
> 本文由 Intern-S1 等 AI 生成,机智流编辑部校对
在当今人工智能领域,“越大越好”似乎已成为默认共识:千亿参数、万亿token训练、超大规模推理……然而,一篇来自三星SAIL蒙特利尔实验室实验室(Samsung AI Lab Montreal)的最新论文却给出了截然不同的答案:用一个仅700万参数的极小网络,通过巧妙的递归机制,就能在多个硬核推理任务上全面超越当前主流的大语言模型(LLMs)。
这项名为《Less is More: Recursive Reasoning with Tiny Networks》的工作提出了一个名为Tiny Recursive Model(TRM,微型递归模型)的新架构。它不仅在Sudoku、Maze、ARC-AGI等需要强逻辑推理能力的任务上大幅领先于包括Gemini 2.5 Pro、Deepseek R1在内的大模型,还以不到0.01%的参数量实现了这一壮举。
更令人惊讶的是,TRM的设计哲学恰恰是“简化”——它摒弃了复杂的生物类比、固定点定理、双网络结构,甚至不需要Chain-of-Thought(CoT)或Test-Time Compute(TTC)等大模型常用的推理增强技术。那么,TRM究竟是如何做到的?
论文链接:https://huggingface.co/papers/2510.04871
PaperScope论文解读:https://www.paperscope.ai/hf/2510.04871
从HRM到TRM:递归推理的“去繁就简”
故事的起点是今年6月由Wang等人提出的Hierarchical Reasoning Model[1](HRM,分层推理模型)。HRM通过两个小型Transformer网络(分别以高频和低频递归)配合“深度监督”(deep supervision)机制,在Sudoku、Maze等任务上取得了远超传统监督学习模型的表现。HRM的灵感部分来自神经科学——认为大脑在不同时间尺度上处理信息,因此模型也应具备“高低频”双通路。
然而,三星团队在深入分析后发现:HRM的性能提升主要来自“深度监督”,而非其复杂的双频递归结构。独立评测显示,仅靠深度监督就能将ARC-AGI准确率从19%提升至39%,而递归机制本身贡献微乎其微。更关键的是,HRM依赖的“隐函数定理”(Implicit Function Theorem)和“单步梯度近似”在实际训练中并不成立——因为模型并未真正收敛到固定点。
于是,作者Alexia Jolicoeur-Martineau提出了一个大胆的简化方案:去掉所有不必要的复杂性,只保留最核心的递归推理机制。
TRM的核心思想:递归改进答案,而非生成答案
TRM的架构极其简洁:仅用一个两层的小网络,递归地改进当前的预测答案。如图1所示,TRM从输入问题 和初始猜测答案 出发,维护一个隐状态 (相当于“推理链”)。在每一步中,它先用 更新 (递归推理),再用更新后的 和当前 生成新的 (答案修正)。这个过程可重复多达16次(称为“监督步”),逐步逼近正确答案。

