论文链接:https://arxiv.org/abs/2503.07152 项目主页:https://yuheng.ink/project-page/control-3d-scene/ 代码链接:https://github.com/yuhengliu02/control-3d-scene (coming soon)
主要贡献
首次实现了基于场景图输入的大规模三维室外场景生成; 提出了结合空间分配模块的图神经网络,将稀疏的场景图映射为紧凑的场景嵌入,并作为条件驱动三维扩散模型进行生成; 构建了一个配对的大规模数据集,包括三维场景及其对应的场景图,用于模型训练; 设计并实现了一个用户友好的场景图构建系统,支持灵活创建个性化图结构,引导三维场景生成,满足多样化需求。
背景介绍
3D 场景生成因其构建真实、物理一致三维场景的潜力而受到广泛关注。这类模型为理解和模拟复杂的三维世界提供了一种有效方式。在众多三维场景生成方法中,概率生成模型近年来展现出巨大潜力。然而,这类模型的随机性也带来了控制精度不足的问题,因此一个可编辑、可控的生成过程显得尤为重要。
为了实现可控的场景生成,许多方法借鉴了近期在 2D 条件生成领域的进展,例如自然语言驱动的图像生成方法。这些方法激发了一些研究使用二维视角引导三维内容生成。然而,它们通常以单个物体为中心,难以扩展至结构复杂、尺度庞大的室外场景。也有方法尝试直接通过文本控制三维场景生成,但文本条件往往难以同时满足物理约束和空间细节控制,难以精确限定物体数量或位置等元素,生成结果常常偏离预期。
一种可能的解决方案是将已有的室内三维场景生成方法拓展至室外环境。但这种适配面临较大挑战:室内场景通常依赖多视角图像,合成封闭、具备纹理的表面,注重物体外观与相对位置;而室外场景多为开放空间,主要通过无纹理的激光点云采集,更关注大范围的空间布局与背景连贯性。
近年来,研究者开始尝试为三维室外场景设计专门的控制方式。例如,有些方法采用鸟瞰图或语义分割图作为控制信号,但这种像素级的交互方式在大规模场景中不够直观且操作成本较高。因此,选择一种合适的中介形式对于实现可控的三维场景生成非常关键。
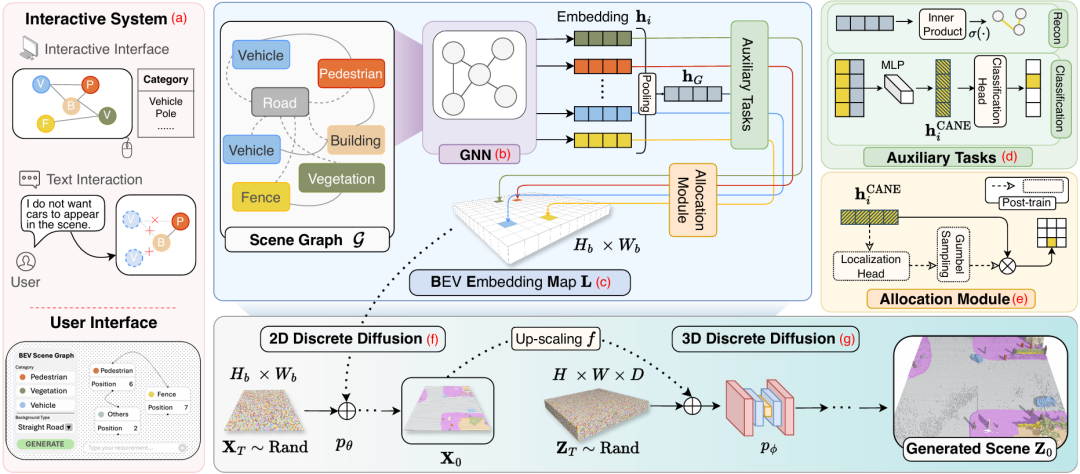
在这种背景下,场景图(Scene Graph)成为一种理想的选择。场景图具有结构化、规则化、稀疏的特点,特别适合表示室外三维场景的布局,同时具备良好的可交互性,用户可以方便地创建和编辑图结构。基于这一点,作者提出了一个新的三维场景生成框架,将场景图作为“稀疏到稠密”的控制信号。
然而,直接使用场景图作为生成条件并不容易,因为它本身抽象且稀疏。为了解决这一问题,作者首先引入图神经网络(GNN)来对场景图中的信息进行聚合。接着,设计了一个空间分配模块(Allocation Module),将节点映射到具体的空间位置,生成鸟瞰视角的嵌入图(Bird's Eye View Embedding Map, BEM)。最终,该嵌入图作为条件输入,引导三维金字塔离散扩散模型生成完整的三维场景。
为了实现端到端的训练,GNN 与扩散模型被联合优化。为了进一步增强 GNN 对场景图的理解能力,作者还引入了两个辅助任务:边重建和节点分类,有助于提升对场景结构的建模能力。
此外,作者开发了一个交互式系统,使用户可以通过图形界面手动编辑场景图,或通过自然语言生成图结构,从而实现从文本到三维场景的闭环控制。在数据方面,作者为 CarlaSC 数据集中的每个场景构建了配套的场景图CarlaSG,明确了节点属性,并根据空间关系建立了图中的边连接。
方法
场景图的结构定义
形式上,一个场景图可以表示为 ,其中包含节点集合 和边集合 。
节点集合 分为两类,即 :
