点击下方卡片,关注“具身智能之心”公众号
作者丨 Wei Gao等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
>>
更多干货,欢迎加入国内首个具身智能全栈学习社区:(戳我),这里包含所有你想要的。
一、核心背景与问题提出
机器人端到端操作策略为实体智能体理解和交互世界提供了巨大潜力。与传统模块化流水线不同,端到端学习能缓解模块间信息损失、孤立优化目标导致的特征错位等关键局限,但现有端到端神经网络(包括基于大视觉-语言-动作(VLA)模型的方法),在大规模实际部署中性能仍显不足——尤其是在可靠性、精度上,甚至逊色于工程化成熟的传统模块化流水线,且在面对未见过的物体或不同机器人平台时,泛化能力短板更突出。
为填补“泛化潜力”与“实际性能需求”的差距,本研究提出一种以“可用性(affordance)”为核心的端到端机器人操作方案:将可用性定义为“任务相关、语义明确的物体局部区域”,并通过“任务特定的定向关键点”来具象化这一概念,最终形成“移动定向关键点链(Chain of Moving Oriented Keypoints, CoMOK)”作为动作表示。这一设计既实现对不同形状、尺寸物体的自然泛化,又能达到亚厘米级精度,同时支持多阶段任务、多模态机器人行为与可变形物体操作。
二、相关工作梳理
机器人抓取检测
抓取算法的核心是寻找稳定抓取位姿,相关研究已较为广泛,但这类方法多局限于“抓取”这一单一任务。而提出的方法将抓取检测纳入统一动作表示框架,使其成为整体公式的一个特例。
基于可用性的机器人操作
传统可用性概念多用于研究人与动物行为,在机器人操作中,常指“与任务相关的物体局部区域”。现有研究多通过目标检测、分割网络识别这些区域,或结合关键点表示(如模仿学习、约束优化、LLM推理)提升泛化性,但存在明显局限:仅适用于特定任务(如物体放置、工具使用),且仅能处理刚性物体。
提出的方法同样基于关键点可用性,但突破了上述局限:一方面,其动作表示具有通用性,可覆盖多种操作技能(如抓取、放置、插入);另一方面,能直接处理可变形物体,扩展了应用场景。
机器人操作的端到端学习
端到端策略通过联合优化整个操作流水线,避免传统模块化中“感知-运动规划-控制”孤立训练的问题。现有方法多将原始感官输入直接映射到低阶控制动作(如关节力矩),或结合VLM构建VLA模型以利用大规模预训练的泛化能力,但动作表示多局限于“末端执行器位姿”或“关节角度”。
这里提出的方法属于端到端学习范畴,但核心差异在于动作表示:以可用性为基础的定向关键点表示,不仅能退化为传统末端执行器位姿(作为特例),还能在泛化性与精度间取得更好平衡。
三、核心方法:基于可用性的动作表示
基础控制权限定义
研究首先明确机器人在不同场景下的控制权限,为后续动作表示奠定基础,具体分为三类(如figure 1所示):

对自身末端执行器:拥有完全6自由度(6-DoF)控制权限; 对抓取的刚性物体:拥有完全6-DoF控制权限(受可达性、碰撞等物理约束限制); 对抓取的可变形物体:无完全控制权限(因可变形物体自由度超6),但可对“抓取的局部区域”进行6-DoF控制。
此外,对于未抓取的物体,机器人可“想象”抓取后的控制权限与操作行为,为规划提供前瞻性。
基础动作表示公式与实例
基础公式
神经网络以“场景观测(,如点云或图像)”和“任务描述(,如自然语言‘拿起杯子’)”为输入,输出包含三部分的动作信息,公式如下:
其中:
:机器人拥有(或将要拥有)控制权限的环境部分,实际中可用场景的边界框或分割掩码表示; :基于定义的“任务相关可用性帧”(属于SE(3)空间,含定向信息),刚性物体上固定,可变形物体上固定于局部区域; :“目标动作帧”(属于SE(3)空间),当与对齐时,任务即可完成。
实例:倒水任务
以倒水任务(如figure 2所示)为例,该任务分为三个阶段,每个阶段对应不同的、与,且能自然适配不同形状、尺寸的杯子:
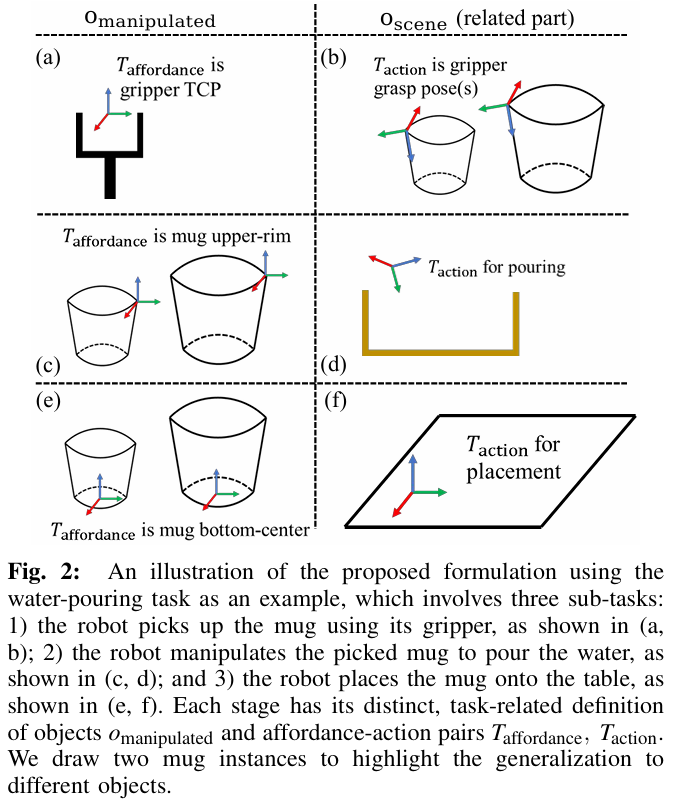
阶段1(拿起杯子):为机器人夹爪,为夹爪TCP帧(工具中心点),为杯子的抓取位姿(本质是传统抓取检测问题); 阶段2(倒水):变为杯子,为杯口边缘,为杯子相对于接水容器的“倒水构型”; 阶段3(放杯子):仍为杯子,变为杯底中心,为杯子在桌面上的“稳定放置构型”。
若将固定为夹爪、固定为夹爪TCP帧,该公式即退化为传统“末端执行器位姿”动作表示,体现了通用性。
方法扩展:覆盖复杂场景
多阶段任务扩展
长时程任务(如倒水)需分解为多个子任务,传统方法需手动设置每个子任务的描述,而提出的方法可从“全局任务描述()”自动生成子任务,且结合场景观测动态调整(如杯子已拿起则跳过“抓取子任务”)。公式如下:
要在Markdown中输出图中的公式,可使用LaTeX语法,如下所示:

其中为子任务动作信息,子任务描述可通过现有LLM/VLM(如提示工程或微调)生成,该方法则补充了对应的可用性-动作帧对,形成完整子任务规划。
多动作候选扩展
实际操作中,多个动作候选可能均能完成任务(如多个抓取位姿、多个放置位置),这些候选来自两类情况:不同(如多个杯子)、同一的不同-对(如同一杯子的多个抓取位姿)。
研究通过“分数匹配网络(扩散模型变体)”建模动作分布,实现多候选生成:对不同,通过目标检测/分割网络识别;对不同-对,通过扩散模型的迭代去噪过程生成。
轨迹动作扩展
基础公式中是单一SE(3)帧,无法满足需连续运动的任务(如切水果、绘画)。因此,研究将其扩展为“SE(3)轨迹序列()”,公式如下:

其中为时间步长,的语义是“沿该轨迹运动即可完成任务”,支持两种轨迹类型(如figure 3所示):

稀疏轨迹:如切水果,仅需两个动作帧(在水果上方,在水果下方); 密集轨迹:如绘画,需数百个连续动作帧。
此外,还需考虑初始点()与当前的对齐问题:
若要求对齐:可直接转换为末端执行器轨迹,在线高频评估(如10Hz)时可作为反应式策略; 若不要求对齐:到的运动可视为“任务无关”,只需满足物理约束(如无碰撞、可达),轨迹生成可采用传统运动规划或学习型方法。
四、神经网络架构与实现
整体架构
架构分为“任务规划网络”与“动作预测网络”两部分,前者负责子任务分解与区域定位,后者负责具体可用性-动作帧预测,形成端到端流水线。
任务规划网络
输入:RGBD图像、全局任务描述(); 输出:子任务列表(),其中,为“需关注的环境区域”(如倒水任务中的接水容器);
实现方式:微调Groma VLM(一种视觉-语言模型),利用其图像理解与语言生成能力,同时输出子任务描述与区域掩码(、)。
动作预测网络
输入:场景点云(由RGBD图像深度通道生成,抓取检测任务使用现有数据集点云)、子任务特征(,即的编码特征);
输出:所有子任务的与; 核心设计(如figure 4所示):

采用transformer架构,先将点云编码为特征序列,再将“带噪声的与”展平为 tokens 并与点云特征融合; 通过多轮自注意力层预测每个SE(3)元素(映射为空间)的去噪向量,实现动作分布建模(扩散模型思想); 引入交叉注意力层,融合点云特征与任务特征,并通过阶段掩码避免对“无任务阶段”的注意力计算与损失优化; 特例处理:当为夹爪时,固定为“单位矩阵”,无需网络预测,仅输出。
机器人轨迹生成
动作预测网络输出的与需转换为“关节空间轨迹”才能执行,研究采用两种生成方式:
仿真实验:使用学习型策略(现有方法),输入点云特征与物体点云,输出关节位移; 真实世界实验:使用传统任务-运动规划算法(现有方法),优势在于能自动从多动作候选中选择“物理可行”的轨迹(满足无碰撞、可达性、轨迹长度优化等约束),弥补学习型方法在真实场景的性能不足。
五、实验验证与结果分析
实验设置
硬件:6自由度机械臂(Rokae SR5)、平行夹爪、末端执行器挂载RGBD传感器; 任务:覆盖四类典型操作场景(如figure 5所示),均需适配“不同形状/尺寸物体”与“动态环境”(如障碍物):

