来源:大明雪山
当所有人都在为GPT-4o的多模态能力狂欢时,“AI教母”、斯坦福教授李飞飞和她的天才学生Justin,却早已将目光投向一个被大众忽视的领域。他们最近联手创办了一家名为World Labs的公司,目标直指AI的下一个前沿——空间智能 (Spatial Intelligence)。
李飞飞直言:“语言是人类发明的信号,但我们生活在物理世界里。空间智能,才是通往通用人工智能(AGI)更基础、更核心的一步。”
为什么?因为我们生活的世界是三维的,而目前的AI(包括多模态模型)在底层逻辑上仍是“一维”的。
这场深度对话,不仅揭示了AI下一个十年的技术浪潮,更藏着两位顶级专家的成长心法和决策模型。读完这篇,你将获得:
🌟 1个认知框架:彻底看懂“空间智能”与语言模型的本质区别,理解AI技术的天花板与未来。 🌟 3个蓝海机会:普通人也能关注的虚拟世界生成、增强现实(AR)和机器人领域的应用风口。 🌟 1个顶级思维:李飞飞的“北极星”思考法,如何帮你规划职业与人生。
第一幕:寒冬与爆发,我们如何走到AI的“寒武纪”
🌟 了解AI发展的真实脉络,看清技术浪潮的周期,找到属于自己的位置。
主持人:
过去两年,我们见证了消费级AI公司的爆炸式增长,这太疯狂了。但你们二位已经在这个领域深耕了几十年。不如我们先回顾一下,这一切是如何发生的?
李飞飞 (Fei-Fei Li):
这确实是一个非常激动人心的时刻。我个人从事这个行业已经二十多年了。我们经历了上一个“AI的冬天”,见证了现代AI的诞生,然后是深度学习的起飞,它向我们展示了像下棋这样的可能性。
现在,我们正看到这项技术和产业的深化,比如语言模型的普及。而此刻,我认为我们正处在一场“寒武纪大爆发”之中,这几乎是字面意义上的——因为除了文本,你现在看到了像素、视频、音频,所有这些都涌现出可能的AI应用和模型。所以,这真的是一个激动人心的时刻。
Justin:
是的,当然。我第一次接触AI是在我本科快毕业的时候。我在加州理工(Caltech)读的数学和计算机科学。当时,谷歌大脑的Hong Knightlee和吴恩达(Andrew Ng)等人发表了一篇后来非常著名的论文——“猫脸识别论文”(The Cat Paper)。那是我第一次接触到“深度学习”这个概念,感觉这技术太神奇了。
大约在2011、2012年,我第一次领悟到那个后来定义了我十多年人生的“配方”:用极其强大的通用学习算法,结合海量的算力,再结合海量的数据,然后,奇迹就会发生。我当时就想:“天啊,这就是我这辈子想做的事。”
第二幕:算力、数据和算法,谁才是真正的“第一性原理”?
🌟 掌握判断AI项目潜力的核心标准,不再被表象迷惑。
主持人:
我们经常谈论一些划时代的事件,比如ImageNet开启了计算机视觉的时代,Transformer论文带来了注意力机制。是不是可以说,这些算法上的突破是今天一切的源头?
Justin:
我认为,最大的突破是算力(Compute)。我知道AI的故事常常被讲述为算力的故事,但无论人们怎么谈论,我觉得大家还是低估了它。过去十年,我们看到的算力增长是惊人的。
真正被认为是计算机视觉领域深度学习突破性时刻的第一篇论文是AlexNet(2012年),它在ImageNet挑战赛上大放异彩,击败了所有其他算法。那是一个拥有6000万参数的深度神经网络,它在两块GTX 580显卡(2010年顶级的消费级显卡)上训练了6天。
为了让大家有个概念,我昨晚算了些数字。英伟达最新最强的产品是GB200。你们猜猜从GTX 580到GB200,原始算力提升了多少倍?……是几千倍。我计算了一下,当年那个6天的训练任务,如果放在一台GB200上,只需要不到5分钟。
主持人:
但也有另一种说法,认为是新的数据源解锁了深度学习,比如ImageNet。所以到底是算力更重要,还是数据更重要?
李飞飞 (Fei-Fei Li):
在我博士毕业和刚成为助理教授的时候,AI领域有一个被忽视的要素,它在数学上对驱动模型的泛化能力至关重要,但整个领域当时并没有这么想——那就是数据(Data)。
当时我们都在琢磨贝叶斯模型或者核方法的复杂性,但我的实验室可能比大多数人更早地意识到:如果你让数据来驱动模型,你就能释放出前所未见的力量。
这正是我们当时在ImageNet项目上进行疯狂押注的原因。当时的数据集规模都是几千个,我们说,忘掉这些吧,我们必须把它推向互联网的规模。幸运的是,那也正是互联网崛起的时代,我们乘上了那股浪潮。
第三幕:从“像素生成文字”到“语言生成世界”:一个天才博士的十年进化史
🌟 从顶级人才的成长路径中,学到可复制的个人发展策略。
李飞飞 (Fei-Fei Li):
Justin的整个博士生涯,几乎就是AI领域发展轨迹的一个微缩故事。他刚来我实验室时,我“逼”他做的第一个项目是关于数据的,他当时并不喜欢。
Justin:
(笑)现在回想起来,我确实学到了很多有用的东西。我的博士生涯大概有三个阶段。第一个是图像和文字的匹配。然后我们进入了生成阶段:输入像素,生成文字。但那仍然是一种信息损失很大的方式。
再后来,我做了一项非常著名的工作。2015年,一篇名为《艺术风格的神经算法》(A Neural Algorithm of Artistic Style)的论文横空出世,它能把普通照片变成梵高风格的画作。这在2015年简直是石破天惊。我当时就被迷住了,花了一个长周末复现了算法。它很美,但非常慢,生成每张图都需要跑一遍优化循环。
我当时就想让它变快。后来我提出的加速方法获得了很大的关注,那可能是我第一次尝到学术工作产生行业影响力的滋味。
李飞飞 (Fei-Fei Li):