图 1. Tiny Recursive Model。TRM通过一个极小的网络递归改进预测答案 。它从嵌入的输入 和初始答案 开始,结合隐状态 ,在最多16步内不断优化答案。这种设计以极低的参数量实现了强大的推理能力,同时有效避免过拟合。
与HRM不同,TRM不假设固定点存在,而是直接对整个递归过程进行端到端反向传播。它也不需要两个网络——同一个网络既负责更新隐状态 ,也负责生成新答案 。作者发现,这种“一网打尽”的设计反而提升了泛化能力。
更重要的是,TRM对“隐状态”的理解更为直观:就是当前的答案(可直接解码为输出),而是辅助推理的中间表示(类似人类的“草稿纸”)。这种解释无需生物学类比,逻辑清晰且易于验证(见图2)。
 图 2. 一个数独难题示例。该示例展示了预训练模型的输入、预期输出以及经过嵌入反转和使用 argmax 处理后的 token 化 z_H 和 z_L。这凸显了一个事实,即 z_H 对应于预测的响应(y),而 z_L 是一种潜在特征,除非通过 f_H 转换为 z_H,否则无法解码为合理的输出。
图 2. 一个数独难题示例。该示例展示了预训练模型的输入、预期输出以及经过嵌入反转和使用 argmax 处理后的 token 化 z_H 和 z_L。这凸显了一个事实,即 z_H 对应于预测的响应(y),而 z_L 是一种潜在特征,除非通过 f_H 转换为 z_H,否则无法解码为合理的输出。
极简设计,极致性能
TRM的“极简主义”体现在多个层面:
参数量仅700万:相比HRM的2700万,TRM减少近75%;相比千亿级LLM,更是微不足道。 仅两层网络:作者尝试增加层数,却发现性能反而下降——在小数据场景下,小模型+深度递归比大模型更能避免过拟合。 无需自注意力(在部分任务上):对于Sudoku这类固定小尺寸输入(9×9),TRM用MLP替代自注意力,性能提升10%以上。 训练更高效:TRM的ACT(自适应计算时间)机制只需一次前向传播,而HRM需要两次。
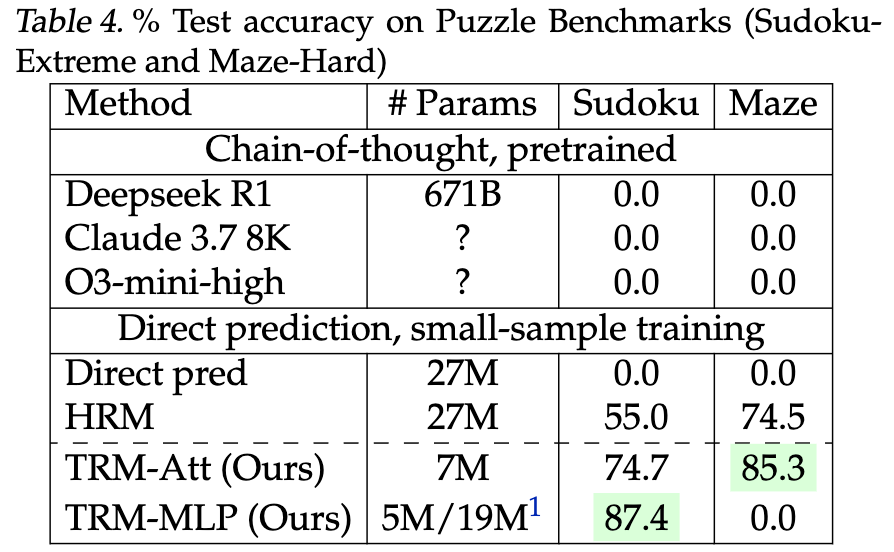
这些设计选择并非随意,而是经过大量消融实验验证。例如,表1显示,当TRM采用两层MLP、EMA权重平均、单网络结构等配置时,在Sudoku-Extreme上的准确率高达87.4% ,远超HRM的55%。
 表 1. 在 Sudoku-Extreme 上对 TRM 的消融实验结果。对比测试准确率、每个监督步骤的有效深度、每个优化步骤的前向传播次数(NFP)以及参数数量
表 1. 在 Sudoku-Extreme 上对 TRM 的消融实验结果。对比测试准确率、每个监督步骤的有效深度、每个优化步骤的前向传播次数(NFP)以及参数数量

图2. Tiny Recursion Models 伪代码。TRM的伪代码展示了其简洁的训练流程:通过深度监督递归更新隐状态 和答案 ,并在每一步计算损失。整个过程仅需一个小型网络和单次前向传播,极大提升了训练效率与稳定性。
