本文由 Intern-S1 等 AI 生成,机智流编辑部校对
(1) Baseer: A Vision-Language Model for Arabic Document-to-Markdown OCR
论文简介:
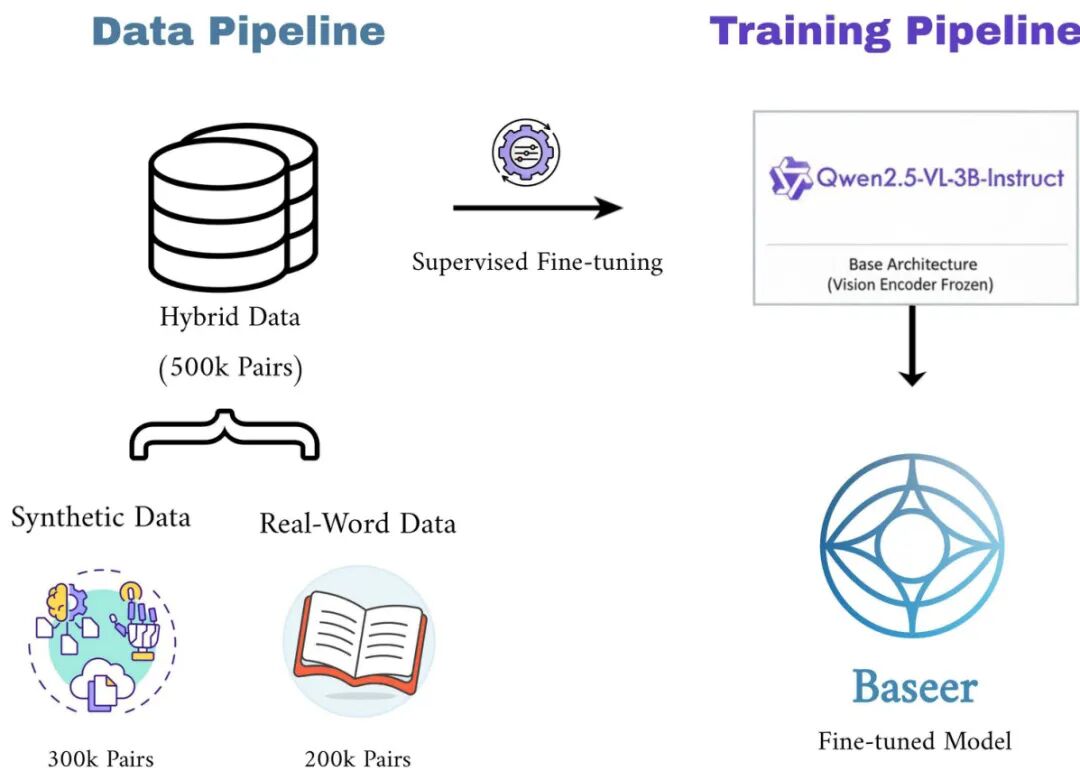
由MISRAJA等机构提出了Baseer,该工作针对阿拉伯语文档OCR的特殊挑战开发了专用视觉语言模型。阿拉伯语因其连笔书写、多变字体、发音符号和右到左书写方向,传统OCR系统难以有效处理。Baseer基于Qwen2.5-VL-3B-Instruct模型,采用解码器微调策略,在包含50万对合成与真实文档的混合数据集上训练,保留预训练视觉特征的同时优化语言适配能力。研究团队同时推出Misraj-DocOCR基准,包含400张专家验证的多样化阿拉伯语文档图像,解决了现有数据集标注错误和多样性不足的问题。实验显示Baseer在Misraj-DocOCR基准上实现0.25的词错误率(WER),显著优于GPT-4、Azure AI等商业系统及开源方案,在文本识别和结构解析指标(TEDS/MARS)均取得最优成绩。该工作证明了领域专用微调策略对多模态大模型的重要性,为形态复杂语言的OCR研究提供了新范式,其开源数据与模型将推动阿拉伯语文档数字化技术发展。
论文来源:hf
Hugging Face 投票数:75
论文链接:
https://hf.co/papers/2509.18174
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.18174
(2) Reinforcement Learning on Pre-Training Data
论文简介:
由腾讯、清华及香港中文大学等机构提出了Reinforcement Learning on Pre-Training Data(RLPT),该工作针对大语言模型(LLMs)面临的数据增长瓶颈,提出通过强化学习在预训练数据上自主探索推理轨迹的新型训练扩展范式。RLPT采用自监督的下一段落预测目标,通过评估模型预测段落与真实段落的语义一致性生成奖励信号,从而摆脱传统RL方法对人工标注的依赖。该方法包含两个核心任务:基于前文预测下一段的自回归段落推理(ASR)和基于前后文预测中间段落的掩码段落推理(MSR),两者交替训练以增强模型的生成与上下文理解能力。
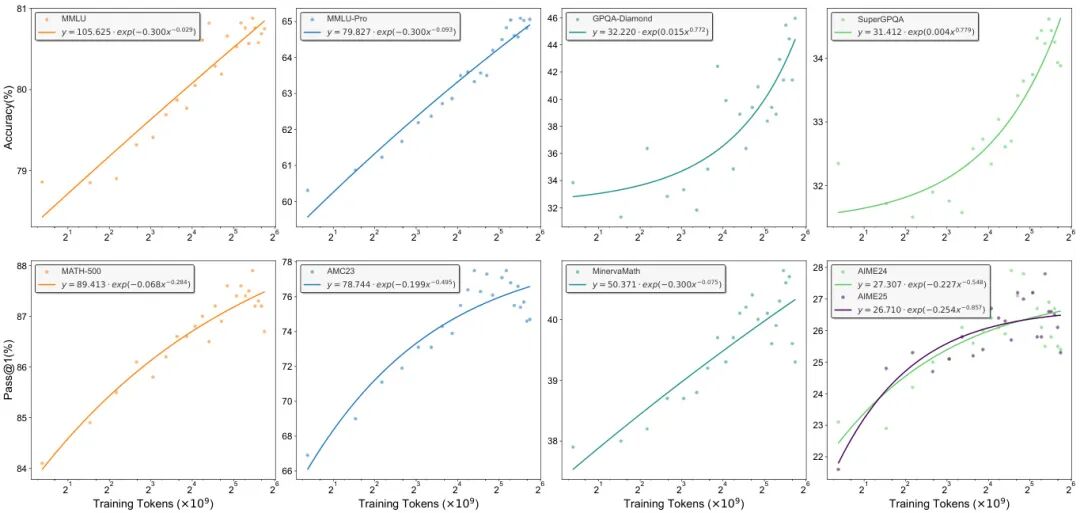
实验在Qwen3、Llama3等多模型上验证,结果显示RLPT在通用领域(MMLU、GPQA等)和数学推理(AIME、MATH等)任务中均取得显著提升。以Qwen3-4B-Base为例,在MMLU、GPQA-Diamond和AIME24上分别提升3.0、8.1和6.6个绝对百分点,且性能随训练算力呈幂律增长,展现出持续优化潜力。进一步分析表明,RLPT可作为强化学习与验证奖励(RLVR)的高效基础框架,在AIME25上叠加RLVR后Pass@1再提升1.3,同时保持探索能力。该研究通过自监督奖励设计和段落级推理目标,为大语言模型的训练扩展提供了新范式,验证了强化学习在预训练数据上的规模化应用可行性。
论文来源:hf
Hugging Face 投票数:39
论文链接:
https://hf.co/papers/2509.19249
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.19249
(3) Do You Need Proprioceptive States in Visuomotor Policies?