我为Justin感到骄傲的还有一件事,这直接关系到今天的生成式AI(GenAI)。在他博士生涯的最后阶段,在全世界还没搞懂GenAI是什么的时候,他做了一项工作:输入语言,直接生成一张完整的图片。这是最早的GenAI工作之一。当时我们还无法处理自然语言,所以我们用“场景图”(Scene Graph)这种结构化的语言来输入,比如“羊在草地上,天空在上方”,然后他用GAN(生成对抗网络)成功生成了图像。
所以你看,从数据到匹配,到风格迁移,再到图像生成。你问这是一个突变吗?对我们这样身处其中的人来说,它是一个持续发生的过程。但对世界来说,结果的呈现更像是突变。
第四幕:终极对决:为什么说“一维”的语言模型,永远无法真正理解“三维”世界?
🌟 建立对AI技术边界的深刻认知,看透当前大模型的天花板与未来。
主持人:
这很有趣。现在大家都在谈论多模态大模型,它们也能处理图像和语言。你们正在做的“空间智能”和它们有什么本质区别?难道不都是在处理像素和语言吗?
Justin:
要回答这个问题,你需要稍微打开这些系统的“黑箱”。
如今的语言模型和多模态语言模型,它们底层的表示(Representation)是一维的(one-dimensional)。我们谈论上下文长度、Transformer、序列、注意力机制……从根本上说,它们的世界观是一维的序列。这对于处理语言来说非常自然,因为书面文本就是离散字符的一维序列。当它们处理其他模态(如图像)时,本质上是把这些模态“硬塞”进这个一维的表示框架里。
而当我们转向空间智能时,我们走了另一条路。我们认为,世界的三维本质应该在表示中处于中心位置。这种算法视角为我们打开了新大门,让我们能以不同方式处理数据,获得不同类型的输出,解决不同类型的问题。所以,即使表面上看多模态大模型也能看图,但它们的核心里,没有那个根本性的三维表示。
李飞飞 (Fei-Fei Li):
我完全同意Justin。一维与三维表示的对比是核心区别之一。另一个区别有点哲学,但对我来说很重要:语言,从根本上说,是一个纯粹的生成信号(generated signal)。自然界里本没有语言,你不会在野外看到天空写着字。你喂给模型什么数据,它就能在足够泛化后,以某种形式再把同样的数据吐出来。
但三维世界不是。那里有一个真实存在的三维世界,它遵循物理定律,有其自身的结构。从根本上把这些信息提取出来、表示出来、并能生成出来,这是一个完全不同的问题。我们会借鉴语言模型的思想,但这在哲学上对我来说是一个不同的问题。
第五幕:World Labs的野心:空间智能将引爆三大万亿级市场
🌟 洞察AI未来的商业应用蓝海,为创业或职业转型寻找方向。
主持人:
那么,一个能实现空间智能的模型,具体能用来做什么呢?
Justin:
我最兴奋的一个方向是世界生成(World Generation)。我们已经习惯了文生图、文生视频,但你可以想象把它再升一级,直接生成一个三维世界。未来,我们得到的不再是一张图或一个短片,而是一个完整的、充满活力的、可交互的三维世界。可以用于游戏、虚拟摄影、教育……任何你能想到的地方。
这实际上是在创造一种新媒体。今天,创造一个虚拟互动世界需要数亿美元和巨大的开发时间,所以只有像3A游戏这样能卖出数百万份的产品才在经济上可行。但如果我们能用AI大幅降低创造这些世界的成本,那么它就能被用于各种小众、个性化的体验。
李飞飞 (Fei-Fei Li):
另一个令人兴奋的应用,是增强现实(Augmented Reality)。就在World Labs成立前后,苹果发布了Vision Pro,他们用了“空间计算”这个词。而我们是“空间智能”。可以说,空间计算需要空间智能。
这项技术将成为AR/VR/MR设备的“操作系统”。无论硬件是眼镜还是隐形眼镜,它都需要一个接口来连接真实世界和你叠加在上面的信息。它可以指导一个非专业人士修理汽车,也可以是下一代《Pokemon Go》。要有效地与真实的三维世界交互,你必须拥有一个三维的数字表示。
最后,是机器人(Robotics)。任何类型的机器人,它们的交互界面天生就是三维世界,但它们的大脑是数字世界。连接机器人大脑和真实世界的桥梁,必然是空间智能。
1. 虚拟世界生成:颠覆游戏、影视和教育内容的生产方式。
2. 增强/混合现实:成为下一代计算平台(如Vision Pro)的“操作系统”。
3. 物理世界交互:为机器人提供理解和操作现实世界的能力。
第六幕:寻找“北极星”:顶级团队的组建与个人选择
🌟 学习顶级专家的决策智慧和识人方法。
主持人:
李飞飞,你为什么决定现在全身心投入创办World Labs?是技术上的突破,还是个人选择?
李飞飞 (Fei-Fei Li):
对我来说,我的整个学术生涯都是在寻找“北极星”——那些对我们领域发展至关重要的宏大问题。我曾以为我的北极星是“用语言讲述图像的故事”,但当Justin和Andre(Andrej Karpathy)他们做到时,我发现它比我想象的100年要快得多。
视觉空间智能是我的热情所在,因为它和语言一样基础,甚至在某些方面更古老。我相信,让智能体(无论是人还是机器人)能够观察、推理并与世界互动,是通往更高智能的必经之路。
现在是正确的时机。就像Justin说的,我们有了算力,我们对数据的理解远超ImageNet时代,我们还有了算法上的进步,比如我们的联合创始人Ben Mildenhall在NeRF(神经辐射场)上的开创性工作。所有要素都已具备,是时候下注并全力以赴解锁空间智能了。
主持人:
你们如何知道自己已经实现了目标?
李飞飞 (Fei-Fei Li):
嗯…虽然北极星看似遥不可及,但有时你也能到达虚拟的“北极星”。对我来说,当成千上万的人和企业开始使用我们的模型来解决他们对空间智能的需求时,那一刻,我就知道我们抵达了一个重要的里程碑。
Justin:
我倒觉得我们可能永远也“到不了”。这件事太根本了。宇宙本身就是一个巨大的、不断演化的四维结构,而空间智能的终极目标就是理解它的全部深度。我认为这段旅程会把我们带到今天无法想象的地方。

