评论:谷歌的nano-banana将模型ImageGeneration能力带上了一个新的里程碑,最近小编也高频的使用AI生成了很多书生IP相关的图片(非常好玩)。让我们把目标转移到学术届,看看8月图片生成论文有哪些值得注意的技术点。
 |  |  |
论文选自 Hugging Face Daily Paper 八月 Image Generation 发现论文,解读由🔥Intern-S1等AI生成,可能有误。
(1) Qwen-Image Technical Report

论文简介:
由Qwen团队提出了Qwen-Image,该工作针对复杂文本渲染和精确图像编辑两大挑战,构建了综合性数据管道与渐进式学习策略。通过引入多阶段文本合成技术,模型在中英文文本渲染精度上取得显著突破,尤其在中文字符生成方面超越现有模型。创新性地设计了双编码机制,将Qwen2.5-VL的语义特征与VAE的重建特征融合,结合改进的多任务训练范式,有效提升了图像编辑的语义连贯性与视觉保真度。模型采用流匹配训练目标与混合并行策略,在256×256至1328×1328多分辨率数据上实现稳定训练。实验表明,Qwen-Image在GenEval、DPG等基准测试中均位列前三,在LongText-Bench中文长文本渲染任务中准确率达到58.3%,显著优于现有模型。其图像编辑能力在GEdit-Bench多语言指令跟随测试中取得8.00的语义一致性评分,刷新了文本到图像生成模型的编辑性能上限。该工作推动了视觉生成模型向精准图文对齐与多模态交互方向的发展,为构建具象化语言界面提供了技术范式。
论文来源:hf
Hugging Face 投票数:239
论文链接:
https://hf.co/papers/2508.02324
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.02324
(2) NextStep-1: Toward Autoregressive Image Generation with Continuous Tokens at Scale

论文简介:
由StepFun等机构提出了NextStep-1,该工作通过140亿参数的自回归模型与1.57亿参数的flow matching头,实现了基于连续图像token的文本到图像生成范式突破。模型采用离散文本token与连续图像token的统一序列建模,通过next-token预测目标训练,在GenEval、GenAI-Bench和DPG-Bench等基准测试中分别取得0.63、0.67和85.28的优异成绩,显著超越同类自回归模型并逼近扩散模型表现。其核心创新在于:1)设计通道归一化与随机扰动的图像tokenizer,解决高维连续token训练不稳定问题;2)采用patch-wise flow matching头替代传统扩散模型,实现纯自回归架构下的连续token生成;3)构建包含400B文本、550M图文对、4.5M指令引导图像和80M多模态序列的多样化训练集。在图像编辑任务中,NextStep-1-Edit在GEdit-Bench和ImgEdit-Bench分别达到6.58和3.71的SOTA指标,验证了模型的多功能性。研究还揭示自回归生成质量与tokenizer重建能力的强相关性,以及flow matching头尺寸对生成性能的非敏感性等关键发现,为后续研究提供了重要方向。
论文来源:hf
Hugging Face 投票数:140
论文链接:
https://hf.co/papers/2508.10711
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.10711
(3) Pref-GRPO: Pairwise Preference Reward-based GRPO for Stable Text-to-Image Reinforcement Learning

论文简介:
由复旦大学、上海人工智能实验室、腾讯混元等机构提出了Pref-GRPO,该工作揭示了现有文本到图像生成强化学习方法中"奖励黑客"现象的本质原因是"虚假优势"问题,并提出首个基于成对偏好奖励的GRPO优化方法,通过将奖励最大化目标转化为偏好拟合来实现更稳定的生成训练。同时构建了包含600个提示词、覆盖5大主题20个子主题的UniGenBench基准,支持10个主维度27个子维度的细粒度评估,利用多模态大模型实现自动化评估流程。实验表明Pref-GRPO在语义一致性指标上较基线提升5.84%,文本和逻辑推理维度分别提升12.69%和12.04%,有效缓解了奖励分数虚高但质量下降的矛盾。UniGenBench的细粒度评估显示:闭源模型在逻辑推理(48.18%)和文本渲染(89.08%)表现突出,开源模型在动作(69.77%)和布局(77.61%)维度接近闭源水平,但在语法和复杂逻辑任务上仍有显著差距。该研究为文本到图像生成的优化范式和评估体系提供了新的技术路径与标准框架。
论文来源:hf
Hugging Face 投票数:85
论文链接:
https://hf.co/papers/2508.20751
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20751
(4) Matrix-3D: Omnidirectional Explorable 3D World Generation

论文简介:
由上海人工智能实验室等机构提出了Matrix-3D,该工作提出了一种基于全景表示的宽覆盖可探索3D世界生成框架,通过结合条件视频生成与全景3D重建技术,解决了传统方法在场景生成范围和几何一致性上的局限性。核心创新包括:1)设计了轨迹引导的全景视频扩散模型,采用场景网格渲染作为条件输入,有效缓解了点云渲染导致的摩尔纹和错误遮挡问题,显著提升了生成视频的视觉质量和几何一致性;2)开发了两种3D重建方案——基于关键帧优化的高精度重建流水线和基于Transformer的前馈式全景重建模型,前者通过多视角超分与高斯溅射优化实现细节丰富的3D场景生成,后者则通过两阶段训练策略(先深度预测后属性优化)实现了快速重建;3)构建了首个大规模全景视频数据集Matrix-Pano,包含116K条高分辨率静态全景视频序列,每条数据配备精确的相机轨迹、深度图和文本注释,为全景视频生成与3D重建研究提供了关键数据支撑。实验表明,该方法在全景视频生成质量(PSNR达23.9,FVD低至140)和3D重建精度(PSNR达27.62)上均超越现有方案,生成场景的探索范围显著优于同期工作WorldLabs。该研究为构建广域覆盖的沉浸式3D环境提供了完整的技术路径,对自动驾驶仿真、元宇宙内容生成等领域具有重要应用价值。
论文来源:hf
Hugging Face 投票数:70
论文链接:
https://hf.co/papers/2508.08086
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.08086
(5) Story2Board: A Training-Free Approach for Expressive Storyboard Generation

论文简介:
由 Hebrew University of Jerusalem 等机构提出了 Story2Board,该工作提出了一种无需训练的分镜生成框架,通过结合潜在面板锚定(LPA)和循环注意力值混合(RAVM)机制,在保持扩散模型生成多样性的同时增强跨面板一致性。方法通过语言模型将故事分解为共享参考提示和面板级提示,利用扩散模型生成双面板图像后裁剪保留目标面板。LPA通过在去噪过程中同步参考面板特征实现跨面板一致性,而RAVM基于双向注意力分数混合语义对齐token的值向量,强化角色身份特征的同时保留空间布局多样性。研究引入了包含100个开放式故事的Rich Storyboard Benchmark数据集,重点评估布局灵活性和环境叙事能力,并提出场景多样性(Scene Diversity)指标量化角色在面板序列中的尺度、姿态和位置变化。实验表明该方法在保持角色一致性的同时,生成的分镜在构图动态性和叙事表现力上显著优于StoryDiffusion、OminiControl等基线方法,用户研究显示其整体偏好度领先。该方法无需模型微调或架构修改,可直接应用于Stable Diffusion 3等扩散模型,为文本到分镜生成提供了兼顾一致性与表现力的轻量化解决方案。
论文来源:hf
Hugging Face 投票数:66
论文链接:
https://hf.co/papers/2508.09983
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09983
(6) Skywork UniPic: Unified Autoregressive Modeling for Visual Understanding and Generation

论文简介:
该工作通过解耦编码策略与渐进式训练方法,构建了一个1.5B参数的统一自回归模型,实现了图像理解、文本到图像生成与图像编辑的深度融合。核心创新包括:1)采用Masked Autoregressive Encoder(MAR)与SigLIP2双编码器分别优化生成与理解任务,通过共享解码器实现跨任务知识迁移;2)设计从256×256到1024×1024的分辨率渐进训练策略,动态解冻参数以平衡模型容量与训练稳定性;3)构建百万级高质量多模态数据集,并引入基于Group Relative Policy Optimization的图像质量奖励模型与编辑对齐奖励模型。实验表明,该模型在GenEval(0.86)、DPG-Bench(85.5)等生成基准测试中超越多数同类模型,在GEditBench-EN(5.83)和ImgEdit-Bench(3.49)等编辑任务中表现优异,且支持在RTX 4090显卡上生成1024×1024图像。与BAGEL(14B)、UniWorld-V1(19B)等大模型相比,其参数效率提升近十倍,验证了紧凑架构实现多模态统一建模的可行性。代码与模型权重已开源,为资源受限场景下的多模态应用提供新范式。
论文来源:hf
Hugging Face 投票数:59
论文链接:
https://hf.co/papers/2508.03320
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.03320
(7) Omni-Effects: Unified and Spatially-Controllable Visual Effects Generation

论文简介:
由阿里巴巴等机构提出了Omni-Effects,该工作构建了一个统一的视觉效果生成框架,支持通过文本提示和空间掩码实现单效、多效及空间可控的视觉效果生成。针对传统方法在多效生成中的任务干扰和空间控制不足问题,研究者创新性地引入LoRA-MoE模块,通过专家LoRA组的动态路由机制实现多效协同训练,有效抑制跨任务干扰;同时设计空间感知提示(SAP)机制,将空间掩码信息嵌入文本token,并通过独立信息流(IIF)模块隔离不同控制信号,避免效果混合。为支撑研究,团队构建了包含55类视觉效果的Omni-VFX数据集,并提出包含区域动态度(RDD)、效果触发率(EOR)等指标的评估体系。实验表明,Omni-Effects在多效生成任务中FVD指标优于传统LoRA方法20%以上,在空间控制任务中EOR达到0.97,ECR达0.88,显著优于CogVideoX等基线模型。该框架在电影特效、游戏开发等领域具有广阔应用前景,为可控视觉生成提供了新范式。
论文来源:hf
Hugging Face 投票数:58
论文链接:
https://hf.co/papers/2508.07981
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.07981
(8) Voost: A Unified and Scalable Diffusion Transformer for Bidirectional Virtual Try-On and Try-Off

论文简介:
由NXN Labs等机构提出了Voost,该工作提出了一种统一且可扩展的扩散Transformer框架,通过单个模型同时实现双向虚拟试穿(Virtual Try-On)和试脱(Try-Off)任务。Voost通过联合建模两个方向的任务,使每个服装-人体对能够互相监督,从而增强服装与人体的空间对应关系,无需依赖任务特定的网络结构、辅助损失函数或额外标注数据。方法上,Voost采用水平拼接的输入布局,将服装图像与人体图像作为共享嵌入空间的条件输入,并通过任务令牌(task token)动态编码生成方向(试穿/试脱)和服装类别(上装/下装/全身装),支持灵活的多任务学习。此外,研究者引入了两种推理优化技术:注意力温度缩放(根据输入分辨率和掩码比例动态调整注意力分布)和自修正采样(通过双向一致性约束迭代优化生成结果),显著提升了生成质量与鲁棒性。实验表明,Voost在VITON-HD和DressCode等基准数据集上均超越了现有方法,在结构一致性(如SSIM、LPIPS)、视觉保真度(FID、KID)等指标上取得最优结果,同时在野外图像(in-the-wild)的复杂姿态、光照和背景条件下表现出优异的泛化能力。用户研究表明,Voost在照片级真实感、服装细节保留和结构一致性方面均获得最高评价。该工作通过统一框架实现双向服装-人体交互建模,为虚拟试衣技术提供了高效且可扩展的新范式。
论文来源:hf
Hugging Face 投票数:57
论文链接:
https://hf.co/papers/2508.04825
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.04825
(9) USO: Unified Style and Subject-Driven Generation via Disentangled and Reward Learning

