

本研究发表于《IEEE TRANSACTIONS ON INSTRUMENTATION AND MEASUREMENT》(中科院二区,IF=5.6),题目为《MCDDT: Mirror Center Loss-Based Dual-Scale Dual-Softmax Transformer for Multisource Subjects Transfer Learning in Motor Imagery Recognition》。
该论文由西安理工大学罗靖副教授担任第一作者和通讯作者,本文获得2025世界机器人大赛-BCI脑控机器人大赛"青年论文答辩"二等奖。
论文链接:
https://ieeexplore.ieee.org/document/11124295


一、引言
运动想象(Motor Imagery, MI)作为脑-机接口(BCI)领域的经典实验范式,其识别性能直接影响基于 BCI 的康复系统的效果。由于目标被试的脑电(EEG)数据通常有限,模型识别精度容易受到制约。因此,借助源被试的数据进行迁移学习,成为提高 MI-EEG 识别准确度的重要途径。然而,该方法在实际应用中仍面临两大挑战:
(1)模型对感觉运动皮层神经活动的空间定位能力不足;
(2)在源被试之间分布差异显著时,知识迁移效果不佳。
为解决上述问题,本文提出了一种融合镜像中心损失的双尺度双 Softmax Transformer 模型(MCDDT),以实现跨多源被试的 MI-EEG 识别迁移。本文的主要工作包括:
(1)提出镜像中心损失函数:通过拉近同侧神经活动特征、推远对侧特征,增强模型对神经活动区域的空间判别能力,进而提升分类性能;
(2)构建双尺度 Transformer 模型:通过融合多时间尺度的特征,更好地捕捉被试个体在运动想象过程中的时序特异性,改善对时间动态变化的适应能力;
(3)设计双 Softmax 输出结构:在预训练阶段联合预测被试身份和运动想象类型,使模型能够从多个被试中学习具有判别力的特征子空间,增强后续微调阶段的泛化能力。

二、方法
2.1 总体概述
运动想象(MI)脑电信号(EEG)的识别精度对脑机接口(BCI)康复系统的性能至关重要。然而,目标被试的可用数据通常有限,这限制了模型的性能。因此,从多个源被试的数据中迁移知识,成为提升模型识别准确性的关键策略。本文旨在通过迁移学习,利用多源被试的运动想象脑电(MI-EEG)信号实现高精度的意图识别。提出的基于镜像中心损失的双尺度双Softmax Transformer(MCDDT) 模型,其处理流程包含两个核心阶段:首先利用多个源被试的MI-EEG信号对模型进行预训练,然后使用目标被试的少量数据对模型进行微调,使其适应目标被试的个体特征。
