
面向自动驾驶的多模态大模型在 “推理链” 上多以文字或符号为中介,易造成空间 - 时间关系模糊与细粒度信息丢失。FSDrive(FutureSightDrive)提出 “时空视觉 CoT”(Spatio-Temporal Chain-of-Thought),让模型直接 “以图思考”,用统一的未来图像帧作为中间推理步骤,联合未来场景与感知结果进行可视化推理。该方法在不改动原有 MLLM 架构的前提下,通过 “词表扩展 + 自回归视觉生成” 激活图像生成能力,并以 “由易到难” 的渐进式视觉 CoT 注入物理先验。模型既充当 “世界模型” 预测未来,又作为 “逆动力学模型” 进行轨迹规划。

项目主页:https://miv-xjtu.github.io/FSDrive.github.io/
论文链地址:https://arxiv.org/abs/2505.17685
代码地址:https://github.com/MIV-XJTU/FSDrive
多模态大语言模型(MLLM)凭借世界知识与可解释推理能力,正加速进入端到端 “视觉 - 语言 - 动作”(VLA)自动驾驶范式。但现有做法多依赖离散文本 CoT(如规则描述、坐标),本质上是对视觉信息的高度符号压缩,存在跨模态语义鸿沟与时空关系表征不足的问题。

核心问题:面向与物理世界深度交互的自动驾驶,思考过程更应接近 “模拟与想象” 的视觉推演,而非纯符号逻辑?
FSDrive 提出 “时空视觉 CoT”,将未来场景与感知结果(车道线、3D 检测框)统一生成到一张未来图像帧中,作为中间推理步骤。一方面用普通未来帧承载时序演化,另一方面用 “红色车道线与 3D 框” 提供可驾驶区域与关键动态物体的空间先验,从而在视觉域内完成因果推断与决策规划。
本文关键创新:
1) 统一的 “视觉中介” 替代文字 / 表格中介,消除跨模态语义鸿沟;
2) 以极小代价在现成 MLLM 上 “激活” 图像生成能力:仅通过扩展词表引入 VQ 类视觉 token,无需改架构大改或海量训练;
3) 渐进式视觉 CoT:先生成 “物理约束” 的粗粒度感知图(车道线 / 3D 框),再生成细节丰富的未来帧,显式注入物理合理性。
价值:保持端到端简洁链路与可解释可视化推理,同时可大规模利用无标注视频数据学习世界演化规律。
方法