论文简介:
由字节跳动UXO团队等机构提出了USO(Unified Style-Subject Optimized),该工作通过解耦内容与风格特征并引入奖励学习机制,首次实现了风格驱动与主体驱动生成任务的统一框架。现有方法通常将风格相似性与主体一致性视为对立目标,而USO通过构建包含20万组三元组数据(风格参考图、去风格化主体图、风格化结果图)的训练集,提出跨任务协同解耦范式:利用主体生成模型生成高质量风格化数据,再通过风格奖励引导的解耦训练优化主体模型。技术上采用SigLIP多尺度特征投影实现风格对齐训练,并通过内容-风格解耦编码器分离条件特征,最终结合风格奖励学习(SRL)进一步提升解耦效果。研究团队还发布了首个支持风格/主体/联合任务评估的基准USO-Bench,包含50组内容图与50组风格图的组合测试集。实验显示USO在Subject-Driven任务中取得0.623 CLIP-I和0.793 DINO的SOTA成绩,在Style-Driven任务中以0.557 CSD和0.282 CLIP-T超越现有方法,在联合任务中更以0.495 CSD和0.283 CLIP-T显著领先基线模型。消融实验证实风格奖励学习使CSD提升8.2%,解耦编码器使CLIP-I提升2.9%,验证了跨任务协同解耦的有效性。该方法支持任意主体与风格的自由组合生成,在保持高文本对齐度的同时,解决了传统方法中风格迁移时主体失真和主体生成时风格干扰的核心矛盾。
论文来源:hf
Hugging Face 投票数:55
论文链接:
https://hf.co/papers/2508.18966
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18966
(10) PixNerd: Pixel Neural Field Diffusion

论文简介:
由南京大学、ByteDance Seed和新加坡国立大学的研究人员提出了PixNerd(Pixel Neural Field Diffusion),该工作通过引入神经场建模大块补丁解码,构建了首个单阶段、单尺度的像素空间扩散模型。针对传统扩散模型依赖预训练VAE导致的解码伪影和训练复杂性问题,PixNerd创新性地将扩散Transformer的最终线性投影替换为隐式神经场,通过预测各补丁神经场MLP权重,结合坐标编码与噪声像素值进行逐像素速度预测,在保持与潜在扩散模型相似计算成本的前提下,实现了端到端的像素空间生成。
在ImageNet 256×256分辨率上,PixNerd-XL/16达到2.15 FID和4.55 sFID,显著优于PixelFlow等像素生成模型;在512×512分辨率下通过微调保持2.84 FID。文本到图像生成任务中,PixNerd-XXL/16在GenEval基准获得0.73综合得分,在DPG基准取得80.9平均分。模型通过DCT基坐标编码和归一化策略优化神经场设计,采用Adams-2nd求解器实现25步快速采样,训练吞吐量较ADM-G提升8倍。该工作验证了像素空间扩散模型的可行性,为消除VAE依赖提供了新范式,但复杂场景下的细节生成能力仍需提升。
论文来源:hf
Hugging Face 投票数:51
论文链接:
https://hf.co/papers/2507.23268
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.23268
(11) ToonComposer: Streamlining Cartoon Production with Generative Post-Keyframing

论文简介:
由腾讯ARC Lab、香港中文大学等机构提出了ToonComposer,该工作提出了一种生成式后关键帧技术,通过稀疏草图注入和空间低秩适配策略,将传统动画制作中的中间帧生成与上色阶段整合为统一自动化流程。ToonComposer基于DiT架构构建,支持仅用单张关键帧草图和彩色参考帧生成高质量卡通视频,其核心创新包括:1)稀疏草图注入机制,通过位置编码映射和位置感知残差模块实现跨时间步的精确草图控制;2)空间低秩适配器(SLRA),在保留时序先验的前提下,通过空间维度低秩分解实现卡通域适配;3)区域级控制功能,允许艺术家指定空白区域由模型根据上下文生成动态内容。研究团队构建了包含3.7万条卡通视频片段的PKData数据集,并推出含真实手绘草图的PKBench基准测试。实验表明,ToonComposer在视觉质量(LPIPS降低52.5%)、运动一致性(DISTS降低73.3%)和生产效率方面全面超越现有方法,支持从单草图到多关键帧的灵活控制,为动画制作提供了兼具精度与效率的生成式解决方案。该方法通过消除传统流程中的误差累积问题,显著降低了人工干预需求,同时保持了艺术风格一致性。
#################
论文来源:hf
Hugging Face 投票数:51
论文链接:
https://hf.co/papers/2508.10881
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.10881
(12) Next Visual Granularity Generation

论文简介:
由Yikai Wang等学者提出了Next Visual Granularity (NVG)图像生成框架,该工作通过将图像分解为具有不同视觉粒度的结构化序列,实现从全局布局到细节纹理的分层生成。NVG通过多粒度量化自编码器构建视觉粒度序列,每个阶段使用不同数量的唯一token表示图像,在相同空间分辨率下形成从粗到细的层次结构。生成过程采用迭代方式,先生成结构图再生成对应内容,通过结构感知的旋转位置编码(RoPE)和残差建模机制,有效缓解了传统自回归模型的误差累积问题。
实验表明,NVG在ImageNet 256×256图像生成任务中表现出色,与VAR系列模型相比,FID指标从3.30提升至3.03,IS和Recall等指标也全面超越。模型通过结构嵌入技术实现了显式的布局控制能力,可复用参考图像的结构图生成新内容,在保持结构一致性的同时保证细节多样性。该方法在生成过程中自然融入结构控制,无需额外条件模块,为图像生成提供了更直观的控制维度。研究还展示了通过固定不同阶段的结构/内容实现渐进式生成控制的能力,为可控图像生成提供了新的技术路径。
论文来源:hf
Hugging Face 投票数:46
论文链接:
https://hf.co/papers/2508.12811
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.12811
(13) S^2-Guidance: Stochastic Self Guidance for Training-Free Enhancement of Diffusion Models

论文简介:
由清华、阿里等机构提出了S²-Guidance,该工作针对扩散模型中广泛使用的无分类器引导(CFG)存在的语义不一致和低质量输出问题,提出了一种无需额外训练的随机自引导方法。通过理论分析高斯混合模型发现,CFG的次优预测可通过模型自身子网络进行有效修正,进而提出利用前向过程中的随机块丢弃构建潜在子网络,动态生成引导信号以规避低质量预测区域。该方法在文本到图像和文本到视频生成任务中均表现出显著优势:在HPSv2.1基准上,SD3模型的平均得分提升0.61%,SD3.5提升0.74%,且在复杂场景理解指标(如颜色、形状)上提升超10%;在视频生成领域,Wan1.3B模型的总分提升0.64%,Wan14B提升0.19%。实验表明,S²-Guidance不仅保持了与CFG相当的计算效率(单步块丢弃即可),还能生成更精细的纹理细节(如宇航员头盔透明度)、更连贯的动态效果(如汽车加速运动的动态模糊),同时避免了传统弱模型构建的训练依赖和架构限制。通过引入基于模型不确定性的反向引导机制,该方法在美学质量(Qalign)和提示对齐度等维度全面超越CFG及APG、CFG++等先进方法,为扩散模型的条件引导提供了新的优化范式。
论文来源:hf
Hugging Face 投票数:45
论文链接:
https://hf.co/papers/2508.12880
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.12880
(14) Visual-CoG: Stage-Aware Reinforcement Learning with Chain of Guidance for Text-to-Image Generation

论文简介:
由阿里巴巴集团提出了Visual-CoG,该工作针对当前文本到图像生成模型在处理多属性和模糊提示时的局限性,创新性地设计了阶段感知的强化学习框架。研究团队通过构建包含语义推理、过程细化和结果评估三个阶段的视觉引导链(Visual-CoG),在生成全流程中引入即时奖励机制,有效解决了传统方法仅依赖最终结果反馈导致的优化偏差问题。核心突破在于:1)语义推理阶段通过对比原提示与推理提示的生成差异计算奖励,提升复杂语义理解能力;2)过程细化阶段采用教师模型指导的掩码重建任务评估中间结果;3)结果评估阶段结合规则引擎与美学模型实现多维质量判断。为验证推理能力,团队特别构建了包含非常规位置、组合、颜色及推理任务的VisCogBench基准,实验显示该方法在GenEval、T2I-CompBench和VisCogBench上分别取得15%、5%和19%的性能提升,尤其在计数、空间关系等多属性任务中表现突出。该研究为生成模型的阶段性优化提供了新范式,相关资源即将开源。
论文来源:hf
Hugging Face 投票数:40
论文链接:
https://hf.co/papers/2508.18032
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18032
(15) Stand-In: A Lightweight and Plug-and-Play Identity Control for Video Generation

论文简介:
由腾讯微信视觉团队提出了Stand-In,该工作提出了一种轻量级且即插即用的身份控制框架,用于高保真视频生成。研究者通过在预训练视频生成模型中引入条件图像分支,利用受限自注意力与条件位置映射机制实现身份信息注入,仅需训练约1%的额外参数即可在身份保持、视频质量和提示词跟随方面达到SOTA效果。该方法通过预训练VAE将参考图像与视频映射到同一隐空间,避免了传统方法对显式人脸编码器的依赖,同时通过低秩适配(LoRA)和条件位置编码策略,在保持模型轻量化的同时确保身份特征的有效融合。实验表明,该方法在OpenS2V基准测试中面部相似度达0.724,自然度3.922,显著优于现有方法,且在2000对训练数据上快速收敛。其即插即用特性使其可无缝扩展至姿势引导生成、视频风格化、换脸等任务,通过与VACE框架集成更可提升姿态引导生成的面部一致性。该框架的高效性(推理速度仅下降2.3%)与泛化能力(支持卡通/物体等非人类主体)为个性化视频生成提供了灵活解决方案。
论文来源:hf
Hugging Face 投票数:39
论文链接:
https://hf.co/papers/2508.07901
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.07901
(16) Tinker: Diffusion's Gift to 3D--Multi-View Consistent Editing From Sparse Inputs without Per-Scene Optimization

论文简介:
由浙江大学等机构提出了Tinker,该工作提出了一种无需逐场景优化的通用3D编辑框架,通过复用预训练扩散模型的3D感知能力,实现了基于稀疏输入的多视角一致编辑。Tinker的核心创新在于构建了首个大规模多视角编辑数据集和数据管道,并开发了两个关键组件:参考多视角编辑器通过LoRA微调使模型能够跨视角传播编辑意图,任意视角到视频合成器则利用视频扩散模型的空间时间先验,在深度条件约束下完成高质量场景补全。实验表明,Tinker在单样本和少样本场景下均优于现有方法,在Mip-NeRF-360和IN2N数据集上实现了0.959的DINO相似度和6.338的美学评分,同时将编辑时间缩短至15分钟。该方法不仅支持物体级和场景级编辑,还能通过深度引导的视频重建实现高效视频压缩,并通过测试时优化迭代提升生成质量。Tinker通过消除逐场景微调需求,显著降低了3D内容创作的技术门槛,为零样本3D编辑提供了可扩展的解决方案。
论文来源:hf
Hugging Face 投票数:39
论文链接:
https://hf.co/papers/2508.14811
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.14811
(17) CharacterShot: Controllable and Consistent 4D Character Animation

论文简介:
由同济大学、上海人工智能实验室等机构提出了CharacterShot,该工作构建了一个可控且一致的4D角色动画框架,能够从单个参考图像和2D姿态序列生成动态3D角色。研究者首先基于DiT架构的图像到视频模型CogVideoX进行预训练,通过引入姿态条件实现对角色运动的精确控制;接着提出双注意力模块并结合相机先验,在生成多视角视频时同步建模时空与视点间的一致性;最终通过邻域约束的4D高斯溅射优化,将多视角视频转化为连续稳定的4D角色表示。为解决角色动画数据匮乏问题,团队构建了包含13,115个高保真角色的Character4D数据集,并搭建了首个4D角色动画基准CharacterBench。实验表明,CharacterShot在多视角视频生成和4D优化任务中均显著优于现有方法,在SSIM、FVD等指标上取得最优结果,同时用户研究显示其对跨域角色具有优异泛化能力。该方法将传统数周的CGI流程压缩至分钟级,为个体创作者提供了低成本的动态角色生成方案。
论文来源:hf
Hugging Face 投票数:38
论文链接:
https://hf.co/papers/2508.07409
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.07409
(18) MV-RAG: Retrieval Augmented Multiview Diffusion