经常有粉丝后台问这样一个问题:
「3D视觉从入门到精通」知识星球,里面有什么内容? 加入星球,是不是可以学习课程呢?有哪些会员权益? 星球里会发布顶会论文等最新动态吗?
今天,咱们一起聊一聊这个沉淀了7年的3D视觉技术圈子。
一 什么是知识星球?
知识星球是一个高度活跃的社区平台,在这里你可以和相同研究方向的小伙伴一起探讨科研工作难题、交流最新领域进展、分享3D视觉最新顶会论文&代码资料、分享视频(讲解3D视觉重要知识点)、发布高质量的求职就业信息、承接项目等,当然还可以侃侃而谈,吐槽学习工作生活。
二 「3D视觉从入门到精通」知识星球
目前已有6400+活跃成员,主要涉及方向:工业3D视觉、SLAM、自动驾驶、三维重建、无人机、具身智能、大模型等科技前沿方向。
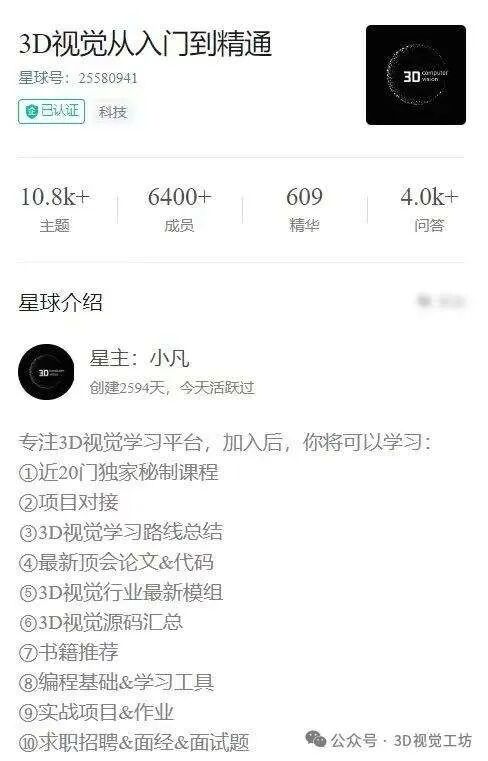
细分方向众多,包括但不限于:工业3D视觉、三维重建、自动驾驶、具身智能、大模型、扩散模型等科技前沿方向,也涉及视觉竞赛、硬件选型、视觉产品落地经验分享、学术&求职交流等。我们也会紧跟最新前沿科技发展,也是我们星球里的热门讨论话题。