实例节点():表示场景中的可数对象,例如车辆、行人等。这些对象拥有统一的语义标签。每个实例节点 都关联一个特征向量 ,其中 表示维度为 的语义属性特征, 表示该对象在俯视图(BEV)中的二维中心坐标。
道路节点():用于描述整个场景中的道路结构及其他全局背景信息,通常仅包含一个节点,即 。
在构建图结构时,作者定义了两类边以表达关键的关系:
物理接近关系:若两个实例节点 的欧氏距离 小于某个距离阈值 ,则在它们之间建立一条边 。
道路连接关系:若实例节点 与唯一的道路节点 相连,则建立一条边 ,表示该对象与道路结构存在连接。
在实际应用中,为了简化用户交互,作者将该场景图结构简化为控制信号:每个实例节点仅保留其语义标签 和近似二维位置 ,其中位置以 BEV 中的 patch 索引表示;而道路节点则简化为对应的道路类型。
基于场景图的扩散生成
给定一个二维场景图,作者的目标是生成一个在语义上与该结构一致的三维场景。整体流程分为三个阶段:首先,利用图神经网络(GNN)将场景图转化为一个密集的二维嵌入;接着,使用一个条件扩散模型合成符合场景图语义的二维场景图;最后,通过一个三维条件扩散模型生成最终的三维户外场景。
场景图神经网络
场景图神经网络的目标是为每个节点生成嵌入表示,该表示能够同时编码局部结构与全局语义上下文。作者采用了图注意力网络(Graph Attention Network, GAT)进行实现。
对于一个图 ,其邻接矩阵为 ,表示节点之间的连接关系。每个节点 的嵌入表示 通过两层 GAT 进行计算。为了引入全局上下文信息,作者将每个节点的嵌入与图级全局平均池化得到的全局嵌入 进行拼接,并通过 MLP 得到最终的上下文感知嵌入(Context-aware Node Embedding, CANE):
其中, 是图的平均池化操作,, 表示多层感知器。
GNN 的训练包含两个目标:辅助任务和下游任务。
辅助任务包括边重建与节点分类。具体损失函数为:
其中, 为二分类交叉熵损失,用于重建邻接矩阵 , 是节点分类交叉熵损失。重建项为:
其中 是 sigmoid 函数。该辅助任务确保模型同时学习节点的类别信息和图的结构关系,增强表示能力。
下游任务方面,作者将 用于构建 BEV 嵌入图(BEV Embedding Map, BEM),作为后续二维扩散模型的条件输入。
具体地,这一过程由一个位置分配模块完成:
其中, 表示输出的 BEV 嵌入图,高为 ,宽为 ,通道数为 。二值掩码 被扩展到通道维度以支持与节点嵌入 的逐元素相乘。
在推理过程中,位置 是从一个基于 MLP 的定位头中采样得到:
其中 是 Gumbel Softmax 的温度参数。在扩散模型训练阶段,作者使用真实位置 替换 进行训练;定位模块则在扩散模型训练完成后单独训练。
该位置分配模块将原本稀疏、结构化的图表示转化为密集的二维嵌入图(BEM),从而为后续的二维扩散模型提供结构对齐的条件输入。
二维离散扩散模块
在给定一个场景图的情况下,可能存在多种合理的二维布局与之对应。为了建模这种多样性,作者引入了一个扩散模型,用于将稀疏的场景图嵌入转化为密集的二维语义图表示。
具体而言,二维扩散模块将输入的稀疏 BEV 嵌入图 进一步细化,生成一个密集的二维语义图 ,其中 表示语义类别的数量。作者采用标准的离散扩散方法来完成这一任务。
在前向过程(forward process)中,原始二维图 在 个时间步内逐渐被扰动。每个时间步通过一个转移矩阵 添加噪声,使得:
也可以通过累积转移矩阵 直接从 采样出某一时间步的状态 :
其中 表示多项式分布(categorical distribution)。
在反向扩散阶段(reverse diffusion),模型 学习从当前时间步的状态 预测较少噪声的状态 ,并以 BEV 嵌入图 作为条件引导:
模型通过最小化前向过程与反向过程之间的 KL 散度来进行训练。对应的损失函数定义为:
其中, 是权重系数,用于平衡辅助重建项的贡献。
在推理阶段,扩散过程从随机噪声开始,并通过学习得到的反向扩散模型逐步去噪,最终生成一个结构合理的二维语义图 。该图作为后续三维场景生成的空间布局参考。
整个训练过程中的优化目标为辅助损失与扩散损失的组合:
三维场景离散扩散模块
三维场景的生成采用与二维扩散类似的离散扩散过程,将前一步生成的二维语义图进一步提升为稠密的三维场景表示。
输入的二维语义图为 ,其中 是语义类别数量,该图作为条件引导三维场景的生成。最终生成的三维场景表示为 ,其中 、 和 分别为三维体素网格的高、宽和深度维度。
三维扩散过程沿用了二维扩散中的前向与反向过程,但操作对象从二维网格扩展到了三维体素空间。具体来说,一个可学习模型 用于从当前时间步的三维状态 预测去噪后的状态 ,并以二维语义图 为条件进行引导:
其中, 是一个上采样函数,用于将二维图嵌入调整为与三维场景匹配的空间分辨率。
三维扩散模型的训练损失函数形式与二维扩散保持一致,定义为:
在推理阶段,模型从一个随机初始化的三维噪声状态出发,结合条件输入 ,通过逐步反向扩散生成最终的三维语义图 。每一步的反向采样操作如上式所示。
最终生成的三维场景在结构上严格对齐于前面的二维语义图,具备清晰且完整的空间细节布局。
交互式系统
作者设计了一个支持用户交互的控制系统(如视频所示),其核心是一个可视化界面,用户可以通过直观的操作方式来构建和编辑场景图。具体操作包括节点的添加、删除以及位置调整等,从而实现对三维场景生成过程的精细控制。
除了图形界面,用户还可以通过输入文本提示的方式来描述场景。系统会调用大语言模型(LLM)自动生成对应的场景图,并将该图作为输入,用于后续三维场景的生成。
实验
数据准备
由于现有的三维户外 LiDAR 场景数据集中缺乏配对的场景图信息,作者从 CarlaSC 数据集中每一个三维语义场景中自动构建对应的场景图,形成了一个新的数据集,命名为 CarlaSG。
基于前文中定义的场景图结构,作者从 CarlaSC 中的每个三维语义图中提取出对应的三维场景图,并将其投影至二维平面中。
值得注意的是,考虑到人行道、地面等区域在空间上与道路分布高度一致,作者将 CarlaSC 数据集中原始的 Ground(地面)和 Sidewalk(人行道)类别合并为 Road(道路)类统一处理。
在此基础上,道路被进一步细分为五类:直路、T 型路口、十字路口、弯道 和 其他类型。
评估方式
作者从两个角度对方法进行评估:一方面评估生成场景的整体质量,另一方面衡量生成场景与其对应场景图之间的一致性。
此外,还设计了一项用户研究,从感知角度评估生成场景与输入场景图在语义结构上的匹配程度。
所有实验均在测试集上进行,测试集包含随机选取的 1,000 个场景图。
场景质量评估
在场景质量方面,作者遵循已有工作的评估方式,采用 mIoU(mean Intersection over Union)和 MA(mean Accuracy)来衡量语义合理性。同时,使用 Fréchet 3D 距离(F3D)来衡量生成场景与真实场景在特征空间中的相似程度。F3D 是在预训练的 3D CNN 自动编码器的特征空间中计算 Fréchet 距离。
控制能力评估
为了评估生成场景在控制方面的表现,作者比较了生成场景中的物体数量与输入场景图中节点数量之间的差异。具体采用平均绝对误差(Mean Absolute Error, MAE)衡量数量偏差,并使用 Jaccard 指数衡量生成场景与场景图在物体类别上的重合程度。这两个指标共同反映了生成结果是否忠实于输入的结构信息。
