
在机器人与智能体领域,一个长期的挑战是:当你给机器人一个「去客厅把沙发上的书拿来」或者「沿着楼道走到门口,再右转」这一类指令时,机器人能不能不仅「看见环境」,还能「理解指令」、「规划路径」、然后「准确执行动作」?

之前的许多方法表面上看起来也能完成导航任务,但它们往往有这样的问题:推理(reasoning)的过程不够连贯、不够稳定;真实环境中路径规划与即时控制之间难以兼顾;在新的环境里泛化能力弱等。
Nav-R1 出场:什么是 Nav-R1?

论文标题:Nav-R1: Reasoning and Navigation in Embodied Scenes
论文地址:https://arxiv.org/pdf/2509.10884
这篇题为《Nav-R1: Reasoning and Navigation in Embodied Scenes》的新论文,提出了一个新的「身体体现式(embodied)基础模型」(foundation model),旨在让机器人或智能体在 3D 环境中能够更好地结合「感知 + 推理 + 行动」。简单说,它不仅「看到 + 听到+开动马达」,还加入清晰的中间「思考」环节。
核心创新
1.Nav-CoT-110K:推理轨迹的冷启动(cold-start)基础
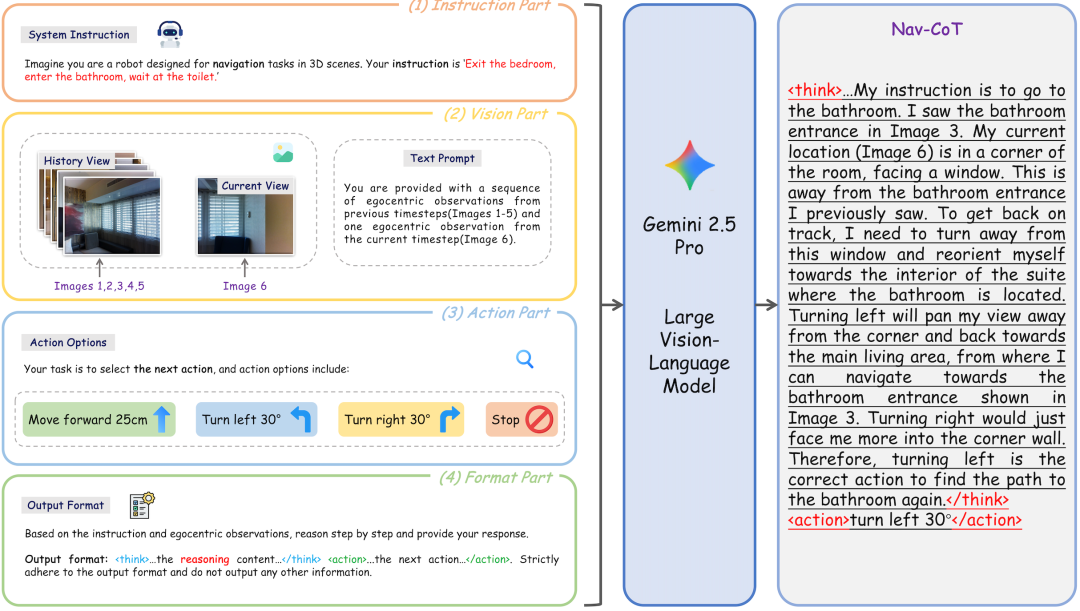
作者构造了一个大规模的数据集 Nav-CoT-110K,包含约 11 万(110K)条 Chain-of-Thought(推理链 / 思考链、CoT)轨迹。每条轨迹里不仅有任务描述(导航指令),还有机器人从环境中看到的 egocentric 视觉输入 (「我从这里看到了墙、看到了桌子、右边是沙发…」 等),以及每一步可能的行动选项,再加上明确格式化的思考与动作输出。
这些轨迹用于冷启动训练(即监督训练阶段),使模型「先学会怎么思考 + 怎么根据环境和指令决定动作」,在进入强化学习 (RL) 优化之前就已有了一个较为稳定的推理与行动基础。
2.三种奖励(rewards):格式、理解、路径

