

该论文发表于IEEE Transactions on Image Processing(中科院1区,IF=13.7),题目为《PTH-Net: Dynamic Facial Expression Recognition Without Face Detection and Alignment》。
温州大学计算机与人工智能学院的李敏为此文第一作者,温州大学计算机与人工智能学院的张笑钦教授和同济大学计算机科学与技术学院的肖国宝教授为通讯作者。
论文链接:
https://ieeexplore.ieee.org/abstract/document/10770138

论文概要
面部表情识别(FER)是情感计算的重要研究方向,特别是动态面部表情识别(DFER),因其能够捕捉表情随时间演变的过程而受到关注。传统方法大多依赖人脸检测与对齐(Face Detection and Alignment, FDA),只关注面部区域,容易丢失肢体动作、头部运动等信息。本文提出了一种新范式——金字塔时间层次网络(Pyramid Temporal Hierarchy Network, PTH-Net),该方法直接作用于原始视频,无需人脸检测和对齐。在设计上,PTH-Net 利用预训练的视频理解模型提取不同时间频率下的多尺度特征,构建时间特征金字塔(Temporal Feature Pyramid),并通过时间层次精炼模块(Temporal Hierarchy Refinement, THR)逐步区分主体与背景。此外,作者提出了可扩展语义区分层(Scalable Semantic Distinction, SSD),增强目标表情与非目标表情之间的判别能力。实验结果表明,PTH-Net 在八个公开数据集(包括 DFEW、FERV39k、MAFW、MELD、CREMA-D、RAVDESS、eNTERFACE05 和 CASME2)上均取得了优异表现,相比现有方法实现了显著提升,同时计算成本更低。

研究背景
在人际交互中,面部表情是最直接、最自然的情绪表达方式。随着计算机视觉和人工智能的发展,自动化面部表情识别逐渐成为促进人机交互、辅助医疗诊断以及心理健康评估的重要工具。现有 DFER 方法通常遵循一个固定范式,即先检测并对齐人脸,再在裁剪的人脸图像上进行表情识别。尽管这一范式在一定程度上降低了干扰,提升了识别准确率,但其流程复杂,灵活性不足,而且忽视了表情中蕴含的肢体动作和头部运动等信息。尤其在实际场景中,背景复杂且人物表情持续时间不一,仅依赖面部区域难以全面反映情绪。基于此,研究者们提出了 PTH-Net 这一新思路,尝试摆脱 FDA 的限制,直接在原始视频层面进行端到端的表情识别,以保留更多有效信息并提升泛化能力。

方法
本文提出的 PTH-Net 整体框架如图所示,由三个主要阶段组成:首先,利用预训练的视频理解骨干网络(VideoMAE v2)在不同时间频率下提取多尺度特征,构建时间特征金字塔,以应对表情持续时间差异并增强动态信息建模。随后,这些特征进入时间层次精炼(THR)结构,通过参数共享与分层精炼,有效区分主体与背景,逐步提升对表情演化过程的鲁棒性。最后,模型结合预测策略,在前向与反向序列上分别进行推理,并通过融合增强对目标表情的建模能力。整体而言,PTH-Net 通过端到端的设计,在无需人脸检测与对齐的情况下,直接在原始视频层面实现高效、准确的动态面部表情识别。

