
新智元报道
新智元报道
【新智元导读】曼巴回来了!Transformer框架最有力挑战者之一Mamba的最新进化版本Mamba-3来了,已进入ICLR 2026盲审环节,超长文本处理和低延时是其相对Transformer的显著优势。另一个挑战者是FBAM,从不同的角度探索Transformer的下一代框架。
算法巨蟒「Mamba」悄然蜕变至第三代!
备受瞩目的Transformer最有力继任者之一:Mamba,它的最新进化版本Mamba-3已进入ICLR 2026盲审阶段。

Mamba-3论文链接:https://openreview.net/pdf?id=HwCvaJOiCj
几年前,Transformer雄踞序列建模领域之巅,但一群研究者另辟蹊径,开始尝试从经典的状态空间模型(SSM)中汲取灵感,打造更高效的序列网络架构。
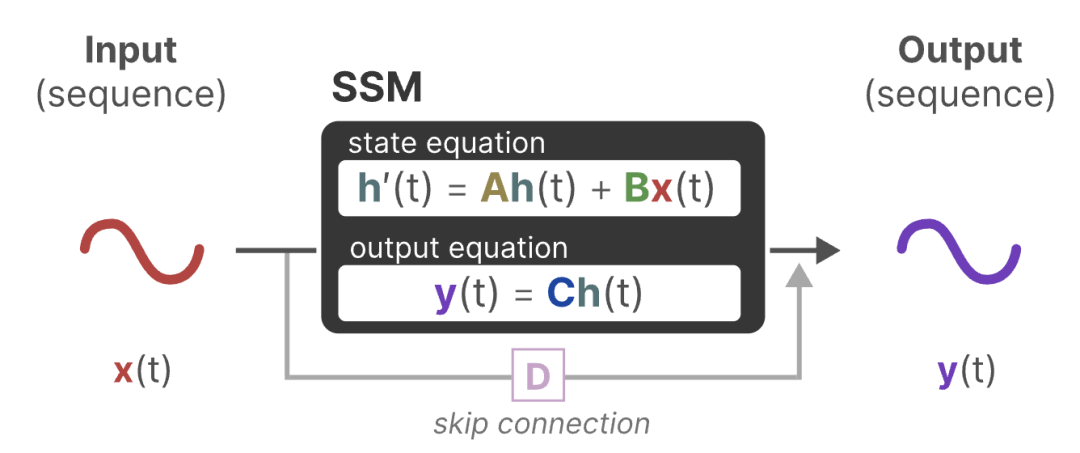
SSM示意图
这就是Mamba系列的由来。
从初代Mamba-1到如今亮相的Mamba-3,这条AI巨蟒一路蜿蜒前行,不断进化出新「技能」,试图在长序列记忆和推理效率上,向Transformer发起挑战。

故事要从Transformer的痛点说起。
Transformer擅长「一览众山小」——它能对输入序列中的任意两点建立直接联系,捕捉复杂的全局模式。
然而这种注意力机制的代价不菲:推理时每产生一个新词,都要重新计算与过去所有词的关系,计算量随序列长度呈平方级增长。
假设你在写文章,每写一个字就翻阅整个前文来决定下一个字,写得越长,速度越慢。
这样的机制在长文本生成或实时应用中变得举步维艰。
研究者们不禁回想起更老的办法:循环神经网络(RNN)。

RNN每次生成下一个输出,只需参考上一步的隐藏状态和当前输入。
就像写文章时,你不必每天都重读整篇文章,而只需看上一段写了什么,就能接着写今天的内容。
因此,RNN具有线性时间的推理速度和潜在的无限记忆长度。
但现实中RNN也有硬伤:它的「日记」往往越写越模糊,隔了许多天就记不清旧事了。
换言之,传统RNN随着时间推移容易遗忘早先的信息。
这种遗忘使得RNN在长距离依赖和复杂推理上表现不佳。
Mamba-1的问世,正是为了解决这一系列矛盾。