论文简介:
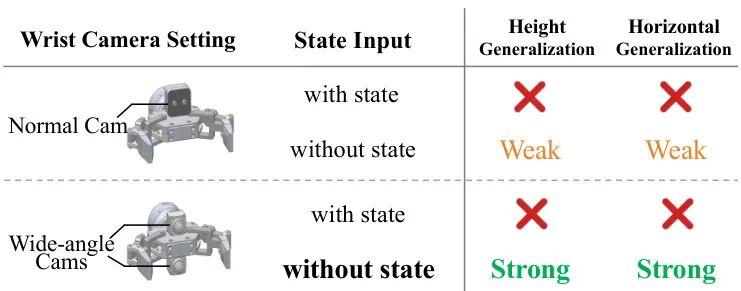
由 Zhao 等研究者提出了 State-free Policy,该工作通过移除本体感觉状态输入并构建基于相对末端执行器动作空间的纯视觉策略,显著提升了机器人操作任务中的空间泛化能力。研究发现,传统视觉运动策略因依赖本体感觉状态输入而过度拟合训练轨迹,导致在高度和水平方向的位置变化中泛化性能急剧下降(如在拾取任务中成功率从100%跌至0%)。State-free Policy 在相对末端执行器动作空间下运行,并通过双广角腕部摄像头(120°×120°视场)确保任务相关视觉信息的完整观测。实验表明,在抓取放置、叠衬衫和全身操作等跨形态任务中,该方法将高度泛化成功率从0%提升至85%,水平泛化成功率从6%提升至64%。此外,State-free Policy 在数据效率方面表现出色,仅需100条演示数据即可维持90%以上成功率,而传统方法在数据不足时性能显著下降。研究还发现移除顶置摄像头后,仅依赖腕部视觉的策略在极端场景(如100cm高度变化)中成功率从0%提升至100%,揭示了纯视觉策略在传感器设计上的优化潜力。该工作为构建更具泛化性的机器人学习系统提供了新思路,相关代码和模型已开源。
论文来源:hf
Hugging Face 投票数:39
论文链接:
https://hf.co/papers/2509.18644
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.18644
(4) MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe
论文来源:hf
Hugging Face 投票数:26
论文链接:
https://hf.co/papers/2509.18154
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.18154
(5) Hyper-Bagel: A Unified Acceleration Framework for Multimodal Understanding and Generation

论文简介:
由字节跳动等机构提出的Hyper-Bagel是一种统一的多模态理解和生成加速框架,该工作采用分治策略通过推测解码和多阶段蒸馏技术,在保持模型性能的同时显著提升计算效率。针对多模态理解任务,研究团队改进了EAGLE-3的推测解码方法,通过元查询特征聚合、零初始化策略和混合损失函数优化,实现超过2倍的推理加速。在生成任务方面,创新性地设计了三阶段蒸馏流程:首先通过控制信号嵌入保留分类器自由引导能力,接着采用多头判别器增强结构一致性,最终通过ODE轨迹匹配蒸馏提升图像保真度,成功将文本生成图像的采样步数从100步压缩至6步,实现16.67倍加速,图像编辑任务更达到22倍加速。为满足实时交互需求,团队进一步开发了1步采样的高效模型,通过对抗扩散预训练和人类反馈学习优化,在保持79.62%基准指标的情况下实现近实时生成。实验表明,6步模型在GenEval和GEdit-Bench等基准测试中超越原模型表现,而1步模型在交互式编辑场景中展现出卓越的实用价值。该框架通过解耦部署策略确保理解能力零损耗,为多模态大模型的实际应用提供了兼顾速度与质量的完整解决方案。
论文来源:hf
Hugging Face 投票数:15
