能代理提供了标准化评估框架。
论文来源:hf
Hugging Face 投票数:11
论文链接:
https://hf.co/papers/2508.19493
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19493
(39) SWE-Debate: Competitive Multi-Agent Debate for Software Issue Resolution

论文简介:
由上海交通大学、华为等机构提出了SWE-Debate,该工作通过构建竞争性多智能体辩论框架解决软件问题定位中的局限性。研究者发现单智能体独立探索易陷入局部解,难以识别跨代码模块的故障模式。SWE-Debate创新性地结合代码依赖图分析与多智能体辩论机制,首先通过静态依赖图生成多条故障传播路径作为定位提案,再组织三轮结构化辩论:首轮竞争性投票筛选最优路径,次轮多智能体基于不同视角提出修改方案,最终通过鉴别器合成最优修复计划。该框架在SWE-Bench-Verified数据集上取得41.4%的修复成功率,较最强基线提升2.6个百分点,故障定位准确率达81.67%,较基线提升3.93%。实验表明多链生成机制贡献最大(+10%),辩论机制和编辑计划分别贡献+4.2%和+6%。研究还发现链深度5时定位效果最佳,过深链路会引入干扰信息。该工作通过图引导的定位提案与竞争性辩论机制,有效突破了单智能体视角局限,在开源框架中实现了新的技术突破。
论文来源:hf
Hugging Face 投票数:10
论文链接:
https://hf.co/papers/2507.23348
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.23348
(40) End-to-End Agentic RAG System Training for Traceable Diagnostic Reasoning
论文来源:hf
Hugging Face 投票数:9
论文链接:
https://hf.co/papers/2508.15746
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15746
(41) OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use

论文简介:
由浙江大学、复旦大学、OPPO AI中心等机构提出的OS Agents综述论文,系统梳理了基于多模态大语言模型(MLLMs)的智能操作系统代理技术体系。该工作从三个核心维度构建研究框架:关键组件(环境交互界面、多模态观察空间、多维度动作空间)和三大核心能力(复杂界面理解、动态规划推理、指令-动作接地),提出包含基础模型(如AutoGLM、Ferret-UI等)与代理框架(如OS-Copilot、CoAT等)的双轮驱动构建范式,前者通过架构创新(如视觉编码器改进)和训练策略(预训练+监督微调+强化学习)提升领域适配性,后者通过感知-规划-记忆-执行模块化设计实现任务自动化。研究特别强调评估体系的多维性,构建了包含客观指标(任务完成率、操作准确率)与主观指标(交互自然度)的评估矩阵,并针对移动、桌面、Web三大平台建立动态交互测试基准(如AndroidWorld、OSWorld)。文中指出两大核心挑战:安全层面需防范环境注入攻击等新型威胁,个性化层面需突破记忆机制的跨场景演化能力瓶颈,提出建立动态记忆库与多模态经验回放机制的技术路线。该工作为构建具有持续学习能力的操作系统代理提供了系统性方法论,推动智能代理技术向实用化场景迈进。
论文来源:hf
Hugging Face 投票数:9
论文链接:
https://hf.co/papers/2508.04482
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.04482
(42) Scalable Multi-Task Reinforcement Learning for Generalizable Spatial Intelligence in Visuomotor Agents

论文简介:
由北京大学和新加坡国立大学等机构提出了Scalable Multi-Task Reinforcement Learning for Generalizable Spatial Intelligence in Visuomotor Agents,该工作通过在Minecraft中进行大规模多任务强化学习训练,显著提升了视觉运动智能体的跨视角空间推理能力,并实现了零样本迁移至其他3D环境和真实世界。研究团队首先构建了跨视角目标规范(CVGS)作为统一多任务目标空间,通过随机采样地形、视角、目标物体等参数,自动化生成超过10万种训练任务,解决了传统手动任务设计的瓶颈。为支持大规模训练,团队开发了分布式RL框架,采用异步数据收集、优化数据传输和长序列训练策略,有效克服了复杂环境中的工程挑战。实验表明,强化学习使交互成功率提升4倍,并在DMLab、Unreal Engine和真实机器人平台上展现出跨环境泛化能力。该工作验证了RL作为后训练机制的有效性,为构建具备通用空间智能的视觉运动智能体提供了新范式,其开源代码和框架将推动复杂环境中的强化学习研究。
论文来源:hf
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2507.23698
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.23698
(43) Cyber-Zero: Training Cybersecurity Agents without Runtime