用户研究
作者采用差分主观评分(Differential Mean Opinion Score, DMOS)对生成场景与输入场景图之间的匹配情况进行感知层面的主观评价。评价维度包括物体数量、位置排布以及道路类型等因素。
实验设置
训练与推理设置
在二维扩散模型与图神经网络(GNN)的联合训练过程中,作者采用了数据增强策略,并为扩散模型引入了 10% 的无条件数据,同时在 GNN 输入上施加了 30% 的特征遮蔽,以模拟部分用户未提供节点位置信息的实际情况。在推理阶段,分配模块中的 Gumbel Softmax 温度参数 被设定为 2.0,用于引入生成场景中的随机性。
网络架构
整个框架采用扩散模型与 GNN 的联合训练结构。二维与三维扩散模型均以 3D-UNet 为主干网络,该架构常用于户外场景理解任务。图神经网络部分采用了两层的图注意力网络(GAT)作为编码器。
对比方法
将室内场景生成方法直接应用于户外场景存在较大挑战,主要由于场景本质差异较大,且此类改造会显著偏离原始方法的核心流程,导致直接比较缺乏可比性。因此,作者选择了以下三个对比基线:
大语言模型(LLM)方法:该方法从场景图的文本描述中提取嵌入向量,然后通过二维反卷积网络对接扩散模型。实现细节见附录材料。 Scene Graph to Image(SG2Im)方法:一种基于生成对抗网络(GAN)的图到图像生成方法。作者对其进行适配,使其能够从场景图生成 BEV 嵌入图(BEM)。 无条件生成模型(Uncon-Gen):该方法不使用任何场景图作为引导,直接进行三维场景生成,来自于已有工作的设置。
核心实验结果
定性结果

图4 展示了在相同的三个场景图输入下,作者的方法与多个基线方法(如 LLM 和 SG2Im)生成的三维户外场景结果。
从结果可以看出,作者的方法能够准确还原场景图中指定的物体数量及道路类型信息。而相比之下,LLM 与 SG2Im 方法在大多数类别上生成的物体数量存在明显偏差,生成的道路类型也与目标结构差异较大。
定量结果

表1 给出了作者方法与各基线方法的定量对比结果。在场景质量方面,Uncon-Gen、LLM 以及作者的方法表现相近,而 SG2Im 的整体表现较弱。
在控制能力方面,作者的方法在所有指标上均优于其他方法,特别是在物体数量控制上表现出色,其 MAE 值控制在 1.0 以下,反映出极高的精度。相比之下,SG2Im 的 MAE 为 0.97,LLM 的 MAE 更高达 1.44,几乎是 0.63 的两倍,显示出显著的准确性差距。
此外,在 Jaccard 指数上,作者的方法也取得了更高的得分,表明其在多样场景中对物体类别的把握更加精确,能够更好地从场景图中提取语义信息。
生成多样性

为了验证模型是否具备生成多样性的能力,而非仅仅是记忆特定场景,作者在同一场景图输入下重复生成三次结果,如图5 所示。
实验结果表明,即使输入完全相同,生成的三维场景在细节与布局上依然具有明显差异,但都能保持与原始场景图在结构和语义类别上的一致性。这说明该方法在引入随机性的同时,仍能保持对输入场景图的精确对齐。
结论
本文提出了一种融合交互系统、BEV 嵌入图与扩散生成的方法,实现了可控的三维户外场景生成。该任务的核心挑战在于户外场景的复杂性,其包含丰富的信息以及多样的结构分布。 作者的方法通过引入场景图,实现了从稀疏到稠密信息的有效转化。在此基础上,结合交互式控制系统,使用户能够以直观、简洁的方式构建并生成所需的三维户外场景。 对比实验结果显示,本方法在物体数量控制和场景图对齐方面均优于现有方法,能够更加精准地还原输入结构。这些结果表明,该方法在可控三维场景生成任务中具有稳健且有效的表现。