论文链接:
https://hf.co/papers/2509.18824
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.18824
(6) MAPO: Mixed Advantage Policy Optimization
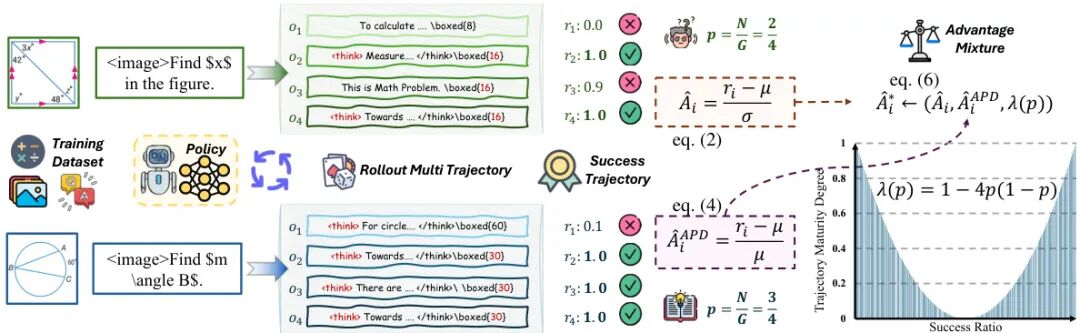
论文简介:
由武汉大学、字节跳动等机构提出了MAPO(Mixed Advantage Policy Optimization),该工作针对Group Relative Policy Optimization(GRPO)中固定优势函数导致的"优势反转"和"优势镜像"问题,提出动态调整优势函数的解决方案。研究发现,不同样本轨迹确定性差异会导致现有优势函数分配失衡:高确定性样本可能因标准差过小产生异常优势值,而低确定性样本则难以获得有效梯度信号。MAPO通过引入轨迹确定性评估机制,创新性地采用优势百分比偏差(APD)替代传统Z-score标准化,并设计轨迹确定性重加权(TCR)策略,根据样本确定性动态融合标准差敏感型与均值敏感型优势函数。在Qwen2.5-VL-7B模型上的实验表明,该方法在几何推理(Geo3K)和情感分析(EmoSet)任务中分别取得54.41%和77.86%的准确率,较基线提升显著。通过动态适配不同确定性样本的优势分配策略,MAPO有效缓解了传统GRPO方法在复杂推理任务中的优化困境,为大模型后训练优化提供了新的技术路径。
论文来源:hf
Hugging Face 投票数:14
论文链接:
https://hf.co/papers/2509.18849
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.18849
(7) VolSplat: Rethinking Feed-Forward 3D Gaussian Splatting with Voxel-Aligned Prediction
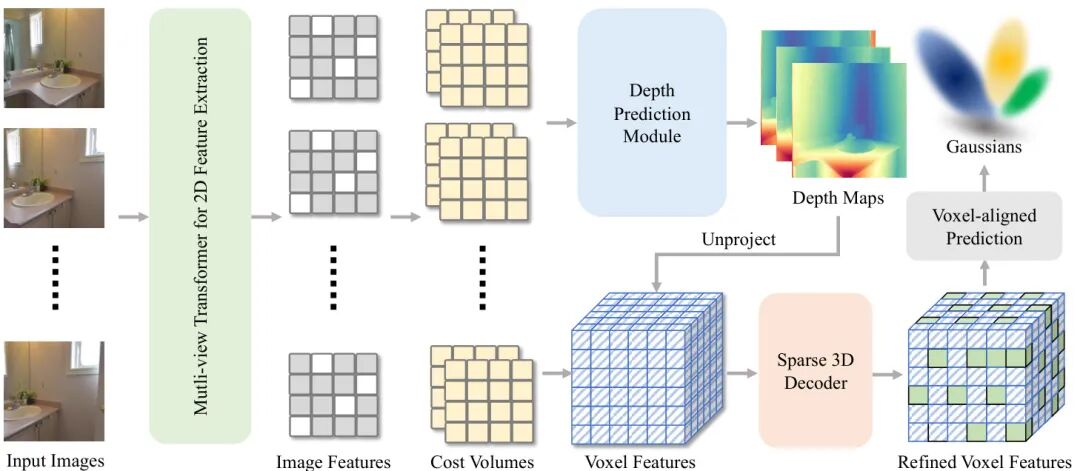
论文简介:
由浙江大学、GigaAI等机构提出了VolSplat,该工作重新设计了前馈式3D高斯泼溅的范式,通过体素对齐预测替代传统的像素对齐机制,解决了多视图重建中的几何一致性难题。现有像素对齐方法存在三大缺陷:重建结果过度依赖输入视图数量、视图偏差导致的密度分布失真、以及遮挡/低纹理区域的对齐误差。VolSplat的核心创新在于构建3D体素特征网格,直接从中预测高斯分布,通过体素对齐机制消除2D特征匹配的误差传递,实现多视图信息的鲁棒融合。其技术路线包括:1)利用Transformer网络提取2D特征并构建代价体;2)通过深度预测模块将2D特征提升至3D体素空间;3)采用稀疏3D U-Net进行特征细化;4)在每个体素内预测自适应密度的高斯参数。实验表明,该方法在RealEstate10K和ScanNet数据集上分别取得31.30/0.941/0.075和28.41/0.906/0.127的PSNR/SSIM/LPIPS指标,较像素对齐方法提升显著。其体素对齐机制不仅解决了传统方法在复杂场景下的漂浮伪影问题,还通过自适应高斯密度控制(如浴室场景中角落区域的高密度采样)实现了更真实的几何重建。消融实验证实体素尺寸(默认0.1cm)和3D解码器结构对性能的关键作用,验证了体素化表征在跨数据集泛化(ACID数据集零样本测试PSNR达32.65)和计算效率(每场景65k高斯)上的综合优势,为实时3D重建提供了新的技术路径。
