金磊 发自 凹非寺
量子位 | 公众号 QbitAI
高手如云,高手如云,但华为依旧“杀”出了一片天。
就在最新一期的SuperCLUE中文大模型通用基准测评中,各个AI大模型玩家的成绩新鲜出炉。
从大家最为关心的开源、国产两个维度来看,前三名排名分别为:
DeepSeek-V3.1-Terminus-Thinking openPangu-Ultra-MoE-718B Qwen3-235B-A22B-Thinking-2507

(注:SuperCLUE是一个综合性的大模型评测基准,本次通过对数学推理、科学推理、代码生成、智能体Agent、幻觉控制、精确指令遵循六个维度的核心能力进行评估,共计1260道题目。)
那么华为这个拥有7180亿参数体量的MoE大模型,究竟凭什么脱颖而出?
在我们与openPangu核心成员深入交流之后,发现他们的训练哲学并非是大力出奇迹,与之恰恰相反——
不靠堆数据,靠会思考。

这又是什么意思呢?接下来,我们就来一同细看。
数量给质量让路
我们都知道,训练数据的质量直接影响大模型的最终能力。
因此,openPangu团队在后训练数据构建中遵循了三个核心原则:质量优先、多样性覆盖、复杂度适配。
并且为此建立了一套覆盖“数据生成-科学筛选-精准增强”的全流程方案。
 △通用后训练数据构建框架
△通用后训练数据构建框架
- 质量优先:团队建立了指令数据质量评估体系,结合规则、模型和人工三重审核机制,以确保低质量样本的有效清理。
- 多样性覆盖:从领域和任务类型两个维度进行设计,并通过去重和压缩选样算法,在保证数据覆盖广度的同时避免冗余。
- 复杂度适配:为避免模型仅在简单任务上过拟合,团队通过推理步骤、概念抽象度、计算复杂度等指标对任务难度进行量化,并利用自迭代拒绝采样策略,重点进行中高难度任务的训练。
这种对数据质量的严格把控,正是提升模型在复杂场景下推理能力的关键因素之一。
三阶段预训练策略
除了数据质量之外,模型的基础能力与预训练阶段是息息相关。
整体来看,团队将openPangu-718B的预训练过程被设计为三个阶段:通用(General)、推理(Reasoning)和退火(Annealing)。
首先是通用阶段,这个阶段的目标是为模型构建广泛的世界知识。模型通过学习大规模的文本和代码数据,形成对世界的基本认知。
其次是推理阶段,专注于提升模型的逻辑推理能力。团队显著增加了泛数学、STEM(科学、技术、工程和数学)及代码数据的训练比重,并重点引入了高难度的多步骤推理题库。
为提升多步推理的准确性并减少幻觉,团队为这部分数据制作了详细的思维链(CoT),以引导模型学习解决问题的逻辑路径。
最后是退火阶段,此阶段旨在增强模型应用知识和推理技能的能力。训练文本的上下文长度被阶梯式地提升至8K、32K和128K,同时增加了指令类数据的占比。
此外,该阶段还引入了多种Agent类型的数据,为模型学习使用外部工具(Tool-use)建立基础。
缓解幻觉有妙招
幻觉可以说是大型语言模型普遍面临的一大挑战,为缓解这个此问题,团队引入了“批判内化”(Critique Internalization)机制。
这个机制的核心思想是,不仅让模型学习正确的示范(传统SFT模式),更要让模型学习如何评判一个解答的优劣。
不同于传统的批判微调(CFT)只依赖固定的人类反馈数据来训练模型, 批判内化策略在初始模型训练完成后,利用拒绝采样阶段引入额外的自我批判信号,引导模型在生成答案时基于不同任务的行为准则Guideline,主动审视自己的推理过程。
通过这种训练,模型能够将批判性思维融入自身推理过程。在生成回答时,它能更好地审视自身的逻辑链条,检查是否存在逻辑跳跃、信息遗漏或偏离指令等问题。
实验结果表明,该机制有效缓解了模型幻觉,并提升了指令遵从性和价值观对齐的表现。同时,这种针对性的反思也使得模型的输出更为精炼和可靠。
Agent能力也进化了
为了提升模型使用工具的能力,团队采用了升级版的工具数据合成框架——ToolACE。
这个框架通过一系列关键技术,生成了大量高质量、高复杂度的多轮多工具调用数据用于训练。
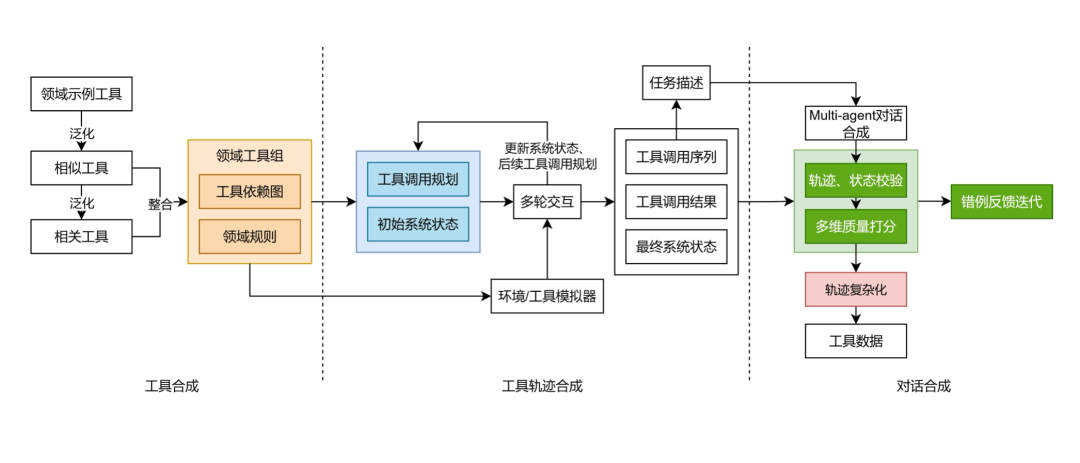
领域工具组合:将现实场景中相互关联的工具(如日历查询和航班预订)进行组合,并提供工具依赖图和领域规则,使模型学习在复杂任务中如何协同使用多个工具。
交互式目标轨迹生成:采用“计划-执行”分离策略,先由AI规划出解决任务的工具调用序列,再通过与模拟环境的交互执行该序列,生成完整的工具使用轨迹。
多智能体对话生成:利用多个AI智能体模拟用户与助手的互动,将工具调用过程转化为自然的对话脚本,并引入随机打断、反问澄清等复杂交互情况,以提升数据的真实性。
多维校验与错例迭代:对生成的数据进行多维度质量检查,包括内容满足度、状态变化正确性、工具调用效率等。低分数据将被分析错误原因,并用于迭代优化生成策略。
通过这套系统,openPangu-718B学习在复杂的多轮交互中准确、灵活地调用工具。
三步式后训练优化方案
在完成数据构建和核心能力训练后,openPangu团队还经过了一个“三步走”的后训练微调方案,进行了最终的性能优化。
第一步:渐进动态微调 (PDFT)
为避免模型在指令微调(SFT)阶段对训练数据产生过拟合,团队采用了渐进动态微调(Progressive Dynamic Fine-Tuning, PDFT)。该方法让模型的学习模式从常规SFT平滑过渡到动态微调(DFT)。
训练初期,模型以常规SFT模式充分学习;后期则逐步增加DFT权重,使模型更关注尚未充分掌握的知识点,从而在欠拟合与过拟合之间取得平衡。
第二步:强化学习 (RL) 微调
考虑到openPangu-718B这类混合专家(MoE)模型的训练稳定性要求较高,团队采用了GSPO(Group Sequence Policy Optimization)算法进行强化学习。
与GRPO算法相比,GSPO在训练大型MoE模型时表现出更好的稳定性,有助于模型性能的持续提升,避免了训练过程中的性能衰退。