三 星球内独家秘制课程

星球内视频课程详细如下:
3.1 基础课程
3.1.1 高精度相机标定从理论到实战系统教程
本课程主要包含两部分,分别是相机标定和3D视觉,相机标定包含单目、双目和鱼眼相机标定;3D视觉包含立体视觉、结构光和TOF,以立体视觉为主。课程提供对应数据与代码。
课程亮点:除了相机标定的基础原理和代码之外,星球里还补充了高精度相机标定的改进方法以及实战技巧,这是相当硬核的。

3.1.2 ROS2从入门到实战视频教程
ROS2从入门到实战视频教程,从小白方式介绍到高阶使用讲解,对ROS2进行全面的实操教学训练,为大家提供系统性的学习机会。

3.1.3 四旋翼飞行器:算法与实战

3.2 工业3D视觉系列视频课程
3.2.1 基于面结构光三维重建系列视频


3.2.1 机械臂抓取、三维点云、三维重建等

3.3 3DGS三维重建专项研讨会
3.3.1 两期3DGS三维重建直播研讨会

3.4 SLAM系列视频
3.4.1 如何轻松拿捏LIO-SAM?(提供注释版本代码)

3.4.2 彻底剖析激光-视觉-IMU-GPS融合SLAM算法:理论推导、代码讲解和实战系列视频**
本视频课程从理论和代码实现两个方面对激光雷达-视觉IMU-GPS融合的SLAM算法框架和技术难点进行讲解,并且博士大佬会根据自己多年的机器人工程经验,向大家讲解在实际机器人应用中多模态融合的方法和技巧。

3.4.3 ORB-SLAM3理论基础+关键技术详解

3.4.4 视觉-惯性SLAM:VINS-Fusion原理精讲
视觉-惯性SLAM的入门与实践视频教程,结合VINS-Fusion源码,系统地对视觉-惯性SLAM的基础理论知识进行梳理。整套课程由一线算法工程师教授,从基础理论到代码剖析,保姆级教学,助力学员一步步从小白成长为大牛。

3.5 自动驾驶
3.5.1 面向自动驾驶领域的多传感器融合系统学习课程
主要分两个大模块:理论篇和实战篇,理论篇部分主要介绍自动驾驶中常用的传感器硬件、传感器间的时间同步和空间同步以及多传感器间的信息融合理论知识;实战篇更多偏向工程应用,工程中传感器间同步与融合如何实现等。

3.5.2 面向自动驾驶领域的3D点云深度学习目标检测系列视频
本视频教程以3D点云深度学习为主,对Point-based和Voxel-based系列的3D目标检测网络架构进行系统剖析和代码梳理,助力各位同学在点云深度学习更快的入门和更深的理解。

3.5.3 单目深度估计方法:理论与实战视频
视频教程主要分为两大部分:理论篇和实战篇,由于有监督方法的深度真值获取困难,且无监督方法的效果与有监督方法几乎相当,我们将课程的重心放在了无监督方法上。

3.5.4 自动驾驶中的深度学习模型部署实战视频
本视频教程将采用理论和实践相结合的思路,首先对TensorRT的编程模型以及GPU/cuda的相关知识进行讲解,带领大家达到知其所以然的程度;之后课程将用分类、检测、分割三个例子来展示详细编程流程,并给出相关代码,达到真正能落地的工业级分享。

