
光通讯成下一战场! 继 Scale-Up、Scale-Out 后,NVIDIA 新喊出的 Scale-Across 是什么?
市场调研机构TrendForce预期,2023年400G以上的光收发模组全球出货量为640万个,2024年约2,040万个,预期至2025年将超过3,190 万个,同比增长56.5%。 其中,AI服务器的需求持续推升800G及1.6T的成长,而传统服务器也随着规格升级,带动400G光收发模组的需求。
另据调查,2026年1.6T光模组需求将大幅超出预期,总出货量预期高达1,100万支,主要动能来自NVIDIA与Google的强劲拉货,以及Meta、微软、AWS的部分占比。
光通讯因为高带宽、低损耗与长距离特性,逐渐成为机柜内外互连间的主要选择方案,使得光收发模块成为数据中心互连的关键。 TrendForce 指出,未来 AI 服务器之间的数据传输,都需要大量的高速光收发模块,这些模块负责将电讯号转换为光讯号,并透过光纤传输,以及将接收到的光讯号转换回电讯号。
光收发模块、光通讯和硅光子有何关系?
根据下图的前两个示意图可知,目前市面上的可插拔光收发器传输速率可达 800G,下一阶段的光引擎(Optical Engine,简称 OE) 已经可安装在 ASIC 芯片封装周围,这称为载板光学封装(On-Board Optics,简称OBO),其传输能力可支持至1.6T。
目前业界希望走向 CPO(Co-packaged Optics,共封装光学),即光学元件与ASIC 能共同封装,透过这项技术实现超过 3.2T、最高达 12.8T 的传输速度; 而最终目标则是达到「Optical I/O」(光学I/O),实现类似全光网络的技术,推动传输速度超过12.8T。
如果仔细观察上图,可以发现做为黄色方块的光通讯模块(以前为可插拔型态)距离ASIC越来越近,这主要是为了缩短电讯号的传输路径,从而实现更高的带宽。 而硅光子制程技术,就是将光学元件整合到芯片上的技术。

(Source:日月光)
光通讯需求暴增,业界聚焦三种扩展服务器架构
由于 AI 应用大爆发,对于高速光通讯的需求急遽提升,目前服务器主要聚焦 Scale Up(垂直扩展)、Scale Out(水平扩展)两种扩展方向,分别对应不同的传输需求与技术挑战,而近期 NVIDIA 又新宣布「Scale Across」这个概念,为业界增添一个思考方向。
Scale-Up
Scale-Up 主要作为机柜内高速互连(上图黄色部分),传输距离通常在 10 米以内,由于对延迟的要求极低,内部仍主要以「铜互连」(Copper Interconnects),避免光电转换造成延迟与能耗。 目前解决方案主要以NVIDIA的NVLink(封闭架构)及AMD及其他公司主导的UALink(开放架构)。
有趣的是,今年 NVIDIA 推出 NVLink Fusion,首度开放 NVLink 技术给外部芯片厂商,将 NVLink 从单一服务器节点延伸至整个机柜级(Rack-Scale)架构,不排除是为了因应 UALink 的竞争。
另个值得关注的是,原本主要专注在Scale-Out的博通,正尝试透过「以太网路」(Ethernet)进军Scale-Up市场。 该公司近期推出多款可用来Scale-Up、符合SUE(Scale-Up Ethernet)标准的芯片,而这部分可以往后看后续的NVIDIA与博通的竞争。
Scale-Out
Scale-Out 则是横跨服务器的大规模平行运算(上图中蓝色部分),为了解决数据高吞吐量,并实现无限扩充。 这是以「光通信」为主,主要的网络互连技术需要靠InfiniBand或者以太网(Ethernet),也将带动光通讯模块市场。
InfiniBand 和 Ethernet 又可以分成两大阵营,前者较受 NVIDIA、微软等大厂的青睐,而后者则以博通、Google、AWS 为主。
谈到 InfiniBand,不得不提领导厂商Mellanox,他在2019年被NVIDIA收购,主要是提供端到端Ethernet与InfiniBand智能互连解决方案供应商。 而中国近期裁定英伟达违反反垄断法,就是针对这起收购案。 另个关注点是,虽然英伟达推出许多InfiniBand产品,但也针对以太网推出相关产品如NVIDIA Spectrum-X,可以说是两种市场兼吃。
做为另一大阵营,包括英特尔、AMD、博通等大厂则于 2023 年 7 月集结组成「超以太网联盟」(Ultra Ethernet Consortium,简称 UEC),合作发展改进的以太网传输堆架构,成为挑战 InfiniBand 的力量之一。
TrendForce 分析师储于超认为,Scale Out 所带动的光通讯模组市场,正是未来数据传输的核心战场。
Scale-Across
做为新兴的解决方案,NVIDIA 近期提出「Scale-Across」的概念,即跨数据中心的「远距连接」,距离能超过数公里以上,并推出以以太网为基础、串接多座数据中心的 Spectrum-XGS 以太网。
Spectrum-XGS 以太网将作为 AI 运算是 Scale-Up 和 Scale-Out 以外的第三大支柱,主要用来扩展 Spectrum-X 以太网络的极致效能与规模,可连接多个分布式数据中心。 NVIDIA 介绍,NVIDIA Spectrum-X 以太网除了提供 Scale-Out 的架构,链接整个丛集、将多个分布式数据中心进行互连,快速将大量数据集串流至 AI 模型,还可在数据中心内协调 GPU 与 GPU 之间的通讯。
换言之,这个解决方案结合Scale-Out与跨域扩展,能根据跨域距离灵活调整负载平衡、动态调整算法,因此概念更类似Scale-Across。
NVIDIA 创办人暨执行长黄仁勋表示,「我们在 Scale-Up 与 Scale-Out 能力之上,进一步加入 Scale-Across,把跨城市、跨国家乃至跨洲际的数据中心连结起来,打造庞大的超级 AI 工厂。」
如果从目前产业走向来看,Scale-Up 和 Scale-Out 都是必争之地,可以看出 NVIDIA 和博通如何从对方手中夺取多一分领地。 而 NVIDIA 新喊出的 Scale-Across 则是聚焦横跨数公里乃至于数千公里的跨数据中心传输,有趣的是,博通也有推出相关的解决方案。
AI 芯片传输到 CPO 卡位战:NVIDIA、博通到底在竞争什么?

