在机器人统治世界之前,它们可能会先“谋杀掉”人类。
大语言模型幻觉|机器智障
一句错误的指令,在聊天对话框中或许无伤大雅。
但如果这种“错误幻觉”,从数字世界迁移到物理世界,其风险将被无限放大。
比如当一个机器人执行指令时,它可能错拿一瓶致命的药丸、走向一个危险的房间,或者错误识别一个需要帮助的人。
没错,这就是长久以来大语言模型的“幻觉”问题,它也一直被视为其迈向更高智能的核心障碍之一。
而最近,OpenAI发布的一篇文章,就专门讨论了这个“老生常谈”的问题——为什么大模型总是会“胡说八道”?
并且,文中「自曝其短」,给出了一个令人不安的结论:
LLM的“胡说八道”并非一个简单的技术缺陷,而是当前训练和评估体系下的一种必然。
甚至,这种错误的行为模式,一直在被无意的“奖励”着……
简单来说,Open AI揭示:他们在训练过程中无形中奖励了AI的“谎言”,却又要求它在现实世界中提供“真相”。

所以,今天我们就来聊聊:大模型幻觉的成因,并结合具身智能的落地案例,聊聊研究者们正在如何尝试破解这一难题。

幻觉的本质
什么是大模型的幻觉?简单来说,就是它生成了看似合理却完全错误的内容。
那,为什么会这样呢?
OpenAI 给出了一个核心解释:
幻觉不是模型“撒谎”,而是它在训练和评估过程中被推向了“乱猜”。
比如学生做选择题:留空一定是零分,但蒙一个答案也许有机会得分。
大模型的学习过程很类似:比起留空不回答,哪怕是“三短一长选最长”也能够让大模型在训练的过程中得到更高的评分。
在预训练阶段,模型只是根据上下文预测下一个词,就算数据完美,也会不可避免地出现“模式匹配错误”;
在后训练阶段,如果模型说“我不知道”,几乎必然会被当成错误,而如果它“编一个答案”,可能恰好对上,得到奖励。
长此以往,模型就学会了在不确定时“自信地乱说”。
因此,幻觉不是偶尔的 bug,而是统计学习的副作用。

▲图1|OpenAI团队做了一项测试,对主流大模型提问一个随机人名的毕业论文题目是什么,面对这个摸不着头脑的问题,三个主流大模型都通过“瞎猜”给出了答案,没有任何大模型回答“不知道”©️【深蓝具身智能】编译
模型在本质上并没有“知道”与“不知道”的概念,它只是在概率空间里挑选一个最像正确答案的词串。
这种机制在对话场景中还能勉强接受,但一旦放到机器人身上,后果就要严重得多。

幻觉在具身智能里的风险
在具身智能里,幻觉并不是“说错话”那么简单,而是会直接转化为行动偏差。
这里我们聚焦三个最典型、也是最危险的场景:导航幻觉、物体误判、长时任务。
接下来依次具体介绍。
导航幻觉:不确定时也要“先走再说”
现象:
机器人接到“去会议室”的指令,前方拐角区域未完全可见,却依然一路直行。
结果要么走到死胡同,要么撞在玻璃门上。
机制:
在训练和评估中,“移动”往往比“停留”更容易拿分,奖励函数鼓励“保持进度”;
语言先验会在信息稀缺时填补空白,比如“走廊尽头通常是房间”。
于是,在不确定时,机器人倾向于选择自信地往前,而不是停下来收集更多信息。
后果:
路径绕远、效率低,严重时会发生物理碰撞。
例子:
导览机器人把透明玻璃门幻觉成“空旷通道”,在进度奖励驱动下径直撞上去。

