机器之心编辑部
通义 DeepResearch 重磅发布,让 AI 从 “能聊天” 跃迁到 “会做研究”。在多项权威 Deep Research benchmark 上取得 SOTA,综合能力对标并跑赢海外旗舰模型,同时实现模型、框架、方案全面开源,把深度研究的生产力真正带到每个人手里。
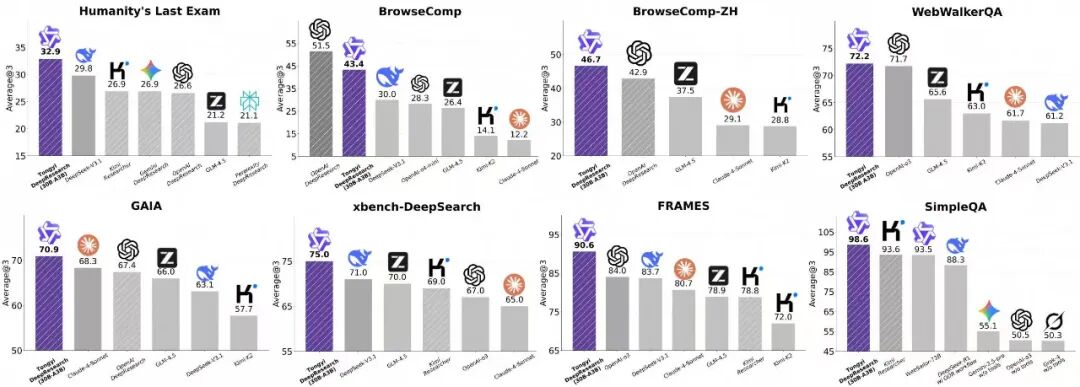
相比于海外的旗舰模型昂贵和限制的调用,通义 DeepResearch 团队做到了完全开源!开源模型,开源框架,开源方案!在 Humanity's Last Exam、BrowseComp、BrowseComp-ZH、GAIA、xbench-DeepSearch, WebWalkerQA 以及 FRAMES 等多个 Benchmark 上,相比于基于基础模型的 ReAct Agent 和闭源 Deep Research Agent,其 30B-A3B 轻量级 tongyi DeepResearch,达到了 SOTA 效果。
通义 DeepResearch 团队也在 Blog 和 Github 完整分享了一套可落地的 DeepResearch Agent 构建方法论,系统性地覆盖了从数据合成、Agentic 增量预训练 (CPT)、有监督微调 (SFT) 冷启动,到强化学习 (RL) 的端到端全流程。尤其在 RL 阶段,该团队提供了集算法创新、自动化数据构建与高稳定性基础设施于一体的全栈式解决方案。在推理层面,模型展现出双重优势:基础的 ReAct 模式无需提示工程即可充分释放模型固有能力;而深度模式 (test-time scaling) 则进一步探索了其在复杂推理与规划能力上的上限。
Homepage: https://tongyi-agent.github.io/
Blog: https://tongyi-agent.github.io/blog/introducing-tongyi-deep-research/
Github: https://github.com/Alibaba-NLP/DeepResearch
Hugging Face: https://huggingface.co/Alibaba-NLP/Tongyi-DeepResearch-30B-A3B
Model Scope: https://modelscope.cn/models/iic/Tongyi-DeepResearch-30B-A3B
1 数据策略:基于全合成数据的增量预训练和后训练
模型能力的提升,主要得益于通义 DeepResearch 团队设计的一套多阶段数据策略。这个策略的核心目标是,不依赖昂贵的人工标注,也能大规模地生成高质量的训练数据。
1.1 增量预训练数据
团队引入了 Agentic CPT(增量预训练)来为模型打下坚实的 Agent 基础。为此,开发了一个系统化、可扩展的数据合成方案。它能利用后续训练流程产生的数据,形成一个数据生成的正向循环。