第三步:模型融合 (Model Merging)
在不同训练阶段,会产出在特定领域各有优势的多个模型版本。为整合这些模型的优点,团队采用了一种黑盒优化的模型融合方法。
通过构建一个覆盖广泛任务的测评集,使用优化算法自动搜索各候选模型的最佳融合权重,最终生成一个综合性能更强的模型。
总结来看,openPangu-718B的优异表现,源于其在预训练、数据构建、幻觉控制、工具学习及后训练优化等环节系统性的技术创新。
从三阶段预训练奠定基础,到通过“批判内化”机制提升可靠性,再到利用ToolACE框架拓展Agent能力,最后通过三步式后训练方案进行精细打磨,每一步都反映了其背后的技术策略。
与此同时,openPangu团队也为行业提供了一个极具价值的范本:真正的竞争力,来自于对技术细节的极致打磨和对核心问题的深刻洞察。
参考链接:
[1] https://ai.gitcode.com/ascend-tribe/openpangu-ultra-moe-718b-model
[2] https://arxiv.org/abs/2501.17703
[3] http://arxiv.org/abs/2409.00920
[4] http://arxiv.org/abs/2508.12685
[5] https://arxiv.org/abs/2508.05629
[6] https://arxiv.org/pdf/2507.18071
[7] https://arxiv.org/abs/2402.03300
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🌟 点亮星标 🌟