论文简介:
由希伯来大学等机构提出了MV-RAG,该工作提出了一种检索增强的多视图扩散框架,通过结合结构化多视图数据和大规模2D图像集合的混合训练策略,有效提升了模型在处理罕见或新兴对象时的生成质量。针对现有文本到3D生成方法在分布外(OOD)场景下几何不一致和语义偏差的问题,MV-RAG创新性地引入了动态检索增强机制:在推理阶段,首先通过BM25从LAION-400M等数据集中检索与文本相关的2D图像,利用ViT编码器提取局部特征并通过可学习的Resampler模块生成条件令牌;在生成阶段,通过解耦的交叉注意力机制将文本语义与检索图像的视觉特征进行自适应融合,并设计了Prior-Guided Attention机制根据OOD程度动态调整基模型与检索信号的权重分配。训练策略上,该方法采用3D模式与2D模式交替训练:3D模式通过渲染Objaverse数据集对象并施加几何/语义增强来模拟真实检索差异,要求模型从增强视图重建原始视角;2D模式则使用ImageNet-21K数据,通过预测被遮掩视图的新型训练目标,使模型从无结构2D图像中学习3D一致性。实验方面,研究团队构建了包含196个OOD概念的评估基准OOD-Eval,对比MVDream、MV-Adapter等SOTA方法,在CLIP、DINO等图像相似度指标上分别提升5.3%和12.1%,同时保持了在Objaverse-XL等标准数据集上的竞争力。该工作不仅通过检索增强突破了传统扩散模型的语义局限,更通过混合训练范式弥合了结构化3D数据与非结构化2D图像之间的鸿沟,为文本到多视图生成开辟了新路径。
论文来源:hf
Hugging Face 投票数:36
论文链接:
https://hf.co/papers/2508.16577
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16577
(19) Waver: Wave Your Way to Lifelike Video Generation
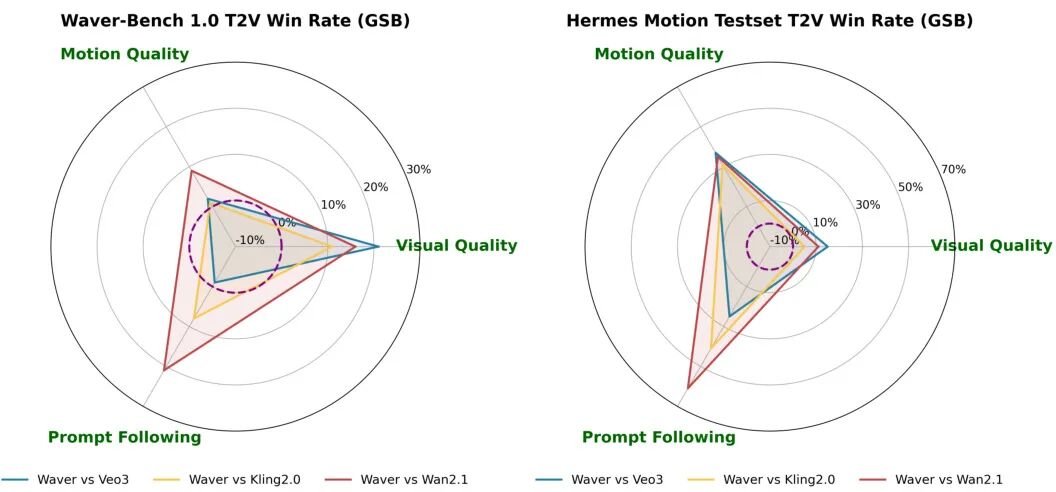
论文简介:
由字节跳动团队提出了Waver,该工作提出了一种高性能统一图像与视频生成模型,通过Hybrid Stream DiT架构实现文本/图像到视频的多任务融合生成,支持5-10秒原生720p视频生成并可上采样至1080p。核心贡献包括:1)创新Hybrid Stream DiT架构,通过双流/单流混合设计优化模态对齐与参数效率;2)构建全流程数据处理体系,包含多阶段过滤、质量标注模型和语义平衡策略,处理超2亿视频片段;3)开发级联上采样器,采用窗口注意力和像素/潜在空间降质策略实现40%推理加速;4)提出运动幅度优化、美学增强、模型平衡等训练策略,在Artificial Analysis排行榜T2V和I2V任务均位列前三,尤其在复杂运动场景中相较竞品提升显著。该工作通过详尽的技术细节开源和多维度优化策略,为视频生成领域提供了可复现的高性能解决方案。
论文来源:hf
Hugging Face 投票数:33
论文链接:
https://hf.co/papers/2508.15761
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15761
(20) MIDAS: Multimodal Interactive Digital-human Synthesis via Real-time Autoregressive Video Generation

论文简介:
由快手科技、浙江大学和清华大学等机构提出了MIDAS(Multimodal Interactive Digitalhuman Synthesis),该工作构建了一种基于自回归模型与扩散渲染的实时多模态数字人合成框架。针对现有方法在低延迟交互、多模态控制和长序列生成上的局限,研究团队设计了三大核心创新:首先通过多模态条件投影器将音频、姿态、文本等异构信号编码为统一指令令牌,引导自回归模型生成时空一致的潜在表示;其次采用因果潜在预测与轻量扩散头结合的架构,以单帧预测策略实现流式生成,在保证质量的同时将推理延迟降至毫秒级;此外开发了64倍压缩比的深度压缩自编码器(DC-AE),显著降低长序列生成的计算负担。为支撑模型训练,团队构建了包含2万小时对话的多场景数据集,并引入可控噪声注入机制缓解训练与推理的暴露偏差问题。实验部分通过双工对话、跨语言唱歌合成和交互式世界模型三项任务验证了框架的有效性:数字人能实现自然的对话轮转与唇形同步,支持中英日等多语言高保真生成,并在《我的世界》场景中展现出稳定的视觉记忆与环境交互能力。该工作在保持身份一致性的同时,实现了多模态条件下的实时响应与开放域生成,为交互式数字人技术提供了可扩展的解决方案。
论文来源:hf
Hugging Face 投票数:27
论文链接:
https://hf.co/papers/2508.19320
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19320
(21) T2I-ReasonBench: Benchmarking Reasoning-Informed Text-to-Image Generation

论文简介:
由香港大学和香港中文大学等机构提出了T2I-ReasonBench,该工作构建了一个新型基准测试框架,旨在系统评估文本到图像生成模型的推理能力。研究团队针对现有模型在隐含语义理解上的不足,设计了包含800个提示词的测试集,覆盖成语解读、图文设计、实体推理和科学推理四大维度,要求模型在生成图像前完成多步骤逻辑推导。通过大语言模型生成定制化评估问题,再由多模态模型进行双阶段评分,该框架可量化推理准确率和图像质量。实验对比了14种主流模型,包括扩散模型、自回归模型和闭源商用模型,发现开源模型普遍存在显著推理缺陷,而GPT-Image-1等闭源模型虽表现更优但仍存在提升空间。研究揭示了当前文本到图像生成技术在知识整合与逻辑推理上的核心瓶颈,为构建具备深度语义理解能力的下一代生成模型提供了基准参考和改进方向。
论文来源:hf
Hugging Face 投票数:26
论文链接:
https://hf.co/papers/2508.17472
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17472
(22) Echo-4o: Harnessing the Power of GPT-4o Synthetic Images for Improved Image Generation

论文简介:
由上海人工智能实验室、中山大学、香港中文大学和北京大学等机构提出的Echo-4o,通过构建180K规模的GPT-4o合成图像数据集Echo-4o-Image,有效弥补了真实图像数据在罕见场景覆盖和监督质量上的不足。该数据集包含38K超现实幻想场景、73K多参考图像生成和68K复杂指令遵循样本,通过纯背景、长尾属性组合等特性提供精准的文本-图像对齐监督。基于此数据集微调的Bagel模型Echo-4o,在GenEval、DPG等基准测试中分别取得0.89和86.07的优异成绩,并在新提出的GenEval++(指令复杂度提升40%)和ImagineBench(评估幻想生成能力)中展现显著优势。研究还验证了数据集的跨模型迁移能力,通过在OmniGen2、BLIP3-o等模型上的应用,实现了多任务性能的普适性提升。该工作揭示了合成数据在增强模型想象力、多参考合成和指令遵循能力方面的核心价值,为多模态生成模型的优化提供了新范式。
论文来源:hf
Hugging Face 投票数:24
论文链接:
https://hf.co/papers/2508.09987
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09987
(23) Matrix-Game 2.0: An Open-Source, Real-Time, and Streaming Interactive World Model

论文简介:
由 Skywork AI 等机构提出了 Matrix-Game 2.0,该工作构建了一个开源的实时流式交互世界模型,通过少步自回归扩散实现长视频的即时生成。针对现有交互式世界模型依赖双向注意力和多步推理导致实时性差的问题,研究团队开发了三大核心组件:基于 Unreal Engine 和 GTA5 环境的可扩展数据生产管道,可生成约 1200 小时带交互标注的高质量视频数据;支持帧级键盘鼠标输入的动作注入模块,实现精准的交互条件控制;基于因果架构的少步蒸馏技术,通过 Self-Forcing 方法将双向扩散模型转化为因果自回归模型。该模型在单个 H100 GPU 上实现 25 FPS 的超快生成速度,可生成跨场景的分钟级高质量视频,同时保持精确的动作可控性。研究团队特别设计了包含导航网格路径规划、强化学习代理训练和精确输入同步的完整数据生产体系,解决了交互视频数据稀缺问题。通过引入 KV 缓存机制和滚动窗口管理,模型在保持长时一致性的同时避免误差累积。实验表明,该模型在 Minecraft 和开放场景中均显著优于 Oasis、YUME 等现有方法,在视觉质量、时序连贯性和动作响应精度等维度表现突出。所有模型权重和代码均已开源,为交互式世界建模研究提供重要基础。
论文来源:hf
Hugging Face 投票数:22
论文链接:
https://hf.co/papers/2508.13009
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13009
(24) MultiRef: Controllable Image Generation with Multiple Visual References

论文简介:
由浙江大学、华盛顿大学、华中科技大学等机构提出的MultiRef,聚焦多参考图像生成任务,构建了包含990个合成样本和1000个真实样本的MultiRef-bench基准测试,并开发RefBlend数据引擎生成38k高质量图像数据集。该研究揭示当前主流模型(如OmniGen、ACE、Show-o等)在处理多参考输入时存在显著缺陷,最佳模型OmniGen在合成样本中仅实现66.6%的对齐度,真实样本为79.0%,远低于人类创作水平。研究通过RefBlend引擎实现多模态参考(如深度图、边缘图、语义图等)的自动化组合生成,建立33种参考组合的兼容性规则,并采用规则评估(如IoU、MSE)与模型评估(MLLM-as-a-Judge)双轨机制。实验发现模型普遍存在空间对齐差、多条件冲突处理弱等问题,尤其在输入顺序变化或缺少文本提示时表现更差,凸显现有模型在多源视觉信息整合能力上的不足。该研究为开发更接近人类创作流程的多参考生成工具提供了关键方向,相关数据集已公开以推动领域发展。
论文来源:hf
Hugging Face 投票数:20
论文链接:
https://hf.co/papers/2508.06905
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.06905
(25) CineScale: Free Lunch in High-Resolution Cinematic Visual Generation

