在人工智能的不断进化中,我们始终在探索机器学习与适应的边界。尽管强化学习已经取得了显著成果,但在许多环境中,缺乏可靠的奖励信号仍然是其面临的一大挑战。如果智能体能够通过自己的行为和结果进行学习,而不依赖于事先设定的奖励,是否能开辟新的可能性?
处在风口浪尖的Meta,最近的一项研究提出了‘早期经验’这一创新方法,智能体通过从自身的动作和结果中获取经验,即使在没有明确奖励的情况下,也能不断进步。 这一方法成功地弥合了模仿学习和传统强化学习之间的鸿沟,在任务效果和泛化能力上取得了显著提升,让AI智能体「无师自通」,为突破强化学习瓶颈提供了一种新思路。
这项创新研究由Meta超级智能实验室(Meta Superintelligence Labs)与俄亥俄州立大学(The Ohio State University)的一组顶尖学者共同开展。值得一提的是,这项研究的大部分作者均为华人学者,展示了中国在全球人工智能研究领域日益崭露头角的力量。Meta作为全球领先的人工智能研究机构之一,一直致力于推动AI技术的边界,尤其在语言智能体和自主学习系统的开发方面取得了重要进展。此次研究聚焦于如何通过智能体的‘早期经验’提升其学习能力,打破了传统的依赖专家数据和明确奖励信号的局限。

论文作者绝大多数都是华人。
论文标题:Agent Learning via Early Experience 论文链接:https://arxiv.org/abs/2510.08558

研究背景回顾
在人工智能(AI)领域,“自主智能体”(Autonomous Agents)一直是追求的目标——它们不仅要感知和行动,还要在复杂的环境中自我学习,完成任务,最终实现无需人工干预的目标。随着大语言模型(LLMs)的兴起,这一愿景正逐渐变为现实。
要培养出这样的智能体,强化学习(Reinforcement Learning,RL)无疑是一个常见的解决方案。通过不断优化“环境回报”(reward),RL帮助智能体在规定的环境中达到最优行为。例如,著名的“AlphaGo”就是基于RL成功击败了围棋高手(Silver et al.,2016)。但现实问题来了:许多真实环境(尤其是开放性平台)并没有提供可靠的奖励信号,这就让RL的应用变得十分困难。
现有的替代方案通常依赖“专家数据”和“监督微调”(Supervised Fine-Tuning,SFT),即通过人类专家提供的数据来指导智能体的学习。这种方法避免了奖励信号的依赖,但也面临着一些不可忽视的局限性:智能体不能主动与环境互动学习,只能被动接受数据,且这种方法无法扩展到复杂动态的环境。
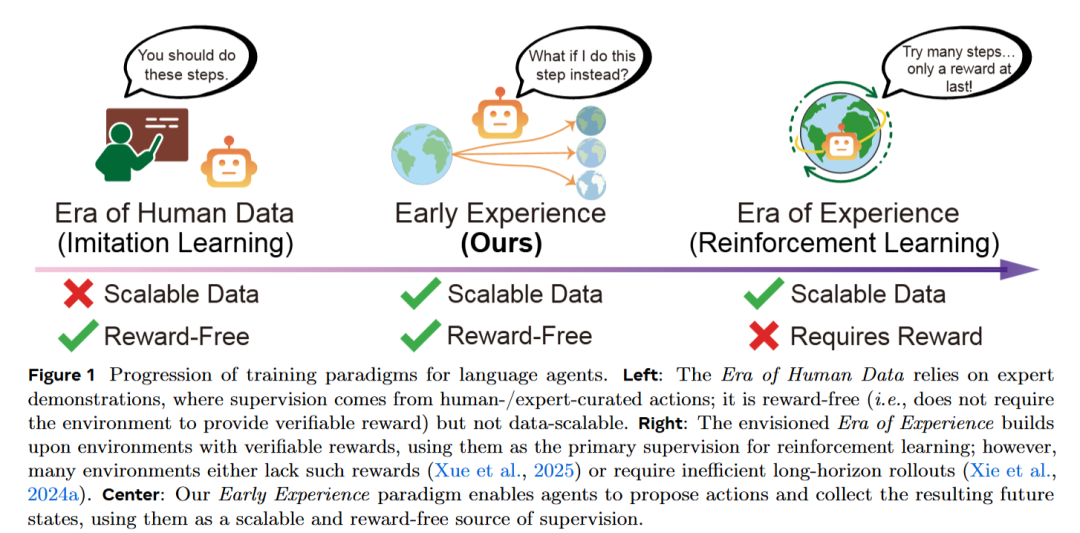
那么,在没有外部奖励信号的情况下,如何让智能体从自己的经验中成长呢?