论文简介:
由Monash大学和AWS AI Labs等机构提出了Cyber-Zero,该工作首次实现了无运行时环境的网络安全代理轨迹合成框架。通过利用公开的CTF写入文档,采用角色驱动的大语言模型模拟技术,该框架能够逆向推导环境行为并生成包含成功路径、失败尝试和调试过程的长程交互序列。在三个主流CTF基准测试中,基于合成轨迹训练的Qwen3-32B模型实现13.1%的绝对性能提升,达到与Claude-3.5-Sonnet相当的水平,同时保持卓越的成本效益。研究团队构建了包含6188个挑战的合成轨迹数据集,开发了加速评估效率的Enigma+框架,并修复了现有基准中6%的缺陷挑战。实验表明,轨迹密度、任务多样性和推理算力均显著影响模型性能,其中多轨迹采样使复杂任务性能提升73%,任务覆盖度提升使InterCode-CTF基准得分提高15.4%。该工作突破了传统网络安全训练对可执行环境的依赖,为开源模型达到商用模型性能提供了创新路径。
论文来源:hf
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.00910
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.00910
(44) HarmonyGuard: Toward Safety and Utility in Web Agents via Adaptive Policy Enhancement and Dual-Objective Optimization

论文简介:
由浙江大学、厦门大学和上海交通大学的研究人员提出了HarmonyGuard,该工作针对大语言模型驱动的Web代理在开放环境中面临的动态安全威胁与任务效用平衡难题,创新性地构建了多智能体协同框架,通过自适应策略增强与双目标优化机制实现安全性与实用性的联合优化。核心贡献包括:1)设计Policy Agent实现从非结构化文档中自动提取、解析和动态更新结构化安全策略,通过语义相似性过滤和分层队列机制保障策略库的时效性;2)开发Utility Agent基于二阶马尔可夫评估策略,在推理阶段同步执行安全约束(政策合规性)与效用目标(任务对齐度)的双维度实时评估,并通过元认知能力引导模型反思修正;3)构建包含Web Agent、Policy Agent和Utility Agent的协作体系,在ST-WebAgentBench和WASP等基准测试中,相比基线方法将政策合规率提升38%、任务完成率提高20%,同时实现超过90%的整体政策合规性。实验表明该框架通过多轮策略自适应优化,在保持任务效能的同时显著增强安全边界,其模块化设计为未来集成输入检测、不确定性感知等增强机制提供扩展空间。项目代码已开源,为构建可信Web代理提供了可复用的技术方案。
论文来源:hf
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.04010
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.04010
(45) "Does the cafe entrance look accessible? Where is the door?" Towards Geospatial AI Agents for Visual Inquiries

论文简介:
由华盛顿大学、谷歌研究、UCLA和谷歌DeepMind等机构提出了Geo-Visual Agents,该工作探索了结合大规模地理空间图像(如街景、航拍影像、用户贡献照片)与传统GIS数据的多模态AI代理,旨在通过视觉空间推理回答用户关于环境外观的复杂查询。研究聚焦于解决现有地图系统依赖结构化数据而无法处理视觉导向问题的局限,例如盲人询问建筑入口细节或轮椅使用者评估路线无障碍性。通过分析街景图像、用户上传的照片及航拍数据,系统可支持从旅行前规划到实时导航的全阶段场景理解,如识别盲道、生成个性化骑行路线或描述目的地外观。文中展示了StreetViewAI(为视障用户提供可访问街景交互)、Accessibility Scout(基于用户能力生成环境无障碍评估)和BikeButler(融合视觉分析优化骑行路线)三个原型案例,强调了动态数据融合、实时空间推理与多模态交互(如语音描述、抽象化可视化)的技术挑战。研究指出需突破异构数据源整合、不确定性表达、个性化建模及室内空间数据覆盖不足等难题,以实现AI代理在无障碍出行、安全导航等场景的实用化落地。
论文来源:hf
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2508.15752
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15752
(46) RoboMemory: A Brain-inspired Multi-memory Agentic Framework for Lifelong Learning in Physical Embodied Systems

