关注Arm生态的读者,对其CSS(Compute SubSystem)解决方案应该不会陌生——尤其此前小米玄戒O1发布时,CSS这个名字也为更多人所知。
最近的媒体活动上,Arm高级副总裁兼终端事业部总经理Chris Bergey在答记者问时说,CSS平台上,Arm不仅基于传统IP授权模式提供RTL选择,也可为客户提供用于参考的物理实现方案(physical implementation),乃至与客户合作产出可用于量产的设计方案。这在大约5年前,于传统意义上的软IP供应商,还是不可想象的一件事。
尤其在越来越多的系统企业——如数据中心、手机、汽车等领域的OEM厂商——都倾向于自己设计芯片时,Arm CSS表现出很高的价值。“要将Arm的CPU, GPU等组成部分组合起来是非常重要的工作,但对他们(系统企业)而言并非业务核心。”

Chris说,所以他们从CSS平台看到了价值,因为相较于由客户去雇佣大量专家将Arm的技术融合到一起,尔后基于应用负载增加差异化方案,Arm CSS就可以以较低的成本为他们赋能,并借此实现他们的专业和差异化。这实际上也更符合如今“应用导向的芯片设计”时代背景下,EDA/IP厂商都倾向于为客户提前解决更多共性问题的大趋势。
Arm到目前为止在全球范围内已经有“超过16个CSS技术授权许可,半数是在过去12个月内发生的”——这的确也为Arm创造了新的营收增长点。
Arm在面向不同的应用方向时,有着不同的CSS方案,比如面向数据中心的Neoverse,面向汽车的Zena,面向PC的Niva,面向IoT的Orbis,以及最近Arm Unlocked 2025上海站活动上,刚刚更新的面向移动(Mobility)市场的Lumex。
本次发布的Arm Lumex CSS主要面向手机、平板、可穿戴设备等移动设备,“提供旗舰级CPU和GPU性能”;是基于Armv9架构的最新演进——所以我们也有机会真正认识Arm的新CPU和GPU IP,及系统解决方案与配套软件。
不过更重要的是,这次的IP与平台更新强调 “AI为先”(AI first)——全天的活动,被提起最频繁的一个词大概就是AI了。其实CPU、GPU加入AI推理加速构成,在这个时代已经不罕见了,毕竟几乎所有垂直领域、大部分主流芯片市场参与者都在谈AI。但Arm针对Lumex CSS平台及其之下的IP构成,对AI的支持也是从软硬件两方面下了不少工夫的。

Part 1,Lumex及其AI为先的思路
以往Arm发布新版CPU, GPU及其他IP时,主要谈的通常都是CPU核心的IPC(每周期指令执行数)提升、通用性能变化,GPU的浮点运算、图形渲染及游戏能效改进等;而这次发布会的大量篇幅都放在了AI上。
开场时Chris就说Lumex是为AI时代打造的(built for the AI era)。Arm终端事业部产品管理副总裁James McNiven则说,AI正在重塑个人设备;且在AI负载从传统ML/CV,走向多模态LLM,到现如今Agentic AI的进化过程中,“我们不仅需要更快的CPU, GPU,还需要重新思考整个计算平台。”
基于带宽、延迟、性能等方面的需求,Lumex CSS平台就是实现了紧密协同设计、协同开发,“系统级优化与整合”的计算IP组合,包括CPU, GPU和其他新的系统IP,以及“与合作伙伴共同打造的软件生态”——整体理念就是以“AI为先”。
“Lumex作为一个平台,在此之前我们从未走得如此之远。为之注入的新特性像是为软件开发者提供帮助的共享遥测(shared telemetry);我们也调整了缓存层级结构(cache hierarchies),在电源域(power domain)等方面做了很多工作;我们还围绕物理实现(physical implementation)做了扩展;软件方面的工作...”James谈到,“这些都能帮助客户加速构建,并定制SoC,在CSS平台之上专注于他们(更偏业务层面)的创新。”
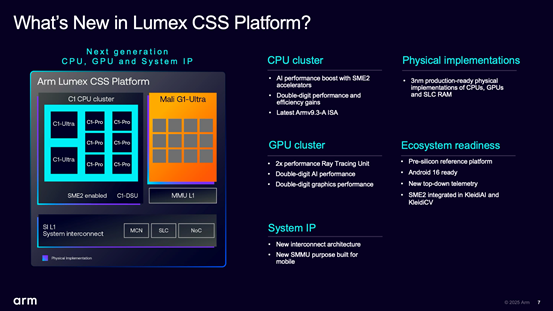
上面这张图囊括了Lumex CSS平台的主要构成:包括C1 CPU集群——尤其新增SME2扩展大幅提升了CPU的AI性能(达成至多5倍性能提升);Mali-G1 GPU集群——AI与图形性能都有两位数提升;系统级IP也有了新的互联架构,针对移动平台所做的新版系统MMU(内存管理单元),“特别针对AI加速了内存路径”,达成“整个平台的性能、效率提升”。
Arm在本次媒体会上,就微架构更新细节谈得不多,这里谈谈其中的关键部分。新的系统IP,主要就是SI L1(系统互连)和MMU L1(内存管理单元)。前者是基于集成SLC(系统级缓存,System Level Cache)和NoC(片上网络,Network on Chip)达成的可扩展相干系统互连,James说这也是提升AI效率的组成部分;后者作为系统内存管理单元,用于支持安全Android和Windows设备的虚拟化实现(基于内存地址转换的虚拟化),而且是在尺寸缩减、具备成本效益的基础上所做的投入。