经过文章上半部理解光通讯与数据中心的三种扩展架构后,我们能够明白市场如今不仅关注竞争对手AMD的动向,更聚焦在AI芯片龙头NVIDIA与全球通讯芯片巨头博通之间的竞争关系。
事实上,现在 AI 产业的竞争除了芯片间的竞争外,更是扩大到系统间解决方案的竞争。
博通与 NVIDIA 第一个交集就是「客制化 AI 芯片」(ASIC)。 由于 NVIDIA GPU 价格高昂,包括 Google、Meta、亚马逊、微软等云服务供应商(CSP)都在开发自家 AI 芯片,而博通的 ASIC 能力成为这些公司的首要伙伴。

除了自研芯片的竞争外,另一个更关键技术是「网络连接技术」,这也是博通与 NVIDIA 的第二个交集。
首先是在 Scale-Up 部分,在 NVLink 和 CUDA 这两大护城河守护下,博通酝酿了多时,终于在今年推出最新的网络交换机芯片 Tomahawk Ultra(战斧),有机会切入 Scale-Up 市场,目标挑战 NVIDIA NVLink 主导地位。
Tomahawk Ultra 是博通一直推动的「纵向扩展以太网」(Scale-Up Ethernet,简称 SUE)计划的一部分,这个产品也视为 NVSwitch 的替代方案。 博通表示,Tomahawk Ultra一次可串联的芯片数量是NVLink Switch的四倍,将交由台积电5纳米制程。
值得注意的是,博通虽然身在 UALink 联盟之一,但他也积极推广基于以太网络的 SUE 架构,因此市场也相当关注博通与 UALink 的竞合关系,以及如何共同应对 NVLink 这个大敌。
为了抵御博通强袭,NVIDIA 今年也推出 NVFusion 解决方案,开放合作伙伴如联发科、Marvell、Astera Labs 等共研,并透过 NVLink 生态系打造客制化的 AI 芯片。 外界认为,这是为了巩固生态系而进行的半开放式合作,也给更多合作伙伴一些客制化空间与机会。
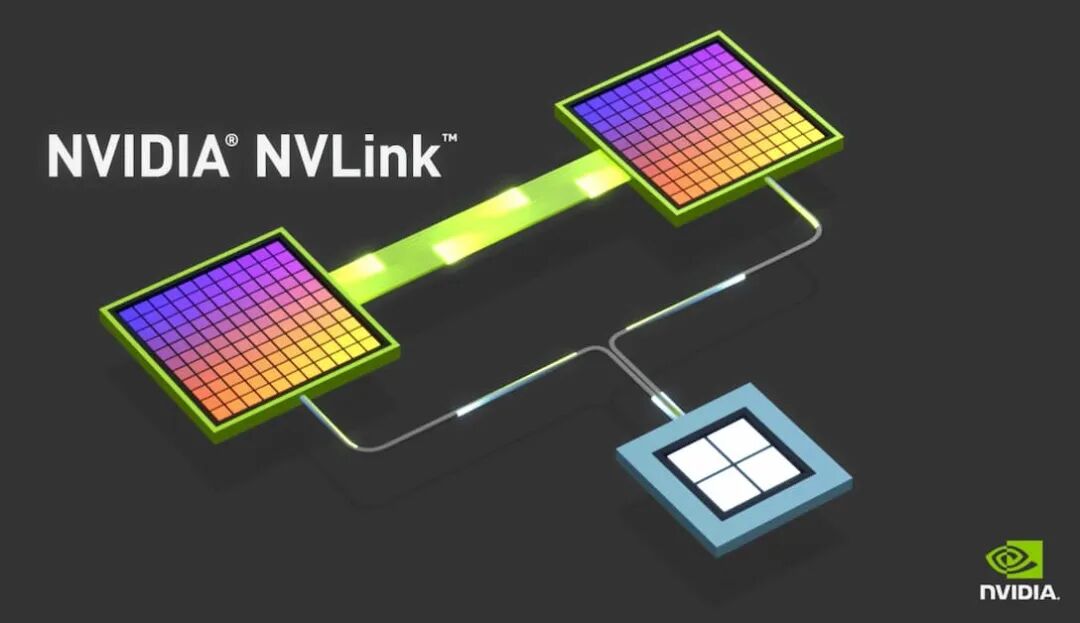
Scale-Out 部分,主要由在以太网深耕已久的博通垄断,近期最新出的产品包括 Tomahawk 6、Jericho4,抢攻 Scale Out 和更远传输距离的商机。
而 NVIDIA 则推出许多 Quantum InfiniBand 交换器产品,以及 Spectrum 以太网交换平台,加强更多面向的 Scale-Out 产品。 虽然InfiniBand属于开放架构,但因产品生态环境主要仍由英伟达收购的Mellanox所垄断,限制了客户的选择弹性。