▲人行机器人在楼梯上摔倒:楼梯两侧的墙面是反射率很高的不锈钢材质,会让机器人的感知系统误以为这是能够前进的“空旷地带”,因此在机器人初次与墙面发生碰撞后,继续因为认为“前面可行”,而生成置信度最高的“前进”动作,导致进一步撞墙,最终摔倒©️【深蓝具身智能】编译
物体误判:语义正确,几何错误
现象:
家务机器人执行“拿勺子”的指令,看见桌上有个银色长柄物体,就径直去抓。
却发现是把刀。
机制:
VLM 对类别的语义识别更强,但对三维姿态、几何细节建模不足;
数据偏差让模型过度依赖外观特征(闪亮的金属柄=勺子);
稀疏奖励设计下,“快速拿起”就算成功,没有激励它去多角度确认。
后果:
抓错物、姿态错误导致掉落甚至危险。
例子:
在餐桌灯光反射下,刀柄的高光区域被当成“勺沿”,导致机械臂抓取方向完全偏离。

▲分类器(虚线)在某些概念上可能准确,例如拼写(顶部),但错误往往源于模型不佳(中间)或在数据中没有模式的情况下出现的任意事实(底部)。©️【深蓝具身智能】编译
长时任务:小小幻觉,连锁失误
现象:
机器人执行“整理房间”,一开始规划合理:收纳 → 擦拭 → 归位。
但执行两步后,抹布掉到地上被桌子挡住了,它却仍然“认为抹布还在台面上”,继续做后续步骤。
机制:
语言推理链条强调自洽(self-consistency),缺乏状态校正;
奖励函数往往只看“最终完成率”,忽略中途是否会发生一些微小的错误;
因此当环境状态和计划出现偏差时,模型更倾向于“继续演下去”。
后果:
任务越做越乱,效率低下,能耗增加。
例子:
机器人在“假设抹布已收纳”的前提下反复寻找下一个目标,反而在桌边空转浪费大量时间。
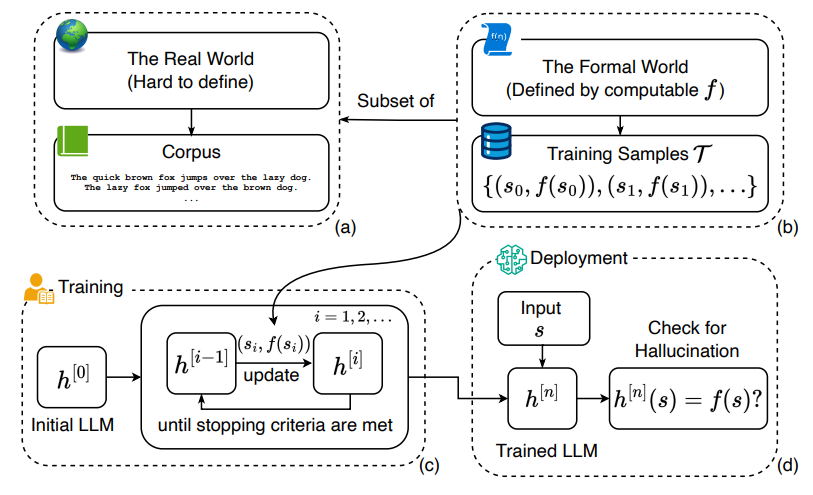
▲幻觉是通过比较LLM的答案与真实值来定义的。©️【深蓝具身智能】编译
小结
这三个场景本质上是一回事:
幻觉让机器人在“不知道”时仍然“装作知道”,而系统奖励和机制往往会推着它这么做。
在聊天里,这最多是笑话;在现实里,这就是潜在的危险。