平行夹爪抓取:检测抓取位姿与“预抓取位姿”(沿夹爪z轴远离抓取位姿),使用现有数据集验证; 稳定放置:抓取物体(瓶子、盒子、三脚架,共35个实例),避开5个随机放置的障碍物,将物体稳定放在桌面; 电缆插入:抓取6种不同绳索(可变形),垂直插入随机放置的夹具; 杯子挂架:抓取20种不同杯子,挂到3种不同架子上,需厘米级精度。
动作分布分析
对“稀疏动作分布任务”(挂杯子、插电缆),统计“预测动作与真实动作的平移/旋转误差”;对“密集动作分布任务”(稳定放置、抓取),统计“有效动作比例”,结果如table I所示:
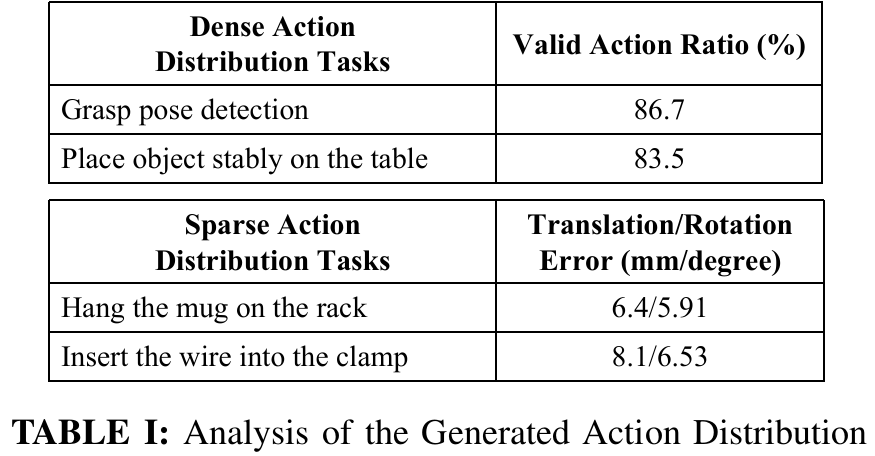
挂杯子:平移误差6.4mm,旋转误差5.91度; 插电缆:平移误差8.1mm,旋转误差6.53度; 有效动作比例:稳定放置任务中,满足“放置点距桌面≤1cm、放置帧z轴与世界z轴夹角≤15度、无碰撞”的动作占比高。
整体任务成功率
统计四类任务的“执行成功率”(如table II所示),成功标准根据任务特性定义:
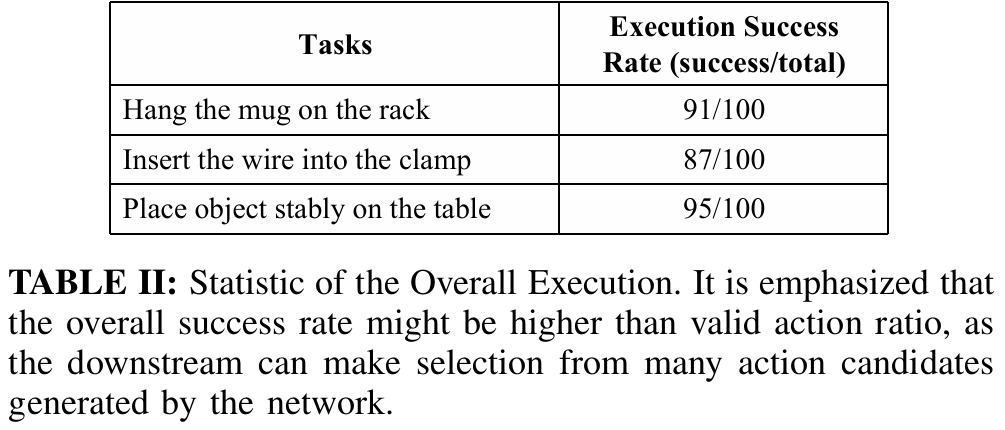
挂杯子:91/100(失败指杯子未挂到架子上); 电缆插入:87/100(失败指电缆未插入夹具); 稳定放置:95/100(失败指轨迹碰撞、物体放置后掉落); 抓取:未单独列成功率,采用现有流水线方法的评估标准,结果符合预期。
失败模式分析
主要失败源于两类问题(如figure 7所示):

任务规划网络检测失败:如未识别出“需操作的物体”(如被障碍物遮挡的杯子); 可达性限制:运动规划算法难以规避硬件约束(如RGBD传感器线缆限制机械臂运动范围)。
参考
[1]ImaginationPolicy: Towards Generalizable, Precise and Reliable End-to-End Policy for Robotic Manipulation