图1 PTH-Net的总体架构
时间特征金字塔
PTH-Net首先利用预训练的视频理解骨干网络VideoMAE v2,在不同时间频率下提取视频特征,构建时间特征金字塔。具体而言,视频会被动态采样为多个不同长度和时间间隔的片段,例如高频(H)、中频(M)和低频(L),从而形成多尺度时间特征表示。这些特征同时包含了主体(人体和面部)与背景的动态演化信息。通过多尺度建模,PTH-Net 能够适应表情的不同持续时间:高频特征保留了细粒度的短期动态信息,而低频特征则更好地捕捉长期趋势。此外,由于骨干网络偏向提取动态信息,静态背景的干扰在特征层面被显著减弱。
时间层次精炼(THR)
为了进一步区分主体与动态背景,PTH-Net在时间特征金字塔的基础上引入时间层次精炼结构。该结构通过参数共享与有限的差异化参数设计,在不同时间尺度上对特征进行分层分析和调整。具体来说,THR包含多个子模块,每个子模块都堆叠了若干可扩展语义区分层(SSD),并在层间通过时间维度的最大池化操作逐步扩大感受野。这样一来,模型在不同时间层级上均可接受监督,逐步学习到跨尺度的时间频率不变性(Temporal-Frequency Invariance, TFI) 表征。通过这种分层精炼,PTH-Net 能够更有效地剥离动态背景对情绪建模的干扰,从而增强表情表示的判别力和鲁棒性。
可扩展语义区分层(SSD)
SSD 是 PTH-Net 的关键创新之一,用于解决视频中大量非目标表情帧(如中性帧)干扰的问题。其核心思想是在Transformer的宏观架构下,将自注意力模块替换为SSD模块,并引入组归一化(GN)以增强稳定性。SSD的结构如图2所示。SSD由两个主要分支组成:区分增强器(Distinction Enhancer, DE)和尺度聚焦(Scale Focus, SF)。DE 通过将特征与视频级平均特征进行对比,扩大目标表情与非目标表情之间的特征差异,从而提升判别能力。由于视频级的全局表达在不同尺度下保持一致,DE 模块的参数可在多尺度间共享,这显著提高了计算效率。SF 通过设置不同卷积核大小(如 5、3、1)在时间维度上捕捉多粒度的动态信息。较大的卷积核可以捕捉长期语义,较小的卷积核则对短期变化更敏感。为了提升灵活性,SF 结合了深度可分离卷积与共享卷积结构,使模型能够在不同时间尺度下动态关注与目标表情相关的语义特征。最后,SSD 通过 跨注意力机制 将 DE 与 SF 的结果进行加权融合,实现对关键特征的动态强调。这样,模型能够在存在大量中性或干扰帧的情况下,依然聚焦于目标情绪的判别性特征。

图2 SSD层的结构图

实验结果
作者在八个公开数据集上对 PTH-Net 进行了系统评估,其中包括四个 in-the-wild 数据集(DFEW、FERV39k、MAFW、MELD)和四个实验室控制数据集(CREMA-D、RAVDESS、eNTERFACE05、CASME2)。实验重点考察了模型的整体性能、对不同情绪类别的区分能力以及效率表现。
In-the-wild 数据集结果
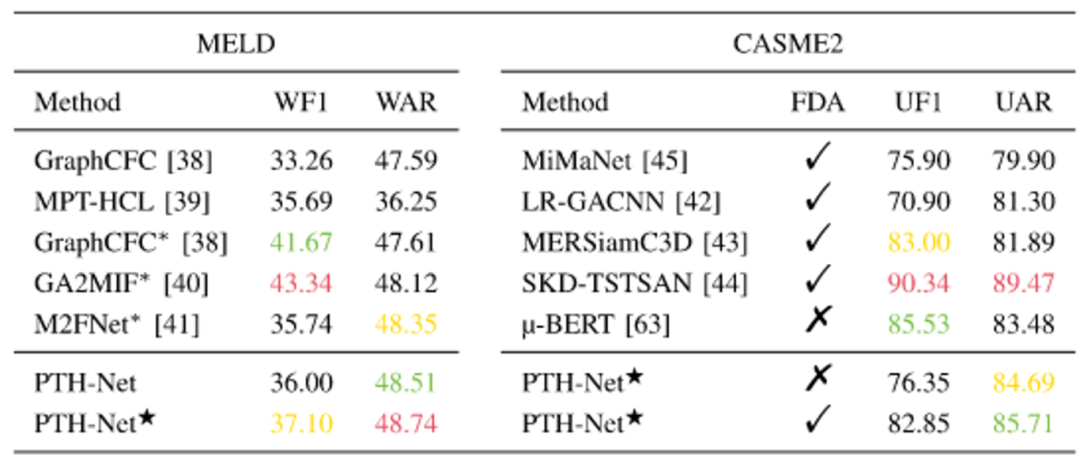
表1-表4展示了在in-the-wild 数据集(DFEW、FERV39k、MAFW、MELD)实验结果。在 DFEW 和 FERV39k 两个大规模视频情绪识别数据集上,PTH-Net 显著优于现有方法。表1显示了 DFEW 上各类别的准确率,其中“fear”类别首次超过了50%,明显缓解了传统模型对少数类识别能力不足的问题。类似地,在 MAFW 数据集上,PTH-Net 的单模态性能甚至超越了部分多模态方法,表明其在复杂环境下的鲁棒性。在 MELD 数据集上,PTH-Net 与多模态方法进行了对比。实验表明,尽管 PTH-Net 仅使用视觉模态,其性能仍接近甚至超过部分依赖语音与文本的多模态模型。这一结果说明 PTH-Net 在视觉建模上的判别性增强,能够独立支撑复杂场景下的情绪识别。
表1 与 DFEW 上最先进的方法的比较。红色:最好的结果。绿色:第二好。黄色:第三好。FDA:使用人脸检测和对齐 †:向后序列。⋆:合并向前和向后序列。