数据重组和问题构建 基于广泛收集和增量更新的知识文档、公开可用的爬虫数据、知识图谱以及后训练产生的轨迹数据和工具调用返回结果(例如,搜索结果和网页访问记录)等,团队构建了一个以实体为锚定的开放世界知识记忆。进一步,研究者基于采样的实体和相关知识构造多风格的(问题,答案)对,以尽可能涵盖智能体所面临的真实场景。
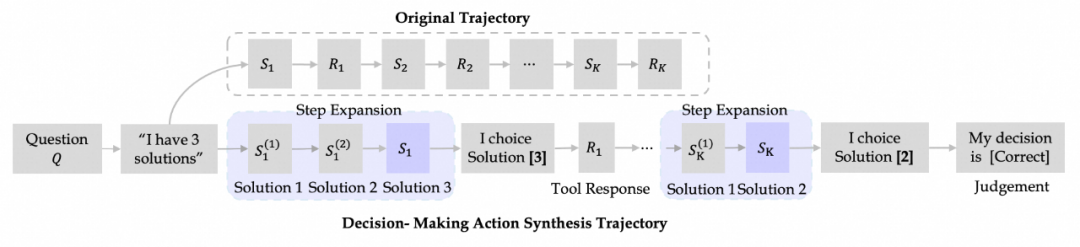
动作合成 基于多风格问题和历史轨迹数据,团队分别构建了三种类型的动作数据,包含规划、推理和决策动作。该方法能够在离线环境下大规模、全面地探索潜在的推理 - 动作空间,从而消除了对额外商业工具 API 调用的需求。特别地,对于决策动作合成,该研究将轨迹重构为多步骤决策过程,以增强模型的决策能力。
1.2 Post-training 数据
通义 DeepRsearch 团队开发了一套全自动的合成数据生成方案,旨在全自动化生成超越人工标注质量的数据集,以挑战模型的能力极限。这个方案经过了多次迭代,从早期的 WebWalker,到更系统的 WebSailor 和 WebShaper,数据质量和可扩展性都得到了保证。
为了生成能应对复杂问题的问答数据,团队开创性得设计了一个新流程。首先,通过知识图谱随机游走和表格数据融合等方式,从真实网站数据中提取信息,保证数据结构的真实性。然后,通过策略性地模糊或隐藏问题中的信息来增加难度。团队将问答难度建模为一系列可控的 “原子操作”,这样就可以系统性地提升问题的复杂度。
为了减少推理捷径,团队还基于集合论对信息搜索问题进行了形式化建模。这帮助他们以可控的方式生成更高质量的问题,并解决了合成数据难以验证正确性的问题。
此外,该团队还开发了一个自动化数据引擎,用于生成需要多学科知识和多源推理的 “博士级” 研究问题。它会让一个配备了网络搜索、学术检索等工具的代理,在一个循环中不断深化和扩展问题,使任务难度可控地升级。
2 推理模式
Tongyi DeepResearch 既有原生的 ReAct Mode,又有进行上下文管理的 Heavy Mode。
2.1 ReAct Mode
模型在标准的 ReAct 模式(思考 - 行动 - 观察)下表现出色。128K 的上下文长度支持大量的交互轮次,团队遵循大道至简,认为通用的、可扩展的方法最终会更有优势。
2.2 Heavy Mode
除了 ReAct 模式外,通义 DeepResearch 团队还开发了 “深度模式”,用于处理极端复杂的多步研究任务。此模式基于该团队全新的 IterResearch 范式,旨在将 Agent 的能力发挥到极致。
IterResearch 范式的创建是为了解决 Agent 将所有信息堆积在一个不断扩展的单一上下文窗口中时出现的认知瓶颈和噪音污染。相反,IterResearch 将一项任务解构为一系列 “研究轮次”。