为什么幻觉难消失?
从表面上看,机器人出现幻觉似乎是“训练没到位”或者“模型粗心大意”。
但 OpenAI 的论文强调:
幻觉不是偶然的 bug,而是大模型架构和训练范式的结构性副产物。
在具身智能里,这些结构性缺陷被进一步放大,主要体现在三个方面:
缺乏真实世界的 grounding
语言模型擅长在文本中找模式,却并不真正理解世界因果。
比如它“知道”走廊通常通向房间,但这只是统计共现,而不是空间几何推理。当机器人依赖这种语言先验来导航时,就容易把“玻璃门”幻觉成“通道”。
结构性原因:训练目标只要求“预测下一个词”,没有迫使模型建立与真实空间的强绑定。
结果:机器人行动时,语言模式与物理现实之间的落差不断累积,导致导航和感知上的幻觉。
感知与语言的脱节
VLM / VLA 的核心优势是把视觉、语言和动作统一到一个空间。
但这种融合往往是“语义主导”的:语言标签覆盖了感知噪声,却掩盖了几何约束。
比如模型可以很自信地说“这就是勺子”,却忽视了手柄角度、物体体积等信息。
结构性原因:视觉信号被压缩进高维 embedding 后,几何细节丢失;训练过程对“识别正确类别”奖励多,对“交互可行性”奖励少。
结果:机器人“看见”但没“看懂”,幻觉在物体识别与操作中频发。
不确定性缺失:不会说“我不知道”
当前大模型几乎没有在输出中显式表达“不确定”的机制。
即便在最模糊的情况下,它也会给出一个自信答案,机器人执行时,等于在“没把握”的情境下仍然盲动。
结构性原因:训练和评估普遍奖励“回答”,而不是“承认不知道”;策略模型里也很少把置信度或熵作为决策依据。
结果:机器人更可能“自信地错误”,而不是“谨慎地停下”。
小结
归根到底,大模型幻觉之所以顽固,是因为现有范式下,“猜一个答案”始终比“说不知道”更有利。
而在具身智能中,这种倾向会被物理执行放大:幻觉不再是信息偏差,而是动作偏差,风险更高。

研究者如何应对?
幻觉难以避免,但并非无解。
OpenAI 在论文中提出:要减少幻觉,就要改变模型在训练和评估中的激励机制,让“不知道”成为可接受甚至被奖励的输出。
这一点在具身智能领域尤其重要,因为机器人如果敢承认不确定,就能用更安全的方式探索环境。
改变奖励:让“不确定”有价值
语言模型的做法:重新设计评估指标,把“拒答”或“表达不确定”视为合理行为,而不是一律扣分。
在机器人中:可以在导航策略里加入奖励,让机器人在不确定时选择“停下观察”“环顾四周”,而不是一味前行。
例子:无人车在识别行人时,如果模型置信度低,就主动减速或触发二次感知,而不是继续加速。
实际上许多自动驾驶的事故,就是由于模型的幻觉,误判了当前的路况,从而产生错误的汽车底盘指令导致的。

▲北大一项最新的研究,通过将错误的轨迹作为学习资源,从错误和不确定性中学习,从而让系统具备了识别偏差轨迹的能力,最终提高了机器人执行任务的成功率©️【深蓝具身智能】编译
相关阅读:成功率提升16.4%!北大董豪团队提出“自我纠错飞轮”:革新视觉语言导航训练范式
多模态融合:让感知制约语言
语言模型的做法:在训练中引入更多模态数据,降低模型对单一文本模式的依赖。
在机器人中:通过视觉、激光雷达、触觉等多传感器融合,校正 VLM 的语义幻觉。
例子:家务机器人在抓取前,不仅依赖图像识别“这是勺子”,还结合力反馈确认是否符合预期形状。
世界模型:先模拟,再行动
语言模型的做法:通过引入内部推理或因果约束,让模型学会检验生成内容的合理性。
在机器人中:世界模型(World Model)可以在虚拟空间中先演练动作,再决定是否执行,降低幻觉直接传导到物理层的风险。
例子:机器人在规划路径时,先在内部地图里“虚拟行走”,发现是死胡同后再调整,而不是撞上去才发现问题。
不确定性感知:学会“谨慎”而非“自信错误”
语言模型的做法:在输出时显式携带置信度或概率分布,而不是只给一个答案。
在机器人中:将熵、方差、跨模态分歧度作为策略输入,让机器人能区分“高置信行动”和“高风险行动”。
例子:在远距离寻找垃圾桶时,如果目标方向的置信度波动很大,机器人就触发主动“look around”,而不是一条路走到黑。