论文简介:
由Nanyang Technological University、Netflix Eyeline Studios等机构提出了CineScale,该工作提出了一种新的推理范式,通过多尺度融合和频率域处理技术,首次实现预训练扩散模型在8K图像和4K视频生成上的突破性效果。研究针对扩散模型在超分辨率生成时出现的重复模式和质量退化问题,设计了定制化的自级联上采样、受限膨胀卷积和尺度融合模块,有效解决了UNet架构下的局部重复问题。同时通过NTK-RoPE位置编码和注意力缩放技术,将方法扩展至DiT架构,在仅需少量LoRA微调的情况下,成功生成4K分辨率视频。实验表明,该方法在图像生成中达到FID 44.723(2048²)和49.796(4096²)的最优指标,视频生成在FVD、动态程度等指标上全面领先基线方法。值得注意的是,该方法支持灵活的局部语义编辑和动态程度控制,用户研究显示其在图像质量、结构合理性等维度获得70%以上的用户偏好。最终实现了在保持预训练模型参数不变的前提下,将图像生成分辨率提升64倍(8K)、视频生成分辨率提升9倍(4K)的技术突破。
论文来源:hf
Hugging Face 投票数:19
论文链接:
https://hf.co/papers/2508.15774
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15774
(26) HPSv3: Towards Wide-Spectrum Human Preference Score

论文简介:
由MizzenAI、CUHK MMLab、King’s College London和上海人工智能实验室等机构提出了HPSv3,该工作构建了首个覆盖广泛质量谱系的人类偏好数据集HPDv3,包含108万文本-图像对和117万标注对,并提出基于视觉语言模型的HPSv3评分模型及不确定性感知排序损失,同时开发了通过迭代优化提升生成质量的CoHP方法。HPDv3通过整合16种生成模型输出和高质量真实图像,覆盖12类用户提示词分布,标注一致性达76.5%。HPSv3采用Qwen2VL-7B提取多模态特征,结合不确定性建模的排序损失,实现与人类偏好0.94的Spearman相关性,在HPDv3测试集准确率达76.9%。CoHP通过模型级和样本级两阶段选择,利用HPSv3作为奖励模型进行迭代优化,生成图像在用户研究中以87%胜率超越ImageReward等基线。实验表明HPSv3显著优于现有指标,CoHP可有效提升生成质量,为文本到图像生成提供可靠评估框架和优化方案。
论文来源:hf
Hugging Face 投票数:18
论文链接:
https://hf.co/papers/2508.03789
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.03789
(27) Gaussian Variation Field Diffusion for High-fidelity Video-to-4D Synthesis
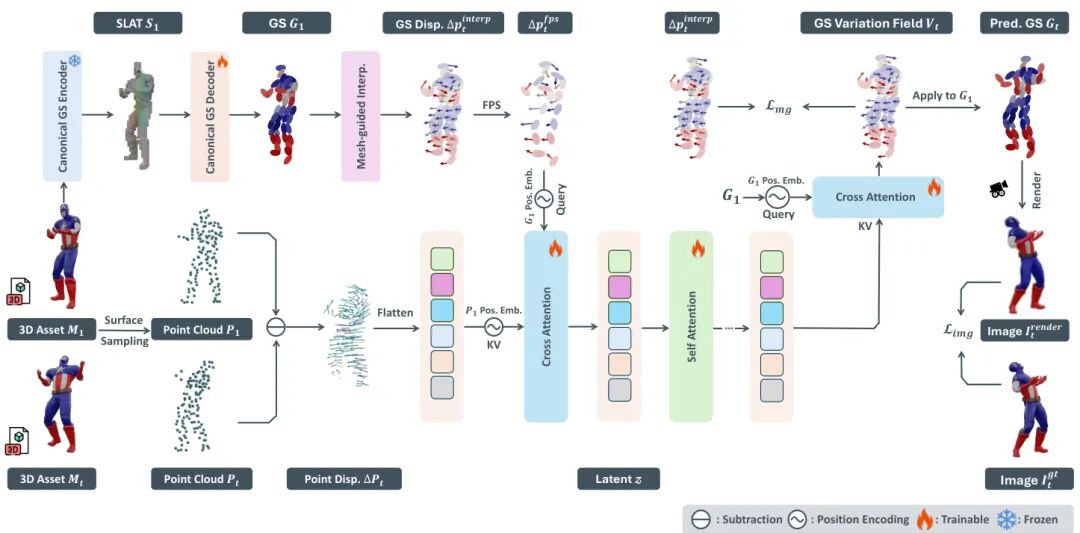
论文简介:
由微软亚洲研究院与中科大等机构提出了Gaussian Variation Field Diffusion,该工作针对4D生成领域中动态3D内容建模困难的问题,提出了一种高效的视频到4D合成框架。研究团队通过构建Direct 4DMesh-to-GS Variation Field VAE,将4D网格数据直接编码为高斯变体场的紧凑潜在表示,有效解决了传统方法中逐实例拟合成本高昂的问题。该框架通过网格引导的位移对齐机制和跨注意力机制,将数千帧点云序列压缩至512维潜在空间,为扩散模型建模奠定基础。在此基础上,团队进一步开发了基于Diffusion Transformer的高斯变体场扩散模型,通过引入时间自注意力和位置先验,实现了对输入视频和规范高斯表示的条件生成。实验表明,该方法在Objaverse数据集上训练后,不仅在PSNR(18.47)、LPIPS(0.114)等指标上超越现有方法,更展现出对真实世界视频输入的优异泛化能力。特别值得注意的是,该方法在4.5秒内即可完成4D动画生成,效率显著优于传统优化方法。这项研究通过将4D生成分解为规范3D生成与变体场建模,在保证计算效率的同时实现了时空一致性,为高质量动态3D内容生成开辟了新路径。项目主页:GVFDiffusion.github.io。
论文来源:hf
Hugging Face 投票数:18
论文链接:
https://hf.co/papers/2507.23785
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.23785
(28) EgoTwin: Dreaming Body and View in First Person

论文简介:
由新加坡国立大学、南洋理工大学、香港科技大学和上海人工智能实验室等机构提出了EgoTwin,该工作首次探索了第一人称视角下视频与人体运动的联合生成问题,通过扩散模型框架实现了视点对齐和因果交互的同步建模。传统方法在处理外视角视频生成时通常依赖预设的相机轨迹,而第一人称视频生成需要同时生成与人体运动严格对齐的相机轨迹。EgoTwin引入头中心运动表示法,将运动锚定在头部关节而非传统根关节,显著提升了运动与视频的视点一致性。同时,其基于控制论的交互机制通过双向注意力设计,使视频帧能基于历史运动生成,运动序列又能根据视频帧的场景变化进行调整,形成闭环的观察-动作反馈。研究团队还构建了包含真实场景文本-视频-运动三元组的大规模数据集,并设计了评估视频-运动一致性的新指标(如相机轨迹与头部轨迹的平移/旋转误差、手部可见性F-Score)。实验表明,EgoTwin在视频质量(FVD↓40%)、运动质量(M-FID↓7%)和跨模态一致性(旋转误差↓70%)等指标上均显著优于基线模型。该框架支持文本驱动的视频-运动联合生成、以及给定视频/运动的条件生成等多样化应用,为可穿戴计算和虚拟现实中的具身智能体建模提供了新范式。
论文来源:hf
Hugging Face 投票数:18
论文链接:
https://hf.co/papers/2508.13013
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13013
(29) UNCAGE: Contrastive Attention Guidance for Masked Generative Transformers in Text-to-Image Generation

论文简介:
由首尔国立大学、FuriosaAI等机构提出了UNCAGE,该工作针对Masked Generative Transformers(MGTs)在文本到图像生成中属性绑定不准确的问题,提出了一种无需训练的对比注意力引导解码策略。研究发现MGTs在组合式文本到图像生成任务中存在对象属性错位、文本-图像对齐度低的问题,这与其并行解码机制和注意力图的局限性密切相关。UNCAGE通过构建正负对象对的注意力对比机制,在解码初期优先解码能清晰表征独立对象的token,从而在不增加模型训练成本的前提下显著提升生成质量。具体而言,方法通过计算每个空间位置的对比注意力分数(正对最小注意力与负对最大注意力的差值),动态调整解码顺序,使关键对象特征在早期生成阶段得到强化。实验表明,该方法在Attend-and-Excite和SSD等基准数据集上,CLIP文本-图像相似度、GPT评估等指标均超越现有方法,在保持0.13%额外计算开销的情况下,用户研究偏好度提升近50%。与扩散模型的梯度优化方法相比,UNCAGE在计算效率和对MGTs的适配性上具有显著优势,为生成式Transformer的解码优化提供了新的技术路径。
论文来源:hf
Hugging Face 投票数:16
论文链接:
https://hf.co/papers/2508.05399
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.05399
(30) OmniTry: Virtual Try-On Anything without Masks

论文简介:
由Kunbyte AI和浙江大学等机构提出了OmniTry,该工作首次实现了面向任意穿戴物品的无掩码虚拟试穿框架。针对传统虚拟试穿(VTON)局限于衣物且依赖人工标注掩码的痛点,OmniTry创新性地构建了支持12类穿戴物品(包括首饰、鞋包等)的统一生成框架,通过两阶段训练策略突破了成对数据稀缺的限制。第一阶段采用traceless erasing技术处理无配对人像数据,训练模型掌握物品定位能力;第二阶段通过masked full-attention机制引入少量成对数据微调,实现物品外观一致性保持。关键技术包括:1)将inpainting模型改造为无掩码生成器,通过零掩码输入实现自然定位;2)设计双流适配器分别处理人物和物品特征;3)构建包含360对图像的OmniTry-Bench基准,覆盖白底/自然背景/试穿场景的多维度评估。实验表明,OmniTry在物体定位准确率(G-Acc=0.9972)和外观一致性(M-CLIP-I=0.8327)等指标上显著优于现有方法(如OOTDiffusion、Any2AnyTryon等),且在仅用1张配对样本微调时即可达到收敛,展现出强大的小样本学习能力。该工作为虚拟试穿技术在电商、元宇宙等场景的落地提供了新的技术路径。
论文来源:hf
Hugging Face 投票数:16
论文链接:
https://hf.co/papers/2508.13632
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13632
(31) Wan-S2V: Audio-Driven Cinematic Video Generation

论文简介:
由HumanAIGC Team Tongyi Lab, Alibaba提出了Wan-S2V,该工作通过结合文本引导的全局运动控制与音频驱动的细节控制,在复杂影视场景中实现更具表现力和一致性的角色动画生成。针对现有音频驱动模型在多角色交互、真实肢体动作和动态镜头控制等场景中的局限性,研究团队基于Wan文本到视频生成框架构建了支持长视频生成的音频驱动模型。核心创新包括:1)构建包含影视级数据的混合数据集,通过精细化标注与多维度质量筛选提升数据有效性;2)采用FSDP与上下文并行的混合训练策略,实现14B参数模型的高效训练;3)提出基于FramePack的运动帧压缩方法,在降低计算成本的同时增强长视频时空一致性;4)设计分阶段训练流程,在语音视频预训练基础上进行影视数据微调,平衡文本控制与音频同步能力。实验显示,该方法在FID、FVD等指标上优于Hunyuan-Avatar、Omnihuman等SOTA模型,尤其在动态场景保持、多角色交互和长时一致性方面表现突出。研究还验证了模型在影视级长视频生成、精确唇同步编辑等场景的应用潜力,为复杂视听内容创作提供了新的技术路径。
论文来源:hf
Hugging Face 投票数:16
论文链接:
https://hf.co/papers/2508.18621
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18621
(32) Training-Free Text-Guided Color Editing with Multi-Modal Diffusion Transformer

