点击下方卡片,关注“具身智能之心”公众号
作者丨Wei Li等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
本篇论文的工作已被 NeurIPS(Conference on Neural Information Processing Systems)2025 接收。
论文题目:CogVLA: Cognition-Aligned Vision-Language-Action Model via Instruction-Driven Routing & Sparsification 论文链接:https://arxiv.org/abs/2508.21046 项目主页:https://jiutian-vl.github.io/CogVLA-page/ 代码仓库:https://github.com/JiuTian-VL/CogVLA
指令:打开抽屉,将玩具放入抽屉,然后将其关上。
指令:打开抽屉,将玩具放入抽屉,然后将其关上。
指令:把T恤折叠起来。
背景:从大模型到具身智能,面临效率困境与语义退化
视觉-语言-动作(VLA)研究在强大的预训练 VLM 所提供的丰富视觉与语言表征推动下,正快速发展。然而,将 VLM 输出的高维多模态特征对齐至连续动作空间仍然计算开销巨大,限制了其大规模部署和实际应用。同时,现有的 VLA 加速方法往往忽视了跨越感知、语言对齐与动作解码的语义耦合,造成严重的跨模态语义退化。
核心挑战:冗余感知与跨模态语义脱节
现有效率优化策略(如层跳过、早期退出)主要聚焦于 VLA 所使用的大语言模型内部的计算优化,忽视了视觉、语言与动作之间的语义耦合。这导致三个问题:
感知冗余:压缩后的视觉信息容易丢失关键细节。 指令-语义脱节:跳过不当的 token 会破坏上下文一致性。 动作不连贯:缺乏跨模态因果推理,生成动作不够稳定。
需要针对 VLA 进行专门适配化设计,才能实现在提升效率的同时保持高性能。
我们的方案:CogVLA——认知对齐的三阶段设计
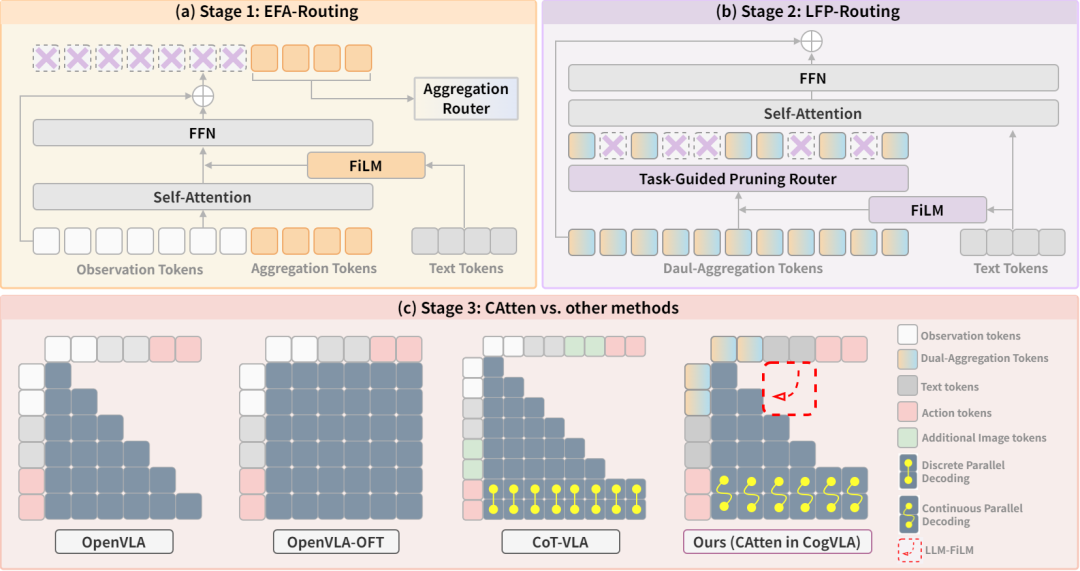
CogVLA 框架概览如下图所示:
传统 VLA 模型在处理初始观测(图 (a))时缺乏视觉压缩,导致计算开销过高。 如图 (b) 与图 (d) 所示,现有压缩方法往往保留无关输入(灰点),未能聚焦于与指令相关的目标(紫点),而CogVLA 通过 EFA-Routing 与 LFP-Routing 基于指令相关性对视觉输入进行稀疏化。 对比图 (c) 与图 (e),CAtten 进一步增强了逻辑一致性与动作连贯性,从而更好地完成目标任务。 图 (f)、图 (g) 和图 (h) 展示了 CogVLA 的架构创新及其在效率与性能上的优越性。