Mamba-1论文链接:https://arxiv.org/abs/2312.00752
Mamba-1借鉴连续状态空间模型的理论,结合RNN的循环结构与一种特殊的线性动态系统,力图兼顾长程记忆与高效推理。
在每个时间步,它通过状态向量来累积信息,并引入了「选择性」机制:根据当前输入来调节遗忘和保留,就像写文章时遇到重要细节会特别标注,避免后续遗失。
在处理离散文本时,这种输入依赖的门控让模型更加游刃有余,不再像传统SSM那样「一股脑儿记流水账」,而是能够有选择地遗忘或强化某些信息。
得益于这一点,Mamba-1在语言等离散模态上表现大有改观。
然而,Mamba-1也留下了一些遗憾。
为了实现输入依赖的状态更新,它放弃了原本SSM可用的高效卷积计算,转而逐步按序列长度展开计算。
这意味着虽然理论上推理复杂度是线性的,但如何充分利用硬件并行成了新的挑战。
初代Mamba在小规模模型上已经展现出与Transformer比肩的潜力,甚至在某些长序列任务上实现了超越,但面对更大规模模型和更苛刻的实时推理需求时,仍有提升空间。

时间来到2024年5月,第二代Mamba-2登场。

Mamba-2论文链接:https://arxiv.org/abs/2405.21060
研究团队深入剖析了Mamba与Transformer的内在联系,提出了一个有趣的观点:Transformer和SSM其实是一对近亲。
他们发现,通过一种称为「结构化状态空间对偶」(SSD)的理论框架,可以将Mamba的循环更新用矩阵运算表示为带特殊掩码的乘法,与一种简化的注意力机制形式等价。

结构化状态空间对偶:通过结构化矩阵的桥梁,状态空间模型(SSMs)和注意力机制可以被证明在数学上是等价的。它们本质上是同一类计算的不同表现形式
这个理论对偶赋予了Mamba-2全新的优化策略。
凭借SSD框架,Mamba-2对核心循环层进行了重新设计和实现,使其在GPU上的运行效率大大提高。
Mamba-2相比前代模型推理速度提升了2~8倍。
Mamba-2不再让GPU闲着等待逐步计算,而是更好地发挥并行能力。
他们巧妙地利用张量核心进行并行计算,相当于把原本单线程执行的文章写作拆分成多人同时书写但结果不乱的过程。
结果是,Mamba-2在保持与Transformer相当建模效果的同时,实现了前所未有的高推理吞吐,真正把线性时间的优势发挥了出来。
当然,Mamba-2并非尽善尽美。
一方面,它的架构本质上仍然遵循Mamba-1的思路,隐藏状态只有一种更新模式,建模能力上可能还欠缺「变化的花样」。
另一方面,即使有了对偶加速,模型在某些需要复杂记忆变换的任务上仍有局限。
例如,当遇到需要周期性状态跟踪或精确计数的场景,Mamba-2可能依旧力不从心,因为它的内部状态演化仍是相对单一的衰减形式,缺乏「钟摆」般来回振荡的机制来捕捉循环规律。
研究者们意识到,要让Mamba系列真正百尺竿头更进一步,既要更聪明地记忆,也要更充分地利用硬件。带着这些经验和反思,Mamba-3孕育而生。

到了第三代,Mamba带来了三项关键改进,分别对应更高的模型精度、更强的记忆能力和更优的效率。

左图为Mamba-2架构图,右图为Mamba-3架构图
这些改进源自经典状态空间理论的智慧,却又服务于现代AI的实际需求。
我们依次揭开这「三板斧」的神秘面纱。

Mamba-3采用了一种更高阶的积分近似方法:广义梯形法则,来计算连续状态演化到离散时间的更新。
简单来说,之前Mamba的状态更新相当于用欧拉法粗略近似:在每个时间步,仅根据区间末端的信息更新状态(就像你只根据一天结束时的感受来写日记)。
这种做法速度快,但难免有偏差,会逐步累积误差。
而梯形法则则更进一步,它综合考虑了时间区间的起点和终点,相当于在早晚各记一笔,再取平均。