在强化学习阶段,Nav-R1 不只是简单地奖励「到达目的地」,它引入了三种互补的奖励机制,使得行为更精准、更有逻辑、更符合人类期待:
Format Reward(格式奖励):确保模型输出遵守结构化格式,比如有 <think>…</think> 和 <action>…</action> 或 <answer> 等标签的分明区分,这样既便于机器解析,也让内在推理清晰。
Understanding Reward(理解奖励):鼓励模型不仅「走到目标」,还要能语义上理解环境,例如回答场景问题、视觉与语言间对齐、语义正确。包括对正确答案的精确匹配,也包括与视觉输入(如 RGB-D 图像)的语义对齐。
Navigation Reward(导航奖励):关注路径的 fidelity,也就是路径与参考路径的匹配度 (trajectory fidelity)、终点精度 (endpoint accuracy) 等。通过这一奖惩机制,保证机器人走出来的不仅只是到达目的地,而是走出一条合理、不绕弯、不浪费时间的路径。
3.Fast-in-Slow 推理范式:脑子快 + 身体稳
一个非常有意思的设计灵感是借鉴人类认知中的 “双系统理论”(Thinking Fast and Slow 等),即一个系统擅长深思熟虑、长远规划;另一个系统擅长快速反应、实时控制。
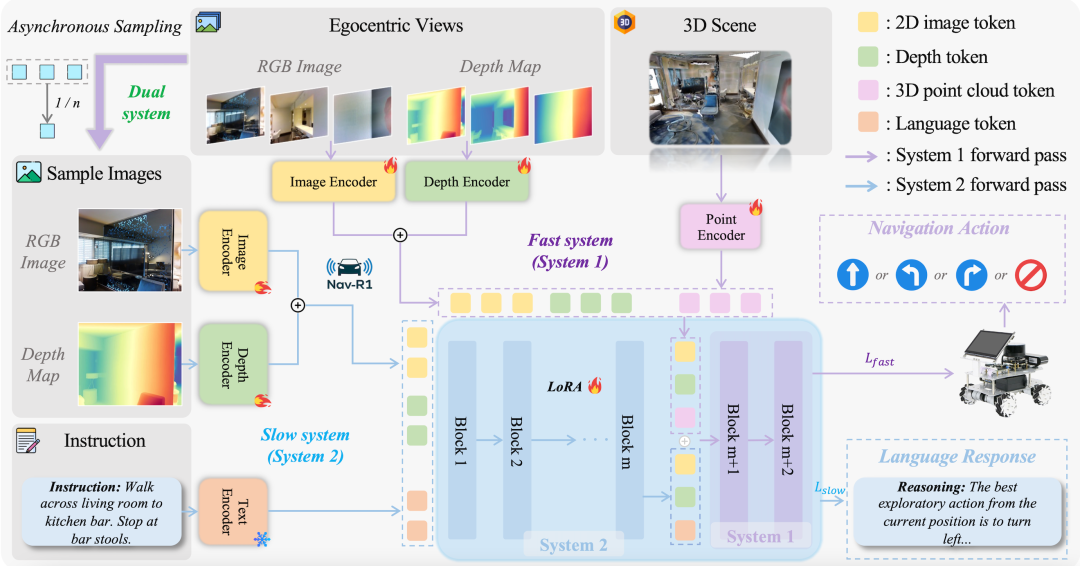
Slow 系统(System-2):以较低频率工作,处理更宏观、更长时段的语义信息和历史观察(视觉历史、语言指令等),负责制定长期目标和语义一致性。
Fast 系统(System-1):以高频率执行,负责即时响应,控制短期动作,比如避障、调整姿态、走直线或转弯等。它借助 Slow 系统的 latent 指导,但自己要轻量、低延迟。
两者异步协调:Slow 提供大致方向和语义指导,Fast 则负责执行,保证在复杂环境中既不丢失目标语义一致性,也能快速响应环境变化。
实验与效果:真的有用吗?
Nav-R1 给出的实验证据很有说服力,既有模拟环境中的各种基准(benchmarks)也有真实机器人部署。
在多个导航任务(如视觉 - 语言导航 Vision-Language Navigation 的 R2R-CE、RxR-CE,以及物体目标导航 ObjectGoal Navigation 等)中,Nav-R1 的成功率(success rate)、路径效率 (SPL, 路径长度加权指标) 等指标相比于其他先进方法提升了约 8% 或更多。

