
9月29日晚间,DeepSeek突然放出重磅消息——实验性版本的稀疏注意力模型DeepSeek-V3.2-Exp正式发布并开源。

令人惊讶的一点是,其API价格同步下调了超50%,缓存命中时输入价格从0.5元/百万token降至0.2元,输出价格从12元/百万token暴跌至3元。


按综合性价比来说,在API调用层面,DeepSeek-V3.2-Exp对开发者而言是成本最低的选择之一,因为OpenAI、谷歌等AI大厂也有同等便宜的模型来竞争。以下是它与其他主流模型的对比情况:

传统的密集注意力机制会计算序列中每个token与其他所有token之间的交互关系,其计算量随序列长度呈二次方增长。随着token数量增加,这会导致内存占用和计算需求急剧上升,进而推高成本并降低推理速度。
大多数大型语言模型(LLM)均采用“密集型”自注意力机制,即让输入中的每个token与其他所有token进行关联计算。因此,若提示词(prompt)长度翻倍,模型为处理所有token间的交互关系,所需完成的计算量增长会远超两倍。
这会增加GPU使用时间与能耗成本,而这些成本最终会体现在API的 “每百万token定价” 中。在预填充阶段,计算量大致随上下文长度的平方增长;而在解码阶段,计算量至少会随上下文长度线性增长。结果便是:当序列长度达到数万甚至超过10万个token时,成本的涨幅会远高于token数量本身的涨幅。

DSA通过“闪电索引器”(lightning indexer)解决了这一问题——它仅筛选出与当前任务最相关的token进行注意力计算。
这种设计在降低计算负荷的同时,几乎保持了相同的响应质量。
通过在“长上下文长度”场景下减少每个token的计算负担,V3.2-Exp使成本曲线更平缓、整体成本更低。
这一特性让“长上下文任务”的落地变得更具实用性且成本可控,例如文档级总结、长历史多轮对话、代码分析等场景,无需再面对推理成本失控增长的问题。

除架构层面的调整外,DeepSeek-V3.2-Exp还对后训练流程进行了优化。该公司采用了“两步法”方案:专家蒸馏与强化学习。
专家蒸馏的第一步,是针对不同领域分别训练专用模型,涵盖数学、竞赛编程、逻辑推理、智能体编码(agentic coding)与智能体搜索(agentic search)。这些 “专家模型” 均基于同一基础检查点(base checkpoint)进行微调,并通过大规模训练强化能力,以生成领域专属数据。随后,这些领域数据会被蒸馏整合至最终检查点,确保整合后的模型既受益于专家模型的领域知识,又能保持通用能力。

强化学习阶段则实现了重大改进。不同于DeepSeek以往模型采用的“多阶段方法”,此次模型将推理能力、智能体能力及人类对齐(human alignment)训练,通过组相对策略优化(Group Relative Policy Optimization,简称GRPO)整合到了单一强化学习阶段。
这种一体化流程不仅能平衡各领域的性能表现,还避免了多阶段流程中常见的“灾难性遗忘(catastrophic forgetting)”问题——即模型在学习新领域知识时,丢失此前已掌握的能力。