左图为欧拉法(保持端点),右图为梯形法则(端点取平均)
这使得每一步的状态更新更加准确,不会因为一次粗略的近似导致长期记忆走样。
实验表明,这种二阶精度的更新法减少了状态演化的截断误差,提高了模型对长序列的处理质量。

如果说梯形离散化让Mamba-3记忆细节时少丢分,那么复数隐状态则赋予了它全新的记忆方式。
传统的SSM为了保证稳定性,一般只用真实数的负值作为状态演化的特征——
这意味着隐藏状态要么逐渐衰减,要么单调增长,但缺乏来回震荡的可能。
这就像一个只会渐渐停下来的秋千,无法自我维持摆动。
而在Mamba-3中,研究者大胆地打开了复数的大门,让状态向量可以在复平面上演化。
这带来了什么好处呢?
复数状态实际上等效于引入二维旋转动态——就像在隐藏状态里加装了一对小钟摆。
钟摆可以一边缓慢衰减,一边周期性振荡,这正是许多复杂序列模式所需要的记忆行为。
例如,追踪句子中的奇偶校验、循环节奏,或者「每隔几个词重复一次」这种规律,纯实数模型常常难以优雅地学习;但有了复数状态,这些问题就迎刃而解。
换个角度类比,Transformer擅长直接「翻书找线索」,Mamba-3则更像脑中有一只耐心摇摆的节拍器或时钟,可以暗自计时、循环,帮助它记住信息的顺序和周期。
事实证明,经过「复数化」,在一些状态追踪类任务(比如模仿算法的计算、处理周期模式)上,Mamba-3获得了以前的模型不曾具备的能力。