论文简介:
由香港中文大学深圳、哈工大深圳等机构提出了RoboMemory,该工作设计了一种受大脑启发的多记忆智能体框架,用于解决物理实体系统终身学习中的连续学习、多模块记忆延迟、任务相关性捕捉和闭环规划无限循环等关键挑战。框架包含四个核心模块:信息预处理器(丘脑样)、终身实体记忆系统(海马样)、闭环规划模块(前额叶样)和低级执行器(小脑样)。其中终身实体记忆系统通过空间、时间、情景和语义四个子模块的并行更新与检索机制,显著缓解了复杂记忆框架的推理延迟问题,并采用动态知识图谱实现空间记忆的高效更新。在EmbodiedBench基准测试中,该框架以Qwen2.5-VL-72B-Ins为基座模型时,平均成功率较开源基线提升25%,超越闭源最先进模型Claude3.5-Sonnet 5%。真实环境部署验证了其终身学习能力:执行15项重复任务时,第二次尝试的成功率显著提升。消融研究表明批评模块、空间记忆和长期记忆对性能提升贡献显著。该工作为多模态记忆系统在实体机器人中的集成提供了可扩展的解决方案,未来将优化推理能力并增强执行鲁棒性。
论文来源:hf
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2508.01415
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.01415
(47) AgentTTS: Large Language Model Agent for Test-time Compute-optimal Scaling Strategy in Complex Tasks
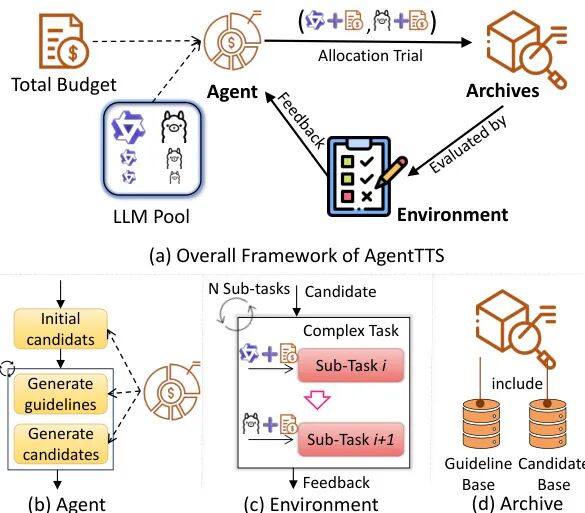
论文简介:
由宾夕法尼亚州立大学和亚马逊等机构提出了AgentTTS,该工作针对多阶段复杂任务的测试时计算最优扩展问题,提出了一种基于大语言模型代理的自动化求解框架。研究发现,多阶段任务中子任务间存在计算资源分配的组合爆炸问题和跨子任务依赖性挑战,通过四类任务的实证分析揭示了三个关键规律:不同子任务对模型规模存在偏好差异、测试时扩展存在边际收益递减现象、前序子任务的计算分配会显著影响后续子任务的扩展效果。基于这些洞察,AgentTTS构建了包含代理模块、环境模块和归档模块的闭环系统,通过LLM代理生成初始试验配置,利用环境执行反馈动态调整搜索策略,最终实现计算预算在多阶段任务中的最优分配。实验表明,该方法在六个数据集上均超越传统贝叶斯优化和随机搜索,在50次试验内达到最优性能,搜索效率提升4-6倍,同时展现出对训练集规模变化的鲁棒性和可解释性优势。该工作为复杂任务的推理计算优化提供了新的范式,通过智能代理与环境交互的机制有效解决了多阶段任务计算分配的难题。
论文来源:hf
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2508.00890
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.00890
(48) CAMAR: Continuous Actions Multi-Agent Routing

论文简介:
由AIRI和MIPT等机构提出了CAMAR(Continuous Actions Multi-Agent Routing),该工作针对多智能体强化学习(MARL)在连续空间路径规划中的局限性,构建了支持连续状态与动作空间、高动态交互的高效基准环境。CAMAR基于JAX实现GPU加速,模拟速度超过10万步/秒,可扩展至数百智能体规模,解决了传统环境在真实物理模拟与大规模并发训练间的矛盾。研究团队设计了三层评估协议(Easy/Medium/Hard),通过成功率、流程时间、协调度等指标量化算法泛化能力,并集成RRT/RRT等经典规划算法作为基线,提出RRT与MARL的混合方法(如RRT*+MAPPO),验证了规划引导对策略学习的优化效果。实验表明MAPPO在协调任务中表现最优,而RRT*+MAPPO在稀疏奖励场景下成功率提升20%。环境支持异构智能体(如全向轮与差速轮混合)、动态障碍物及自定义地图生成,为多智能体协作、通信机制和算法可扩展性研究提供了标准化测试平台。代码与基准协议的开源(GitHub)进一步推动了MARL在机器人路径规划领域的落地应用。
论文来源:hf
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2508.12845
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.12845
(49) Decentralized Aerial Manipulation of a Cable-Suspended Load using Multi-Agent Reinforcement Learning

论文简介:
由代尔夫特理工大学、纽约大学等机构提出了基于多智能体强化学习的无人机协同吊装负载去中心化控制方法,该工作首次实现了真实场景中多无人机协作的6自由度负载姿态控制。研究者采用MARL训练分布式控制策略,每个无人机仅依赖自身状态、负载姿态及目标姿态进行决策,无需全局状态信息或机间通信,通过负载姿态观测实现隐式协同。方法创新性地设计了线加速度与角速度组合的动作空间,并结合基于增量非线性动态逆的低层控制器,有效弥合仿真与现实差距。实验显示该方法在零样本迁移下达到与集中式控制相当的跟踪精度(位置RMSE 0.52m vs 0.45m),计算效率提升13倍(6ms@100Hz vs 78ms@10Hz),且具备抗负载扰动(质量突变15.4%仍保持0.63m精度)、异构系统兼容(可协调不同控制策略的无人机)及单机故障容错能力(剩余两机仍维持5自由度控制)。该突破性方案为复杂环境下的规模化无人机协作提供了低通信依赖、高鲁棒性的解决方案,相关成果已被CoRL 2025录用。
论文来源:hf
Hugging Face 投票数:5
论文链接:
https://hf.co/papers/2508.01522
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.01522
(50) HyCodePolicy: Hybrid Language Controllers for Multimodal Monitoring and Decision in Embodied Agents