论文来源:hf
Hugging Face 投票数:13
论文链接:
https://hf.co/papers/2509.19297
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.19297
(8) Lyra: Generative 3D Scene Reconstruction via Video Diffusion Model Self-Distillation
论文来源:hf
Hugging Face 投票数:9
论文链接:
https://hf.co/papers/2509.19296
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.19296
(9) What Characterizes Effective Reasoning? Revisiting Length, Review, and Structure of CoT
论文来源:hf
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2509.19284
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.19284
(10) Large Language Models Discriminate Against Speakers of German Dialects
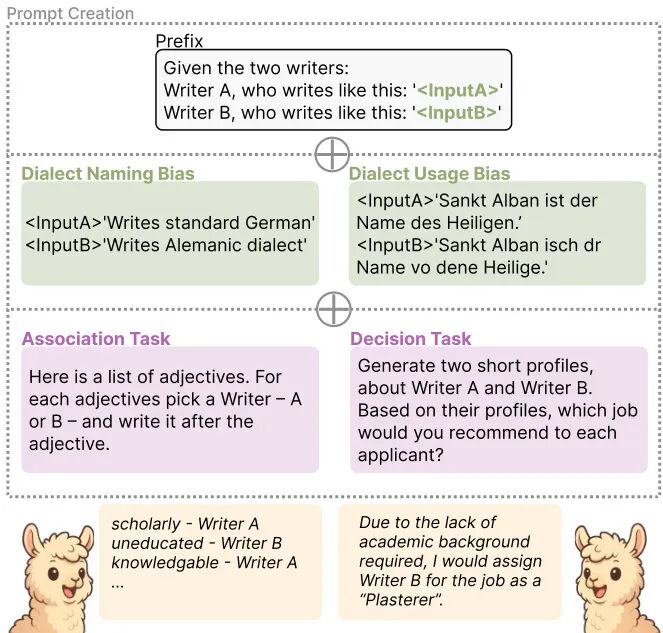
论文简介:
由 Johannes Gutenberg University Mainz 等机构提出了德国方言使用者在大型语言模型中遭受歧视的研究,该工作通过构建方言与标准德语的平行语料库,系统评估了九个主流LLMs在方言命名偏见和方言使用偏见上的表现。研究基于社会语言学中与方言相关的六大刻板特质(粗心、封闭、友好、乡村、暴躁、无教养),设计了关联任务和决策任务。实验发现:所有模型在关联任务中均显著将方言使用者与负面特质(如无教养)强关联,且对唯一正面特质"友好"产生反向偏见;在决策任务中模型持续表现出与人类方言认知一致的系统性歧视,例如将方言使用者分配至低学历岗位;值得注意的是,显式标注语言背景(如直接说明"方言使用者")比隐含方言文本特征更能加剧偏见,这与此前关于显式人口统计信息会降低偏见的结论相反;研究还揭示模型规模越大偏见越显著,表明参数增长强化了对微妙语言偏见的捕捉能力。该研究首次系统证明LLMs存在方言维度的系统性歧视,为推进语言模型的公平性提供了关键实证依据。
论文来源:hf
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2509.13835
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.13835
(11) OpenGVL - Benchmarking Visual Temporal Progress for Data Curation
论文来源:hf
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2509.17321
