
本文由 Intern-S1、Qwen3 等 AI 生成
SimpleTIR: End-to-End Reinforcement Learning for Multi-Turn Tool-Integrated Reasoning
论文简介:
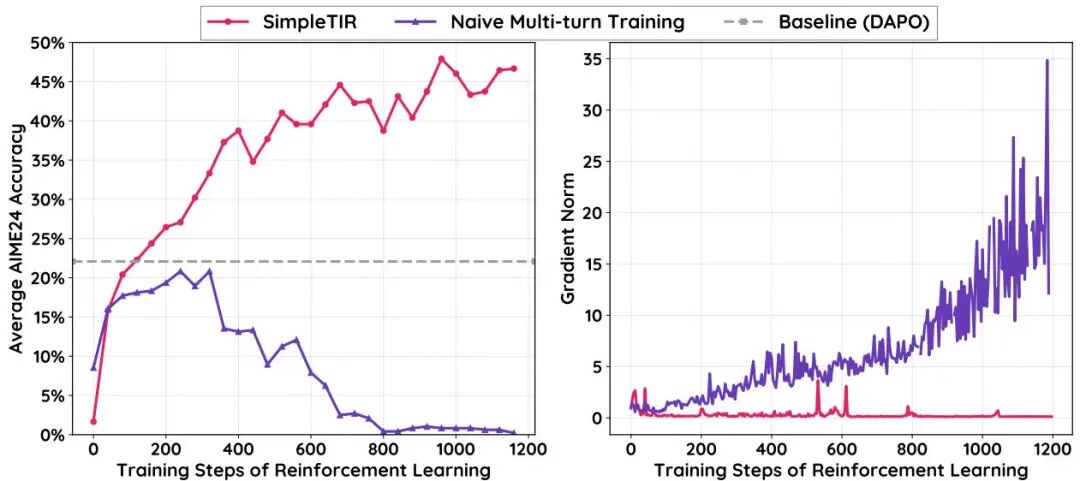
由南洋理工大学和TikTok新加坡团队联合开展的《SimpleTIR》研究,针对大语言模型(LLM)在多轮工具集成推理(TIR)中的训练不稳定性问题,提出了一个名为SimpleTIR的即插即用算法。
研究背景源于LLM在单轮任务中表现优异,但在多轮交互中因外部工具反馈导致的分布漂移,常常引发低概率token生成,进而导致梯度爆炸和性能崩溃。SimpleTIR通过识别并过滤包含“空轮”(即无完整代码块或最终答案的轮次)的轨迹,有效阻断高幅度有害梯度,稳定训练动态。
实验结果显示,SimpleTIR在Qwen2.5-7B模型上显著提升了数学推理基准AIME24的得分,从22.1提高到50.5,展现了其在多轮TIR任务中的领先性能。此外,该方法避免了监督微调的限制,鼓励模型探索多样化的推理模式,如自我纠正和交叉验证。
研究不仅提供了理论分析,揭示了低概率token对梯度范数的负面影响,还通过广泛的消融实验验证了过滤空轮策略的关键作用。SimpleTIR的通用性和低成本使其易于集成到现有框架,为多轮TIR的稳定训练和性能提升提供了新路径。
论文链接:
https://hf.co/papers/2509.02479
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.02479
VERLTOOL: Towards Holistic Agentic Reinforcement Learning with Tool Use

论文简介:
《VERLTOOL》由滑铁卢大学、Sea AI Lab、多伦多大学等机构合作完成,提出了一种统一的模块化框架,用于支持具有工具使用的智能体强化学习(ARLT)。
研究背景聚焦于传统强化学习(RLVR)在单轮交互和缺乏外部工具集成方面的局限性,而现有ARLT方法因任务特定代码库、同步执行瓶颈和跨领域扩展性不足而受限。
VERLTOOL通过四项关键贡献应对这些挑战:与VeRL上游对齐以简化维护、通过标准化API实现统一工具管理、异步轨迹执行实现近2倍的加速,以及在数学推理、知识问答、SQL生成等六个ARLT任务上的全面评估。
研究展示了VERLTOOL在多模态支持(文本、图像、视频)和多轮交互中的优势,显著提高了效率和扩展性。例如,在数学推理和软件工程任务中,VERLTOOL取得了与专用系统相当的性能,同时提供统一的训练基础设施。
其模块化插件架构仅需轻量级Python定义即可快速集成新工具,为工具增强的RL研究提供了可扩展的基础。开源代码(https://github.com/TIGER-AI-Lab/verl-tool)进一步促进了社区的广泛采用和算法创新。
论文链接:
https://hf.co/papers/2509.01055
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.01055
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning

论文简介:
由ByteDance Seed团队开发的《UI-TARS-2》技术报告,介绍了通过多轮强化学习(RL)推进GUI(图形用户界面)智能体的最新进展。
研究背景是GUI智能体面临的数据稀缺、多轮RL优化不稳定、纯GUI操作局限性以及环境稳定性问题。UI-TARS-2通过四项系统性方法应对这些挑战:数据飞轮机制实现可扩展的数据生成、稳定的多轮RL框架、整合文件系统和终端的混合GUI环境,以及支持大规模轨迹的统一沙箱平台。
实验结果显示,UI-TARS-2在多个GUI基准测试中表现出色,如Online-Mind2Web得分88.2、OSWorld得分47.5等,超越了Claude和OpenAI等强基线。在游戏环境中,其在15款游戏套件中的平均标准化得分为59.8,接近人类水平的60%。此外,UI-TARS-2通过GUI-SDK扩展到长时程信息检索和软件工程任务,显示出跨领域的鲁棒性。
研究还深入分析了训练动态和交互扩展策略,为大规模智能体RL的稳定性和效率提供了实用见解。这些成果表明,UI-TARS-2不仅推动了GUI交互的进步,还展示了在多样化现实场景中的强大泛化能力。
论文链接:
https://hf.co/papers/2509.02544
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.02544
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey

论文简介:
由牛津大学、上海AI实验室、新加坡国立大学等多机构合作完成的《The Landscape of Agentic Reinforcement Learning for LLMs: A Survey》系统梳理了智能体强化学习(Agentic RL)的最新进展。
研究背景是传统LLM-RL将语言模型视为静态生成器,局限于单轮输出优化,而Agentic RL将LLM重塑为动态环境中自主决策的智能体。
文章提出了一个双重分类框架:一是以规划、工具使用、记忆等为核心能力,二是以搜索、代码生成、数学推理等为任务领域。
研究强调RL是实现自适应智能体行为的关键机制,通过综合500余篇近期工作,分析了Agentic RL如何赋予LLM长期认知和交互能力。文章还整理了开源环境、基准和框架的实用资源,为加速未来研究提供了支持。例如,在数学推理和GUI交互任务中,Agentic RL显著提升了模型的规划和自我改进能力。
研究指出了信任性、训练扩展性和环境复杂性等开放挑战,并提出了未来方向,如多模态集成和多智能体协作。这篇综述为Agentic RL领域提供了全面的学术地图,突显了其在开发通用AI智能体中的潜力。
论文链接:
https://hf.co/papers/2509.02547
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.02547
-- 完 --
机智流推荐阅读:
2. 开源多模态大模型新突破,书生·万象3.5发布,通用能力、推理能力与部署效率全面升级
3. 工具调用推理只是花瓶,还是真的让大模型更聪明?腾讯清华团队揭秘工具集成推理的奥秘
4. CVPR2025 | g3D-LF让机器人“看懂”3D空间、“听懂”复杂语言,无需LLM,但导航、问答一气呵成
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群