全面超越:TRM在四大硬核任务上的表现
论文在四个极具挑战性的推理基准上测试了TRM:
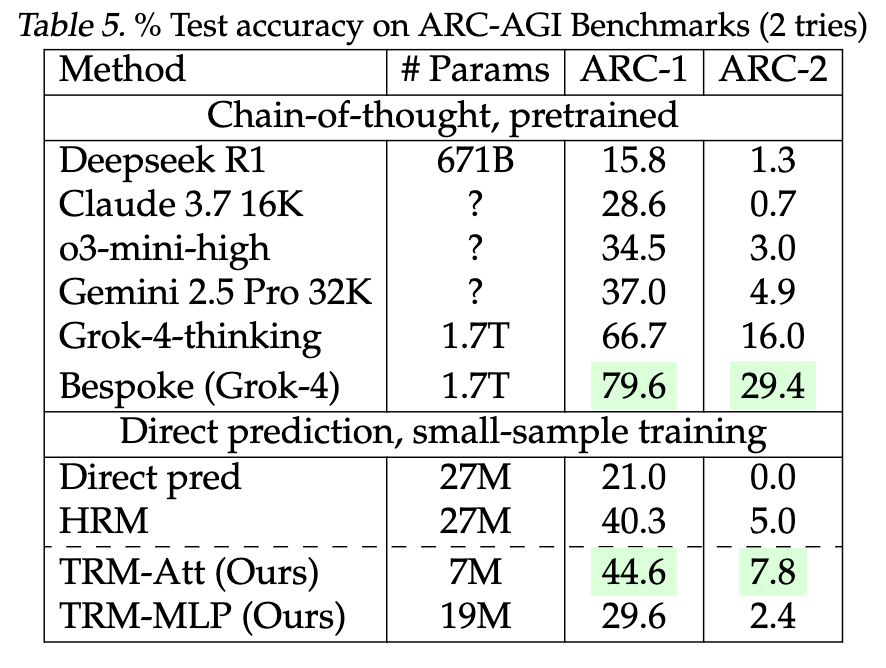
Sudoku-Extreme:仅1000个训练样本,测试集达42万。TRM(MLP版)准确率87.4% ,HRM为55%。 Maze-Hard:30×30迷宫,最短路径超110步。TRM(带自注意力)达85.3% ,HRM为74.5%。 ARC-AGI-1:人类易解、AI难解的视觉推理任务。TRM准确率44.6% ,超越Gemini 2.5 Pro(37.0%)和多数LLM。 ARC-AGI-2(2025新基准):难度更高。TRM达7.8% ,而Gemini 2.5 Pro仅4.9%。
尤其值得注意的是,TRM在ARC-AGI上的表现已接近某些专为该任务定制的模型(如Bespoke Grok-4达29.4%),但参数量仅为后者的几千分之一。
为什么“小”反而更好?
TRM的成功挑战了“模型越大越好”的直觉。作者认为,在数据极度稀缺的场景下(如Sudoku仅1K样本)。大模型容易记住训练样本而非学习泛化规则,而TRM通过“深度递归+小容量”强制模型学习可迁移的推理过程。
此外,递归机制本身提供了一种“时间展开”的深度——TRM的有效深度可达42层以上,但参数并未增加。这种“计算换参数”的策略,在小数据时代或许更具性价比。
未来方向:从确定性推理走向生成式推理
目前TRM仍是一个确定性监督模型——给定输入,输出唯一答案。但在许多现实场景中(如数学证明、程序生成),一个问题可能有多个合理解。作者指出,未来可将TRM扩展为生成式模型,支持多答案采样与概率推理。
此外,TRM的架构是否适用于更广泛的NLP或视觉任务?其“递归改进”思想能否与强化学习、规划算法结合?这些问题都值得进一步探索。
结语:少即是多,简即是强
在AI界狂奔向更大、更贵、更复杂的今天,TRM像一股清流,提醒我们:有时候,解决问题的关键不在于堆砌资源,而在于设计更聪明的机制。
正如论文标题所言:“Less is More”。一个仅700万参数的小模型,凭借极简而深刻的递归推理架构,竟能在硬核推理任务上击败千亿大模型——这不仅是技术上的突破,更是对当前AI发展范式的一次有力反思。
或许,真正的智能,不在于规模,而在于如何用有限的资源,实现无限的推理可能。
论文链接:https://huggingface.co/papers/2510.04871
PaperScope论文解读:https://www.paperscope.ai/hf/2510.04871
ARC-AGI Leaderboard:https://arcprize.org/leaderboard
HRM性能分析:https://arcprize.org/blog/hrm-analysis
Hierarchical Reasoning Model: https://arxiv.org/abs/2506.21734