四 3D视觉顶会直播
星球内已沉淀近超过100场3D视觉顶会论文直播回放,内容覆盖具身智能、自动驾驶、三维重建、数字人、扩散模型、3D生成等前沿领域。
具身智能

三维重建

自动驾驶

SLAM

其他方向

五 3D视觉基础入门
考虑到很多初学者在配置3D视觉软件或者视觉库可能会有困难,我们已经为大家梳理了各个模块的配置教程文档,供学习参考。

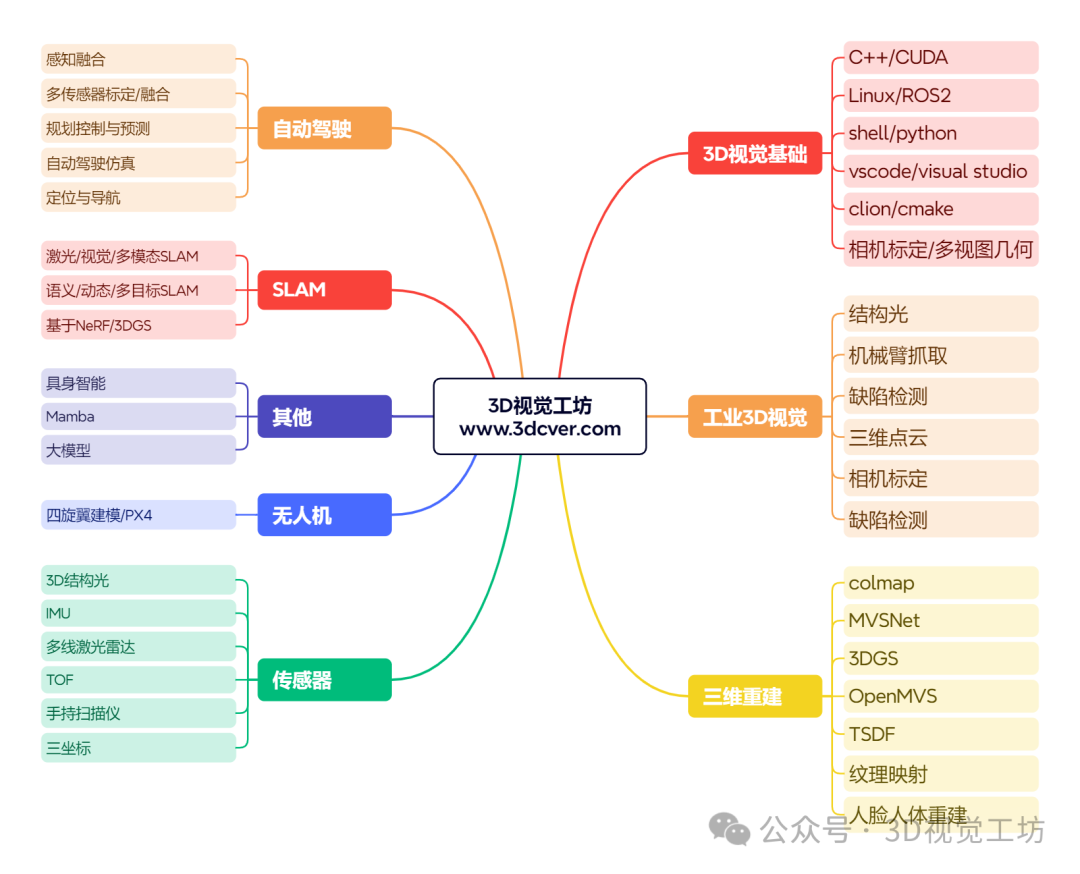
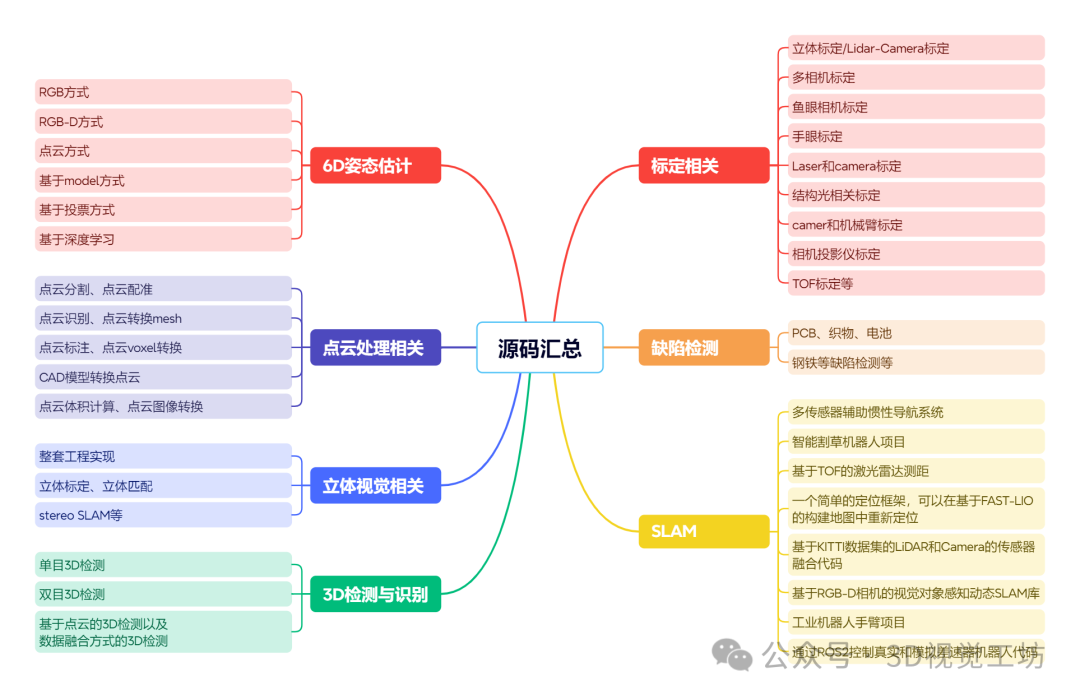
六 3D视觉源码汇总
七 高质量项目发布与对接