▲港科大的前沿研究提出:通过让大预言模型自我反省,能够减少幻觉的产生©️【深蓝具身智能】编译

总结
大模型的幻觉,在对话里或许只是个笑话,但在具身智能里却可能变成隐患。
导航时走错路、抓取时拿错物、执行长任务时一路错下去……
这些现象背后都源于同一个问题:模型在“不知道”时,习惯“装作知道”。
OpenAI 的最新研究提醒我们,幻觉不是偶然,而是大模型训练范式的自然产物。
要想让机器人真正可靠,研究者们必须重新设计奖励,让“不确定”变得有价值;必须用多模态和世界模型来弥补语言的不足;必须让智能体敢说“我不知道”,而不是自信地乱动。
未来的具身智能不只是“更聪明”,更要“更诚实”。
或许有一天,我们会觉得,一个能停下来说“让我确认一下”的机器人,比一个滔滔不绝却常常犯错的机器人,更值得托付。
编辑|阿豹
审编|具身君
参考文献:
1. Why Language Models Hallucinate
2. Xu Z, Jain S, Kankanhalli M. Hallucination is inevitable: An innate limitation of large language models[J]. arXiv preprint arXiv:2401.11817, 2024.
3. Ji Z, Yu T, Xu Y, et al. Towards mitigating LLM hallucination via self reflection[C]//Findings of the Association for Computational Linguistics: EMNLP 2023. 2023: 1827-1843.
4. Martino A, Iannelli M, Truong C. Knowledge injection to counter large language model (LLM) hallucination[C]//European Semantic Web Conference. Cham: Springer Nature Switzerland, 2023: 182-185.
5. Yu Z, Long Y, Yang Z, et al. CorrectNav: Self-Correction Flywheel Empowers Vision-Language-Action Navigation Model[J]. arXiv preprint arXiv:2508.10416, 2025.
工作投稿|商务合作|转载
:SL13126828869(微信号)
>>>现在成为星友,特享99元/年<<<


【具身宝典】具身智能主流技术方案是什么?搞模仿学习,还是强化学习?|看完还不懂具身智能中的「语义地图」,我吃了!|你真的了解无监督强化学习吗?3 篇标志性文章解读具身智能的“第一性原理”|解析|具身智能:大模型如何让机器人实现“从冰箱里拿一瓶可乐”?|盘点 | 5年VLA进化之路,45篇代表性工作!它凭什么成为具身智能「新范式」?动态避障技术解析!聊一聊具身智能体如何在复杂环境中实现避障
【技术深度】具身智能30年权力转移:谁杀死了PID?大模型正在吃掉传统控制论的午餐……|全面盘点:机器人在未知环境探索的3大技术路线,优缺点对比、应用案例!|照搬=最佳实践?分享真正的 VLA 微调高手,“常用”的3大具身智能VLA模型!机器人开源=复现地狱?这2大核武器级方案解决机器人通用性难题,破解“形态诅咒”!|视觉-语言-导航(VLN)技术梳理:算法框架、学习范式、四大实践|盘点:17个具身智能领域核心【数据集】,涵盖从单一到复合的 7 大常见任务类别||90%机器人项目栽在本地化?【盘点】3种经典部署路径,破解长距自主任务瓶颈!|VLA模型的「核心引擎」:盘点5类核心动作Token,如何驱动机器人精准操作?
【先锋观点】周博宇 | 具身智能:一场需要谦逊与耐心的科学远征|许华哲:具身智能需要从ImageNet做起吗?|独家|ICRA冠军导师、最佳论文获得者眼中“被低估但潜力巨大”的具身智能路径|独家解读 | 从OpenAI姚顺雨观点切入:强化学习终于泛化,具身智能将不只是“感知动作”人形机器人赛道:“爆单”是假,“饥饿”是真。
【非开源代码复现】非开源代码复现 | 首个能抓取不同轻薄纸类的触觉灵巧手-臂系统PP-Tac(RSS 2025)|独家复现实录|全球首个「窗口级」VLN系统:实现空中无人机最后一公里配送|不碰真机也不仿真?(伪代码)伯克利最新:仅用一部手机,生成大规模高质量机器人训练数据!
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

【深蓝具身智能】的内容均由作者团队倾注个人心血制作而成,希望各位遵守原创规则珍惜作者们的劳动成果。
投稿|商务合作|转载:SL13126828869(微信)

点击❤收藏并推荐本文