值得一提的是,Arm将Lumex的新版系统互连架构称作为“channelized”(通道化)架构。James没有特别解释具体是怎么做的,只是谈到相较于先前的互连架构,新架构有利于减少数据搬运工作,能够有效改善功耗、节省面积、管理QoS。实际上Arm在以往的某些技术参考手册中也提过这个词——且基于下面这张示意图,我们大致推测它是指并行数据路径,并且做了流量隔离,同时具备可扩展性、QoS的架构方向。
在SI系统互连“更高性能”,MMU“面积更小”,以及更新NoC(S3)——有助于非旗舰设备尤其对于非一致性(non-coherent)内存系统相当友好,这几点的加持下,系统层面整体上实现了更好的可扩展性或可伸缩性,也就是从旗舰设备到可穿戴设备的覆盖。

另外,CSS平台的物理实现交付一直是很多人相当关注的——物理实现交付应该是Arm去年才开始面向客户提供的。“从物理实现角度来看,我们也新增了选项”,在CPU, GPU之外,还涵盖了SLC物理实现,皆为3nm工艺就绪(3nm production ready)。
当然如文首所述,客户也依旧可以选择传统的软IP。Arm现在之所以开始提供物理实现,就是因为芯片设计、制造工艺的复杂性陡增,尤其系统客户不应将太多时间放在共性技术上,故而由Arm来解决问题——当然这也是新的盈利增长点。“我们的RTL团队和物理实现团队花了很多时间,一起在产品上达成最好的PPA,不管合作伙伴想要自己做实现,亦或直接用我们的物理实现。”

软件和工具方面的更新,主要是面向Android 16做出支持的软件栈,以及后文将着重谈到的对SME2做出抽象层支持的KleidiAI,还有新的“自上至下”的遥测(top-down telemetry)特性等。这部分追求的主要是Arm多名发言人提到的“开发者为先(developer-first)”理念,着眼现在半导体行业常说的在pre-silicon阶段,就率先做出软件开发的支持,并且给开发者提供易用性。

Chris在主题演讲中总结Arm Lumex的几大亮点:跨高端设备,扩展设备上的AI能力——主要是通过CPU获得IPC两位数提升 + 集成SME2,实现AI性能的大幅跨越;新一代Mali GPU加上光线追踪和AI加速能力,移动平台上实现了“桌面品质”的游戏和AI体验;“开发者为先”,跨Arm平台来加速真实场景AI部署。
这番总结基本上就是对Lumex平台之上CPU、GPU、软件工具更新的概括了。接下来,我们就以AI为主要依据,着眼这几个方向,来谈谈新平台、新IP的部分高抽象层级信息——虽然绝大部分内容还是不会涉及到这些新产品的微架构层面。
Part 2,新CPU及其通用性能水平
Arm面向移动平台的新CPU IP已不再用Cortex这个更加广为人知的名称,这次全线基于Armv9.3架构的新核心IP就叫C1——不同规模的CPU核心分别叫C1-Ultra, C1-Premium, C1-Pro, C1-Nano。
其中C1-Ultra用于取代此前的Cortex-X系列;而C1-Premium看起来应该是面向次旗舰的新生态位IP;C1-Pro是相对于以往Cortex-A700系列的迭代;C1-Nano自然就是传统意义上的小核,故而取代的是A500系列。Chris说这个新命名法更加简洁明了,应该会得到行业和合作伙伴的支持(sympathized),且会在未来持续。