Meta团队提出了一个名为“早期经验”(Early Experience)的新范式,正是为了应对这个挑战。这一框架位于模仿学习与强化学习之间,智能体不仅从专家数据中学习,还可以通过自己的行动生成“未来状态 (Future States)”,并将其转化为监督信号,直接从自身经验中汲取成长的动力,而无需外部奖励。两大核心策略:
隐式世界建模(Implicit World Modeling):智能体通过收集未来状态,构建对环境动态的内在表征,进而能够预测未来状态,更好地理解环境。
自我反思(Self-Reflection):通过引导智能体将自身行为与专家示范进行对比,找出次优决策并提取经验教训,以改进未来的决策。
这两种策略的核心思想一致:即使没有外部奖励,智能体的行动及其带来的未来状态本身就构成了有效的经验,可以作为直接的监督信号。
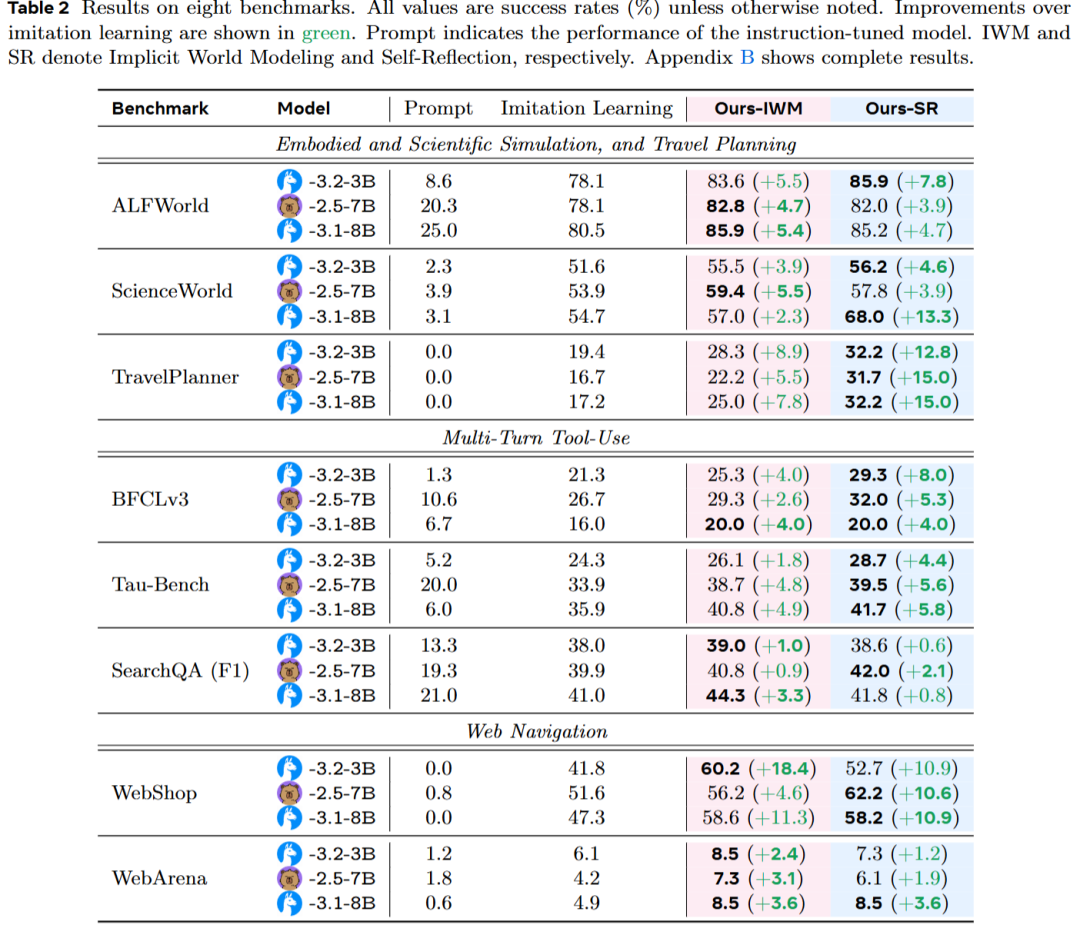
该研究在八个多样化的环境中对“早期经验”范式进行了全面评估,涵盖了体感导航、网页导航、多轮工具使用、长时间规划等任务。结果表明,这两种方法在所有设置中均超越了纯模仿学习基线,成功率平均提升了**+9.6,且跨领域泛化能力提升了+9.4**。
而在那些有明确奖励信号的环境中,研究发现将“早期经验”方法训练的检查点初始化到强化学习中,相较于传统的模仿学习热启动,能显著提高性能,最终成功率提升了**+6.4。这一结果表明,“早期经验”阶段的表现增益能够有效延续到最终的强化学习阶段,增强智能体的整体能力**。