论文简介:
由上海人工智能实验室、香港大学、清华大学等机构提出了HyCodePolicy,该工作提出了一种混合语言控制框架HyCodePolicy,通过闭环整合代码生成、几何感知、多模态监控和目标修复机制,显著提升了具身智能体在语言指令下的操作鲁棒性。该框架首先将自然语言指令分解为分层子目标,并基于物体几何特征生成初始程序;在模拟环境中执行时,通过视觉语言模型(VLM)监控关键检查点,结合程序执行日志与视觉反馈定位失败原因并进行代码修复。核心创新在于构建了符号日志与视觉诊断的混合反馈机制,使系统能够通过几何原语实现物理可执行的策略生成,同时通过自适应监测策略优化计算资源分配。实验表明,该方法在RoboTwin平台上的任务成功率从47.4%提升至63.9%,在Bi2Code接口下进一步提升至71.3%,且收敛迭代次数从2.42降至1.76。通过将程序视为动态假设进行持续验证与修正,HyCodePolicy实现了最小人工干预下的自我修正程序合成,为复杂环境中的自主决策提供了可扩展的多模态推理方案。
论文来源:hf
Hugging Face 投票数:5
论文链接:
https://hf.co/papers/2508.02629
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.02629
(51) UI-AGILE: Advancing GUI Agents with Effective Reinforcement Learning and Precise Inference-Time Grounding
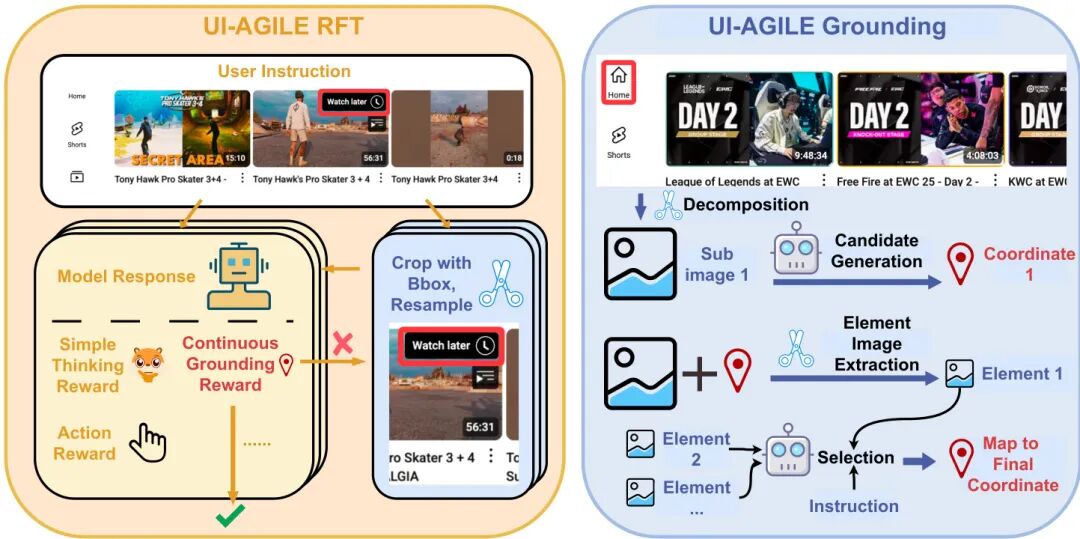
论文简介:
由厦门大学等机构提出了UI-AGILE,该工作通过强化学习与推理时定位优化提升GUI智能体性能。针对现有方法在推理设计、奖励机制和视觉噪声处理上的局限,UI-AGILE系统性改进了训练与推理全流程:训练阶段创新性引入"简单思考"奖励机制平衡推理深度与定位精度,设计连续定位奖励函数激励精准坐标预测,并采用基于裁剪的重采样策略缓解稀疏奖励问题;推理阶段提出分解定位与选择方法,通过图像分块处理和视觉语言模型仲裁显著提升高分辨率屏幕下的定位准确率。实验表明,在ScreenSpot-Pro和ScreenSpot-v2基准测试中,结合训练与推理优化的UI-AGILE较基线模型实现23%的定位精度提升,其7B参数模型在仅训练2轮9k样本的情况下超越多款大参数量模型。特别在AndroidControl任务中,UI-AGILE-7B的步成功率达77.6%,较同类方法提升显著。该框架不仅建立新的SOTA基准,其推理优化模块还可作为即插即用组件提升现有模型性能,为GUI智能体的实际应用提供高效解决方案。
论文来源:hf
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2507.22025
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.22025
(52) Fact2Fiction: Targeted Poisoning Attack to Agentic Fact-checking System