Arm这次提供核心层面的通用性能提升数据比较粗略:C1-Ultra单线程峰值性能提升25%;而C1-Premium则在相比C1-Ultra小了35%的基础上同样“提供出色的性能”;C1-Pro达成了出色的持续性能,在游戏中的性能提升达到16%;C1-Nano作为高能效核,功耗缩减了26%;
另外还有C1-DSU(DynamIQ Shared Unit,用于实现核间通信、L3 cache管理、QoS与隔离、性能伸缩等)将这些核心连起来:Arm提供的数据是,搭配C1-Nano,日常使用最多降低26%的功耗;当然它也是覆盖旗舰手机到可穿戴设备、达成不同应用市场可伸缩性的基础。
总体上C1 CPU平均性能提升15%、平均功耗降低12%(从PPT来看,前面这两项是面向真实应用场景的系统表现,包括视频流播、社交网络、网页浏览等);而Benchmark基准测试的平均成绩提升有30%。虽然就通用计算性能层面来看,这些数字还不够明朗,但明年的新机应该是可以期待一下的。
单独看C1-Ultra,核心性能微观层面尤为值得一提的是IPC的提升。Arm终端事业部产品管理总监Ronan Naughton说自Cortex-X1到C1-Ultra的这6年里,Arm CPU的IPC连续实现两位数提升——关注CPU技术的读者应该知道,这在业内并不容易达成。而和Cortex-X1相比,C1-Ultra的IPC性能提升了超过75%。

C1-Ultra峰值性能相比Cortex-X925提升了25%,从能耗曲线可见相同性能水平下(基于Geekbench 6.3),C1-Ultra节省了28%的功耗(而且从曲线来看应该是在Cortex-X925的峰值性能点)。就通用性能角度看,这个核心的代际提升表现还是相当不错的。

而C1-Premium如前所述,是个全新定位的核心IP,介于传统意义上大核心与中核心之间的“次旗舰”(sub-flagship)定位。从系统层面来看,Arm预期将其应用在追求能效和面积效益的AP SoC中:采用这类AP SoC的终端设备可构成“次旗舰”。
比如采用2个C1-Premium核心 + 6个C1-Pro核心这种组合方式,相比2 C1-Ultra + 6 C1-Pro的组合,面积节省超过35%——似乎主要是通过精简矢量单元、L2 cache及优化物理实现达成的(只不过没说性能损失),而其单线程性能又比C1-Pro高出至多35%,可以说是个追求面积效益与性能平衡点的核心了。

定位中核心的C1-Pro,Arm明确其能效和持续性能释放水平较高,毕竟就像上代Cortex-A700系列,这类核心的发热量也不会太大。此处Arm给出了两组数据,在相同频率下,C1-Pro相比Cortex-A725核心提升至多16%的性能(尤指RHI thread:图形引擎的Render Hardware Interface是很多低层级图形API的一个抽象层,RHI thread就是负责给GPU提交渲染指令的专用线程);而在相同性能下,在诸如视频流播、网页浏览、社交网络等负责中则可实现12%的能效提升。
Arm给出C1-Pro的能效曲线,也是全性能段领先Cortex-A725(如上图):每瓦性能至多提升11%,同性能则至多降低了26%的功耗——这两个值应当都是基于SME2的引入,在特定负载下达成的。
基于Arm的“第二代面积优化配置”方案,C1-Pro在不增加面积的情况下实现了性能提升:在保持Cortex-A78核心面积的基础上,以Cortex-A78为单位性能(100%),Cortex-A720的Geekbench 6.1和SPEC2K17性能分别为105%和110%,而C1-Pro则达到了113%和119%;而且需要再度明确的是,这是在加入SME2构成还保持相同面积的前提下——而GB6.1和SPEC2K17则并非偏AI的测试项。