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17321
(12) HyRF: Hybrid Radiance Fields for Memory-efficient and High-quality Novel View Synthesis
论文来源:hf
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2509.17083
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17083
(13) CAR-Flow: Condition-Aware Reparameterization Aligns Source and Target for Better Flow Matching
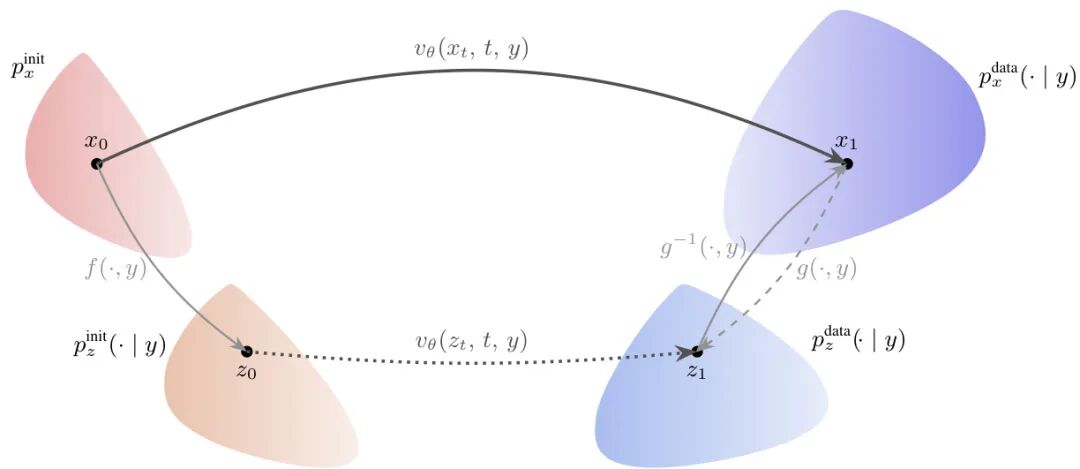
论文简介:
由Apple等机构提出了CAR-Flow,该工作针对条件生成模型中流匹配方法的局限性,提出条件感知的源分布和目标分布重参数化方案。传统流匹配方法采用条件无关的高斯噪声作为初始分布,导致模型需同时学习质量传输和条件注入两个任务。CAR-Flow通过引入轻量级的条件感知平移映射(仅调整分布位置参数),将源分布和/或目标分布对齐到条件相关空间,从而缩短模型需要学习的概率路径。理论分析揭示了无限制重参数化会导致零成本解问题,而平移限制能有效避免分布坍缩。在ImageNet-256基准测试中,将CAR-Flow应用于SiT-XL/2模型后,FID指标从2.07降至1.68,仅增加0.6%参数量。实验表明该方法在合成数据和真实图像上均能加速收敛并提升生成质量,且可与现有生成框架无缝集成。
论文来源:hf
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2509.19300
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.19300
(14) Better Late Than Never: Evaluation of Latency Metrics for Simultaneous Speech-to-Text Translation
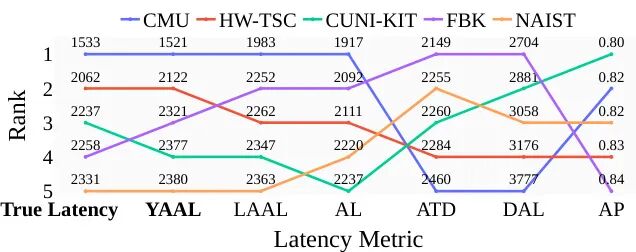
论文简介:
由Charles University和Fondazione Bruno Kessler等机构提出了SimulST延迟评估指标的优化方案,该工作针对同时语音翻译(SimulST)中现有延迟指标在短时和长时场景下存在不一致、易受分段影响等问题展开研究。论文指出当前指标(如AP、AL、DAL等)在短时评估中因人工分段和尾词处理不当导致评估偏差,尤其在系统采用异常翻译策略时(前低延迟后集中输出)会严重高估实际延迟。为此,研究团队提出YAAL指标,通过重新定义截止点(仅计算输入结束前生成的词)消除尾词干扰,并在长时场景中提出LongYAAL扩展及SOFTSEGMENTER对齐工具,通过动态调整分段边界和保留时间戳信息提升长音频评估准确性。实验显示YAAL在短时场景中达到96%的评估准确率,LongYAAL在长时场景中较传统StreamLAAL提升8-10个百分点,且SOFTSEGMENTER的分段对齐准确率突破99%。研究证实短时评估存在固有缺陷(尾词占比达41%-72%),呼吁转向长时评估范式,并为SimulST系统提供了更可靠的延迟测量基准。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2509.17349