八专业的智囊团为星球成员答疑解惑
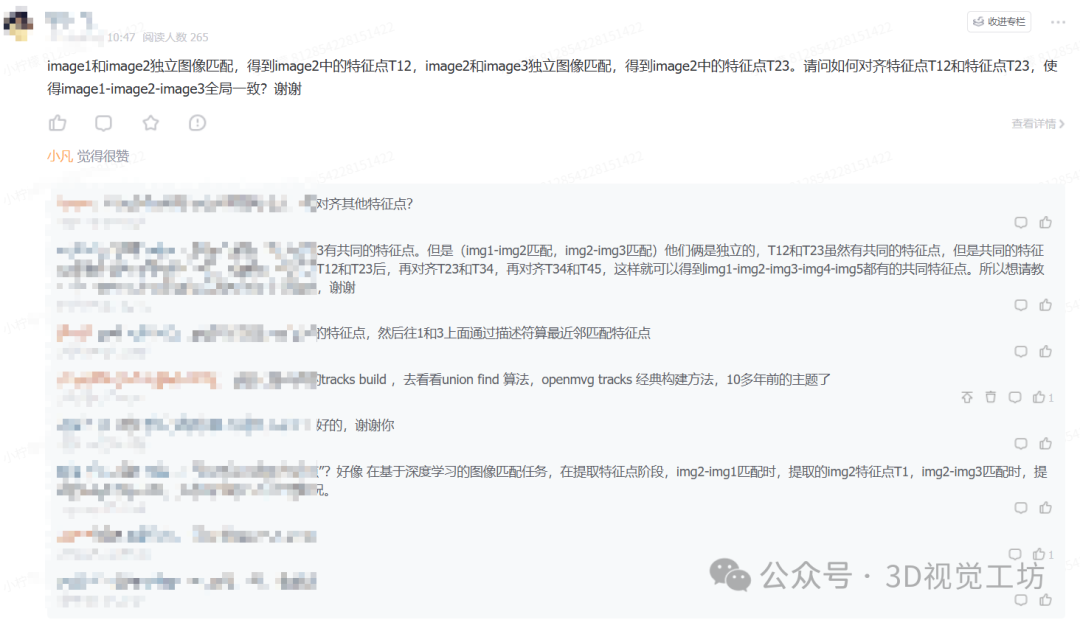
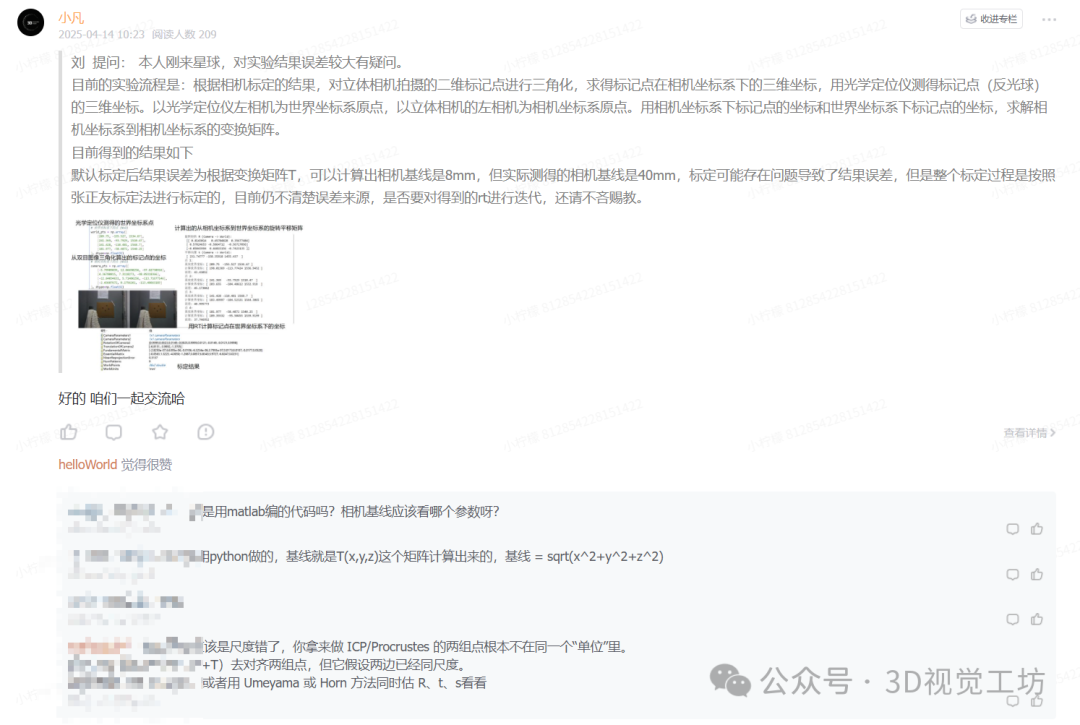
九 最新前沿顶会分享