最后是替代Cortex-A500系列的小核心C1-Nano,从能效角度应该也是Lumex体系之中最出色的核心,据说也是Arm现在最高效的小核心;搭配C1-DSU,相较Cortex-A520在相同制造工艺的情况下,能效提升幅度26%;同时SPECint2017性能还高出5.5%;Ronan提到C1-Nano的取指能力得到提升,通过解耦预测与取指管线,在取指敏感型负载中能够达成超过10%的性能提升。

将所有核心“串联”起来的C1-DSU相较上一代降低了11%的典型功耗,同时令RAM在Quick nap(也就是浅睡模式,核心存储单元保持供电,但外围逻辑单元关闭,可确保快速唤醒)之时的功耗降低7%。从可扩展性、效率、带宽的角度,都“对许多设备的日常使用很重要”,包括部分生成式AI负载。
Ronan还特别提到了如果中核+小核组合起来,本代(C1-Pro + C1-Nano)相比上代(Cortex-A725 + Cortex-A520)的计算密度提升了至多2倍——特指SME2加持下的AI性能提升。即便是小核心,也都贯彻了SME2的设计,也是Lumex整体设计以“AI为先”在CPU核心中的体现。
另外就是从AP SoC组合核心的角度来看,从低成本、入门级,到主流、次旗舰、旗舰的不同选择皆有:包括2个C1-Nano核心可面向可穿戴和其他边缘设备;高至2个C1-Ultra + 6个C1-Pro面向旗舰手机。
中间档位的4Nano、2Pro+4Nano、2Pro+6Nano、4Pro+4Nano、1Premium+3Pro+4Nano、2Premium+6Pro等......其间的性能差值有17倍,面积差值25倍,体现的还是面向不同客户需求的配置伸缩性。
Part 3,CPU划重点:SME2加持下的AI能力
以上主要谈到的都是CPU的常规性能提升部分,实际上Arm这次在CPU的技术讲解中,有一半时间是特别给到了AI的:包括本代CPU的AI性能至多提升5倍,能效提升3倍;背后的最大功臣当然就是这次的大热门——SME2了,而且因为全系C1都配了SME2,也就实现了覆盖不同定位设备的可扩展性——包括可能会用上C1-Nano的可穿戴设备。
Chris在谈CPU的时候说,预计到2030年,SME与SME2扩展将为超30亿台设备增加超100亿TOPS的算力,”实现端侧AI能力的指数级飞跃”。所以有必要单独用一个章节来谈属于C1 CPU的AI加成。
从CPU扩展指令集来看Arm对于AI的支持,实际是可以追溯到Armv8-A的SMLAL(Signed Multiply-Accumulate Long)的,往后分别又相继出现了INT8点积(SDOT & UDOT)、矩阵乘(SMMLA & BFMMLA),以及后来更加广为人知的SVE(scalable vector extension)。
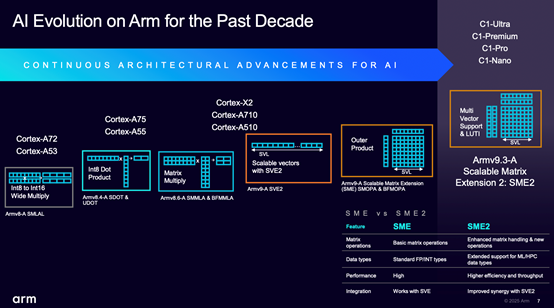
Armv9-A开始应用SME(scalable matrix extension)矩阵扩展初代,一直到这次基于Armv9.3-A的C1问世全系搭载了SME2。这些都可以视作指令集层面对于AI计算的加速。上面这张图右下角的表格给出了SME2相较初代SME的差异——不过现在SME2应当已经作为SME的超集(superset)存在了。
Ronan总结说SME2带来了诸如多矢量加载(multi vector load)、多矢量存储(store)和多矢量乘的能力,简单来说就是以更少的指令完成更多的工作——也是扩展指令的常见思路;另外James在问答环节提到SME2对更小数据类型2 bit、4bit整数做出了支持,James说这对高度量化模型的移动生态非常重要。
就CPU的AI性能,Arm并没有给出特别明确的算力数字,大方向只提到5倍性能提升、3倍能效提升。不过James有在问答环节大致提到,基于芯片的不同规格,SME2可给到的AI算力在2-6TOPS区间。无论这是说INT8还是INT4,就可实践“AI民主”的CPU扩展指令加速来看,2-6TOPS都还是比较理想的数字;对于小语言模型推理,和常见的CV、语音识别类的工作负载还是很有价值的。
在更具体的工作负载上,Ronan给出了几组数字,包括做语音识别(Whisper Base模型)的延迟从1495ms降低到315ms,性能提升4.7倍;LLM模型推理方面,基于Gemma3模型的编码性能从84 tokens/s提升到398 tokens/s,提升幅度4.7倍;还有Stability AI的音乐生成用例(基于Stable Diffusion的模型),生成音乐、音效的时间从将近半分钟缩减到9.7s。