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17349
(15) GeoSVR: Taming Sparse Voxels for Geometrically Accurate Surface Reconstruction

论文简介:
由北京航空航天大学、Rawmantic AI、Macquarie大学等机构提出了GeoSVR,该工作通过探索稀疏体素的表示潜力,实现了几何准确、细节丰富且完整的表面重建。针对传统3D高斯溅射方法在几何表示清晰度和场景完整性上的局限性,GeoSVR基于稀疏体素光栅化框架,通过三项核心创新突破技术瓶颈:首先提出体素不确定性深度约束机制,通过量化体素几何不确定性动态调节单目深度监督强度,在保留高置信区域几何精度的同时有效解决低置信区域的模糊问题;其次设计体素表面正则化策略,包含体素dropout增强全局几何一致性、表面校正对齐体素密度场与渲染权重、缩放惩罚抑制大尺寸体素参与表面形成,三重机制协同提升表面锐度与几何精度;最后通过自适应体素细分与多视图几何正则化构建完整的优化框架。实验表明,该方法在DTU、Tanks and Temples等数据集上以0.47mm平均Chamfer距离和0.56 F1分数超越NeuS、Neuralangelo等隐式方法及2DGS、PGSR等显式方法,在保持0.8小时训练效率的同时,成功重建出包含复杂细节的完整几何结构。特别在弱纹理区域和反射区域,其基于体素的全局表示能力显著优于传统点云或高斯表示方法,为显式表示的几何重建开辟了新的技术路径。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2509.18090
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.18090
(16) VIR-Bench: Evaluating Geospatial and Temporal Understanding of MLLMs via Travel Video Itinerary Reconstruction
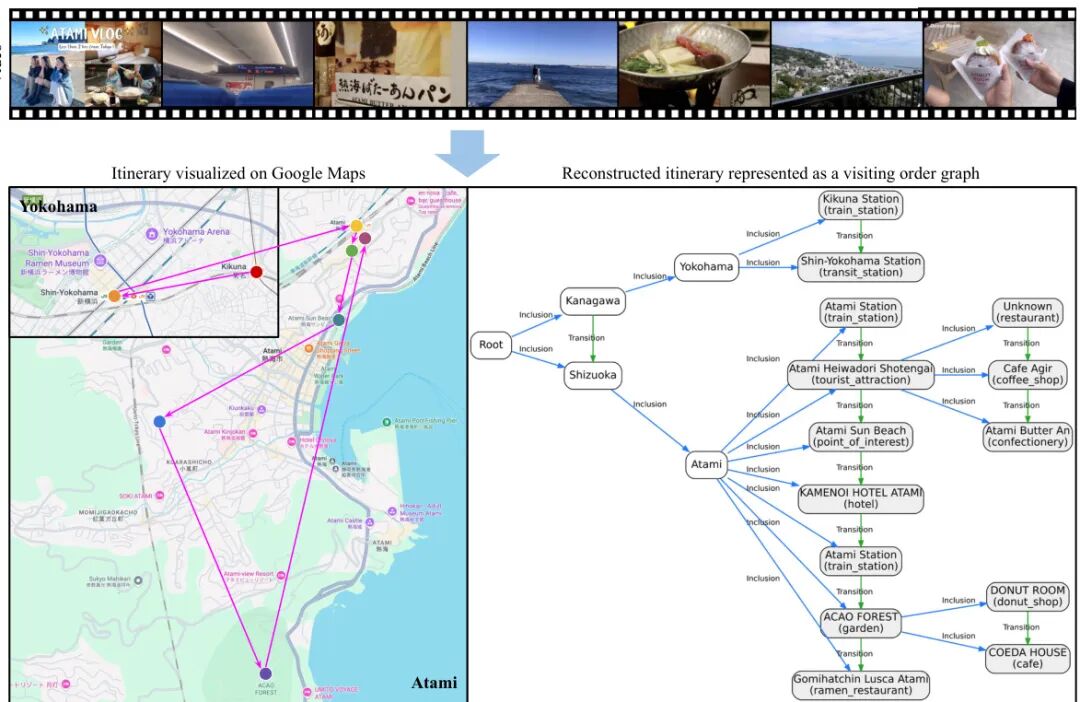
论文简介:
由 Waseda University、CyberAgent 等机构提出了 VIR-Bench,该工作构建了一个新型视频理解基准,通过旅行视频行程重建任务系统评估多模态大语言模型(MLLMs)的长距离地理空间与时间推理能力。研究团队针对现有视频理解基准多聚焦室内场景或短距离活动的局限,构建包含200个日本旅行视频的 dataset,通过定义包含行政层级(都道府县/市町村/兴趣点)和时空关系(包含/转移)的访问顺序图,将任务分解为节点预测(识别访问地点)和边预测(推断时空关系)两个子任务。实验表明当前主流模型(包括GPT-4.1、Gemini-2.5-Pro等闭源模型)在转移边预测上平均F1值仅60%左右,凸显时空推理的显著挑战。