方法详解
在传统的模仿学习中,智能体只看到专家演示的成功预定过程。而在早期经验方法下,智能体也会尝试点击不同的按钮,填写错误的信息,观察错误消息、页面变化等其他结果,这些观察将成为学习信号,而不依赖于外部奖励信号。智能体从专家的轨迹开始,提出自己的动作,并通过探索来收集更多的环境反馈。
早期经验的标记法
对于数据集中的每个专家状态,我们定义一个候选动作集 ,其中是专家在状态 下的动作。我们从初始策略 中采样 个动作,以便在分析中使用。此外,我们还包括专家动作,作为对比分析的一部分。
对于每个专家动作,执行该动作后会转移到下一个状态 。对于每个候选动作,执行它会导致下一个状态 ,该状态是通过过渡函数 采样得到的。这些下一个状态捕捉了执行非专家动作后对环境的即时影响,例如 DOM 结构的更新、新的工具输出、错误消息或任务进度。
这些交互收集到一个回滚数据集(Rollout Dataset)中:
隐式世界建模
世界建模被公式化为一个辅助预测任务,帮助智能体从自身的早期经验中内化环境动态。在这种设置下,状态完全由自然语言表示,从而使得智能体可以将下一个状态的预测任务建模为标准的下一个令牌预测目标。
受先前训练语言模型(LLMs)作为世界模型的工作启发,我们使用从回滚数据集 中获得的下一个状态 作为直接训练信号来训练语言智能体的策略 。例如,在网上预定机票的场景中,智能体可能会在输入无效日期后预测页面状态,并从文本错误消息中学习。这种设计去除了对单独模块的需求,且能够自然地嵌入到 LLM 微调的框架中。