上面这张图展示了不同负载之下,SME2可达成的性能提升:包括生成式AI、传统感知AI,还有非AI负载(比如这里没有展示出来的C1-Pro借助SME2,相比SVE2/Neon可达成libyuv图像处理性能的3倍提升),性能的平均提升幅度为3.7倍。

能效对比方面,James给出的是在跑Geekbench的对象检测子项时,有无SME的功耗与性能差异:这个测试项中,CPU功耗整体降低28%,性能提升12%——是功耗降低同时的性能提升——虽然没有提供绝对值数据还是有些可惜。
事实上所有CPU厂商在推扩展指令集时,都面临开发者的接受程度及生态培养问题——尤其这种偏专用的扩展指令集,真正能动员起开发者响应,才有其存在价值。比如PC领域内,前些年唱衰AVX512的声音就不断,但这两年声势就又起来了,根源就是开发者的接受与否。
所以这里也简单淡淡SME2生态及Arm面向开发者准备的中间件。这次的技术主题演讲中,Arm花了大篇幅去谈KleidiAI,毕竟新CPU的AI加速就依托于它为上层应用服务:当然不止是SME2,应该还包括其他所有AI加速的相关指令。上面这些性能提升数字与KleidiAI也是分不开的。

Arm KleidiAI是介于底层处理器与上层AI框架之间的中间抽象层、软件库,James说过去10年的Arm CPU在包括Neon、SVE2和如今SME2扩展指令之上的加速都靠它。对于很多只涉足AI框架的开发者而言,KleidiAI是不可见的,所以绝大部分开发者不需要关注KleidiAI这一层——实际上KleidiAI支持了业界大部分主流AI框架,包括PyTorch、LiteRT、ONNX、腾讯混元、阿里MNN等。
Chris和James在主题演讲中都特别提到了谷歌LiteRT,由于KleidiAI整合进了XNNPACK(谷歌的神经网络推理库,作为LiteRT的后端存在),故而也就相当于Android的大量AI应用已经用上SME2,或者其他属于Arm CPU的AI加速。当然还有Windows on Arm生态下,KleidiAI融入进了ONNX Runtime,该生态达成Arm CPU的AI加速也就水到渠成了。
事实上James展示了不少SME2扩展指令集通过KleidiAI实现AI应用加速的案例,受限于篇幅不做展开。不过有一点给我们留下深刻印象的,即对于不同AI模型推理,开关SME2前后的AI性能变化——但这还不是重点,注意下面这张图。
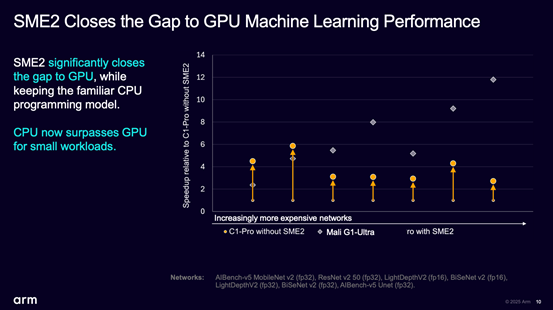
在这些测试项目里,SME2加持的C1-Pro相比关闭SME2的版本,性能提升3-6倍;更重要的是前两个小型网络(MobileNetv2和ResNetv2)中的性能表现甚至超过了GPU(Mali G1-Ultra),虽然绝大部分对比项都是FP32精度,且随网络规模扩大,具备更高并行计算能力的GPU还是能保持领先:这其中自然也有KleidiAI效率上的帮助。