Mamba-3的第三项改进,面向的是推理阶段的硬件效率。
在生成长序列时,Mamba系列理论计算量低于Transformer,但此前模型每步只处理单一输入和单一输出(称为SISO,Single-Input Single-Output),导致计算单元常有闲置。
为此,Mamba-3引入了MIMO(Multi-Input Multi-Output)的广义结构,可在每个时间步并行处理多路输入信号并产生多路输出。
举个通俗的例子:想象高速公路上原本只有一条车道,每次只能过一辆车,现在拓宽为多条车道,多个车辆并行通过。
对于Mamba的隐藏状态更新,也是类似的思路:以前每步只能「一个管道传输一份信息」,现在通过矩阵运算实现「一次传输多份信息」。
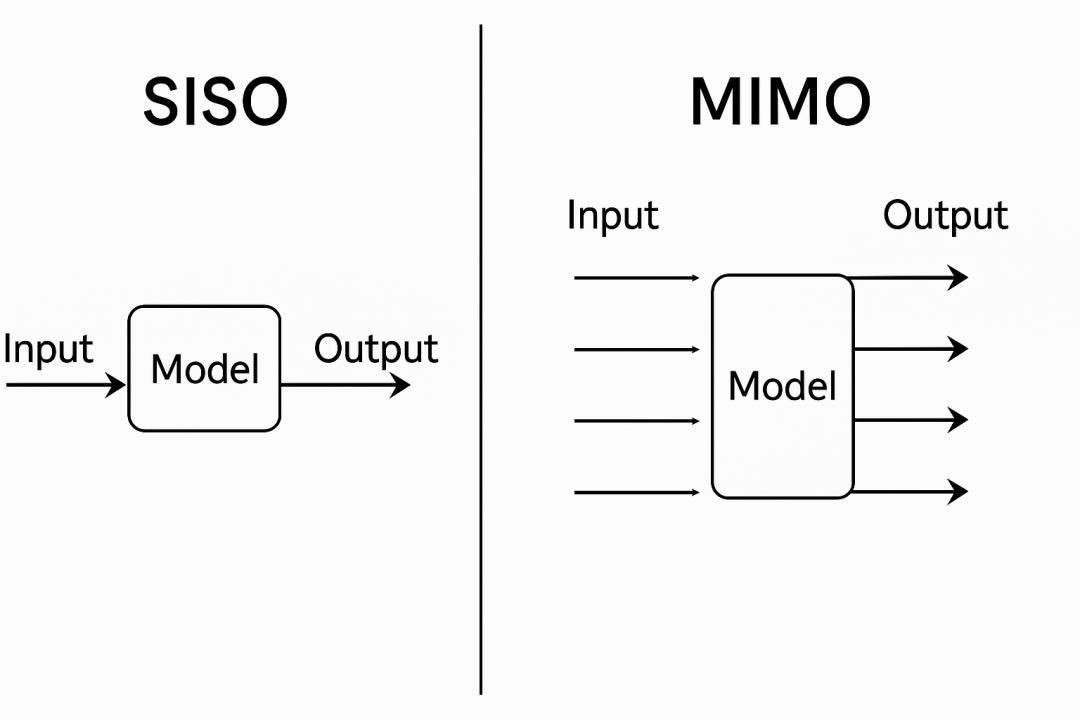
SISO与MIMO对比示意图
这样一来,计算资源利用率大大提高。
在实际硬件上,这种改变显著提高了算术强度(即每次数据访问所进行的计算量),使得GPU等加速器能够满负荷运行,不再受限于内存带宽瓶颈。
MIMO设计让Mamba-3能更好地跑满硬件。
引入多输入多输出后,Mamba-3的循环公式本质上从向量外积变为矩阵乘积,这一改变不仅带来效率提升,也是对经典控制论中多通道状态空间模型的延续。
研究者表示,在不增加明显开销的情况下,这一改变为模型提供了灵活开关,今后甚至可以按需选择打开MIMO模式来平衡速度与性能。
经过这三大升级,Mamba-3的整体架构依然保持了前代的简洁模块化设计,但在细节上更加洗练。
原本为提升稳定性而在Mamba-2中加入的额外归一化层也被重新安置,以更契合现代Transformer的范式;
过去线性模型里常用的短卷积辅助在Mamba-3中也因梯形更新和复数增强的加入而不再需要。
种种改动,使Mamba-3真正蜕变成一条灵活敏捷又力量倍增的「巨蟒」。

Mamba-3的出现,无疑为序列建模开拓了新的可能性。
它更可能将在长文本处理与内容生成、实时推理与交互式AI、推理阶段成本优化这三大方向中大放光彩。

对于需要处理超长序列的任务,Mamba-3如鱼得水。
无论是长篇文章生成、长对话上下文理解,还是分析日志、DNA序列这类海量数据,Mamba-3都不受窗口长度桎梏,能够持续地记忆和生成。

注:NIAH(needle-in-a-haystack,大海捞针)是一个超长上下文信息检索测试
而且在保持生成质量的同时,它对长序列的计算开销增长缓慢,更适合此类应用。
正如实验所示,在相同模型规模下Mamba-3在语言建模上的表现全面优于前代模型,这意味着它有潜力在长文本任务中提供比肩甚至超越Transformer的效果,却不需要为了扩大量程而付出指数级计算代价。

在需要快速响应的AI应用中(例如实时对话助手、线上翻译、语音交互等),推理速度和延迟至关重要。
Mamba-3天生适合这类场景,因为它每步计算固定且高效。

不同模型、精度和dstate参数下的延迟(单位:ms)比较
比如一款部署在手机上的实时翻译器,需要在用户说话时连续输出翻译文本。
使用Mamba-3引擎,设备无需担心随着对话变长计算量爆炸,可以始终以恒定速度输出,不拖慢用户体验。
同时,由于Mamba-3对硬件要求相对低,移动设备或物联网终端也有望承载一定规模的模型,在本地以低延迟运行AI推理。
这为边缘计算和隐私保护带来好处:数据不必上传云端也能实时处理。

