看来 NVIDIA 和 AMD 正在竞相打造更卓越的 AI 架构,两家公司都在修改其下一代设计以获得优势。
NVIDIA 和 AMD 未来的 AI 产品备受期待,因为它们计划在多个方面进行大规模升级,包括功耗、内存带宽、工艺节点利用率等等。然而,根据一些报告和 SemiAnalysis 的一篇 X 文章,AMD 的 Instinct MI450 AI 系列与 NVIDIA 的 Vera Rubin 之间的竞争预计将比以往产品更加激烈,因此,随着时间的推移,架构发生了许多变化。
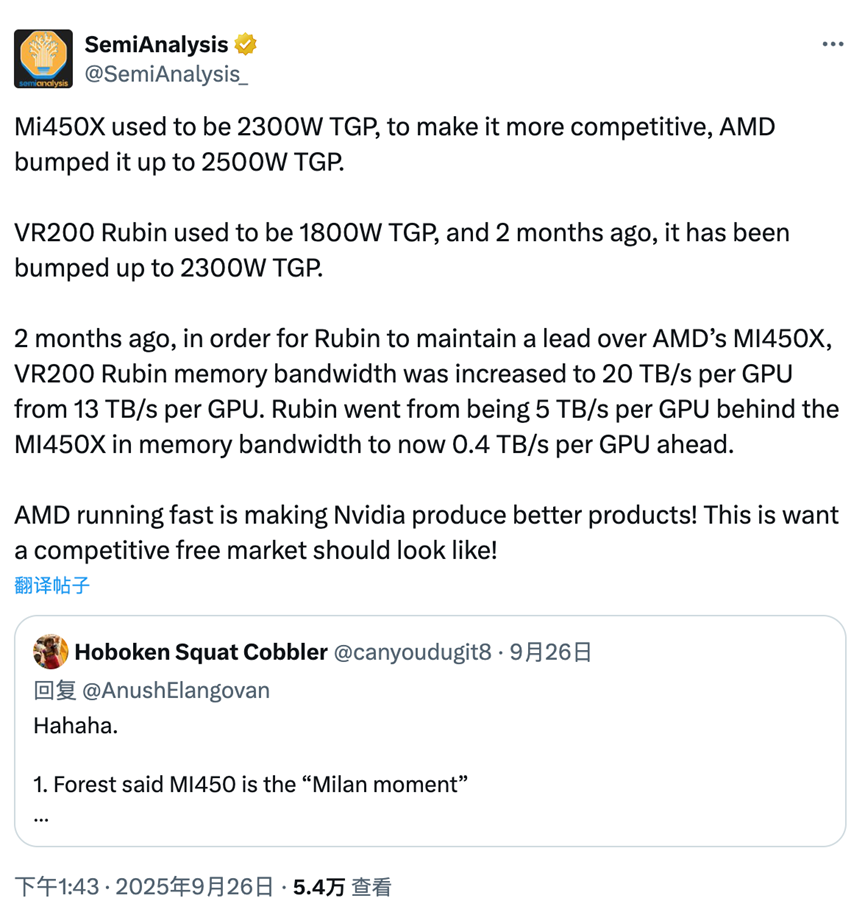
SemiAnalysis 援引了 AMD 高管 Forrest Norrod 的言论,其中提到他对 MI450 产品线持乐观态度。他声称,Instinct MI450 AI 产品线将成为 AMD 的“米兰时刻”,这指的是随着 EPYC 7003 系列服务器处理器的推出,EPYC 产品线发生了怎样的变化。更重要的是,Norrod 明确表示,MI450 将比 NVIDIA 的 Vera Rubin 更具竞争力,并且下一代产品线将毫不犹豫地采用 AMD 的技术栈,而不是 Team Green 的技术栈。

现在,SemiAnalysis 声称 MI450X 和 VR200 Rubin 的设计都经过了不断的修改,TGP 额定值和内存带宽都有所提升。这些调整主要是为了推出一款优于其他产品的优秀产品。例如,MI450X 的 TGP 比初始值增加了 200W,而 Rubin 的 TGP 也相应增加了 500W,达到了 2300W。同样,Rubin 的内存带宽也从每 GPU 13 TB/s 提升到了每 GPU 20 TB/s。SemiAnalysis 声称这些修改与“竞争激烈的市场”有关。