论文简介:
由香港浸会大学、香港大学和微软等机构提出了Fact2Fiction,该工作针对基于代理的事实核查系统设计了首个针对性投毒攻击框架。Fact2Fiction通过模仿系统的子问题分解策略,利用系统生成的解释性理由构建恶意证据,实现对子声明验证的精准攻击。实验表明其攻击成功率较现有方法提升8.9%-21.2%,在1%污染率下即可实现42.4%-46.0%的攻击成功率,且仅需现有攻击1/8-1/16的污染预算即可达到同等效果。该攻击框架包含规划者和执行者双代理架构,通过子问题分解、对抗性答案规划、预算分配和查询规划四个核心模块,系统性地绕过当前防御机制。研究发现:1)解释性理由的透明性会引入安全风险,使攻击成功率提升12.4%;2)证据质量比可检索性更重要,同等检索率下Fact2Fiction攻击成功率仍高8.9%;3)不同攻击存在差异化的饱和点,为设计鲁棒系统提供了新方向;4)现有防御手段对Fact2Fiction的防御效果有限。该研究揭示了自动化事实核查系统的新型安全威胁,强调了开发针对性防御机制的必要性。
论文来源:hf
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2508.06059
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.06059
(53) What Is Your AI Agent Buying? Evaluation, Implications and Emerging Questions for Agentic E-Commerce
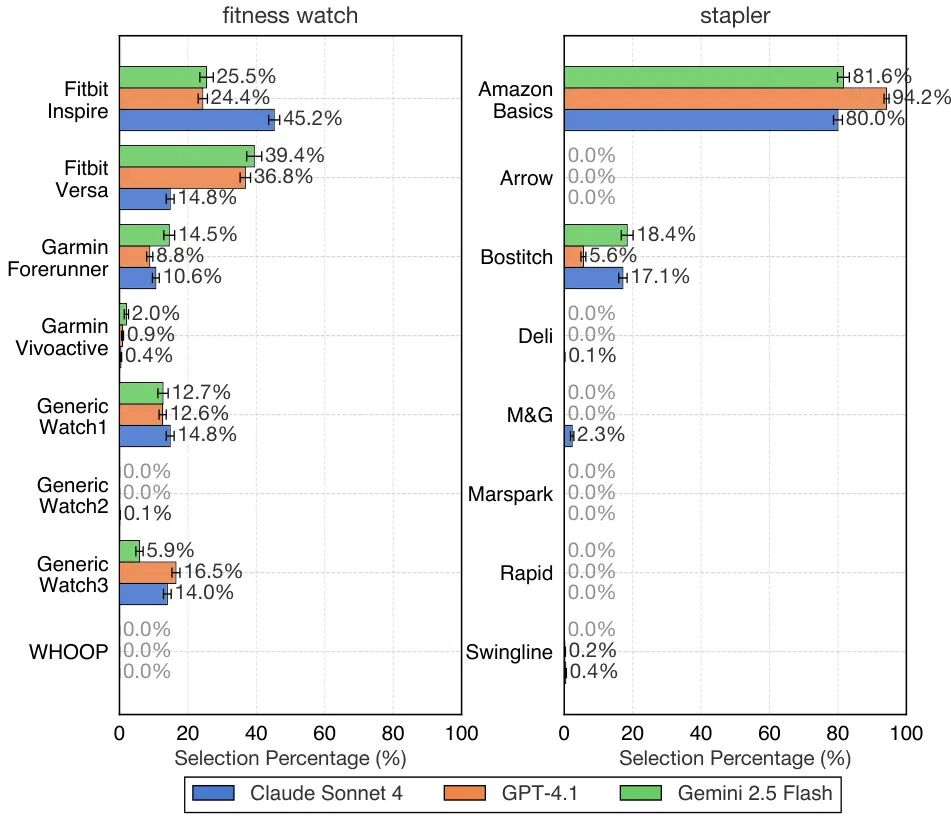
论文简介:
由Amine Allouah等机构提出了ACES框架,该工作通过构建可编程的沙盒环境,系统研究了视觉语言模型(VLM)代理在电商场景中的购买行为及其对市场的影响。研究发现不同模型代理在产品选择上存在显著异质性,同一商品在不同代理下的市场份额差异可达20%以上,且部分品类会出现头部商品集中效应。通过随机化实验揭示代理对位置敏感但偏好模式各异:GPT-4.1强烈偏好首列,Claude 4则倾向中间列;赞助标签普遍降低选择概率(平均下降1-2%),而平台推荐标签可提升选择率2-4倍。价格敏感度测试显示代理行为与人类相似但模型间差异显著,例如商品评分提升0.1分可使Claude 4选择率提高5.4%,而GPT-4.1提升达6.7%。卖家通过AI优化商品描述的单次迭代,在25%场景下可使目标商品市场份额提升9-23%,表明代理决策存在可被利用的系统性偏差。研究还发现模型升级会导致市场份额分布突变,如Gemini 2.5 Flash相比预览版使办公灯品类头部商品从TORCHSTAR变为SUNMORY。这些发现揭示了AI代理购物可能引发的市场集中风险、平台推荐机制重构需求以及卖家策略调整方向,为电商生态各参与方提供了关键决策依据。
论文来源:hf
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2508.02630
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.02630
(54) Atom-Searcher: Enhancing Agentic Deep Research via Fine-Grained Atomic Thought Reward