论文简介:
由香港科技大学、国际数字经济学研究院、清华大学、智谱AI等机构提出了ColorCtrl,该工作提出了一种无需训练的文本引导颜色编辑方法,通过解耦多模态扩散Transformer(MM-DiT)中的结构与颜色信息,实现对物体反照率、光源颜色和环境光照的精准编辑,同时保持几何结构、材质属性和光物质交互的物理一致性。ColorCtrl通过定向操控注意力图和值令牌,仅修改文本提示指定的区域而不影响无关区域,并支持词级控制颜色属性强度。实验表明,该方法在SD3和FLUX.1-dev等MM-DiT模型上显著优于现有训练-free方法,在编辑质量与一致性指标上均达到SOTA水平。值得注意的是,ColorCtrl在保持非编辑区域一致性方面甚至超越了FLUX.1 Kontext Max和GPT-4o等商业模型,其生成结果在色彩和谐度与物理合理性上表现更优。该方法还展现出强大的跨模型泛化能力,可无缝迁移至视频生成模型CogVideoX及指令编辑模型Step1X-Edit,在时序一致性与材质保真度上优势更为显著。通过引入区域颜色保持模块和属性重加权机制,ColorCtrl在无需人工调参的情况下实现了从粗粒度到细粒度的全尺度颜色控制,为生成式AI在影视级后期处理和自动化批处理场景的应用提供了新的技术路径。
论文来源:hf
Hugging Face 投票数:16
论文链接:
https://hf.co/papers/2508.09131
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09131
(33) Noise Hypernetworks: Amortizing Test-Time Compute in Diffusion Models

论文简介:
由 Technical University of Munich 等机构提出了 Noise Hypernetworks,该工作通过学习优化初始噪声分布实现扩散模型的测试时计算压缩。核心贡献包括:1) 提出噪声超网络框架,通过训练轻量级网络预测优化后的初始噪声,将测试时噪声优化转化为训练时的单步操作;2) 建立可处理的噪声空间目标函数,通过L2正则化近似KL散度,在保持基础模型分布保真度的同时优化生成质量;3) 在SD-Turbo、SANA-Sprint等模型上验证,恢复了测试时优化的大部分质量提升,同时将推理成本降低至1/30。实验显示该方法在GenEval基准上将SD-Turbo的得分从0.49提升至0.57,超过SDXL的性能,且推理时间仅增加0.1秒。
[原文摘要内容]
论文来源:hf
Hugging Face 投票数:15
论文链接:
https://hf.co/papers/2508.09968
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09968
(34) DreamVVT: Mastering Realistic Video Virtual Try-On in the Wild via a Stage-Wise Diffusion Transformer Framework

论文简介:
由字节跳动智能创作团队等机构提出了DreamVVT,该工作提出了一种基于扩散Transformer的两阶段框架,通过关键帧试穿与多模态引导生成高保真虚拟试穿视频。针对现有方法依赖稀缺配对数据、难以保留服饰细节及保持时间一致性的问题,DreamVVT创新性地引入三个核心机制:首先通过运动相似性采样关键帧,利用视觉语言模型生成服饰描述,并结合LoRA适配器实现多帧一致的高质量试穿图像生成;其次构建包含姿态引导、视频大语言模型解析的多模态输入系统,将关键帧图像与时空特征注入预训练视频生成模型;最后采用轻量级LoRA适配器微调策略,在保持预训练模型时空建模能力的同时,实现对服饰交互细节的精准控制。实验表明,该方法在ViViD和Wild-TryOn基准上均取得SOTA表现,尤其在复杂场景(如360°旋转、动态背景)中展现出显著优势,其VFID指标相较MagicTryON提升25.8%,Garment Preservation得分提升42.3%。该框架通过有效融合未配对数据、预训练模型先验及推理阶段输入信息,在电商广告和娱乐应用中展现出强大的落地潜力。
论文来源:hf
Hugging Face 投票数:13
论文链接:
https://hf.co/papers/2508.02807
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.02807
(35) Lumen: Consistent Video Relighting and Harmonious Background Replacement with Video Generative Models

论文简介:
由北京大学等机构提出了Lumen,该工作基于大规模视频生成模型构建了首个支持文本控制的视频重光照框架,通过创新的多域联合训练策略实现影视级光照调整与背景替换。研究者针对视频重光照任务构建了包含20万组配对视频的跨域数据集,其中合成域视频通过Unreal Engine渲染生成,真实域视频采用HDR光照模拟技术构建。为解决跨域数据分布差异问题,研究团队设计了域感知适配器模块,在训练阶段动态切换渲染风格,在推理阶段移除适配器以消除人工痕迹。该框架支持通过文本指令灵活控制光照强度、色温及背景场景,实验表明其在前景保留度(PSNR达23.06)、光照一致性(LPIPS低至0.0741)等指标上显著优于现有方法。论文还提出了"内在一致性"评估指标,通过统一光照转换后的前景相似性度量,有效解决了真实场景下无真值视频的评估难题。项目主页已开源,为影视制作和AR/VR应用提供了高效可靠的视频编辑解决方案。
论文来源:hf
Hugging Face 投票数:12
论文链接:
https://hf.co/papers/2508.12945
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.12945
(36) Cut2Next: Generating Next Shot via In-Context Tuning

论文简介:
由香港中文大学、上海人工智能实验室和南洋理工大学等机构提出的Cut2Next,首次提出Next Shot Generation(NSG)任务,旨在生成符合专业剪辑模式并保持严格电影连续性的高质量后续镜头。该工作针对现有方法仅关注基础视觉一致性而忽视叙事性剪辑模式的问题,创新性地采用层次化多提示策略指导Diffusion Transformer(DiT)生成。通过关系提示定义镜头间编辑风格(如正反打、切入/切出),独立提示控制单镜头内容与摄影属性,结合无需新增参数的上下文感知条件注入(CACI)和分层注意力掩码(HAM)机制,实现多模态信号的高效融合。研究团队构建了包含20万组镜头对的RawCuts数据集和经人工筛选的CuratedCuts数据集,并设计CutBench评估基准。实验显示Cut2Next在视觉一致性(DINO相似度0.4952)和文本保真度(CLIP-T 0.2979)上显著优于IC-LoRA-Cond基线,用户研究更证实其生成结果在电影连续性(93.7%偏好率)和剪辑模式遵循度(96.5%偏好率)上的压倒性优势。该方法为多镜头叙事生成提供了兼顾专业剪辑规范与视觉连续性的新范式,但目前仍受限于人类中心场景且难以处理高动态动作序列。
论文来源:hf
Hugging Face 投票数:12
论文链接:
https://hf.co/papers/2508.08244
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.08244
(37) GENIE: Gaussian Encoding for Neural Radiance Fields Interactive Editing

论文简介:
由Poznan University of Technology和Jagiellonian University等机构提出了GENIE(Gaussian Encoding for Neural Radiance Fields Interactive Editing),该工作通过融合NeRF的高质量渲染能力和高斯溅射(GS)的可编辑性,实现了神经渲染与物理交互的统一。传统NeRF虽能生成高保真图像,但其隐式编码难以直接编辑;而GS虽支持实时渲染和直观操作,却受限于离散表示导致的细节缺失。GENIE创新性地将GS的每个高斯分量赋予可训练特征嵌入,并通过Ray-Traced Gaussian Proximity Search(RT-GPS)算法动态选取k个最近邻高斯,结合多分辨率散列网格实现特征初始化与更新,使高斯位置调整能即时反映在渲染结果中。核心贡献包括:1)Splash Grid Encoding机制,通过空间选择的高斯特征驱动NeRF网络;2)RT-GPS算法将最近邻搜索转化为光线追踪问题,显著降低计算开销;3)支持从手动操作到物理模拟的多模态编辑,如刚体运动、软体变形和布料仿真。实验表明,GENIE在NeRF-Synthetic数据集上保持与SOTA方法相当的重建质量(PSNR 34.67),并首次在Mip-NeRF 360等开放场景中实现可编辑性。该方法不仅解决了神经渲染与几何编辑的兼容性难题,更为虚拟现实、机器人仿真等需要物理交互的场景提供了新范式,代码已开源供社区探索。
论文来源:hf
Hugging Face 投票数:11
论文链接:
https://hf.co/papers/2508.02831
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.02831
(38) The Promise of RL for Autoregressive Image Editing

论文简介:
由Mila – Quebec AI Institute等机构提出了EARL(Editing with Autoregression and RL),该工作通过系统性比较监督微调(SFT)、强化学习(RL)和链式推理(CoT)三种范式,提出了一种基于自回归模型的文本引导图像编辑新方法。研究发现RL结合大模型验证器(如Qwen2.5-VL-72B)能显著提升编辑质量,尤其在复杂编辑任务(如空间关系调整、动作修改)中表现突出。EARL通过将视觉和文本标记统一为自回归生成序列,在OmniEdit、AURORA和VisMin等基准测试中超越了现有扩散模型基线(如Omnigen),且仅使用其五分之一的训练数据。研究还发现CoT推理对性能提升有限,揭示了当前自回归模型在多模态推理整合上的局限性。该工作推动了自回归模型在图像编辑领域的边界,证明了RL在无需真实编辑图像监督下的有效性,同时通过VIEScore指标与GPT4o-mini的结合实现了可靠的编辑质量评估。代码、数据和模型均已开源,为后续研究提供了重要基础。
论文来源:hf
Hugging Face 投票数:11
论文链接:
https://hf.co/papers/2508.01119
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.01119
(39) OneReward: Unified Mask-Guided Image Generation via Multi-Task Human Preference Learning
论文来源:hf
Hugging Face 投票数:11
论文链接:
https://hf.co/papers/2508.21066
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.21066
(40) Precise Action-to-Video Generation Through Visual Action Prompts

论文简介:
由浙江大学、复旦大学、清华大学等机构提出了Precise Action-to-Video Generation Through Visual Action Prompts,该工作提出视觉动作提示作为统一动作表示,通过将复杂高自由度动作(如人手/机械臂交互)渲染为2D骨架等视觉表征,在保持动作精度的同时实现跨域动态迁移。针对现有方法在动作精度与泛化性间的权衡问题,研究者设计了从人类-物体交互视频和机器人操作数据中鲁棒恢复骨架的流程:对野外视频采用四阶段管道解决遮挡问题,对机器人数据通过状态日志渲染并校正骨架。将骨架提示注入预训练视频生成模型(CogVideoX)时,采用ControlNet和LoRA进行轻量微调,并通过区域损失加权强化交互学习。在EgoVid、RT-1和DROID数据集上的实验表明,该方法在PSNR、FVD等指标上超越文本控制(CogVideoX)和原始状态控制(IRASim),尤其在动态准确性(ST-IoU)提升显著(如DROID数据集提升12.3%)。跨域联合训练的统一模型在保持生成质量的同时,实现机器人新技能泛化(如抽屉关闭)和对象一致性增强,验证了视觉提示在复杂交互场景下的精度-泛化平衡能力。
论文来源:hf
Hugging Face 投票数:10
论文链接:
https://hf.co/papers/2508.13104
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13104
(41) FantasyTalking2: Timestep-Layer Adaptive Preference Optimization for Audio-Driven Portrait Animation

论文简介:
由阿里巴巴集团等机构提出了FantasyTalking2,该工作通过时层自适应多专家偏好优化框架(TLPO)解决音频驱动肖像动画中多维偏好对齐难题。研究团队首先构建了多模态奖励模型Talking-Critic,通过410K规模的多维偏好数据集Talking-NSQ实现对生成视频在动作自然度、唇形同步和视觉质量三个维度的精准评估。针对传统偏好优化中多目标冲突问题,TLPO创新性地将偏好解耦为三个轻量级LoRA专家模块,分别针对不同维度进行独立优化,并通过时间步-网络层双感知的融合门机制动态调整专家权重。实验表明,Talking-Critic在偏好对齐准确率上较基线模型提升显著(MN 92.5% vs 63.15%),而TLPO在FID、FVD等指标上分别达到35.438和341.181,较现有SOTA方法提升12.7%-15.0%。该方法通过解耦优化与动态融合机制,有效解决了多目标偏好优化中的竞争冲突问题,在保持动作自然性的同时显著提升了唇形同步精度和视觉质量,为扩散模型在可控生成领域的应用提供了新范式。
论文来源:hf
Hugging Face 投票数:10
论文链接:
https://hf.co/papers/2508.11255
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.11255
(42) TempFlow-GRPO: When Timing Matters for GRPO in Flow Models