具体来说,CogVLA 借鉴认知科学中的人类多模态协调机制,提出 认知对齐的三阶段稀疏化框架:
EFA-Routing:指令驱动的视觉聚合,压缩冗余信息,仅保留与任务相关的视觉特征。 LFP-Routing:在语言模型中进行语义感知剪枝,过滤掉与动作无关的视觉 token。 CAtten:跨模态耦合注意力,保证语义一致性和动作序列的连贯性,同时支持并行解码。

三阶段渐进式设计示意图。CogVLA 通过指令驱动的路由与稀疏化模拟人类的多模态协同机制。EFA-Routing(阶段 1)、LFP-Routing(阶段 2)以及 CAtten(阶段 3)分别对应视觉注意系统(VAS)、辅助运动区(SMA)与前运动皮层(PMC)。图 (c) 突出了 CAtten 相较于以往注意力机制的优势,包括结合单向与双向注意力、注入动作意图、支持并行解码以及充分利用稀疏视觉 token。
实验结果:性能与效率均领先 OpenVLA-OFT、π0等先进模型
1.CogVLA在仿真评测与真实环境实验中均取得SOTA性能
CogVLA在LIBERO上取得了平均97.4%的最高成功率,同时实现了8×的视觉压缩倍率 CogVLA在一系列真实环境任务中取得最优的子任务成功率和综合成功率,凸显了其与人类对齐的感知规划能力

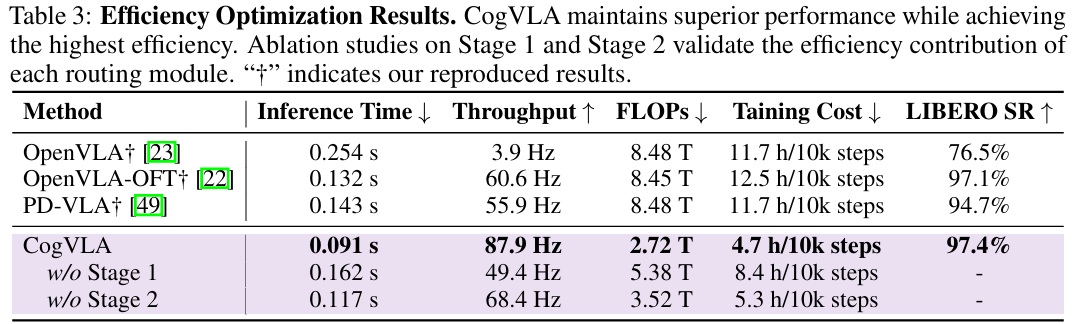
2.CogVLA极大缓解了当前VLA普遍存在的低效难题
与OpenVLA相比,CogVLA的推理时间快2.79倍,吞吐量高22.54倍,FLOP低3.12倍,训练成本降低2.49倍。 CogVLA在训练和推理效率方面也优于OpenVLA OFT和PD-VLA等最先进的高效VLA模型,进一步实现了20Hz的吞吐量提升,以及节省70%的训练时间
可视化分析:精准聚焦与稳定执行的优势
论文通过可视化视觉聚合Token生成的注意力图,进一步凸显了CogVLA的人类感知对齐能力。
如图所示,注意力权重突出显示了输入图像中与任务相关的区域,表明CogVLA的指令感知路由机制有效地引导感知模块关注语义上有意义的区域,即使在混乱或模糊的场景中也能实现强大的视觉基础。