表2 与FERV39K上最先进的方法进行比较.红色:最好的结果。绿色:第二好。黄色:第三好。FDA:使用人脸检测和对齐 †:向后序列。⋆:合并向前和向后序列

表3 与 MAFW 上最先进的方法的比较。∗:多模态方法 †:向后序列。⋆:合并向前和向后序列

表4 与用于recognition in conversation(ERC)的MELD和用于micro-expression recognition(MER)的CASME2的最先进方法的比较。∗:多模态方法
实验室控制数据集结果
表4-表5展示了实验室控制数据集(CREMA-D、RAVDESS、eNTERFACE05、CASME2)的结果。在 CREMA-D、RAVDESS、eNTERFACE05 和 CASME2 四个受控环境下的视频数据集上,PTH-Net 的表现同样优异。例如,在 CREMA-D 上,其平均准确率明显高于现有的基于 Transformer 和 CNN 的方法,进一步验证了其在短视频和受控场景下的适用性。
表5 在三个实验室对照数据集上与最先进的方法进行比较。A:音频模式。V:视觉模式。红色:最好的结果。绿色:第二好。黄色:第三好。FDA:使用人脸检测和对齐 †:向后序列。⋆:合并向前和向后序列

消融实验结果
论文中对DFEW、FERv39k和MAFW数据集进行消融实验,以证明PTH-Net中关键组件的影响。消融实验分析了不同的输入序列,评估比例因子 k 的有效性,评估模型深度,并探索每个超参数的作用。结果展示在表6-表8。
表6 输入序列的消融研究。粗体:默认设置。红色:最好的结果。绿色:第二好。黄色:第三好

表7 缩放因子 K的消融研究。 粗体:默认设置

表8 模型深度的消融研究。粗体:默认设置


结论
本文提出的 PTH-Net 为动态面部表情识别提供了一种新的端到端范式,突破了传统 FDA 的限制。该网络利用时间特征金字塔和时间层次精炼,有效分离主体与背景,提升了对复杂表情序列的建模能力;同时,设计了高效的 SSD 层,增强了目标与非目标表情的判别能力;最后,在多个公开基准数据集上实现了显著优于现有方法的性能,且参数量和计算量均更小。这一研究不仅在理论上推动了 DFER 范式的转变,也为实际场景中高效、鲁棒的表情识别提供了可行方案。不过,作者也指出 PTH-Net 在短视频上的表现仍有改进空间,未来可通过优化数据流设计进一步提升模型的适应性。
撰稿人:闫玉龙
审稿人:梁艳


脑机接口与混合智能研究团队



团队主页
www.scholat.com/team/hbci