VLN 任务结果

ObjectNav 任务结果
在真实硬件上的部署也通过了测试:机器人平台(WHEELTEC R550,Jetson Orin Nano + LiDAR + RGB-D 摄像头等硬件)在会议室、休息室、走廊这些不同的室内场景中执行导航任务,表现稳健。
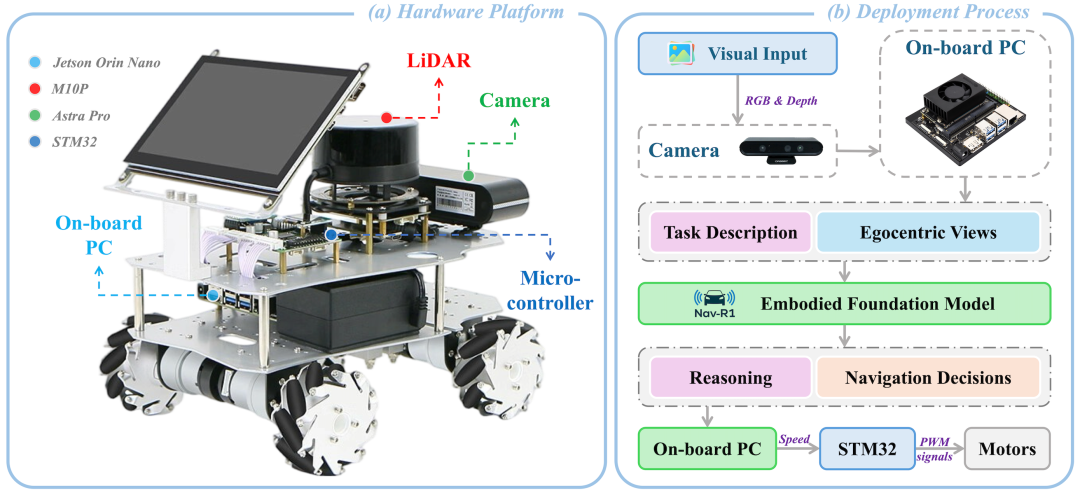
Robot Setup
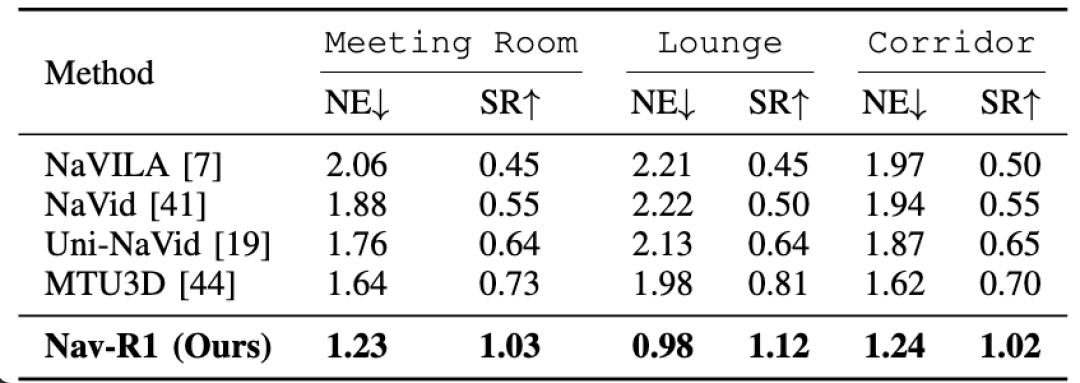
在三个不同的室内环境中进行真实世界实验结果
延迟 / 实时性方面也做了设计优化:Nav-R1 虽然推理能力强,但通过云端推理 + 本地执行命令 + Fast-in-Slow 架构,使得在资源受限的边缘设备上仍可近实时运行(服务器端推理延迟在约 95 ms 左右)对比只在本地推理的大延迟优势明显。