论文简介:
由浙江大学与腾讯微信视觉团队提出的TempFlow-GRPO,针对流模型中GRPO方法的时间均匀性假设缺陷,提出了一种基于时间感知的强化学习框架。该工作通过轨迹分支机制与噪声感知加权策略,解决了传统方法因稀疏终端奖励和均匀优化导致的探索效率低、收敛效果差等问题,实现了生成过程中关键时间步的精准信用分配与动态优化强度调节,在人类偏好对齐和文本到图像生成任务中取得SOTA表现。
TempFlow-GRPO的核心创新在于:1)轨迹分支机制通过在特定时间步注入随机性,将终端奖励精确归因到中间决策,无需额外训练过程奖励模型即可实现信用分配;2)噪声感知加权策略根据各时间步固有噪声水平动态调整优化强度,早期高噪声阶段增强探索,后期低噪声阶段侧重稳定优化。理论分析表明,该方法通过调整梯度系数与时间步参数的匹配关系,有效平衡了不同生成阶段的优化贡献。
实验部分,在Geneval和PickScore两大基准测试中,TempFlow-GRPO在4400步内将SD3.5-M模型的Geneval得分从0.63提升至0.97,在PickScore上较Flow-GRPO基线提升1.3%,且仅需100-200步即可追平基线模型性能。消融实验证实轨迹分支与噪声加权分别贡献了5%和9%的性能提升,1024分辨率测试进一步验证了方法的跨尺度有效性。可视化结果表明该方法显著改善了图像细节质量与结构完整性,在复杂纹理生成和错误抑制方面表现突出。
该研究揭示了生成时间步动态特性对优化效果的关键影响,为流模型与强化学习的结合提供了新的理论视角与实践范式,其时间感知的优化思想对其他生成模型的训练优化具有启发意义。
论文来源:hf
Hugging Face 投票数:10
论文链接:
https://hf.co/papers/2508.04324
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.04324
(43) StyleMM: Stylized 3D Morphable Face Model via Text-Driven Aligned Image Translation

论文简介:
由 KAIST 等机构提出了 StyleMM,该工作提出了一种通过文本驱动的对齐图像翻译构建风格化3D可变形人脸模型(3DMM)的框架。该方法基于预训练的网格变形网络和纹理生成器,利用文本引导的图像到图像翻译生成的风格化面部图像作为训练目标,在保持身份、面部对齐和表情不变的前提下,通过图像训练实现一致的3D风格迁移。核心创新包括:1)提出Explicit Attribute-preserving Stylization(EAS)方法,通过稀疏面部关键点、头部旋转和表情参数显式保留源图像属性;2)设计三阶段训练策略(几何预热、形状纹理联合微调、纹理细化)以从稀疏几何信息的风格化图像中提取3D线索;3)引入Consistent Displacement Loss(CDL)增强身份级面部多样性,防止模式崩溃。实验表明,StyleMM在身份多样性、风格化能力和结构一致性方面均优于现有方法,支持显式控制形状、表情和纹理参数,生成具有统一顶点连接性和可动画性的风格化人脸网格。该方法在迪士尼角色、绿皮兽人等风格化场景中展现出优异性能,为影视、动画和游戏制作中的个性化3D头像生成提供了新范式。
论文来源:hf
Hugging Face 投票数:9
论文链接:
https://hf.co/papers/2508.11203
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.11203
(44) Visual Autoregressive Modeling for Instruction-Guided Image Editing

论文简介:
由中科大与HiDream.ai联合提出的VAREdit是一种基于视觉自回归建模的指令引导图像编辑框架,该工作通过将图像编辑重构为多尺度残差预测任务,有效解决了扩散模型存在的编辑区域纠缠和计算效率低下的核心痛点。研究团队创新性地引入Scale-Aligned Reference(SAR)模块,在自注意力机制的第一层注入与目标尺度对齐的源图像特征,突破了传统多尺度条件输入带来的计算冗余与特征错配问题。实验表明,VAREdit在保持512×512分辨率编辑仅需1.2秒(较UltraEdit快2.2倍)的同时,通过GPT-Balance指标在EMU-Edit和PIE-Bench基准测试中分别取得6.77和7.30的分数,较现有扩散模型领先30%以上。该框架不仅实现了编辑精度与生成效率的双重突破,其提出的尺度对齐条件注入机制更为视觉自回归模型在多模态任务中的应用提供了重要范式参考。
论文来源:hf
Hugging Face 投票数:9
论文链接:
https://hf.co/papers/2508.15772
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15772
(45) Multi-human Interactive Talking Dataset

论文简介:
由新加坡国立大学等机构提出的Multi-human Interactive Talking Dataset(MIT),首次聚焦于多人体交谈视频生成这一未被充分探索的领域,旨在突破现有单人对话或面部动画的局限性。研究团队开发了一套自动化数据收集与标注流程,构建了包含12小时高清视频的多人体对话数据集,涵盖2-4位说话者,提供精细的体态姿势与语音交互标注,真实还原多说话者场景中的自然对话动态。为验证数据集价值,团队进一步提出CovOG基线模型,创新性集成多人体姿态编码器(MPE)与交互式音频驱动器(IAD):前者通过聚合个体姿态嵌入实现灵活人数适配,后者基于语音特征动态调节头部运动,共同解决多说话者场景中身份切换、非语言行为建模等核心挑战。实验表明,CovOG在SSIM、PSNR等指标上超越AnimateAnyone等现有方案,并在用户研究中展现出更优的角色一致性与视听同步效果。该研究通过构建首个支持多人体交互的高质量数据集,为社交场景下的视频生成提供了新基准,其提出的自动化标注框架与基线模型为后续研究奠定了技术基础。
论文来源:hf
Hugging Face 投票数:9
论文链接:
https://hf.co/papers/2508.03050
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.03050
(46) LAMIC: Layout-Aware Multi-Image Composition via Scalability of Multimodal Diffusion Transformer

论文简介:
由中科大、Onestory Team和华东师范大学等机构提出了LAMIC,该工作首次将单参考扩散模型扩展到多参考场景的零样本布局感知多图像合成框架。LAMIC基于多模态扩散Transformer(MMDiT)架构,通过Group Isolation Attention(GIA)和Region-Modulated Attention(RMA)两种即插即用注意力机制实现核心突破:GIA通过限制视觉-文本-空间三元组内的局部注意力增强实体解耦,RMA则通过延迟区域融合和跨实体交互指令注入提升布局可控性。为全面评估模型能力,研究团队引入了Inclusion Ratio(IN-R)、Fill Ratio(FI-R)和Background Similarity(BG-S)三项新指标,分别衡量布局控制精度和背景一致性。实验表明,LAMIC在2/3/4参考图像设置下均取得最优表现,尤其在身份保持(ID-S)、背景一致性(BG-S)、布局控制(IN-R)和综合指标(AVG)上全面领先现有方法。值得注意的是,该框架无需任何训练或微调即可实现多参考图像合成,展现出强大的零样本泛化能力。在复杂场景下(如四参考图像),LAMIC的DPG指标与UNO持平,但ID-S和BG-S分别领先8.41和6.46分,凸显其在身份保真和背景合成上的优势。未来研究将聚焦于优化注意力设计以平衡区域边界平滑性与实体解耦效果,并探索提示词与参考图像的早期绑定机制以增强跨实体交互能力。
论文来源:hf
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.00477
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.00477
(47) Artificial Intelligence and Misinformation in Art: Can Vision Language Models Judge the Hand or the Machine Behind the Canvas?
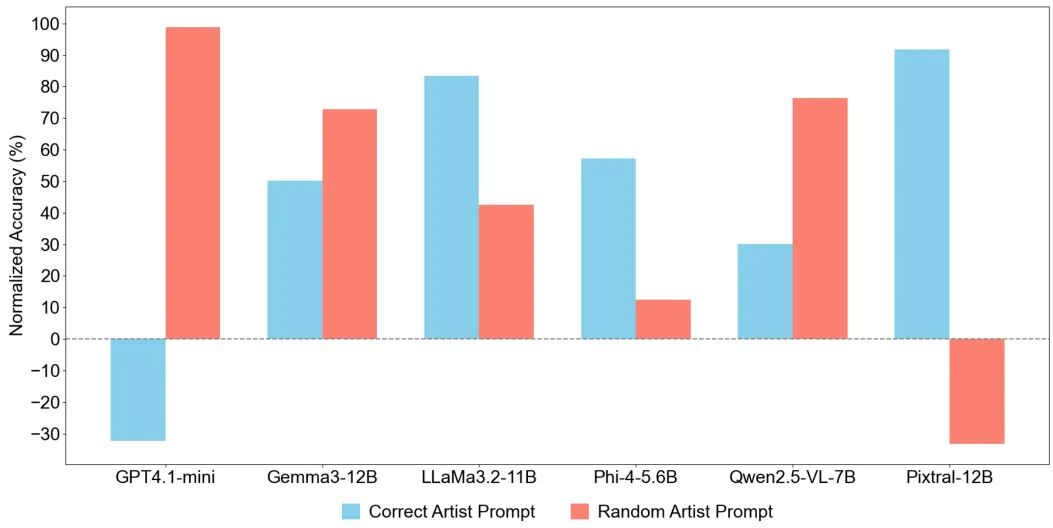
论文简介:
由南京航空航天大学、马德里理工大学、瓦拉多利德大学和内布里哈大学等机构提出了《Artificial Intelligence and Misinformation in Art: Can Vision Language Models Judge the Hand or the Machine Behind the Canvas?》,该工作通过实验评估了当前视觉语言模型(VLMs)在艺术作品归属和AI生成图像识别上的能力局限。研究团队使用近40,000幅128位艺术家的画作及其AI生成仿作,测试了包括GPT4.1-mini、Gemma3-12B、LLaMa3.2-11B等6种主流VLMs的性能。实验表明,VLMs在真实画作归属任务中表现参差不齐,最佳模型Gemma3-12B和LLaMa3.11B的归一化准确率不足40%,且对达芬奇、梵高等名家作品识别准确率接近零。对于AI生成图像,模型表现依赖生成工具(Stable Diffusion、Flux、F-Lite),其中GPT4.1-mini对Flux/F-Lite生成图像的识别准确率超95%,但对Stable Diffusion生成图像易误判。研究揭示了VLMs在艺术领域存在显著风险:用户过度依赖AI可能导致信息误传,尤其在AI生成内容泛滥的背景下,错误标注可能通过自动化系统扩散。论文呼吁谨慎使用VLMs作为决策工具,建议通过数据集公开和模型优化提升可靠性,并提出将生成式AI与艺术鉴定结合的研究方向。
论文来源:hf
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.01408
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.01408
(48) Personalized Safety Alignment for Text-to-Image Diffusion Models