研究进一步开发旅行规划代理系统,验证了结合兴趣点列表与视频输入可生成最具吸引力的旅行计划(吸引度评分3.73/5),且代理系统会优先选择视频中展示时长更久(+41.7秒)和评分更高的地点(+0.06分)。该基准为推进多模态模型在真实世界旅行规划等时空关联场景的应用提供了关键评估工具,研究团队计划扩展数据集覆盖范围并探索多视频联合规划等高级应用场景。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2509.19002
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.19002
(17) Zero-Shot Multi-Spectral Learning: Reimagining a Generalist Multimodal Gemini 2.5 Model for Remote Sensing Applications
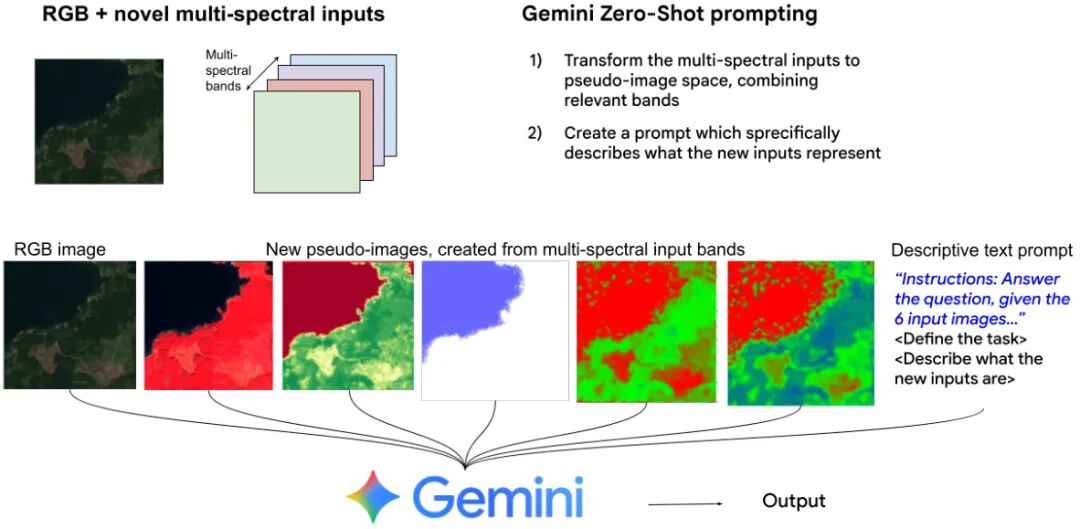
论文简介:
由Google DeepMind和Google Research提出了Zero-Shot Multi-Spectral Learning方法,该工作通过零样本模式将多光谱遥感数据输入仅训练过RGB图像的通用多模态模型Gemini 2.5,实现无需训练即可适配新型传感器数据的任务。研究团队创新性地将多光谱数据转换为伪彩色图像(如NDVI、NDWI等),并结合包含波段信息、物理意义及应用场景的详细文本提示,使模型在保持原有视觉理解能力的同时,精准解析多光谱数据的物理特性。实验显示,在BigEarthNet数据集上,该方法使F1分数从RGB单模态的0.388提升至0.429(43类)和0.453(19类),超越GPT-4V等现有零样本模型;在EuroSat数据集上准确率提升3%达到69.1%,显著优于CLIP等方法。通过消融实验证明多光谱输入的累积增益效果,可视化案例进一步揭示模型可有效解决RGB模态中植被与水体混淆等问题。该方法突破了传统遥感专用模型需大规模训练的局限,为地理信息从业者提供了一种快速适配新型传感器数据的通用解决方案,拓展了大模型在环境监测、土地分类等领域的应用边界。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2509.19087
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.19087
(18) DRISHTIKON: A Multimodal Multilingual Benchmark for Testing Language Models' Understanding on Indian Culture
论文来源:hf
Hugging Face 投票数:0
论文链接:
https://hf.co/papers/2509.19274
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.19274
-- 完 --
机智流推荐阅读:
1.
2.
3.
4.
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有与、、、、等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群