在每一轮中,Agent 仅使用上一轮中最重要的输出来重建一个精简的工作空间。在这个专注的工作空间中,Agent 会分析问题,将关键发现整合成一个不断演变的核心报告,然后决定下一步行动 —— 是收集更多信息还是提供最终答案。这种 “综合与重构” 的迭代过程使 Agent 能够在执行长期任务时保持清晰的 “认知焦点” 和高质量的推理能力。
在此基础上,团队还提出了 Research-Synthesis 框架:让多个 IterResearch Agent 并行探索同一个问题,最后整合它们的报告和结论,以获得更准确的答案。

3 训练

打通整个链路,引领新时代下 Agent model 训练的新范式
通义 DeepResearch 团队对 Agent model 训练流程进行革新!从 Agentic CPT (contine pre-training) 到 RFT (rejected fine-tuning) 再到 Agentic RL (reinforment learning),打通整个链路,引领新时代下 Agent model 训练的新范式。
端到端 Agent 训练流程
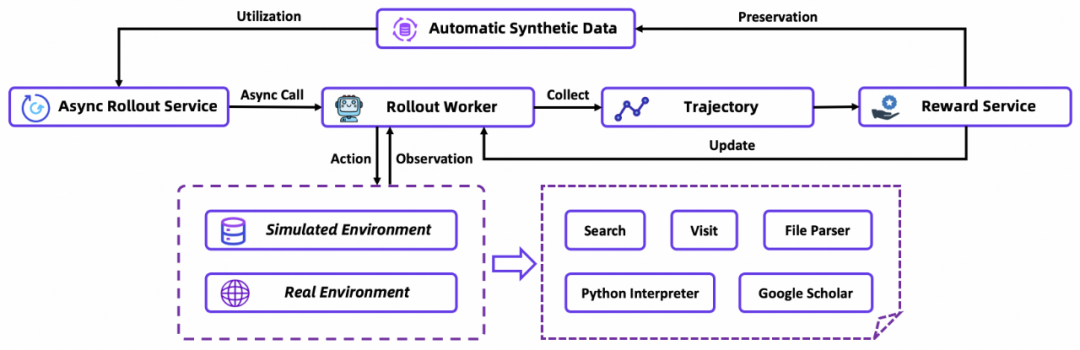
Tongyi DeepResearch Agent 建立了一套连接 Agentic CPT → Agentic SFT → Agentic RL 的训练范式。下面重点介绍该团队如何通过强化学习来完成最后的优化。
基于策略的强化学习(RL)
通过强化学习构建高质量的 Agent 是一项复杂的系统工程挑战;如果将整个开发过程视为一个 “强化学习” 循环,其组件中的任何不稳定或鲁棒性不足都可能导致错误的 “奖励” 信号。接下来,团队将分享他们在强化学习方面的实践,涵盖算法和基础设施两个方面。
在强化学习(RL)算法方面,通义 DeepResearch 团队基于 GRPO 进行了定制优化。他们严格遵循 on-policy 的训练范式,确保学习信号始终与模型当前的能力精准匹配。同时,团队采取了一个 token 级别的策略梯度损失函数来优化训练目标。其次,为了进一步降低优势估计(advantage estimation)的方差,团队采用了留一法 (leave-one-out) 策略。此外,团队发现未经筛选的负样本会严重影响训练的稳定性,这种不稳定性在长时间训练后可能表现为 “格式崩溃”(format collapse)现象。为缓解此问题,他们会选择性地将某些负样本排除在损失计算之外,例如那些因过长而未能生成最终答案的样本。出于效率考虑,该团队没有采用动态采样,而是通过增大批次(batch size)和组规模(group size)的方式,来维持较小的方差并提供充足的监督信号。

训练过程的动态指标显示,模型学习效果显著,奖励(reward)呈持续上升趋势。同时,策略熵(policy entropy)始终维持在较高水平,这表明模型在持续进行探索,有效防止了过早收敛。团队人员将此归因于 Web 环境天然的非平稳性,该特性促进了稳健自适应策略的形成,也因此无需再进行显式的熵正则化。
通义 DeepResearch 团队认为,算法固然重要,但并非 Agentic RL 成功的唯一决定因素。在尝试了多种算法和优化技巧后他们发现,数据质量和训练环境的稳定性,可能是决定强化学习项目成败的更关键一环。一个有趣的现象是,团队曾尝试直接在 BrowseComp 测试集上训练,但其表现远不如使用合成数据的结果。研究者推测,这种差异源于合成数据提供了一致性更高的分布,使模型能进行更有效的学习和拟合。相比之下,像 BrowseComp 这样的人工标注数据,本身就含有更多噪声,加之其规模有限,导致模型很难从中提炼出一个可供学习的潜在分布,从而影响了其学习和泛化(generalize)能力。这一发现对其他智能体的训练同样具有启发意义,为构建更多样、更复杂的智能体训练方案提供了思路。