对于每一个回滚三元组 ,构建一个预测任务,其中模型将状态-动作对 作为输入,学习预测下一个状态 。定义训练目标为:
其中 表示语言模型的输出分布, 并与智能体的策略 对齐。
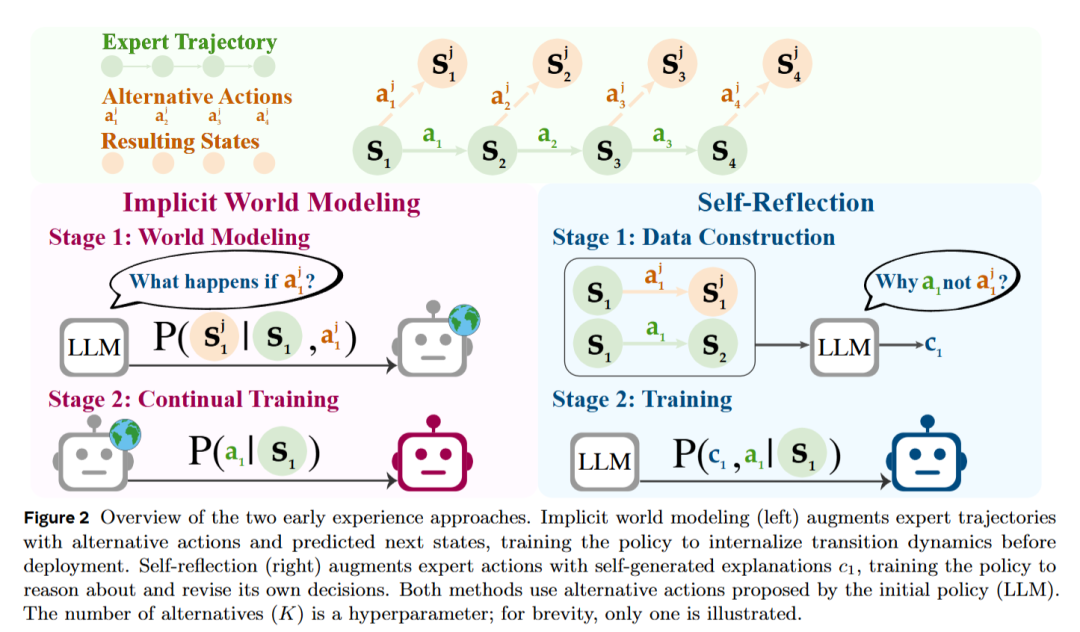
自我反思
自我反思作为智能体从自身探索性结果中学习的一种机制。与单纯依赖专家状态-动作对不同,这一方法要求智能体在每个状态下比较专家的动作和其他可选动作。通过这种方式,智能体不仅学会模仿专家行为,还能理解为什么专家的选择更优。通过这种方法,智能体获得了比单纯的专家动作更丰富的学习信号,这些信号能够促进其在不同任务间的迁移能力。
具体来说,对于每个专家状态 ,我们首先执行专家动作 ,以获得专家的下一状态 。然后,我们提示语言模型生成一个链式思维 ,解释为什么专家的动作 比备选动作 这一提示旨在引导模型生成自然语言推理,突出备选动作 的潜在限制或低效性,这些限制是基于实际的状态转移观察结果。
将得到的三元组 收集到一个数据集 中。然后,我们训练智能体联合预测链式思维和专家动作,基于状态 进行训练,使用标准的下一个令牌预测损失:
其中 表示语言模型的输出分布,并与智能体的策略 对齐。
在实践中,自我反思数据集 与专家数据集 混合,训练模型时使用来自自我反思的链式思维,并通过专家数据补充原始任务数据。每当专家提供的轨迹中包含链式思维时,这些内容就保留。通过这种联合训练,模型能够平衡来自专家演示的决策基础和来自探索结果的对比性见解。