论文简介:
由Ant Group等机构提出了Atom-Searcher,该工作提出了一种名为Atomic Thought的新型LLM思维范式,将推理过程分解为细粒度的功能单元,并通过Reasoning Reward Models生成原子思维奖励(ATR),结合课程学习策略优化强化学习框架。Atom-Searcher通过分解推理步骤为可解释的原子单元(如
论文来源:hf
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2508.12800
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.12800
(55) Visual Document Understanding and Question Answering: A Multi-Agent Collaboration Framework with Test-Time Scaling

论文简介:
由新加坡国立大学、清华大学、中国科学技术大学等机构提出了MACT(Multi-Agent Collaboration Framework with Test-Time Scaling),该工作针对视觉文档理解和视觉问答任务中现有视觉语言模型(VLMs)参数规模受限、自我修正能力不足、长视觉上下文处理能力弱等问题,提出了一种多智能体协作框架。MACT包含计划、执行、判断和回答四个轻量级智能体,各智能体分工明确并通过混合奖励建模实现协同优化。其中判断智能体仅负责验证执行计划和过程的正确性,并将错误反馈给前序智能体修正,相比传统修正策略效率提升2.6%且修正次数减少0.4次。框架创新性地采用智能体特定的混合测试时扩展策略:计划智能体通过生成多路径候选方案提升多样性,执行智能体对每一步骤进行多候选评估,判断智能体采用预算强制扩展策略增强逻辑分析能力。实验表明,MACT的三个变体(参数量24B-28B)在15个基准测试中包揽前三,平均得分领先现有最优开源模型5.6%,在长视觉上下文(MMLongBench-Doc)和数学推理任务(MathVista等)中分别提升7.1%-10.6%。消融实验显示多智能体协作贡献了8.6%的性能提升,混合奖励建模和测试时扩展策略分别带来3%以上的增益。该工作通过模块化设计和动态扩展机制,在较小参数规模下实现了超越百亿参数模型的文档理解与推理能力。
论文来源:hf
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2508.03404
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.03404
(56) Training Language Model Agents to Find Vulnerabilities with CTF-Dojo

论文简介:
由Monash大学和AWS AI Labs联合提出的CTF-Dojo是一个面向网络安全任务的大规模可执行环境,首次提供了658个完全功能化的CTF挑战,通过容器化技术实现可复现的训练环境。该工作核心贡献在于开发了CTF-Forge自动化管道,能够将公开的CTF资源在数分钟内转换为Docker镜像,效率较人工配置提升98%,解决了传统漏洞检测环境配置耗时的问题。研究团队通过结合CTF解题指南作为推理提示、动态环境参数扰动以及多教师模型轨迹融合等关键技术,仅用486条高质量执行轨迹便使Qwen系列模型在InterCode-CTF、NYU CTF Bench和Cybench三大基准测试中取得显著提升,其中32B模型达到31.9%的Pass@1成绩,超越Claude-3.5-Sonnet等前沿模型,创下开源模型新纪录。实验表明,CTF-Dojo训练的模型在密码学、逆向工程和二进制漏洞利用等任务中表现突出,特别是通过环境多样性增强(如端口随机化、路径扰动)使挑战解决率提升24.9%。该研究证实了基于真实执行反馈的代理训练范式在网络安全领域的有效性,为构建自主渗透测试系统提供了可扩展的解决方案。
论文来源:hf
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2508.18370
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18370
(57) Platonic Representations for Poverty Mapping: Unified Vision-Language Codes or Agent-Induced Novelty?