论文简介:
由 Yu Lei 等研究者提出了 Personalized Safety Alignment (PSA) 框架,该工作针对当前文本到图像扩散模型统一安全机制无法满足用户个性化需求的问题,创新性地通过用户安全配置文件实现生成内容的动态安全对齐。研究者构建了包含1000个虚拟用户配置文件的 Sage 数据集,涵盖810个有害概念和10个敏感类别,利用LLM生成用户对安全内容的偏好标签,并设计交叉注意力适配器将用户嵌入向量注入扩散模型的U-Net架构。PSA 通过个性化扩散DPO损失函数优化模型,在生成过程中动态调整安全边界,实验显示其在SD v1.5和SDXL架构上均显著优于SLD、SafetyDPO等基线方法,在I2P和UD等数据集上将有害内容生成概率(IP)降低至0.05-0.12区间,同时保持34.3的CLIPScore语义对齐度。特别在用户偏好对齐评估中,PSA 相较基线模型获得86.2%的胜率提升,并通过5级安全强度调节实现视觉质量与内容过滤的灵活权衡。该研究开创了生成模型个性化安全对齐的新范式,为构建用户中心化的内容生成系统提供了重要技术路径。
论文来源:hf
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.01151
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.01151
(49) Distilled-3DGS:Distilled 3D Gaussian Splatting
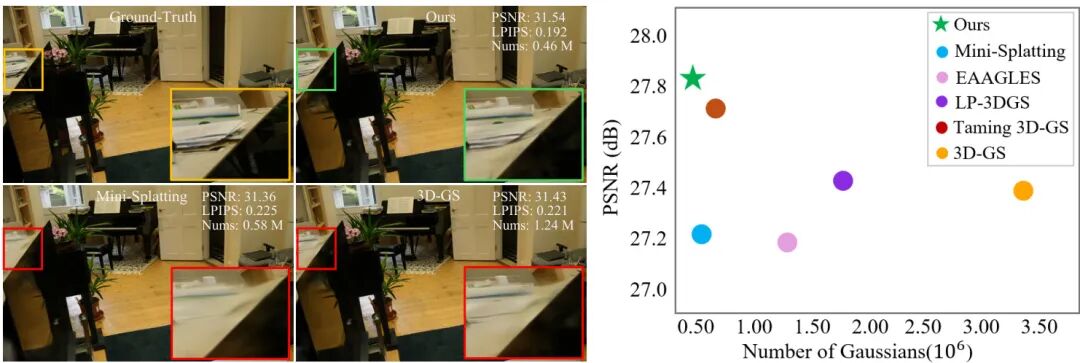
论文简介:
由 Great Bay University 等机构提出的 Distilled-3DGS 提出了一种基于知识蒸馏的轻量化 3D Gaussian Splatting 框架,通过多教师模型引导优化学生模型,在保持高渲染质量的同时显著降低存储需求。该方法针对传统 3DGS 需要大量高斯分布导致内存消耗高的问题,创新性地引入知识蒸馏机制,采用 vanilla 3DGS、噪声增强和 dropout 正则化三个教师模型生成伪标签监督学生模型训练。为解决 3DGS 点云无序性带来的蒸馏难题,研究者提出空间分布一致性损失,通过体素直方图对齐师生模型的几何结构分布,实现结构感知的特征迁移。实验表明,在 Mip-NeRF 360、Tanks&Temples 等数据集上,Distilled-3DGS 在 PSNR、SSIM 和 LPIPS 指标上全面超越 Plenoxels、Instant-NGP 等传统方法,相较原始 3DGS 在减少 86%-89% 高斯数量的情况下仍提升 PSNR 0.55-0.62dB,特别在细节保留和存储效率间取得优异平衡。消融实验验证了多教师模型互补性和空间分布蒸馏的有效性,为资源受限场景下的高质量视图合成提供了新思路。
论文来源:hf
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2508.14037
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.14037
(50) FakeParts: a New Family of AI-Generated DeepFakes

论文简介:
由Hi!PARIS、LIX和U2IS等机构提出了FakeParts,该工作揭示了一类新型AI生成的深度伪造视频——FakeParts,其通过在真实视频中进行局部区域或时间段的细微篡改(如面部表情修改、物体替换、背景调整等),在保留原始视频主体的情况下制造高欺骗性内容。研究团队指出,这类伪造方式因与真实内容高度融合,导致人类观察者检测准确率下降超30%,现有检测模型性能也平均降低43%。为应对这一威胁,团队构建了首个针对局部伪造的基准数据集FakePartsBench,包含2.5万段视频及像素级/帧级标注,涵盖从传统换脸到最新扩散模型生成的多种伪造技术。数据集特别强化了对空间局部篡改(如局部擦除、背景扩展)、时间连续性修改(如帧插值)和风格迁移的标注精度,并引入Sora、Veo2等前沿闭源模型生成的高分辨率内容。实验表明,现有检测方法在FakeParts上普遍失效:传统频率特征检测器在扩散模型内容前失效率达99.6%,而基于CLIP的语义检测器虽对局部篡改更敏感(如对象擦除检测率提升至39%),却难以识别高保真整体伪造。研究强调,FakeParts的隐蔽性源于其利用真实上下文作为掩护,而当前检测模型对细微语义矛盾的捕捉能力不足。FakePartsBench的推出为开发兼顾空间细节与时间一致性的新型检测算法提供了关键资源,其标注体系和评估框架或将重塑深度伪造防御的技术演进路径。
论文来源:hf
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2508.21052
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.21052
(51) ROSE: Remove Objects with Side Effects in Videos

论文简介:
由浙江大学、KunByte AI、北京大学和香港大学等机构提出了ROSE(Remove Objects with Side Effects),该工作针对视频中物体及其副作用(如阴影、反射、光照变化等)的去除问题,通过构建3D渲染驱动的自动化数据生成流程,解决了真实场景配对数据稀缺的难题。研究者系统性地将物体副作用归纳为五类典型场景(阴影、反射、光照、半透明、镜面),并基于扩散Transformer设计了参考式擦除模型,通过引入差异掩码预测机制显式监督副作用区域的识别。实验表明,ROSE在自建的ROSE-Bench基准(含合成与真实数据)上显著优于现有方法,尤其在复杂环境交互场景中展现出更强的泛化能力,为视频编辑中物理一致性修复提供了新范式。
论文来源:hf
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2508.18633
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18633
(52) CannyEdit: Selective Canny Control and Dual-Prompt Guidance for Training-Free Image Editing

论文简介:
由华为香港AI框架与数据技术实验室、香港科技大学以及上海财经大学联合提出了CannyEdit,该工作通过选择性Canny控制和双提示引导实现免训练的高质量区域图像编辑。针对现有方法在文本一致性、上下文保真和编辑无缝性之间的平衡难题,CannyEdit创新性地提出两种技术:1) 选择性Canny控制,通过用户指定可编辑区域掩码,在目标区域解除Canny边缘约束,同时利用反演阶段缓存的控制网输出严格保留未编辑区域细节;2) 双提示引导,结合局部对象编辑提示与全局场景交互提示,确保编辑对象与背景的语义一致性。在真实世界图像编辑基准RICE-Bench上,CannyEdit在编辑平衡性指标上较KV-Edit提升2.93%-10.49%,用户研究显示其编辑结果在与真实图像对比时仅49.2%被普通用户识别为AI生成,专家识别率更低至42.0%,显著优于其他方法76.08%-89.09%的识别率。该方法无需额外训练,基于FLUX模型和Canny控制网实现,支持单次生成多区域编辑,为图像编辑任务提供了灵活高效的解决方案。
论文来源:hf
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2508.06937
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.06937
(53) ObjFiller-3D: Consistent Multi-view 3D Inpainting via Video Diffusion Models

论文简介:
由南京大学等机构提出了ObjFiller-3D,该工作提出了一种基于视频扩散模型的多视角一致3D补全方法,通过适配视频编辑模型解决3D场景补全中的跨视角不一致问题。现有方法依赖多视角2D图像补全,但存在纹理模糊和空间不连续等缺陷。ObjFiller-3D创新性地将视频扩散模型VACE引入3D补全任务,通过分析3D与视频数据的表征差异,采用低秩适应(LoRA)技术将视频模型迁移至3D领域,并设计了360度循环视频生成策略。方法通过渲染3D物体为多视角视频序列,利用视频模型的时序一致性保持几何和纹理的跨视角连贯性,同时支持参考图像引导的条件生成。实验显示,在Objaverse等数据集上,ObjFiller-3D在PSNR(26.6 vs 15.9)和LPIPS(0.19 vs 0.25)等指标上显著超越NeRFiller和Instant3dit等现有方案,重建时间缩短至10分钟内。该方法还拓展至3D场景补全和对象编辑任务,在文化遗产修复等场景展现应用潜力,为高质量3D内容生成提供了新范式。
论文来源:hf
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2508.18271
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18271
(54) Bifrost-1: Bridging Multimodal LLMs and Diffusion Models with Patch-level CLIP Latents

论文简介:
由 UNC Chapel Hill 和 Lambda 等机构提出了 Bifrost-1,该工作通过引入与多模态大语言模型(MLLM)原生对齐的 patch-level CLIP 图像嵌入作为潜在变量,实现了 MLLM 与扩散模型的高效整合。核心创新在于利用 MLLM 自身视觉编码器生成的空间对齐图像嵌入,通过轻量级 ControlNet 适配器注入扩散模型,同时为 MLLM 增加视觉生成分支以预测 patch-level 图像嵌入,从而在保持原始多模态推理能力的前提下实现高保真可控图像生成。实验表明,该方法在图像重建、文本到图像生成等任务上达到或超越现有方法性能,同时训练计算量显著降低。通过解耦训练策略和原生 CLIP 潜在空间对齐,Bifrost-1 在 ImageNet 和多模态基准测试中展现出优异的视觉生成质量与理解能力平衡,为统一多模态生成与理解模型提供了高效解决方案。
论文来源:hf
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2508.05954
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.05954
(55) GSFixer: Improving 3D Gaussian Splatting with Reference-Guided Video Diffusion Priors

论文简介:
由澳门大学、vivo、港中深、西电和大湾区大学等机构联合提出的GSFixer,旨在解决稀疏视图下3D高斯泼溅(3DGS)重建中普遍存在的伪影问题。该方法创新性地构建了参考引导的视频修复模型,通过融合输入视图的2D语义特征(基于DINOv2提取)与3D几何特征(基于VGGT提取),引导视频扩散模型在修复伪影时同步保持语义一致性与几何一致性。研究团队进一步设计了参考引导轨迹采样策略,在迭代优化过程中平衡视图覆盖范围与修复质量,显著提升了稀疏视图重建效果。为验证方法有效性,团队构建了DL3DV-Res基准数据集,首次系统评估生成模型在3DGS伪影修复中的表现。实验表明,GSFixer在DL3DV-Res数据集上将PSNR提升2.16dB、SSIM提升0.067,LPIPS降低0.087,显著优于Difx3D+和GenFusion等前沿方法。在Mip-NeRF 360数据集的3视图重建任务中,GSFixer的PSNR达15.61,较现有最佳方法提升0.44dB。该方法在保持生成内容与输入视图一致性方面展现出突出优势,为稀疏视图3D重建提供了新范式。
论文来源:hf
Hugging Face 投票数:5
论文链接:
https://hf.co/papers/2508.09667
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09667
(56) Dress&Dance: Dress up and Dance as You Like It - Technical Preview
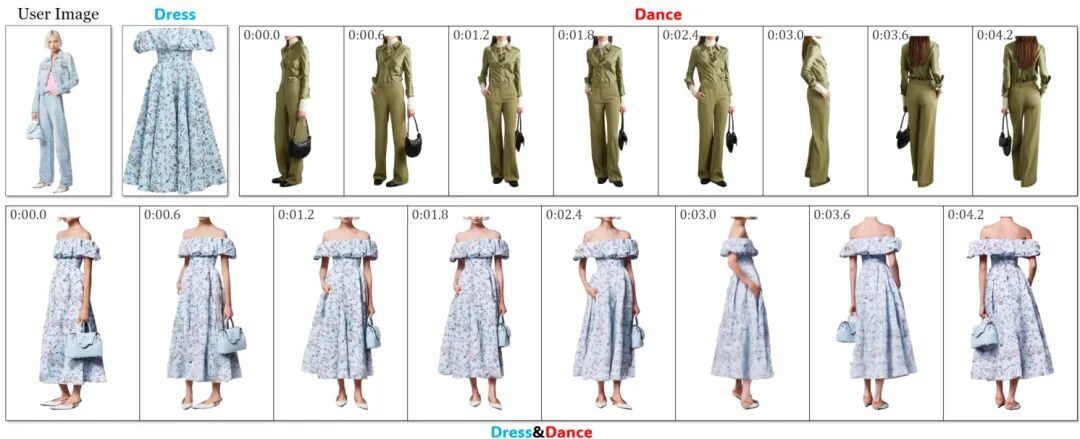
论文简介:
由伊利诺伊大学厄巴纳-香槟分校和SpreeAI的研究人员提出了Dress&Dance,该工作提出了一种视频扩散框架,能够生成5秒24帧/秒、分辨率为1152×720的高质量虚拟试衣视频。用户仅需提供单张人像照片、目标服装图像及一段动作参考视频,模型即可生成穿戴指定服装并匹配动作的动态效果。核心创新点在于CondNet条件网络,通过跨注意力机制统一处理文本、图像和视频多模态输入,有效提升服装定位精度与动作保真度。为解决高分辨率生成的计算挑战,研究团队设计了分阶段渐进式训练策略,结合合成三元组数据增强,实现有限算力下的高质量输出。实验表明,该方法在服装保真度、动作连贯性及视觉质量等指标上全面超越现有开源方案,并与Kling、Ray2等商业模型表现相当。特别在复杂动作生成、多件服装同步试穿及跨人体服装迁移等场景中,Dress&Dance展现出显著优势,例如能准确处理手部遮挡的服装纹理恢复,以及同时试穿上下装时的精准语义理解。研究还构建了包含8万对服装视频的互联网数据集和183人试穿的专用数据集,为后续研究提供基础。这项技术突破为虚拟试衣、数字内容创作等领域提供了更自然生动的解决方案。
论文来源:hf
Hugging Face 投票数:5
论文链接:
https://hf.co/papers/2508.21070
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.21070
(57) Optimization-Free Style Transfer for 3D Gaussian Splats