平均推理延迟比较
Demo 展示:从仿真到现实的双重验证
为了让大家更直观地理解 Nav-R1 的能力,研究团队还准备了视频 Demo,涵盖仿真环境和真实机器人环境两类典型场景。
仿真环境:VLN 与 ObjectNav
在 Habitat 仿真平台中,Nav-R1 接收自然语言导航指令,例如「从走廊穿过客厅,到达右边的沙发」。
在 VLN (Vision-Language Navigation) 任务中,Nav-R1 能够理解复杂的语言描述。
指令:Walk past brown leather recliner. Walk through open french doors. Make hard left opposite zebra painting. Wait at mirror.
在 ObjectNav (Object Goal Navigation) 任务中,给定目标类别(如「找到电视显示器」),Nav-R1 会主动探索、识别物体,并规划合理路径,避开障碍物,快速到达目标。
指令:Search for a tv monitor.
真实世界:VLN ObjectNav 机器人部署
研究团队还把 Nav-R1 部署在 WHEELTEC R550 移动机器人平台(配备 Jetson Orin Nano、RGB-D 摄像头和 LiDAR)。在会议室、走廊、休息区等真实场景中,Nav-R1 执行类似的 VLN 指令和 ObjectNav 任务。
在 VLN (Vision-Language Navigation) 任务中,Nav-R1 能够理解复杂的语言描述,并在真实环境中执行指令。
指令:Go to the black chair on your left and pause, then move forward to the front-right and stop at the blue umbrella.
在 ObjectNav (Object Goal Navigation) 任务中,给定目标类别(如「找到电视显示器」),Nav-R1 会主动探索真实环境、识别物体,并规划合理路径,避开障碍物,快速到达目标。
指令:Move straight ahead and look for the keyboard along the wall in front.
意义与应用场景
Nav-R1 它带来了一些比较实际且有影响力的可能性。
1. 服务机器人 / 家庭机器人
在家里,机器人要在杂乱的环境中穿行、按指令找东西、与人交互时,不仅要走得快、走得稳,还要走得「懂」。Nav-R1 的结构化推理 + 路径精准性 + 实时控制恰好能提升用户信心与使用体验。
2. 助老 / 医疗 / 辅助设备
在医院、养老院、辅助设施中,环境复杂,人多物杂,需要机器人能安全、可靠地导航,且对错误能够有语义上的理解与纠正能力。
3. 增强现实 / 虚拟现实
AR 或 VR 中,如果虚拟智能体或助手要在用户的物理环境中导航(或通过视觉输入理解环境为用户指路),这样的推理 + 控制结合非常关键。
4. 工业 / 危险环境
在工厂、矿井甚至灾害现场,机器人需要在未知或危险环境中执行任务。Nav-R1 的泛化能力与稳健性使得它可以作为基础模块进一步应用。
作者介绍
刘庆祥是上海工程技术大学电子电气工程学院在读硕士,研究方向聚焦于视觉语言导航、具身智能。曾参与多项科研项目,致力于构建具备具身世界模型。
黄庭是上海工程技术大学电子电气工程学院在读硕士,Zhenyu Zhang 和 Hao Tang 老师的准博士生,研究方向聚焦于三维视觉语言模型、空间场景理解与多模态推理。曾参与多项科研项目,致力于构建具备认知与推理能力的通用 3D-AI 系统。
张泽宇是 Richard Hartley 教授和 Ian Reid 教授指导的本科研究员。他的研究兴趣扎根于计算机视觉领域,专注于探索几何生成建模与前沿基础模型之间的潜在联系。张泽宇在多个研究领域拥有丰富的经验,积极探索人工智能基础和应用领域的前沿进展。
唐浩现任北京大学计算机学院助理教授 / 研究员、博士生导师、博雅和未名青年学者,入选国家级海外高水平人才计划。曾获国家优秀自费留学生奖学金,连续两年入选斯坦福大学全球前 2% 顶尖科学家榜单。他曾在美国卡耐基梅隆大学、苏黎世联邦理工学院、英国牛津大学和意大利特伦托大学工作和学习。长期致力于人工智能领域的研究,在国际顶级期刊与会议发表论文 100 余篇,相关成果被引用超过 10000 次。曾获 ACM Multimedia 最佳论文提名奖,现任 ACL 2025、EMNLP 2025、ACM MM 2025 领域主席及多个人工智能会议和期刊审稿人。更多信息参见个人主页: https://ha0tang.github.io/

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