实验结果
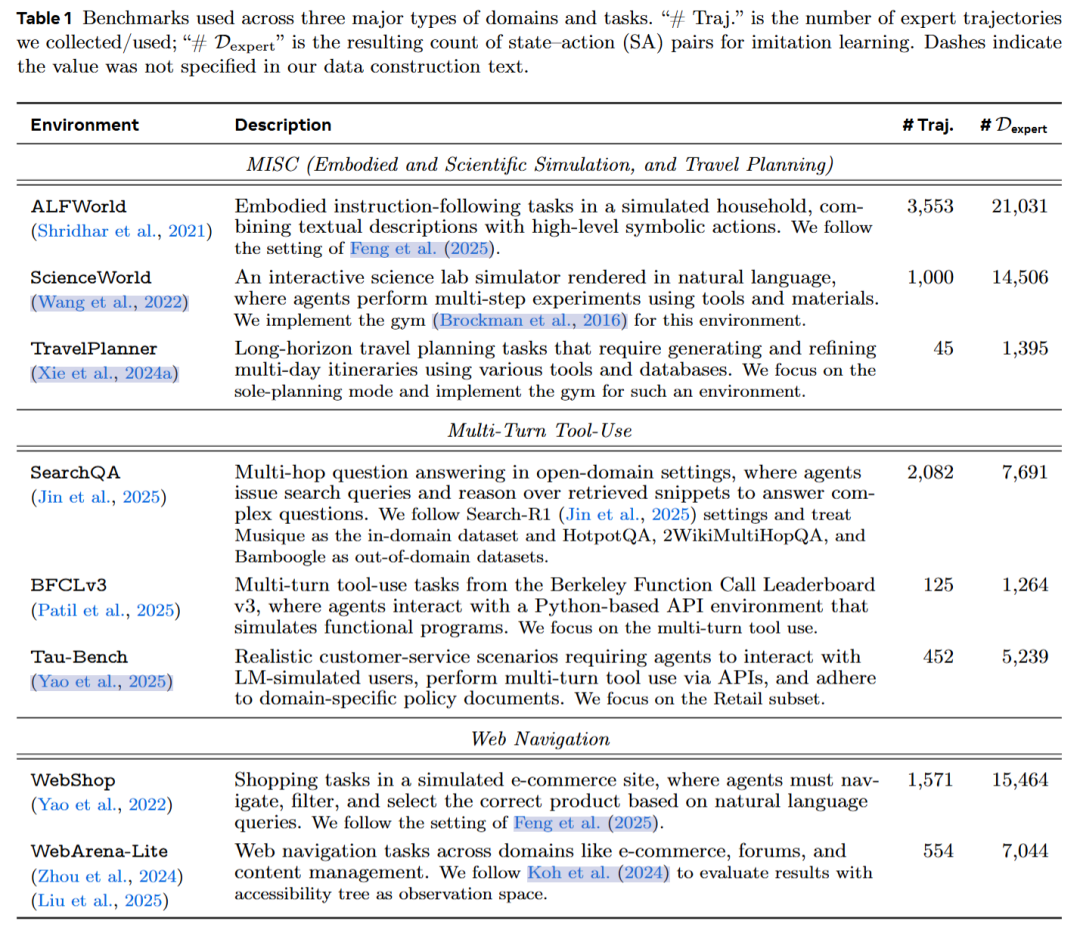
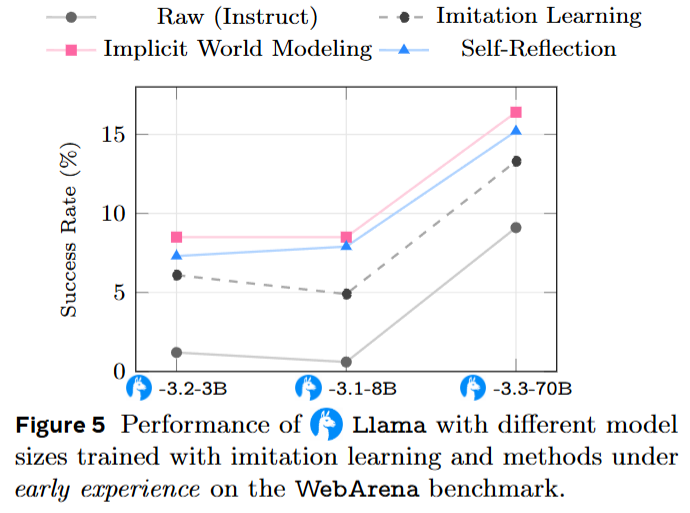
在8个语言智能体环境中进行了一系列实验,涵盖了多轮工具使用、网页导航、科学仿真等任务。通过使用Llama-3.2-3B、Qwen-2.5-7B等三种模型,验证了早期经验方法在不同环境中的效果,跨领域泛化能力,以及与后续强化学习的兼容性。
效果
早期经验方法在几乎所有设置中均表现出优于模仿学习的效果,无论是在小型模型还是大型模型上。
跨领域泛化能力
为评估训练策略在跨域(OOD)任务中的鲁棒性,在多个环境中进行了早期经验的测试。结果显示,(1)所有任务的OOD得分相比领域内性能有所下降,但早期经验方法在大多数情况下能够有效缩小这一差距。(2)在某些任务中,OOD性能的提升甚至超过了领域内的增益(如SearchQA),表明将自身探索过程转化为监督信号有助于智能体适应未覆盖的状态。
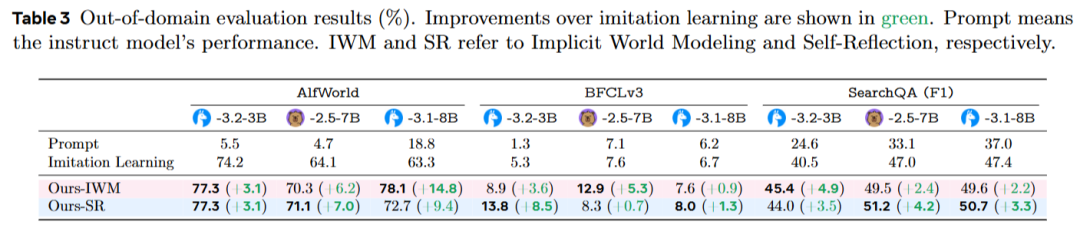
后续强化学习的兼容性
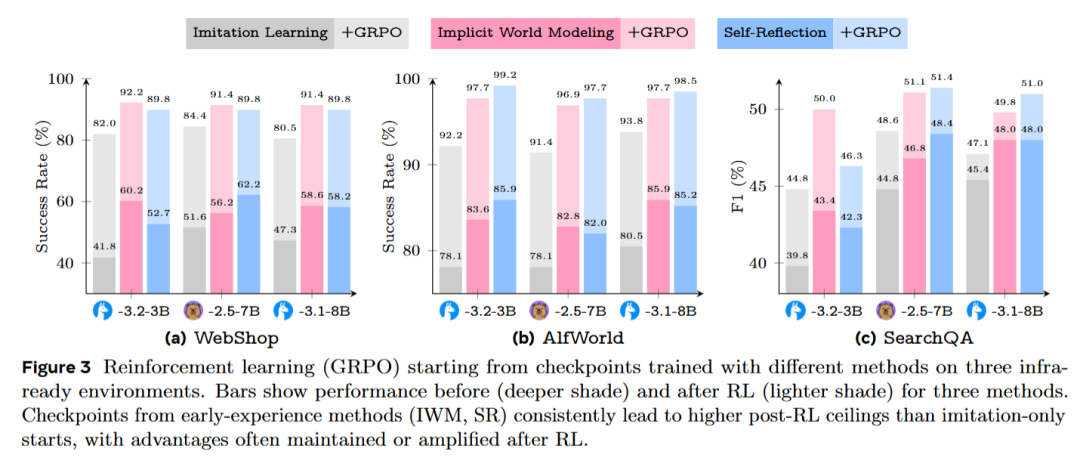
三个具有奖励机制的基准任务:WebShop、ALFWorld和SearchQA被选择,并采用了广泛使用的GRPO算法,其超参数和训练步骤与标准配置一致。唯一不同的因素是初始化方法:模仿学习(IL)、隐式世界建模(IWM)或自我反思(SR)。