▲ 根据博通照片,三款产品各自横跨两种不同的服务器扩展架构 。
针对更长距离的跨数据中心扩展的 Scale-Across,目前还不确定博通或 NVIDIA 谁会领先,不过 NVIDIA 针对这一概念率先推出 Spectrum-XGS,该解决方案通过新的网络算法,来实现站点之间更远距离的数据有效移动,也可以作为现有 Scale-Up 和 Scale-Out 架构的补充方案。
至于博通的 Jericho4 也符合 Scale-Across 的概念。 博通指出,Tomahawk 系列芯片能串联单一数据中心内的机柜,连线距离通常不超过一公里(约 0.6 英里),而 Jericho4 设备则能处理距离超过 100 公里的跨机房距离内连线,维持无损 RoCE 传输, 其数据处理能力则约前一代产品的四倍。

那么 NVIDIA 和博通的 CPO 解决方案?
随着网络传输战场持续,相信在光网络的竞争将会更加激烈,对此 NVIDIA 和博通都针对 CPO 光通讯找寻新解方,而台积电、格罗方德也积极开发用于 CPO 的制程与解决方案。
NVIDIA 的策略是以系统架构为出发点,并将光学互连视为 SoC 的一部分,而非外挂式模块,并于今年 GTC 正式发布 Quantum-X Photonics InfiniBand 交换器和 Spectrum-X Photonics Ethernet 交换器,前者将于年底推出,后者则于 2026 年问世。
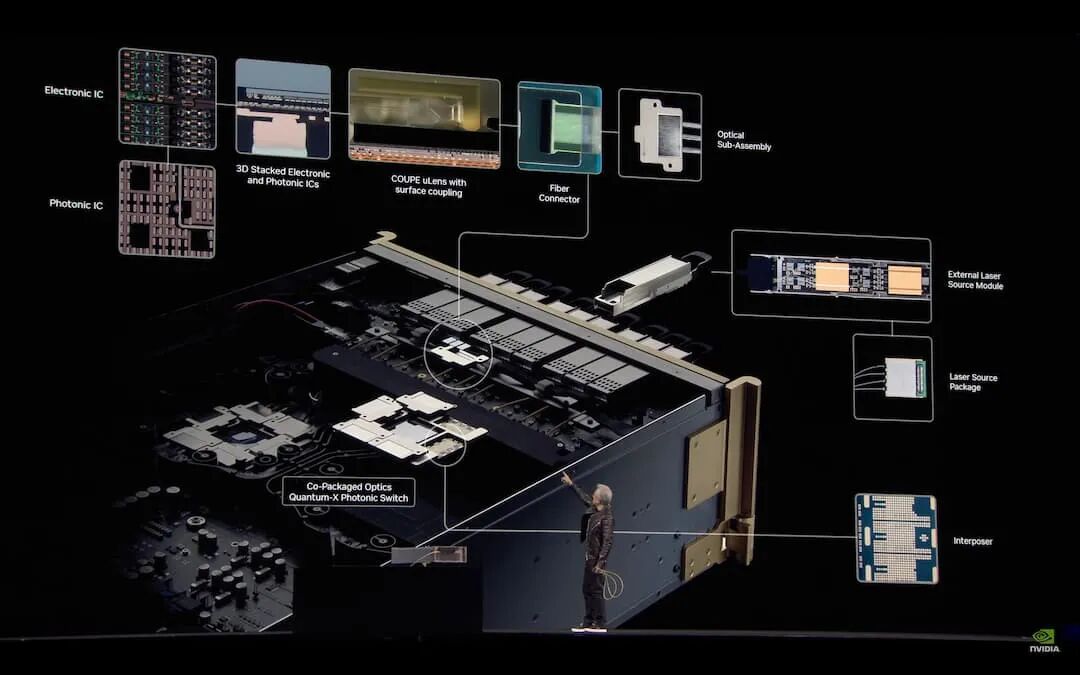
两个平台均采用台积电COUPE平台,透过SoIC-X封装技术将65纳米的光子集成电路(PIC)与电子集成电路(EIC)整合。 而这个策略出发点,是为了强调自家平台整合,加强整体效益与规模扩展。
博通的策略则专注于提供全方位解决方案,聚焦在供应链的规模化运作,供应第三方客户完整的模块化方案,帮助客户应用落地。 博通也表示,公司之所以在CPO领域成功,是建立在深厚的半导体与光学技术整合能力之上。

