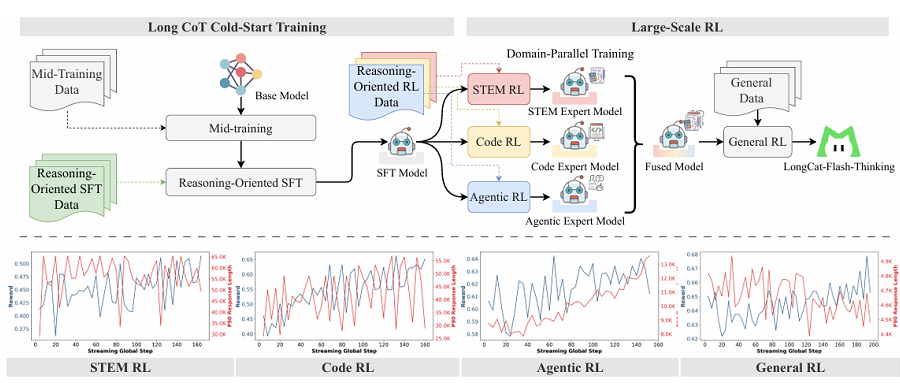
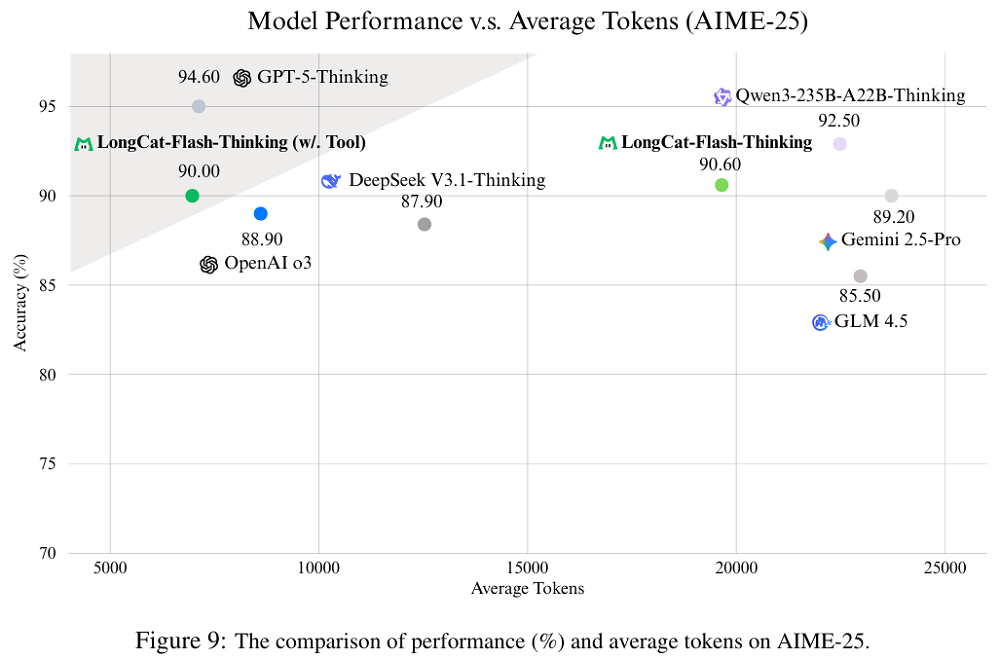
强化学习中,LongCat-Flash-Thinking采用了一套“三管齐下”的方案,从系统、算法和奖励的角度,提升强化学习的效率和稳定性。在系统设计中,LongCat团队构建了名为DORA的分布式RL框架,这是RL训练的基石。DORA支持异步训练与灵活的加速器调度,既保证稳定性,又提升效率。DORA通过流式架构让已完成的响应立即进入训练,而不会被最长输出拖慢;通过多版本策略保证同一响应由同一模型版本完成,避免推理片段间的不一致;再结合弹性角色调度,让不同算力设备可灵活切换角色,实现近乎零闲置。这一机制在大规模算力集群上展现了较高的效率:在数万张加速卡上,LongCat-Flash的RL训练速度达到传统同步方式的3倍以上,FLOPs(Floating Point Operations,浮点运算数)的投入约为预训练阶段的20%。算法层面,团队则对经典的PPO方法进行改良。异步训练常因推理引擎与训练引擎的数值差异,或因旧版本策略生成的数据过多而导致模型收敛不稳。为此,研究人员引入了截断重要性采样来缓解引擎差异带来的误差,并设计了裁剪机制,对正负样本分别设置不同阈值。这些细节调整,大大提高了推理任务下的稳定性。奖励机制是RL的方向盘。对于写作、问答等无法直接验证的任务,团队训练了判别式奖励模型,基于人机联合标注数据,学会判断优劣偏好。而在数学与编程等可验证场景,则引入了生成式奖励模型(GenRM),它不仅能判断对错,还能给出推理链路,做到有理有据。在编程任务中,团队还搭建了分布式沙箱系统,支持数百万次并发代码执行,覆盖20多种编程语言。最后,LongCat团队提出了一个三阶段的训练配方:领域平行训练、模型融合、通用RL微调。LongCat团队先分别训练数学、编程、智能体等专家模型,再通过参数融合技术合并为统一大模型,最后用多样化数据进行通用微调,避免融合后的性能退化,确保安全性、泛化性和实用性。