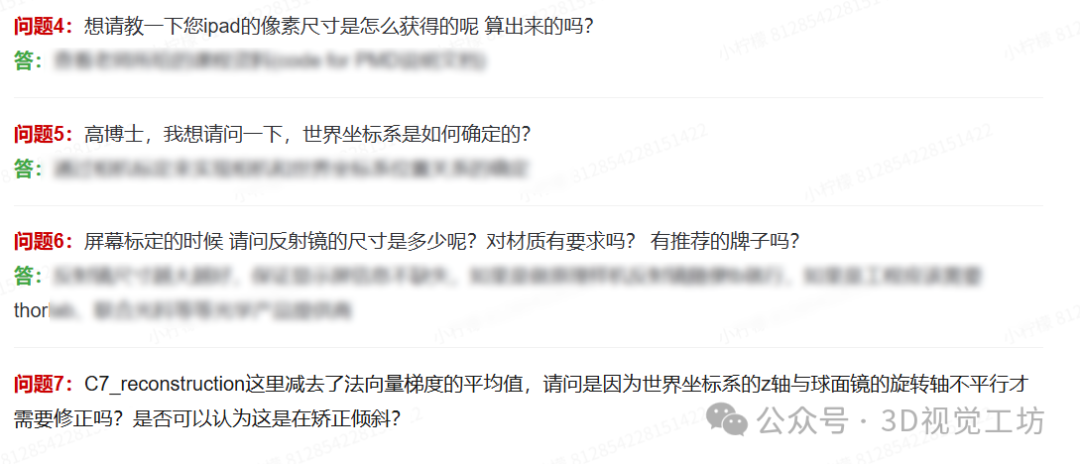
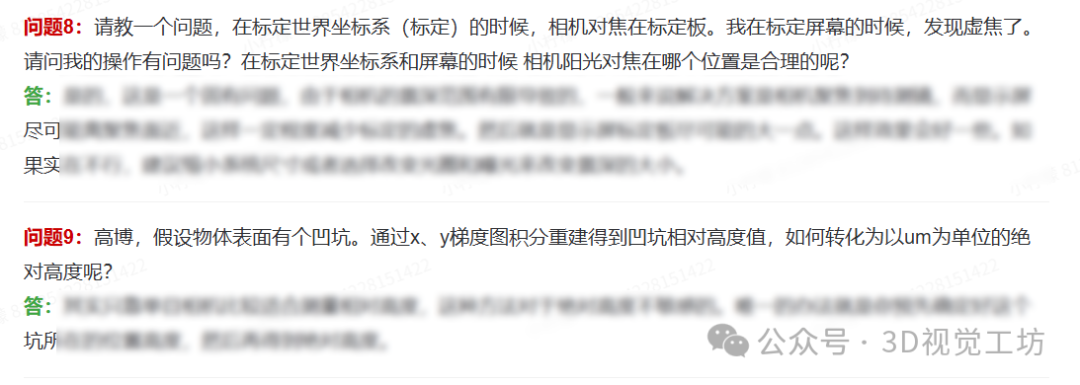
十 精华问题100问
 |
 |
 |
 |
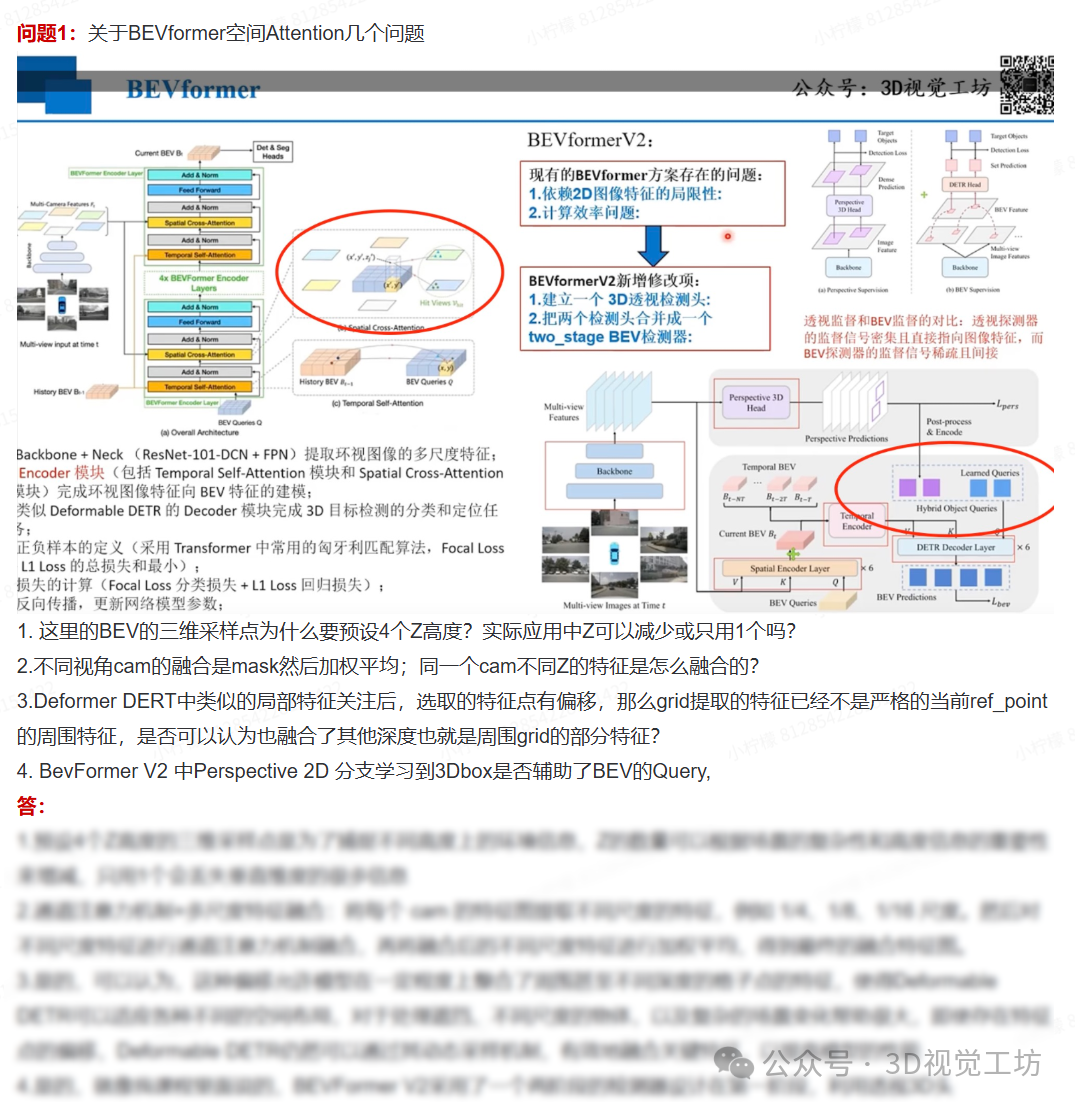 |