FSDrive 整体框架:
输入:环视图像与任务指令;输出:统一未来帧(含红色车道线 / 3D 框叠加)作为时空 CoT,以及最终轨迹。
双角色:模型先作为 “世界模型” 生成未来统一帧(时空 CoT),再作为 “逆动力学模型” 依据当前观测与未来预测进行轨迹规划。
统一预训练范式:理解 + 生成
理解保持:沿用 VQA 任务(如 OmniDrive-nuScenes/DriveLM 风格),维持原 MLLM 的语义理解能力。
生成激活:不改 MLLM 结构,仅将 VQ-VAE/MoVQGAN 等的视觉 token 并入 LLM 词表,扩展到 “图文共享词汇”。随后以自回归下一 token 预测方式直接生成图像 token,并由 detokenizer 还原像素。
数据高效:相较部分统一理解 - 生成方法,所需数据量约为其 0.3%,且不需从零训练或复杂解码器融合。
渐进式视觉 CoT(物理先验→细节补全)
先推理未来车道线(Ql):指示可行驶区域,注入静态物理约束;
再推理未来 3D 检测(Qd):刻画关键动态体的运动模式,注入动态约束;
最后在上述约束下生成完整未来帧(Qf):补全细节、提升真实性与一致性。
训练阶段采用该 “由易到难” 顺序,推断阶段将三者整合为 “统一未来帧” 以提高效率。
时空视觉 CoT 用于规划
将 “普通未来帧(时间演化)+ 红色车道线 / 3D 框(空间结构)” 合成为统一图像中介 QCoT,直接作为中间推理步骤输入规划头。模型在视觉域完成因果链条的传递,显著减少因符号化导致的语义缺失与二义性。
表达式:基于 It 与 QCoT 自回归生成未来轨迹 Wt,兼容导航指令与自车状态(可选)。
训练策略
初始化:可从任一现成 MLLM(如 Qwen2-VL-2B、LLaVA-7B)出发;冻结视觉编码器,微调 LLM 主体。
阶段一(统一预训练):混合训练 VQA、未来帧生成与渐进式感知生成(车道线 / 3D 框),大量使用 nuScenes 无标注视频用于未来帧预测。
阶段二(SFT):联合优化场景理解(DriveLM GVQA)与轨迹规划(nuScenes,含统一时空 CoT 作为中间步骤),通过不同提示词调用任务专属推理。
实现要点:MoVQGAN 视觉码本并入词表,detokenizer 回像素;预训练 32 轮,SFT 12 轮;仅 LLM 全量微调。
实验
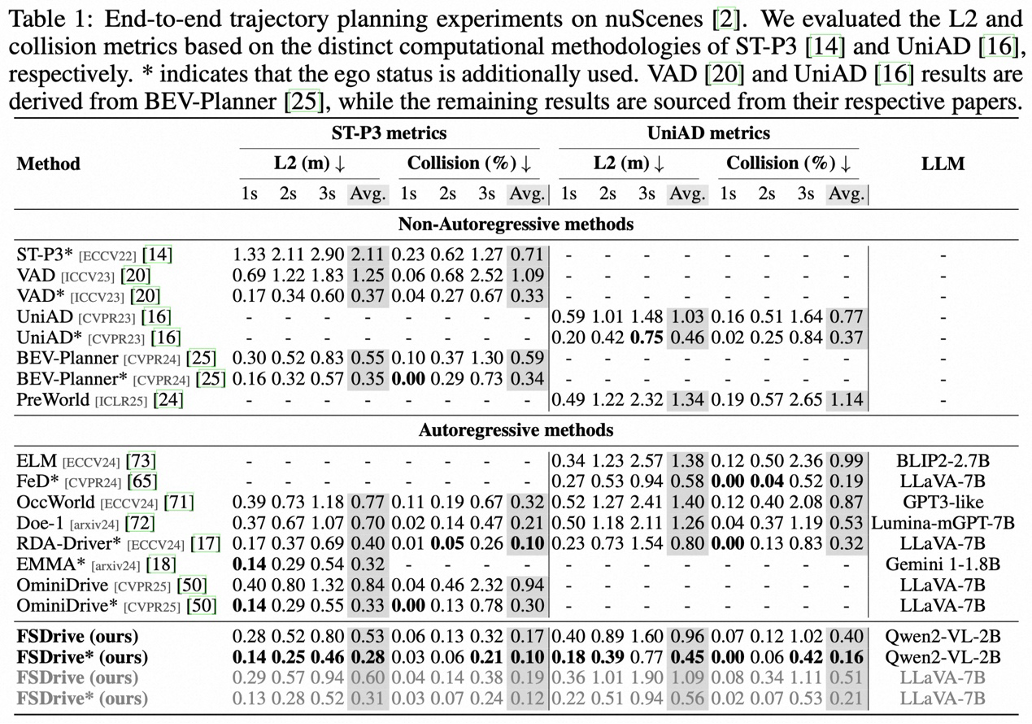
端到端轨迹规划
相比同时具备视觉生成的 Doe-1(Lumina-mGPT-7B),FSDrive 在不使用自车状态时取得更低 L2 与更低碰撞:
ST-P3 平均 L2:0.53 vs 0.70;碰撞率:0.19 vs 0.21(基于 Qwen2-VL-2B)。
UniAD 平均 L2:0.96 vs 1.26;碰撞率:0.40 vs 0.53。
与 LLaVA-7B 系列下的近期方法(如 OminiDrive、RDA-Driver)相比,FSDrive 在相同设置下展现出强竞争力,说明框架可广泛迁移到主流 MLLM。

未来帧生成质量(FID)
在 128×192 分辨率下,FSDrive(自回归)FID=10.1,优于多数扩散式世界模型(如 GEM 10.5)并显著优于 Doe-1(15.9),兼顾实时性与质量。

场景理解(DriveLM GVQA)
Final Score 0.57,超过 OminiDrive(0.56)、Cube-LLM 等;多项语言生成指标与多选准确率(0.72)均表现稳健,表明 “理解 + 生成” 统一预训练的有效性。

定性分析
在错误导航指令下,FSDrive 可通过 “观察 + 未来预测” 的视觉推理纠偏路径,降低潜在碰撞;体现其 “逆动力学” 能力与可解释性。
总结
本文提出 FSDrive:以 “统一的时空视觉 CoT” 作为中间推理,打通未来场景预测与感知结果的视觉表达,让 VLA 在视觉域内完成因果推理与轨迹规划。
方法无需改动原 MLLM 结构,通过扩展词表与自回归训练即可激活图像生成;配合 “由易到难” 的渐进式视觉 CoT,显式注入物理约束,提升未来预测的真实性与一致性。
在规划、生成与理解三大任务的系统验证显示:FSDrive 以更低的数据 / 算力成本实现强竞争力甚至 SOTA 的开放回路表现,并显著降低碰撞风险,推动自动驾驶从 “符号推理” 走向 “视觉推理”。
局限与展望:当前为实时性考虑主要生成前视未来帧,未来可扩展至环视统一预测;同时,随模型落地需重视安全、隐私与监管等伦理合规问题,确保技术向善与可靠部署。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