实验结果显示,经过蒸馏与强化学习优化的模型,性能几乎与领域专用专家模型持平;且在强化学习训练后,两者间的性能差距被有效缩小。
在几乎不影响模型输出效果的前提下,新模型实现了长文本训练和推理效率的大幅提升。
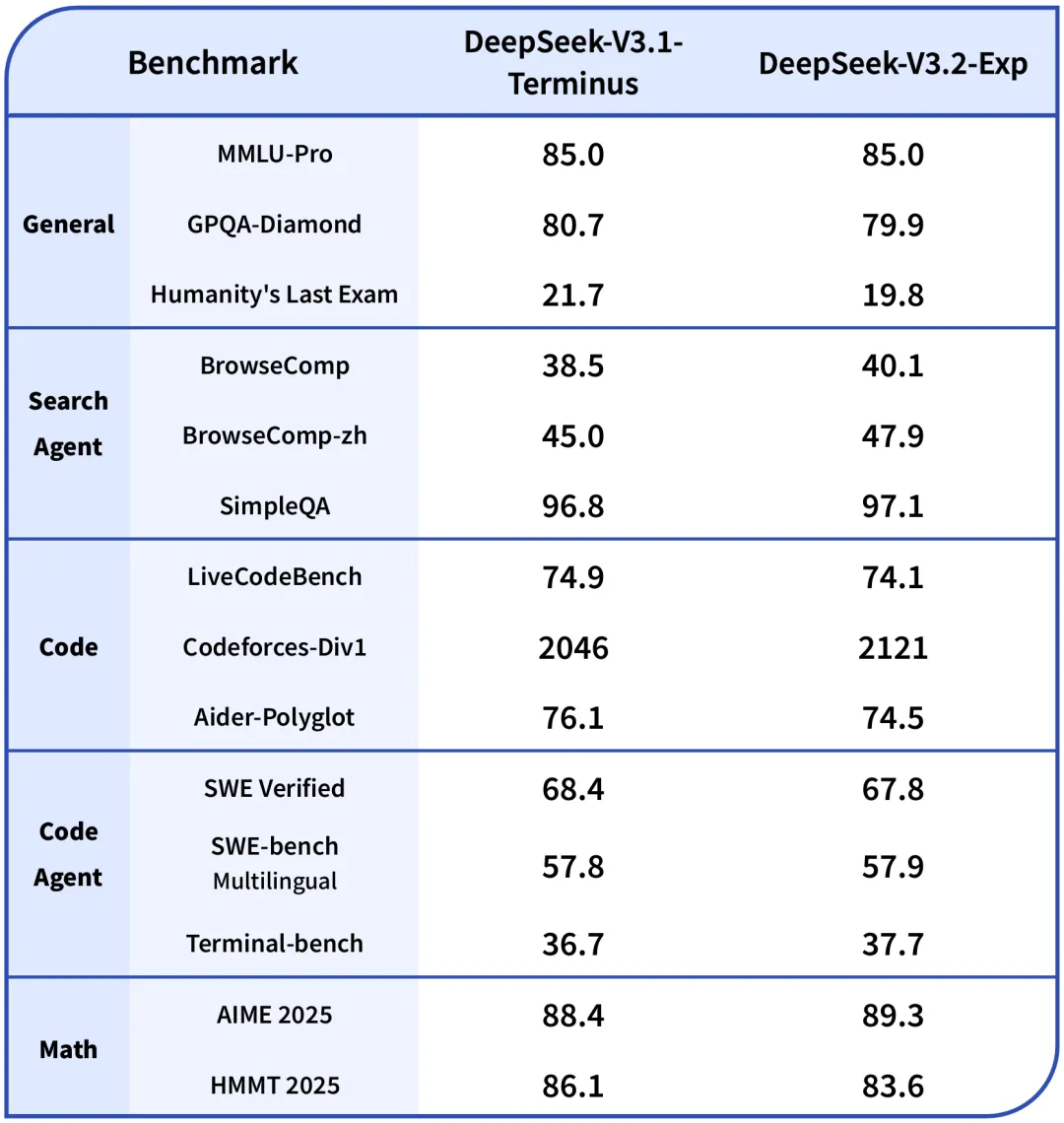
为了严谨地评估引入稀疏注意力带来的影响,演技人员特意把DeepSeek-V3.2-Exp的训练设置与V3.1-Terminus进行了严格的对齐,在各领域的公开评测集上,DeepSeek-V3.2-Exp的表现与V3.1-Terminus基本持平。

秉承开源的理念,DeepSeek在MIT许可下发布了V3.2-Exp模型权重,供研究人员和企业免费下载、修改和部署该模型用于商业用途。
对于本地部署,DeepSeek提供了更新的演示代码,以及与NVIDIA H200、AMD MI350和NPU兼容的Docker镜像,该模型包含6850亿个参数,支持多种张量类型,包括BF16、FP8和FP32。

DeepSeek-V3.2-Exp展示了开源参与者如何推动前沿规模模型,同时解决成本和部署的实际挑战。
通过引入稀疏注意力、降低API价格、将强化学习合并到统一阶段,并通过Hugging Face和GitHub发布保持完全透明,DeepSeek既提供了研究测试平台,也提供了可行的企业选择。

不过这个假期,新发模型不止DeepSeek一家,从目前的基准跑分来看,国内的智谱发布了旗下最强代码Coding模型GLM-4.6,在模型通用能力的评估中,GLM-4.6在部分榜单表现对齐Claude Sonnet 4/Claude Sonnet 4.5,压过DeepSeek的新模型一头。
而美国AI独角兽Anthropic则推出了Claude Sonnet 4.5,定位为“世界上最好的编码模型”,其自主编码时长提升到了30多个小时,向OpenAI最近发布的GPT-5发起挑战。
DSA作为V3.2-Exp的核心创新,被认为是DeepSeek迈向下一代模型的关键中间步骤,其设计思路(如分层索引、动态稀疏模式)为未来千亿级模型的高效训练和推理提供了可复用的技术范式。
V3.2-Exp的实验性质也为迭代留下了更大创新空间,或为V4版本打下更好的基础。