 |
| …… |
 |
 |
 |
 |
 |
 |
 |
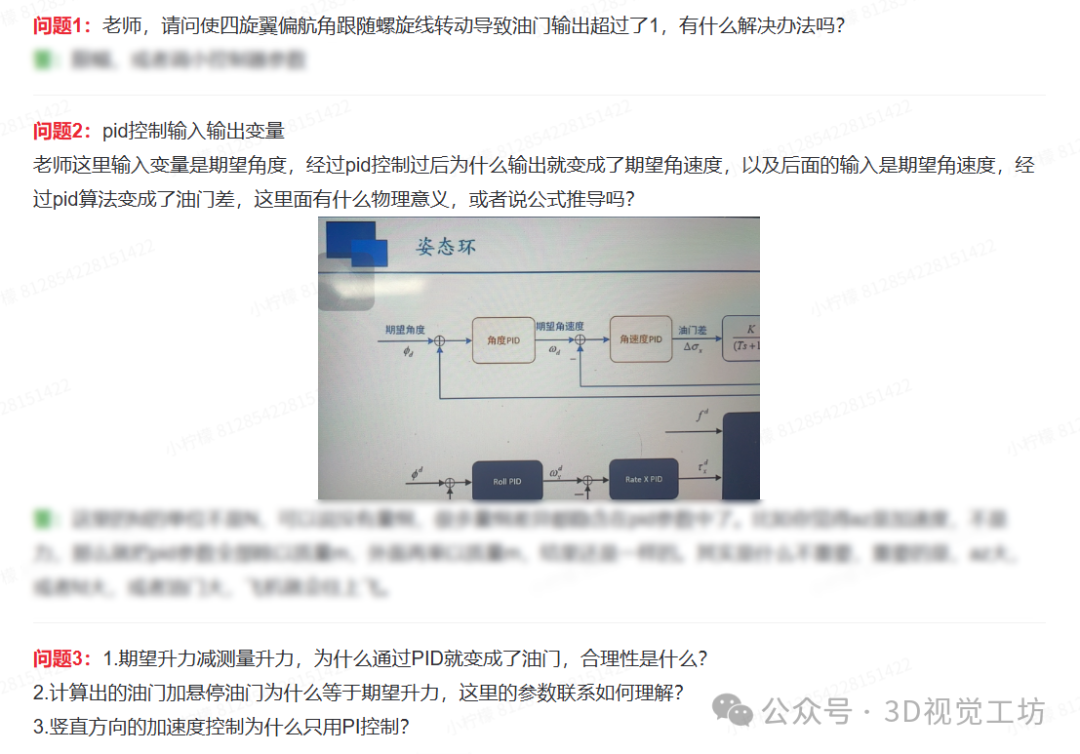 |
十一 3D视觉方向求职招聘
最后
目前已有6400多名3D视觉从业者正在星球里一起交流、分享、进步,我们也欢迎您一道同行!