对于云端的大模型服务提供商来说,推理阶段的算力和内存成本是沉重开销。
Mamba-3提供了一种降低成本的新路径。在相同推理预算下,使用Mamba-3架构可以支撑更大的模型或更长的序列生成。
其在固定计算预算下的性能-效率折中曲线优于现有模型,意味着在保证输出质量的前提下,每秒能生成的Token数更多。

状态规模与预训练困惑度
这对于需要大规模生成内容的应用(如对话机器人批量回复、内容创作工具等)将直接转化为吞吐提升和成本节省。
当然,Mamba-3也并非万能。
训练方面,Transformer成熟的训练技巧和广泛的社区支持仍是优势,而Mamba-3这种新架构可能需要更多探索来充分发挥其威力。
在某些精细推理任务上,Transformer的直接注意力可能依旧更胜一筹。
另外值得一提的是,此前两代Mamba的一作都是华人。
Albert Gu是CMU助理教授,兼任Cartesia AI的首席科学家,目前论文被引超17000次。

Tri Dao则是越南裔,本科和博士均毕业于斯坦福大学,是普林斯顿大学助理教授,兼任Together.AI的首席科学家,目前论文被引破2万次。

但对Transformer发起有力挑战的,绝非仅有Mamba。接下来我们将简单介绍另一位挑战者:FBAM。

对长上下文任务来说,当序列长度远大于模型层数时,模型在极少步骤里需要聚合越来越多的信息。
如果把AI智能体看作是在理解「环境观察」的问题,那随着「不可见状态」的增长(也就是观察不到,需要推理出来的信息),模型要解决的就变成了「状态追踪问题」。
这类问题Transformer难以胜任,所以Mamba等状态空间模型(State-space models)应运而生。
但类似问题依旧存在:当序列超过某个临界长度N之后,如果不增加层数,它们也会失败。
本质原因在于「可判定性」:当任务需要串行完成N个子决策时,如果层数不够,模型就处理不了。
这就是引入FBAM(Frame-based Action Models,基于帧的行动模型)的动机。
过去数月,AI初创公司Prime Intellect的研究工程师Michael Keiblinger苦心钻研,成果最终问世。

论文链接:https://arxiv.org/abs/2510.06828
他认为,长程感知需要重新审视循环结构。
FBAM不同于传统语言模型,它不是简单地串联式自回归。
虽然依旧是自回归模型,但它的输入输出关系更复杂,不是「生成一个Token就拼到输入序列里」。
FBAM是预测一个操作(action),由这个操作驱动「环境」生成下一个「帧」(frame)。
FBAM分解为两个主件:
「帧头」(Frame Head):负责满足整合器从当前帧内容中获取信息的需求,有效地「嵌入」该帧;
「主序列模型」/「整合器」(Main sequence model/Integrator):负责聚合帧嵌入,并在相应时间步输出下一个动作。

帧头部分仍采用Transformer骨干网络。

从技术上讲,FBAM完全可以仅依靠帧局部上下文(frame-local context)运行,只要周边文本可见且无需历史记录。
随着序列长度不断增长,研究者观察到即使参数数量保持不变,模型的损失水平也持续降低,损失随序列长度呈经典幂律分布。

不同序列长度下,模型的损失随训练步数的变化
从实际耗时来看,最终长时间运行的模型会赶上较短序列长度的模型。在这种情况下,除了实用性考虑之外,刻意训练一个较短序列长度的模型没有任何意义。


Mamba-3已经展示了状态空间模型在新时代的生命力:原来序列建模并非只能一条路走到黑。
在追求更长上下文、更快推理的道路上,这条机敏的「Mamba」巨蟒正昂首前行。
当我们回顾Mamba的进化历程,不难发现每一代的革新都凝结着研究者对记忆与计算的深刻思考。
从Mamba-1的雏形初现,到Mamba-2的加速攀升,再到Mamba-3的全面跃迁,这项技术就像一段连续的乐章,一步步逼近效率与能力的完美和声。