论文简介:
由东卡罗来纳大学等机构提出了Optimization-Free Style Transfer for 3D Gaussian Splats,该工作提出了一种无需重建或优化的3D高斯泼溅风格迁移方法。通过构建泼溅隐式表面的图结构,采用前馈表面风格化方法并插值回原始泼溅,实现任意风格图像与3D泼溅的快速匹配。该方法无需额外训练或优化,支持消费者级硬件运行,处理速度在2分钟内。核心创新在于将2D图像风格迁移网络适配到3D泼溅表面,通过KNN图构建、法向量估计和局部平面投影实现泼溅点云的卷积操作。实验表明,该方法在保持视觉质量的同时,预处理和风格化总耗时仅1分钟,显著快于现有方法(如G-style的12.5分钟和StyleGaussian的4小时)。通过超采样技术提升细节保留能力,并通过点过滤算法去除噪声泼溅点。局限性包括无法修改几何结构及依赖泼溅隐式表面假设。代码已开源,为3D高斯泼溅风格化提供了高效实用的解决方案。
论文来源:hf
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2508.05813
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.05813
(58) LightSwitch: Multi-view Relighting with Material-guided Diffusion

论文简介:
由卡内基梅隆大学等机构提出了LightSwitch,该工作提出了一种基于材料引导扩散的多视角一致重光照框架。通过结合多视角注意力机制与推断的材料属性(如反照率、粗糙度等),LightSwitch能够高效生成跨视角一致的重光照效果,并支持2D图像与3D场景的高质量重光照任务。传统方法或依赖单视角直接重光照导致视角间不一致,或采用逆渲染方法因物理建模复杂而效率低下。LightSwitch通过改进扩散模型架构,在去噪过程中引入多视角特征交互与材料属性编码,并设计了分布式推理策略以支持任意数量输入视图的高效处理。实验表明,其2D重光照质量在合成数据上超越现有扩散模型基线,在场景级缩放下保持更高一致性;在3D重光照任务中,LightSwitch在合成与真实数据集上均达到与逆渲染方法相当或更优的视觉效果,同时将推理时间从数小时压缩至2分钟内。该方法通过材料属性引导与多视角协同优化,突破了传统重光照任务中效率与一致性难以兼顾的瓶颈,为虚拟现实与视觉特效等应用场景提供了快速可靠的解决方案。
论文来源:hf
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2508.06494
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.06494
(59) SPARSE Data, Rich Results: Few-Shot Semi-Supervised Learning via Class-Conditioned Image Translation

论文简介:
由Guido Manni等机构提出了SPARSE(Semi-supervised Pseudo-labeling via Adversarial Representation tranSlation Enhancement),该工作针对医学图像分类中极端低标注数据场景,提出了一种基于GAN的半监督学习框架。核心创新包括:1)动态交替监督与无监督训练的三阶段框架,通过图像到图像翻译而非生成新图像来增强特征表示;2)集成判别器和分类器的置信度加权时间集成伪标签机制,提升低数据场景下的标签估计可靠性;3)三网络协同架构(生成器、判别器、分类器)实现互补特征学习。实验在11个MedMNIST数据集上验证,5-shot设置下ensemble版本相比SGAN、TripleGAN等6种SOTA方法平均精度提升15.4-38.4%,且在5-50 shot全场景保持优势。该方法通过保留真实医学图像解剖特征的翻译机制,解决了传统生成式方法在低数据场景下的特征失真问题,为标注成本高昂的医疗场景提供了实用解决方案。代码已开源。
论文来源:hf
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2508.06429
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.06429
(60) SpotEdit: Evaluating Visually-Guided Image Editing Methods

论文简介:
由Sara Ghazanfari等研究者提出了SpotEdit,该工作针对视觉引导图像编辑任务构建了首个系统性评估基准,重点解决现有方法在复杂场景和幻觉场景下的性能评估难题。研究团队通过构建包含500个样本的多模态数据集,系统评估了扩散模型、自回归模型和混合生成模型在视觉引导编辑任务中的表现,特别设计了40%的幻觉测试样本用于检测模型对缺失视觉线索的鲁棒性。
SpotEdit的创新性体现在三个方面:首先采用视频关键帧构建数据集,包含多物体复杂场景、多尺度变化和姿态变化,显著提升任务难度;其次设计了包含参考图像、输入图像、文本指令和真值图像的四元组结构,实现编辑结果的定量评估;最重要的是首次引入幻觉评估子集,通过刻意移除参考或输入图像中的目标物体,测试模型在异常情况下的错误编辑行为。
实验结果显示当前主流模型在该基准上表现有限,最强开源模型仅达到0.685的全局相似度得分。模型间呈现互补特性:BAGEL在背景一致性上表现突出但目标编辑能力较弱,OmniGen2能精准遵循视觉引导但背景保持能力不足。特别值得注意的是,GPT-4o在幻觉场景下出现严重错误,其目标物体误检率高达91.7%,揭示了现有模型在异常处理能力上的重大缺陷。
该研究通过构建高难度基准测试集,系统揭示了视觉引导编辑任务的核心挑战,为后续研究提供了明确改进方向。代码和数据集的开源为领域发展提供了重要基础设施,其幻觉评估方法为提升模型鲁棒性提供了新的研究视角。
论文来源:hf
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2508.18159
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18159
(61) The Cow of Rembrandt - Analyzing Artistic Prompt Interpretation in Text-to-Image Models

论文简介:
由米兰大学等机构提出了《The Cow of Rembrandt - Analyzing Artistic Prompt Interpretation in Text-to-Image Models》,该工作通过交叉注意力热图分析文本到图像扩散模型在生成艺术作品时对内容与风格概念的内部表征机制。研究发现,模型在无显式监督的情况下,对不同艺术提示词表现出差异化的分离特性,内容词主要影响主体对象区域,风格词则更多作用于背景纹理,揭示了生成模型对艺术概念的隐式解耦能力。
研究团队通过构建包含16,000个提示词的实验集(涵盖COCO 80类物体与WikiArt 50种艺术风格),利用Stable Diffusion XL模型生成图像并提取跨注意力热图。通过阈值分割生成二值掩码,计算内容-风格词对的IoU值(Δ=0.64),显著低于基线指标(p<0.001),证实两者空间分布的分离性。实验表明动物类内容(如长颈鹿Δ=0.43)与写实风格(如新现实主义Δ=0.39)分离度最高,而人物内容(Δ=0.03)与抽象风格(如抽象表现主义Δ=0.11)分离度最低。特别发现伦勃朗风格(Δ=-0.07)会将人物服饰纳入风格影响区域,印证了训练数据中艺术家创作特征的内化效应。
该研究通过量化分析揭示了扩散模型在艺术生成中"内容-风格"表征的动态特性,为理解生成模型的创作逻辑提供了可解释性工具。代码与可视化工具已开源,支持通过注意力热图探索提示词对图像生成的细粒度影响。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2507.23313
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.23313
(62) WGAST: Weakly-Supervised Generative Network for Daily 10 m Land Surface Temperature Estimation via Spatio-Temporal Fusion

论文简介:
由法国奥尔良大学等机构提出的WGAST,是一种基于弱监督生成网络的每日10米分辨率地表温度(LST)估计方法。该工作针对传统遥感卫星在时空分辨率上的权衡难题,首次构建了端到端的深度学习框架,通过融合Terra MODIS、Landsat 8和Sentinel-2数据,实现了高时空分辨率的LST反演。核心创新在于:1)采用条件生成对抗网络架构,设计四阶段生成器(特征提取-融合-重建-降噪),通过余弦相似度、自适应归一化和时序注意力机制实现跨分辨率特征融合;2)提出物理驱动的弱监督策略,利用30米Landsat LST作为代理标签,解决10米真值数据缺失问题;3)通过引入Landsat 8作为中间分辨率桥梁,避免直接从1km到10m的极端尺度转换;4)仅依赖目标时刻的MODIS数据进行预测,消除对未来时相的依赖。实验表明,WGAST在定量指标上显著优于双三次插值、Ten-ST-GEE等传统方法及FuseTen等混合模型,平均RMSE降低17.18%,SSIM提升11%。其生成的LST在河流热边界、城市热岛效应等细节刻画上优于30米Landsat参考数据,并通过33个地面传感器验证与空气温度呈现0.80-0.95的强相关性。该方法有效解决了Landsat数据云层遮挡问题,为城市规划、灾害响应等场景提供了连续高分辨率热环境监测方案。(498字)
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.06485
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.06485
(63) REGEN: Real-Time Photorealism Enhancement in Games via a Dual-Stage Generative Network Framework

论文简介:
由亚里士多德大学等机构提出了REGEN,该工作提出了一种实时照片级真实感增强的双阶段生成网络框架。针对动态游戏环境中视觉质量与性能难以平衡的问题,REGEN通过结合非配对与配对图像到图像翻译技术,先利用非配对Im2Im方法生成语义一致的高质量数据集,再训练轻量级配对模型实现实时推理。该框架在《侠盗猎车手V》中的实验显示,相比传统非配对方法EPE,REGEN在保持相近视觉效果的同时将推理速度提升32倍,达到30FPS实时性能,且显著优于直接使用轻量级非配对方法CUT的效果。其核心创新在于通过两阶段策略将复杂非配对问题转化为易处理的配对任务,同时无需访问游戏引擎底层信息,适配主流引擎的ONNX部署方案。实验数据表明,REGEN在Fréchet Inception Distance和Kernel Inception Distance指标上与EPE相当,但内存占用更优,为商业化游戏实现实时照片级渲染提供了可行路径。
论文来源:hf
Hugging Face 投票数:0
论文链接:
https://hf.co/papers/2508.17061
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17061
(64) Improving Masked Style Transfer using Blended Partial Convolution

论文简介:
由East Carolina University等机构提出了基于混合部分卷积的掩膜风格迁移方法,该工作针对传统风格迁移算法在局部区域应用时存在的风格特征错位问题,提出将部分卷积集成到风格迁移框架中,通过在卷积操作中嵌入掩膜机制,使网络能够精准聚焦于目标区域进行风格特征提取与重构。实验表明,该方法在SA-1B数据集500张图像的测试中,相较于传统"先风格化后掩膜"方案,地球移动距离(EMD)降低43%(灰度EMD从0.121降至0.086),感知风格损失下降41%(从760降至449),显著提升了局部风格迁移的色彩分布一致性与视觉保真度。研究还创新性地引入了三级混合优化策略:掩膜预羽化处理、卷积动态掩膜扩张、解码器内容特征融合,通过多阶段边界平滑技术将边界梯度幅度降低42%(从142.9降至82.65),有效消除了风格化区域与背景的接缝 artifacts。此外,该方法支持多掩膜多风格并行处理,在单次前向传递中实现不同区域的差异化风格迁移,通过特征级融合与加权叠加机制,使相邻风格区域过渡自然流畅。代码已开源至GitHub,为图像编辑工具的局部风格化功能提供了高效解决方案。
论文来源:hf
Hugging Face 投票数:0
论文链接:
https://hf.co/papers/2508.05769
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.05769