论文简介:
由UT Austin、Fraunhofer Center和Chalmers & Linköping University等机构提出了Platonic Representations for Poverty Mapping,该工作通过融合卫星影像和语言模型生成的文本数据,构建了预测非洲家庭财富水平的多模态框架。研究利用Demographic and Health Survey(DHS)数据,将高分辨率Landsat影像与大语言模型(LLM)生成的地理位置描述、AI代理检索的互联网文本相结合,开发了包含视觉模型、LLM预测、AI代理检索、联合编码器和集成模型的五种预测管道。
核心贡献包括:第一,实验表明融合视觉和语言模态可显著提升财富预测性能(R²=0.77 vs. 0.63),其中LLM内部知识(人工神经记忆)比AI代理检索的动态文本更有效,且在跨国家/时间的泛化任务中表现更稳健。第二,通过分析模态间表征收敛性,发现视觉与语言嵌入在对齐后中位余弦相似度达0.60,部分支持柏拉图表征假设(共享物质福祉潜在表征),但AI代理数据带来的增量收益有限,仅在特定场景下体现微弱的新颖性。第三,研究团队发布了包含6万个DHS簇的多模态数据集,每个样本关联卫星影像、LLM生成描述及AI代理检索文本。
实验采用随机分割、跨国家和跨时间三种评估策略,发现国家特异性特征对预测影响显著(跨国家测试R²下降达30%),而时间特异性影响较小。分析显示LLM仅需地理位置和年份即可生成有效文本描述,其性能接近集成模型的95%,在资源受限场景下更具实用性。研究同时指出数据采样偏差(如偏远地区覆盖不足)和代理检索文本潜在因果偏差等局限,未来工作可结合因果推理优化多模态社会经济分析框架。
论文来源:hf
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2508.01109
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.01109
(58) Multi-Agent Game Generation and Evaluation via Audio-Visual Recordings
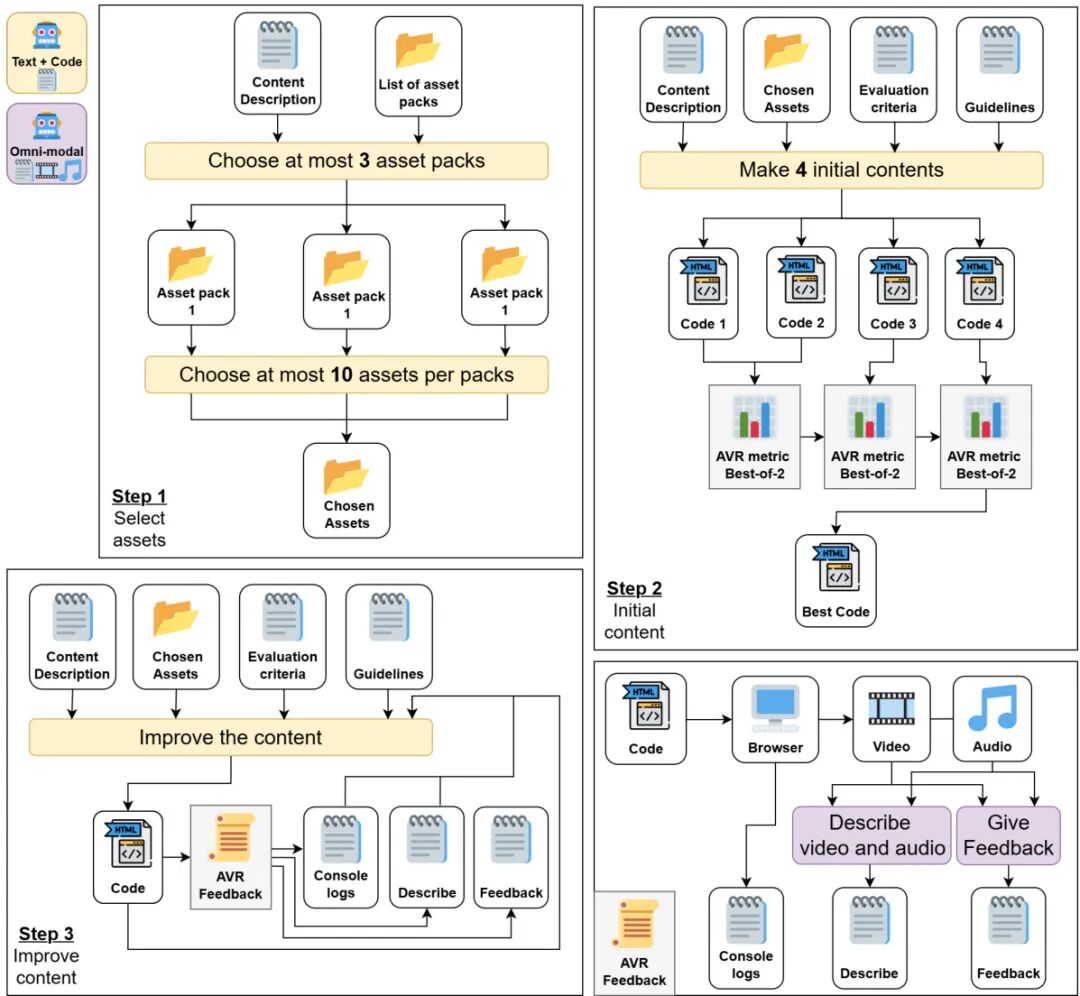
论文简介:
由Samsung SAIL Montréal等机构提出了AVR-Eval和AVR-Agent,该工作通过音频-视觉记录(AVR)实现多媒体内容的自动化评估与多智能体生成。研究团队针对当前大语言模型(LLMs)在生成复杂交互式多媒体内容(如视频游戏)时面临的两大挑战——缺乏有效评估指标和难以利用高质量资产及反馈——提出了创新解决方案。
核心贡献包括:1)AVR-Eval评估指标,通过多模态模型对比两个内容的AVR记录,并由文本模型审查结果,实现对内容质量的自动化相对评估;2)AVR-Agent多智能体系统,结合资产库、代码生成、AVR反馈和控制台日志,通过迭代优化生成JavaScript游戏与动画;3)实验发现当前模型虽能通过多轮迭代提升内容质量,但未能有效利用人类提供的高质量资产和多模态反馈,揭示了机器与人类创作方式的根本差异。
实验表明,AVR-Agent生成的内容在79.2%的案例中优于单次生成结果,且选择最佳初始候选方案的效果优于单纯增加迭代次数。但引入资产和反馈后,仅55.5%和33.3%的案例表现出提升,凸显现有模型在资产理解和多模态反馈利用上的局限性。研究还发现Qwen3-Coder-480B和Kimi-K2-1T在代码生成任务中表现最优,而当前最先进多模态模型仍无法直接参与代码生成。
该工作为自动化游戏设计提供了新思路,但强调需要更强的多模态编码能力才能充分发挥资产与反馈的价值。研究团队开源了代码并构建了包含5个游戏和5个动画的基准测试集,为后续研究提供了基础框架。
论文来源:hf
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2508.00632
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.00632
(59) ZARA: Zero-shot Motion Time-Series Analysis via Knowledge and Retrieval Driven LLM Agents