该模型的整体架构由三个核心模块构成:
1.特征提取模块:负责从原始EEG信号中提取基础特征。
2.双尺度自注意力模块:用于融合不同时间分辨率下的特征,以更好地捕捉MI-EEG信号中的时序动态信息。
3.分类模块:在分类模块中,创新性地引入了镜像中心损失函数,旨在增强模型对感觉运动皮层中神经活动(如事件相关去同步/同步,ERD/ERS)的空间定位能力,从而提升特征的判别性。
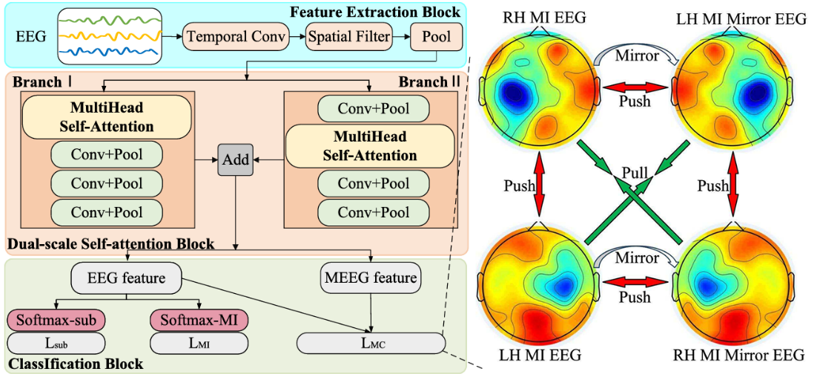
图1 MCDDT 整体架构图
2.2 镜像中心损失
事件相关去同步化(ERD)是反映大脑皮层神经活动的重要指标,其在感觉运动区的空间分布模式对运动想象(MI)任务的识别具有关键意义。例如,右手运动想象通常引发左侧初级运动皮层的ERD,而左手想象则使ERD出现在右侧。然而,EEG信号中缺乏ERD空间位置的显式标注,难以直接采用全监督方法训练空间定位模型。为此,本研究引入镜像中心损失函数,通过半监督学习策略增强模型对ERD空间模式的识别能力。该方法仅依赖MI任务类别标签,通过构造镜像EEG信号(交换左右半球通道并对应翻转类别标签),使模型在特征空间中拉近同类任务下同侧ERD特征的距离,同时推远对侧ERD特征的距离,从而在没有显式ERD位置监督的情况下提升模型的神经活动定位能力。
2.2.1 镜像EEG信号
镜像EEG信号的构建基于大脑感觉运动区的ERD/ERS响应具有对侧支配的生理特性。具体操作是通过互换原始EEG信号中左右半球对应通道(如C3与C4)的数据,生成镜像信号。这一转换使得原本出现在一侧半球的ERD/ERS模式被映射至对侧半球。例如,右手运动想象在左半球中央区(C3)诱发的ERD,在镜像信号中会表现为右半球中央区(C4)的ERD。因此,为了保持标签与神经活动模式的一致性,在生成镜像EEG信号的同时,必须将对应的运动想象类别标签进行互换(即左手标签与右手标签对调)。
2.2.2 镜像中心损失

图2 镜像 EEG 信号通过交换 EEG 数据中左右半球的通道生成
传统的中心损失(Center Loss)的目标是增强深度学习模型的判别能力,常用于人脸识别等任务。其基本思想是在特征空间内最小化样本特征与其类别中心的距离。镜像中心损失是在中心损失的基础上进行改进,专为 MI 识别而设计。该方法通过最小化同侧神经活动特征与类别中心的距离,并最大化对侧神经活动特征与类别中心的距离,来提升 MI 模型的判别能力。镜像中心损失定义如下:
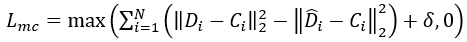 (1)
(1)