博通目前推出第三代 200G / lane CPO 抢市。 博通也表示,其CPO产品采用3D芯片堆栈架构,PIC同样使用65纳米,EIC则采用7纳米制程。
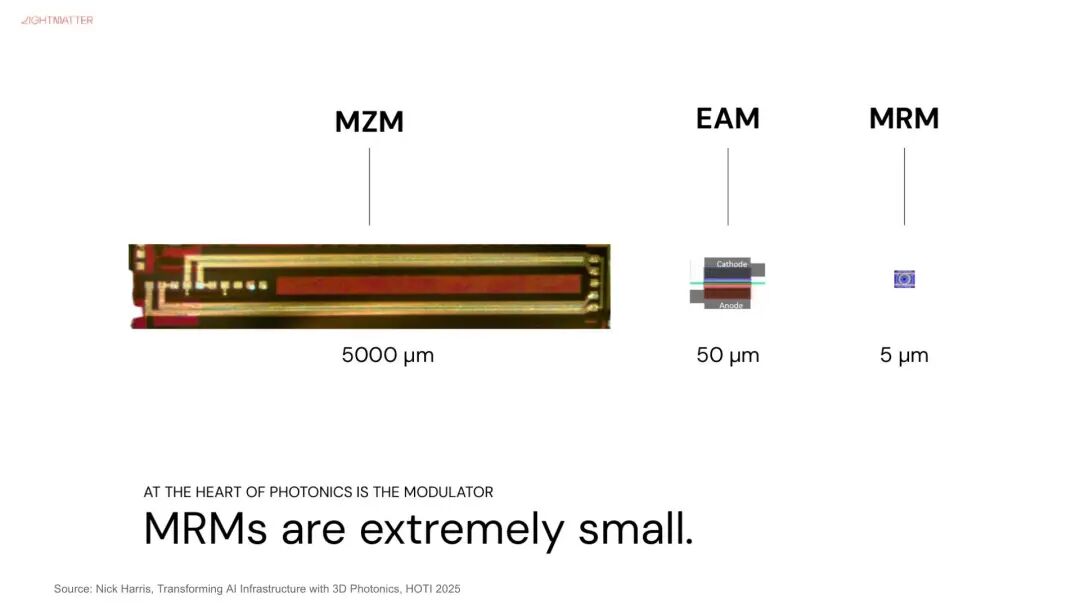
由下图可知,光收发模块由以下关键组件组成,如激光光源(Laser Diode)、光调变器(Modulator)、光感测器(Photo Detector)等。 其中,激光光源负责产生光讯号,光调变器负责将电讯号/数字信号转成光讯号,因为涉及电光转换,也可以说是决定单通道传输速度关键。

在关键的光调变器上,NVIDIA 选择 MRM(微环调变器,Micro-Ring Modulator)。 由于 MRM 尺寸较小,容易受误差及温度影响,也将是导入 MRM 的挑战之一。
至于博通,则选择使用技术较成熟的MZM调变器(马赫–曾德尔调变器,Mach-Zehnder Modulator),同时布局 MRM 技术,目前已经通过 3 纳米制程试产,并以芯片堆叠方式,持续领导 CPO 进展。
目前在 AI 推论持续扩张浪潮下,市场焦点已逐渐从「算力竞赛」转向「数据传输速度」,无论是博通主打的网络与交换技术、NVIDIA 推动的端到端解决方案,谁能率先突破传输效率与延迟的限制,谁就有机会在下一波 AI 竞赛中夺得先机。
来源:technews
推荐:
欢迎加入 EETOP 微信群
报名