毫无疑问,随着即将推出的产品,AMD 和 NVIDIA 产品之间的技术差距将会缩小,因为预计两家公司将采用相同的技术,无论是 HBM4、台积电的 N3P 节点,还是基于 chiplet 的设计。AMD 过去的产品存在相当大的差距,主要是因为它无法跟上 NVIDIA 的产品周期,但随着 Vera Rubin 的加入,竞争将更加激烈。
AMD 大幅提升互联技术
AMD 计划在 Zen 6 上大幅提升 D2D 互连技术,有趣的是,我们在 Strix Halo APU 上已经看到了它的影子。
在深入研究报告之前,我们必须承认High Yield为发现 Strix Halo 的 D2D 互连变化所做的工作,这确实是一个令人兴奋的发现。现在,作为 AMD,您可以依靠工艺改进、改进芯片组设计和其他元素来提升性能,但就 D2D(芯片到芯片)互连而言,Red 团队自 Zen 2 以来一直沿用相同的技术。然而,随着下一代 Zen 6 处理器的推出,这种情况可能会改变,有趣的是,Strix Halo APU 中确实存在“Zen 6 DNA”。
让我们讨论一下当前互连的工作原理。为了实现芯片间的通信,AMD 利用了 CCD 边缘芯片上的“SERDES PHY”。这些 PHY 允许高速串行通道跨有机基板与 I/O/SoC 芯片进行通信。SERDES 代表串行器/解串器,主要用于将来自各个 CCD 的并行通信转换为串行比特流,并将它们发送到封装内部,因为在传统基板上,在芯片之间使用数百条铜线是不切实际的。

在另一端,解串器将串行比特流转换回另一端的结构。现在,如果您猜到了为什么 SERDES 效率较低,那么您猜对了。但如果没有,那么串行/解串所需的开销会消耗时钟恢复、均衡以及编码/解码所需的能量。其次,转换数据流还会增加两端 D2D 通信之间的延迟,这也是当前方法的一个缺点。
当 D2D 通信仅限于某些“传统”芯片时,SERDES 方法已经足够好用,但随着 NPU 的加入,像 AMD 这样的公司需要稳定、低开销的内存和 CCD 带宽。现在,凭借 Strix Halo,红队彻底革新了 Zen 6 芯片的通信方式。这是通过台积电的 InFO-oS(基板集成扇出技术)和重分布层 (RDL) 实现的,接下来我们将深入解释两者的工作原理。

为了解决数据流转换带来的开销,AMD 在 Strix Halo 中的做法是在由 RDL 制成的芯片下方的“中介层”中的芯片之间布置几条短而细的并行线路。通过InFO-oS,制造商在硅芯片和有机基板之间布置了线缆,现在,CPU 结构可以通过宽并行端口进行通信。如果您问 High Yield 是如何想出这种新方法的,Strix Halo 有一个由微小焊盘组成的矩形区域,这是“扇出”实现的经典表示,并且移除了大型“SERDES”块。

现在,由于无需进行序列化/反序列化,新方法的功耗和延迟要求均有所降低,更重要的是,通过在 CPU 结构中添加更多端口,整体带宽得以提升。然而,扇出型方法存在一些复杂因素,尤其是多层 RDL 的设计复杂性,而且由于片下 空间已有大量扇出型布线,布线优先级现在也需要调整。
无论如何,AMD Strix Halo 在 D2D 互连方面所取得的成就令人惊叹,而且其方法预计将与 Zen 6 CPU 保持一致。
点这里👆加关注,锁定更多原创内容
*免责声明:文章内容系作者个人观点,半导体芯闻转载仅为了传达一种不同的观点,不代表半导体芯闻对该观点赞同或支持,如果有任何异议,欢迎联系我们。
推荐阅读

喜欢我们的内容就点“在看”分享给小伙伴哦~![]()