有关生态建设、SME2应用的具体成果,Arm Unlocked 2025上海站活动上参与站台的至少包括了阿里云、支付宝、网易伏羲,以及作为OEM厂商的vivo宣布其加速平台全面支持SME2,和“vivo即将发布的全新X旗舰系列产品”会加入支持;加上Meta、谷歌等国际企业,作为所谓“Day 1”的支持,还真是相当契合当代软件开发“左移”的时代特征。
Ronan说现阶段Arm还在与更多第三方应用合作,包括AI翻译、语音识别等,乃至和游戏引擎合作,丰富SME2加速的AI生态。
CPU部分的最后,谈谈为什么要在CPU之中加入指令集层面的AI加速,而不是完全仰仗GPU, NPU之类更擅长并行计算能力的加速器的问题。这也是个老生常谈的话题了。我们总结了三点:(1)CPU的AI加速具备了最出色的灵活性和可编程性,尤其是对不同数据类型的支持是相当灵活的,且开发者要启用AI加速的编程负担低得多;
(2)对低延迟有要求的小型AI负载还是明显更适用CPU来做AI加速的,比如音乐生成、语音识别、个性化商品的实时推荐等,毕竟启用独立加速器的延迟会明显高一个量级——这就像游戏的AI超分也倾向于用GPU内置的张量加速单元,而不是去选择外部NPU,这是一个道理;
(3)CPU之中加入AI加速,也更有利于所谓的“AI民主”,也就是普及AI技术。不仅是GPU、NPU作为加速器加入SoC之中会增加成本,是某些入门级应用无法承担的;而且GPU和NPU也很大程度面临一定的市场碎片化问题,尤其NPU连行业标准都不存在,这就给AI在终端应用的普及,以及开发者聚集力量去融入AI加速造成了影响。
于是CPU成为其中的最优解,即便在特定负载类型下其效率和性能都未必比GPU、NPU好。
所以Arm对于CPU, GPU, NPU在AI加速上扮演的角色差异认知也很明确,一个词总结就是基于不同类型的AI负载“各司其职”。这也是Intel、苹果、NVIDIA等参与AI竞争的所有企业的共识。
Part 4,GPU同时强化图形与AI性能
基于手游用户对画质要求的提高,以及如虚幻引擎5移动版每个版本更新也在加强图形负载,手游的图形复杂度在不断提升,Arm认为GPU IP还是需要持续强化图形渲染能力。另一方面,如CPU部分提到的,旗舰移动设备的AI加速需求也在提升,GPU始终作为AI加速的重要载体,正在为个人设备提供AI算力,所以加强AI性能也是必须的。
不过随Lumex新平台一同更新的Mali G1 GPU能谈的内容不多,因为Arm并未花太多篇幅去聊这次新IP的架构改进。从PPT来看,Mali G1有3个不同档位:Mali G1-Ultra(10核或更多+RTUv2第二代光追单元)、Mali G1-Premium(6-9核)、Mali G1-Pro(1-5核)。