结果发现,(1)从早期经验开始的模型在后续强化学习阶段的表现更好,最终得分普遍较高。(2)在某些任务中,性能差距在强化学习阶段进一步扩大(如ALFWorld),而在其他任务中,差距逐渐缩小,但从未逆转。(3) 即使在相同强化学习步骤下,模仿学习(IL)起始的模型很少能达到早期经验方法的最终表现。(4)为了完整性,研究还直接从预训练的原始模型开始运行GRPO,未经过任何监督阶段。这在所有任务中表现最差,且训练动态不稳定,进一步证明了强初始化的重要性。
比较研究
早期经验方法与两种其他方法进行了比较,这些方法通过不执行备选动作或观察其结果状态来注入额外的监督或推理信号。通过这种比较,研究测试了是否可以通过推理扩展(推理时加长时间)或在训练时添加无根据的推理来匹配早期经验方法的效果。结果显示:
长时间推理(Long CoT) 能够在某些设置中提供适度的改进,但在更困难的环境中,增益很快消失。缺乏内在推理的模型很难持续长时间的推理,导致推理链条经常偏离或崩溃,尽管存在截断机制。 在STaR风格的数据中,生成的推理与专家动作之间的匹配率较低,留下的可用训练数据很少。由于这些推理未在实际环境中经过测试,且经常出现错误或虚构的工具和事实,微调可能会导致性能下降。

为研究专家监督量对性能的影响,该研究通过调整用于引导早期经验的示范数量,同时保持总训练预算固定。图4 (a) 显示,在不同数据量下,早期经验始终保持领先于模仿学习。具体表现为:
在WebShop上,使用仅1/8的示范就已经超过了在完整数据集上训练的模仿学习模型。 在ALFWorld上,使用1/2的示范也达到了类似的效果。 尽管随着专家数据的增加,IWM和SR方法的性能得到了提升,但与模仿学习相比,其优势始终保持明显。这表明,早期经验提供的额外监督信号超出了仅通过示范能够获得的范围。
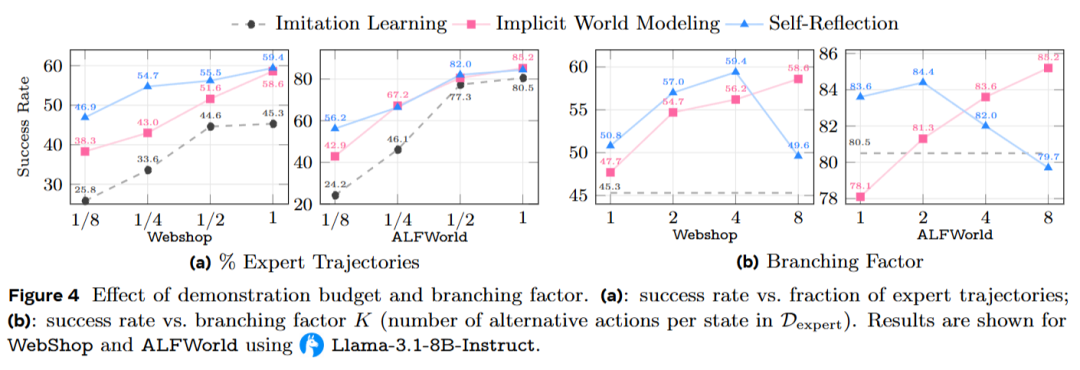
对分支因子 KKK 进行了消融实验,结果显示,随着 KKK 的增加,隐式世界建模(IWM)表现出稳定的提升,这与学习更丰富的转移规律一致。而自我反思(SR)则在较小到中等的 KKK 范围内表现良好,但在 KKK 非常大时,性能可能会出现非单调变化:比较更多的备选动作有时会包括其他成功的动作,这会减少与专家动作的对比。此外,当前的模型在单一上下文中推理多个备选动作和结果的能力有限。
总结
早期经验范式下提出的两种方法:隐式世界建模(IWM)和自我反思(SR),在领域内有效性和跨领域鲁棒性方面均有所提升,且在用于强化学习热启动时仍然保持其优势。因此,早期经验被视为一个实用且通用的基础,为构建更强大的语言智能体提供了前瞻性框架,尤其是在即将到来的经验时代。
但目前的隐式世界建模和自我反思方法主要集中在短时间跨度的轨迹上,如何扩展这些方法以应对没有显式奖励的长时间跨度的信用分配仍是一个未解的挑战。