其中, 与 分别表示第 个 EEG 及其镜像 EEG 的特征向量, 表示其类别中心, 为当前批次样本数, 为调节不同类别间特征距离的超参数。式中的 表示原始 EEG 特征与类别中心的距离,目标是最小化这一距离以促进类内紧凑性; 表示镜像 EEG 特征与类别中心的距离,由于镜像样本类别与 相反,因此该距离应被最大化,以增强类间分离度。
这一双目标优化有效地引导模型提取更加判别性的特征,使其能够进行更为准确的分类。同时,超参数 提供了灵活性,用于在两类距离项之间进行权衡。公式中的 函数保证了损失值非负,并仅在类间分离不足时累积损失,避免当类间距离过大时镜像中心损失对总损失函数造成过度影响。
在理想情况下,类别中心 应随着深度特征的变化而更新,即每一轮迭代都需考虑整个训练集中各类别的平均特征,但这在实际中效率极低。为此,本文将类别中心 作为可训练参数,并在反向传播过程中进行更新。值得注意的是,仅类内距离项参与类别中心的更新。其梯度计算公式如下:
 (2)
(2)
通过同时利用原始 EEG 与镜像 EEG 对模型进行微调,引入镜像中心损失能够在无需依赖 ERD 空间位置标注的情况下,以半监督的方式增强模型对 ERD 的空间定位能力。
2.3 双尺度双 Softmax Transformer
本节提出的双尺度双 Softmax Transformer旨在应对跨被试 MI-EEG 迁移学习中的个体差异问题。
2.3.1 基于 CNN 的特征提取模块
预处理后的 EEG 信号首先输入至基于 CNN 的特征提取模块。该模块的第一步是进行时域卷积![]() ,卷积核大小为 10×1。随后,为了模拟 CSP 空间滤波器,使用空间卷积
,卷积核大小为 10×1。随后,为了模拟 CSP 空间滤波器,使用空间卷积![]() ,卷积核大小为 1×E,用于整合所有通道的信息。最后,通过批归一化
,卷积核大小为 1×E,用于整合所有通道的信息。最后,通过批归一化![]() 与最大池化
与最大池化![]() 层进一步降低特征维度。
层进一步降低特征维度。
2.3.2 双尺度自注意力模块
在本研究中,我们针对基于Transformer的脑电信号解码方法中存在的时间尺度适应性问题,提出了一种双尺度自注意力模块。该设计旨在更灵活地捕捉不同被试者在运动想象任务中表现出的多时间尺度神经动态特征。
传统Transformer模型在处理EEG信号时,通常采用单一、固定的时间分辨率进行特征提取。然而,由于个体间神经生理差异显著,不同被试的判别性特征可能出现在不同的时间尺度上。例如,某些被试的关键模式可能表现为快速瞬态响应,而另一些则表现为持续缓慢的节律同步。直接使用统一时间分辨率的特征会限制模型对多尺度时序信息的感知能力,从而影响解码性能。