在基础设施方面,使用工具训练智能体需要一个高度稳定高效的环境:
仿真训练环境:依赖实时 Web API 进行开发成本高昂、速度慢且不一致。团队利用离线维基百科数据库和自定义工具套件创建了一个模拟训练环境来解决这一问题。并且通过 SailorFog-QA-V2 的流程,为该环境生成专属的高质量数据,创建了一个经济高效、快速可控的平台,显著加快了研究和迭代速度。
稳定高效的工具沙盒:为了确保在智能体训练和评估期间对工具的稳定调用,团队开发了一个统一的沙盒。该沙盒通过缓存结果、重试失败的调用以及饱和式响应等改进来高效地处理并发和故障。这为智能体提供了快速且鲁棒的交互环境,可以有效防止工具的错误响应破坏其学习轨迹。
自动数据管理:数据是提升模型能力的核心驱动力,其重要性甚至超过了算法。数据质量直接决定了模型是否能通过自我探索提升分布外泛化能力。因此,团队在训练动态的指导下实时优化数据,通过全自动数据合成和数据漏斗动态调整训练集。通过数据生成和模型训练之间的正向循环,这种方法不仅确保了训练的稳定性,还带来了显著的性能提升。
基于策略的异步框架:团队在 rLLM 之上实现了异步强化学习训练推理框架,多个智能体实例并行与(模拟或真实)环境交互,独立生成轨迹。
通过这些措施,通义 DeepResearch 团队实现了智能体强化训练的 “闭环”。从基座模型开始,团队进行了 Agentic 持续预训练以初始化工具使用技能,然后使用类似专家的数据进行监督微调以实现冷启动,最后进在 on-policy 的强化学习,使模型进行自我进化。这种全栈方法为训练能够在动态环境中稳健地解决复杂任务的 AI 代理提供了一种全新的范例。
4 应用落地
目前通义 DeepResearch 已赋能多个阿里巴巴内部应用,包括:
高德出行 Agent:
高德 App 作为通义在集团内长期共建的重点客户,其 “地图导航 + 本地生活” 的业务场景,以及高德内部丰富的专用工具,具备构建这类 Agent 的土壤,高德也将这类 Agent 能力作为 25 年暑期大版本 V16 的一个亮点功能。通义团队近期在地图 + 本地生活场景,基于纯 agentic+ReAct 执行复杂推理的垂类 agent 技术建设,可以为高德提供更好效果的模型。因此,双方团队共建合作,“通义团队提供模型 + 高德团队提供工具和 Agent 链路”,打造了高德 App 中助手高德小德的复杂查询体验,在地图行业内打出影响力。

通义法睿:
通义法睿,作为大模型原生的 “法律智能体”,致力于为大众及法律从业者提供专业、便捷的法律智能服务。集法律问答、案例法条检索、合同审查、文书阅读、文书起草等功能于一体,全面满足法律用户需求。依托创新的 Agentic 架构与迭代式规划(Iterative Planning)技术,通义法睿全新升级司法 DeepResearch 能力,可高效执行多步查询与复杂推理,实现权威类案精准检索、法条智能匹配与专业观点深度融合。我们以真实判例、官方法规和权威解读为基础,打造可追溯、高可信的法律分析服务,在法律问答的深度研究三大核心维度 —— 答案要点质量、案例引用质量、法条引用质量上领先行业。


通义 DeepResearch 也拥有丰富的 Deep Research Agent 家族。您可以在以下论文中找到更多信息:
[1] WebWalker: Benchmarking LLMs in Web Traversal
[2] WebDancer: Towards Autonomous Information Seeking Agency
[3] WebSailor: Navigating Super-human Reasoning for Web Agent
[4] WebShaper: Agentically Data Synthesizing via Information-Seeking Formalization
[5] WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent
[6] WebResearch: Unleashing reasoning capability in Long-Horizon Agents
[7] ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
[8] WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research
[9] WebSailor-V2: Bridging the Chasm to Proprietary Agents via Synthetic Data and Scalable Reinforcement Learning
[10] Scaling Agents via Continual Pre-training
[11] Towards General Agentic Intelligence via Environment Scaling
通义 DeepResearch 团队长期致力于 Deep Research 的研发。过去六个月,以每月持续发布一篇技术报告,迄今为止已发布五篇。今天,同时发布六篇新报告,并在开源社区发布了通义 DeepResearch-30B-A3B 模型。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com