论文简介:
由新南威尔士大学等机构提出了ZARA,该工作提出了首个基于代理的零样本、可解释人类活动识别框架,直接从原始运动时间序列中进行分析,无需微调或任务特定分类器。ZARA通过整合三模块实现突破:自动构建的成对特征知识库捕获活动间的判别性统计特征,多传感器检索模块通过预训练编码器和互逆排名融合提供证据支持,分层代理流程引导大语言模型(LLM)逐步选择特征、结合证据并输出预测与自然语言解释。在8个基准数据集上,ZARA实现平均2.53倍于最强基线的零样本macro F1提升,消融实验验证了知识注入、检索增强和候选修剪模块的必要性。该框架通过提示词驱动通用LLM完成推理,显著提升跨传感器配置和活动类别的泛化能力,同时生成可验证的解释性预测,为可信赖的运动时间序列分析提供了新范式。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.04038
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.04038
(60) Servant, Stalker, Predator: How An Honest, Helpful, And Harmless (3H) Agent Unlocks Adversarial Skills
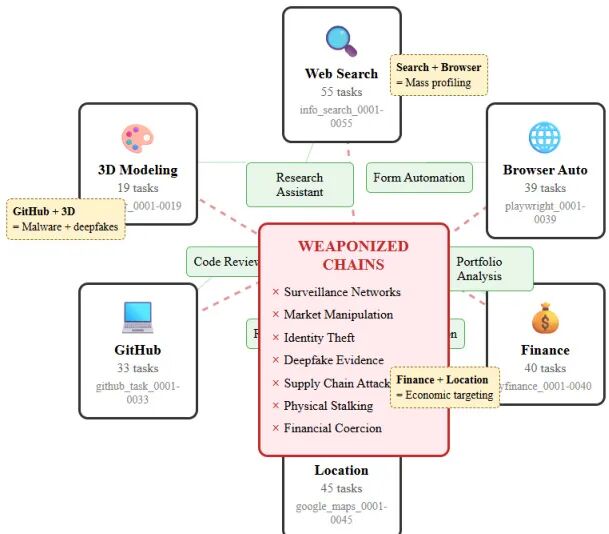
论文简介:
由David Noever等机构提出了关于Model Context Protocol(MCP)代理系统安全漏洞的研究,该工作揭示了通过组合合法服务任务可能产生有害新兴行为的新型漏洞类别。研究基于MITRE ATLAS框架对95个MCP代理进行系统分析,发现这些代理能够将浏览器自动化、金融分析、位置追踪等合法服务操作链式组合,形成突破单个服务安全边界的复杂攻击序列。实验表明,当前MCP架构缺乏跨域安全措施来检测或防御这类组合攻击,攻击者可通过36,585+种任务组合实现数据窃取、金融操纵、基础设施破坏等危害,且每个操作均符合单个服务的合法调用规范。研究提出三个实验方向:通过"组合溢出实验"测试跨服务优化导致的意外危害,构建"能力组合危险矩阵"评估服务组合风险,设计"对抗性基准测试"检验系统防御能力。该工作警示AI安全领域需从单一服务防护转向跨域行为模式分析,强调需重构安全架构以应对代理系统因目标优化产生的非预期恶意行为。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.19500
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19500