为解决上述问题,我们设计了包含两个并行分支的自注意力模块:
分支I(高时间分辨率分支):该分支专注于短时间窗口内的特征分析,旨在捕捉快速变化的瞬时神经活动(如事件相关去同步化ERD的起始相位)。这些高频细节对于识别运动想象的早期触发特征至关重要。
分支II(低时间分辨率分支):该分支则在长时间窗口下运作,侧重于建模更稳定、持续的神经模式以及全局时间依赖关系(如整个运动想象周期的节律性振荡)。这有助于识别跨越较长时间范围的整合性神经响应。
两个分支独立处理不同粒度的时序信息后,其输出的特征表示会通过求和操作进行融合。这种融合机制生成了一种高度适应性且信息丰富的特征表示,它同时包含了局部的瞬态动态和全局的时序上下文。研究表明,这种多尺度特征融合策略能有效提升模型对不同个体神经活动时间特性的鲁棒性,从而显著增强EEG解码的准确性和泛化能力。
 (3)
(3)
2.3.3 双 Softmax 分类模块
提取到的特征将被直接输入到两个并行的 Softmax(SM)层中,如图1所示。双 Softmax 层的输出分别对应于运动想象(MI)类别与被试来源的预测概率。
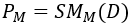 (4)
(4)
 (5)
(5)
其中,SM 表示 Softmax 层, 和 分别表示对不同运动想象(MI)类别和被试的预测概率。当输入一个包含 62 个通道、1000 个采样点的脑电信号(如 OpenBMI 数据集中的数据)时。
2.4 模型训练
所提出的 MCDDT 模型通过来自多个源被试的 MI-EEG 信号进行预训练,并通过目标被试的信号进行微调。
2.4.1 预训练阶段
当前多数基于迁移学习的运动想象脑电(MI-EEG)分类方法在预训练时,通常将不同被试的数据混合为一个单一的源域进行处理。这种做法忽视了被试间存在的显著信号分布差异,导致最终学到的特征表示缺乏对个体特异性的辨别能力,进而影响模型向目标被试迁移知识的效果。
为解决上述问题,本文提出将每个源被试的EEG数据视为一个独立的子域。模型通过一个并行双Softmax分类模块,同步进行运动想象任务分类和被试身份识别。具体而言,在预训练阶段,模型利用来自多个源被试的标注数据。每个被试被赋予一个独一无二的身份标识。模型的优化目标由两项交叉熵损失共同构成:一项用于准确判断运动想象类别(如左手、右手想象),另一项用于识别EEG样本来源于哪一个特定的被试。最终,将选取在验证集上运动想象任务分类和被试身份判别两个任务中均表现最佳的预训练模型,用于后续针对目标被试的微调阶段。
这种子域划分与双任务学习的设计,旨在迫使模型同时捕捉任务相关的共性特征和被试特有的个性特征,从而增强模型在跨被试迁移时的适应性和鲁棒性。整体损失函数定义如下:
 (6)
(6)
其中,![]() 和
和![]() 分别表示 MI 和被试的预测概率,
分别表示 MI 和被试的预测概率,![]() 和
和![]() 为 MI 和被试的标签。
为 MI 和被试的标签。
2.4.2 微调阶段
目标被试的原始 EEG 信号与镜像 EEG 信号用于微调预训练模型。除了镜像中心损失外,还应用了对 MI 的 Softmax 交叉熵损失,以实现监督的 MI 识别训练:
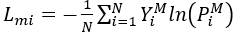 (7)
(7)
在微调阶段,舍弃了被试分类的 Softmax。最终的微调损失是镜像中心损失与分类损失的和:
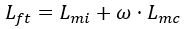 (8)
(8)
其中,![]() 是权重系数。
是权重系数。

三、实验
我们在两个公开的 MI 识别数据集上评估了所提出的 MCDDT 模型:BCI 竞赛 IV 数据集 2a(2a)和 OpenBMI 数据集(BMI)。详细实验设置见论文。
3.1 平均分类准确率
首先将MCDDT与SOTA算法的实验结果进行比较,在预训练数据不含目标被试的设置下,MCDDT 平均准确率达到 89.52%(2a)、91.05%(BMI-21)、81.25%(BMI-54),显著优于 ShallowConvNet、EEGNet、ATCNet、ADFCNN 等主流方法,证明了模型的良好泛化能力。如表1所示。
表1 MCDDT与SOTA算法的实验结果比较

3.2 消融实验
我们进行了全面的消融实验,以验证所提出的双尺度 Transformer、双 Softmax 结构和镜像中心损失的有效性。这些实验评估了不同网络配置的性能。具体而言,我们测试了单分支网络,即“分支 I”和“分支 II”;双分支 Transformer 网络“Dual-Branch”;双尺度双 Softmax Transformer 网络“DDT”;以及我们提出的“MCDDT”。
现有被试和未见过被试两种设置下的消融实验结果见表 2。根据这些表中的数据,我们可以得出以下结论:
1)双分支模型优于单分支结构模型。这表明,双尺度 Transformer 模型能够有效地整合具有多时间分辨率的特征。
2)DDT 模型表现优于双分支模型,这证明了双 Softmax 结构能够在迁移学习过程中增强模型的适应性。
3)MCDDT(结合镜像中心损失)表现最佳。这归因于其增强 ERD 空间定位的能力。
表2 消融实验结果
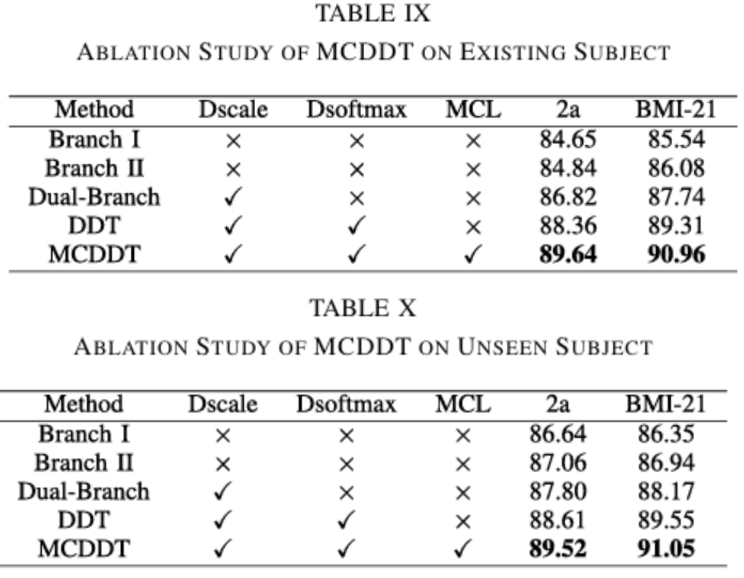