首先从命名来看,Arm已经确定舍弃此前所用Immortalis这一高端品牌名,所以现在旗舰款的GPU IP同样名为Mali。微架构层面,目前仅知的信息是,虽然前两个月Arm宣布了Arm Neural Technology(神经技术)及对应的NSS(Neural Super Samping)超分即将到来,以及未来Mali GPU的shader核心内部将因此新增AI加速单元,但尚未出现在本次更新的Mali G1之中。
总体上来看,Arm给出Mali G1-Ultra的性能数字包括:14核Mali G1-Ultra比较前代14核Immortalis-G925,图形基准测试与游戏性能提升20%、每一帧的能耗降低9%、光追性能提升2倍,AI/ML推理性能提速20%。
游戏与图形性能方面,在包括《原神》《堡垒之夜》《暗区突围》几款游戏中的性能提升幅度分别为17%、11%、25%,以及在Arm自己的概念演示场景《Mori》之中的性能提升幅度26%。PPT大致提到了几个部分的提升:IRD(Index-Driven Rendering,最小化内存带宽的一种技术), tiler提升;IDVS(Index-Driven Vertex Shading,前述IRD在顶点着色阶段的具体实施)及其计算调度优化......
图形性能部分尤为值得一提的是RTUv2光追单元的更新,James特别在媒体会上演示了3DMark Solar Bay Extreme光追基准测试——关注游戏的读者应该知道,这是个相当复杂的光追重载场景测试,而相比RTUv1的2倍光追性能提升在James看来是能够大幅推升未来手机游戏的视觉体验的。
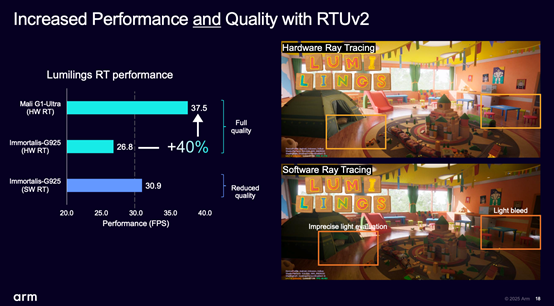
有关RTUv2,虽然现在可知的细节信息仍然不多,但首先它和RTUv1一样也是位于shader核心内部的光追加速单元——也就能随shader核心数量变化做伸缩。另外RTUv2从所谓packed ray model(成组的光线模型)转向了single ray model(单一光线模型)。
前者是指多个光线以batch的方式做并行处理,只不过它会带来光线之间依赖性的复杂度提升;而后者就是指每个RTU管线只处理一条光线,它的价值在于没有依赖性问题,而且实现了细粒度控制且在shader核心之间能做更好的调度——据说是特别适配移动应用这类功耗和带宽敏感型场景的。James说这种新的处理方式也会让画质更好、更真实。
在Arm自己的Lumilings光追测试(基于UE5桌面渲染器)中,同样是画质全开的硬件加速光追、再搭配ASR超分,Mali G1-Ultra相比Immortalis-G925可提升40%的帧率,达到37.5fps的平均帧。这个测试主要用上了虚幻引擎5.5的MegaLights技术,其直接光照路径重在处理大量动态光线,展示的主要是这一代GPU的实时光照与阴影呈现能力。未来的移动光追游戏还是可以期待一下的。
另外在面向开发者时,James提到新的开发工具为开发者提供了细节化的每个帧区域的GPU性能数据,包括基于tile的硬件计数器——每个tile四个硬件计数器,“如此一来开发者对于性能有了更好的可视性”,包括发现画面中的hotspot和瓶颈,以实现进一步的游戏性能优化。另外未来的Android版本会有Vulkan扩展对RenderDoc这一debug工具做出更好的支持。

而在AI性能方面,上面这张图给出了FP32精度下包括图像分类、图像增强、语言处理、语音识别、语义分割等不同AI模型的推理负载上,Mali G1 GPU带来不同程度的性能提升。
架构方面还可以增加一些信息:问答环节,James有提过一句为GPU增加了指令支持,以加速16bit浮点数据的计算;微架构层面对FP32的处理工作进行了优化,某些负载的性能提升2倍(如上图中的语音识别负载);我们猜测核心规模应当也有增大——因为James提到了CPU和GPU都在扩增,“我们在其中做平衡”——具体的,Arm未来应该会公布更多信息。

在我们看来,Arm Lumex整体算得上是移动计算思路的转变:无论是可扩展的C1 CPU核心全系加入了SME2,并借助KleidiAI中间层,达成AI性能5倍提升、能效3倍提升;还是GPU强调图形性能、2倍光追性能提升的基础上,也提升了AI性能;
以及系统层面包括SLC、系统互连、MMU等组成部分皆以“AI优先”的设计思路;还有CSS平台面向芯片设计客户提供RTL或3nm ready物理实现交付的选择;都能体现Chris所说的“Lumex不仅是一组IP 模块,更是专为 AI 从底层打造的全栈式旗舰平台”。
Arm宣传说移动计算的未来都将建基于Arm Lumex(The future of Mobile Compute is built on Arm Lumex)就是以这些新设计为基础的。显然明年的手机和更多移动设备预计会看到更多属于AI的基因。