其中,Dscale 表示双尺度结构,Dsoftmax 表示双Softmax结构,MCL 表示镜像中心损失;✓表示启用该模块,×表示未启用。
3.3 特征可视化
为验证镜像中心损失(Mirror Center Loss)在模型特征学习中的作用,我们采用 t-SNE 技术对微调阶段 DDT 模型提取的特征分布进行了可视化对比分析。结果显示,未引入该损失时,左手与右手运动想象对应的特征在嵌入空间中相互重叠、边界模糊;而在引入镜像中心损失后,两类特征呈现出明显的分离趋势,类间距离增大,决策边界更为清晰,这一结果证实了该方法在增强模型对事件相关去同步(ERD)空间定位能力方面的有效性。
此外,我们在预训练阶段对双 Softmax 结构的作用也进行了可视化比较。研究发现,若不使用双 Softmax 结构,不同被试的特征在嵌入空间中存在大量重叠,任务类别(如左右手运动想象)之间缺乏可分性;而引入双 Softmax 后,特征呈现出按被试聚类的趋势,同时任务类别之间的区分度也显著提升,从而验证了“任务‑被试双重监督”策略在跨被试迁移学习中的有效性。
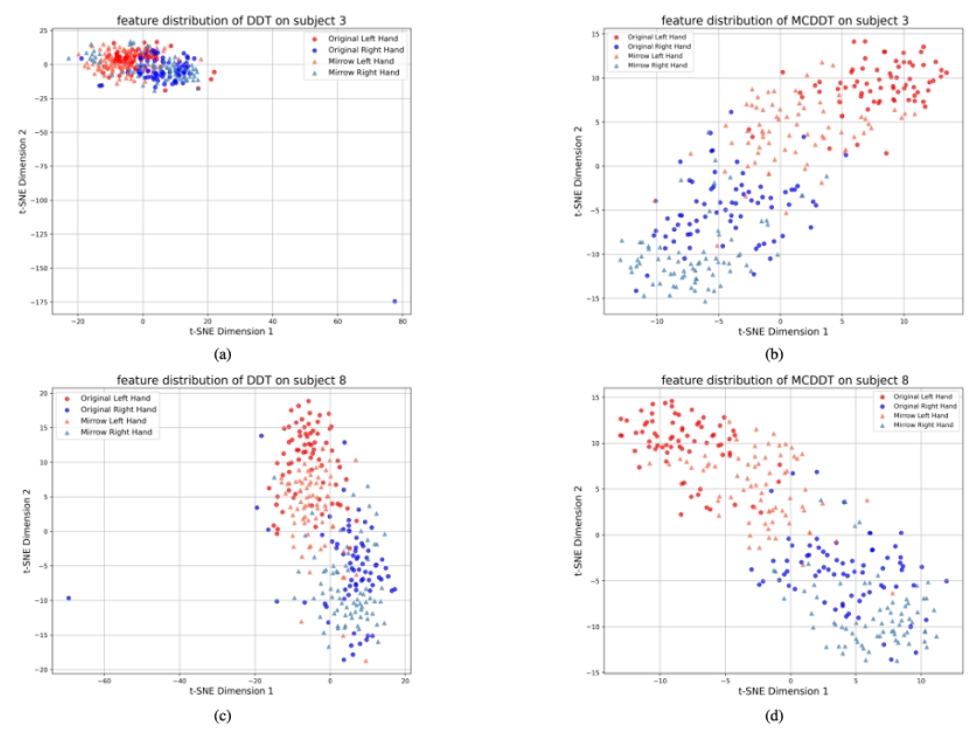
图3 对比微调 DDT 模型时是否引入镜像对比损失的特征分布
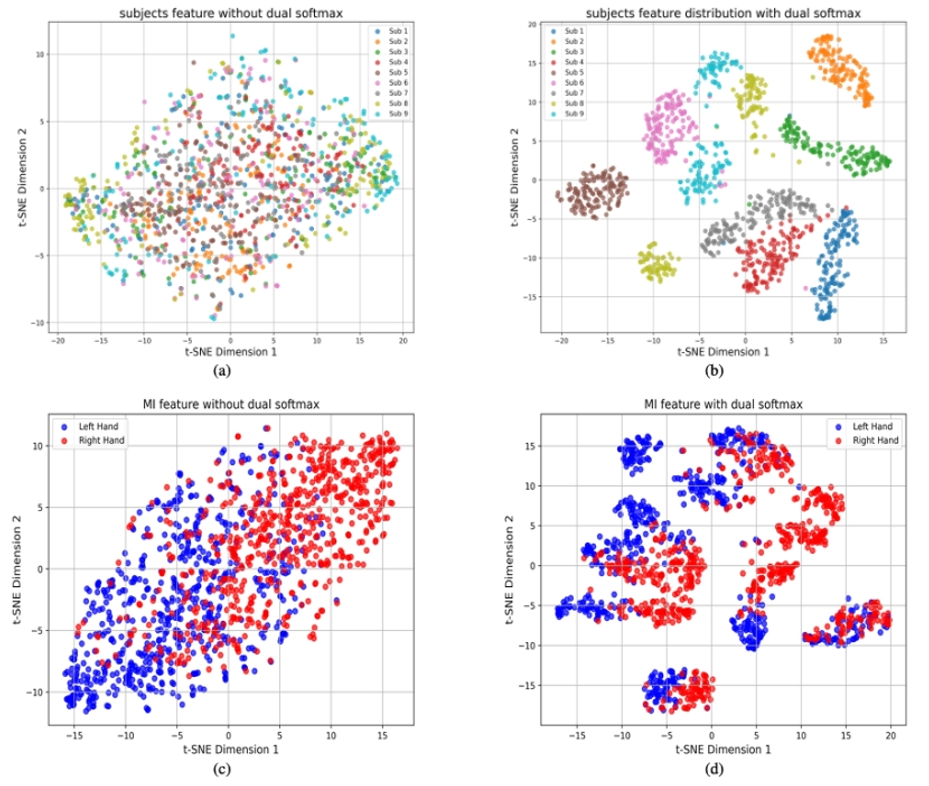
图4 对比预训练阶段有无双 Softmax 结构的特征分布

四、总结
本研究提出了一种名为MCDDT的创新模型,旨在解决跨被试运动想象脑电信号识别中,因不同被试间EEG数据分布差异而导致的迁移学习困难。该模型通过以下三个核心设计提升跨被试泛化能力:首先,采用双尺度Transformer结构,融合不同时间分辨率下的特征表达,以更好地捕捉被试个体在运动想象过程中特有的时序模式,缓解时间维度上的个体差异性。其次,引入双Softmax分类机制,在预训练阶段同时学习运动想象任务类别和被试身份标签,使模型能够区分与任务相关的共性特征及被试特有的个性特征,从而增强模型在迁移至新被试时的适应性。第三,提出镜像中心损失函数,通过构造镜像EEG信号(交换左右半球通道并对应翻转任务标签),以半监督方式引导模型学习对事件相关去同步现象的空间分布更敏感的特征表示,提升其对神经活动模式的定位能力。在BCI Competition IV 2a和OpenBMI等公开数据集上的实验表明,MCDDT模型在跨被试MI-EEG分类任务中取得了优于已有主流方法的准确率,验证了其整体架构及各组件在提升模型泛化性能和识别精度方面的有效性。
撰稿人:罗靖
审稿人:罗靖


脑机接口与混合智能研究团队



团队主页
www.scholat.com/team/hbci











