论文选自 PaperScope HF 数据库,论文解读由闻星使用 Intern-S1 等 AI 生成
今天突然来了兴致想了解一些 DPO、PPO、GRPO 算法及其变种,于是我在 P 站(https://PaperScope.ai)的数据库里面搜索了一下 Policy Optimization 这个关键词,感受一下这 40+ 论文的冲击感。
PPO,DPO,GRPO,ARPO,CAMPO,EPO,AHPO,TreePO,
PAPO,GPPO,MPO,BRPO,SPO,GRPO,PVPO,GMPO,
StepGRPO,DIALTREE-RPO,MAPO,MATPO,DCPO,
DPPO,HBPO,IGPO,TAPO,ASPO,GFPO,T-PPO,
T-PPO,DVPO,DR-PO,TAROT,INPO,LSPO,
SFPO,GCPO,SPO,HAPO,TGPOPPO, DPO, GRPO, ARPO... 是不是感觉刚弄懂一个,新的“PO”又冒了出来?你不是一个人!大模型优化的世界,就像一个不断扩张的“字母汤宇宙”。今天,我们就带你跳出这个漩涡,一次性梳理40+种策略优化算法的核心思想,让你彻底告别“PO”焦虑。
(1) Proximal Policy Optimization Algorithms

论文简介:
由OpenAI的John Schulman等学者提出了Proximal Policy Optimization(PPO)算法,该工作通过设计带剪贴概率比率的替代目标函数,在保持策略更新稳定性的同时,显著提升了策略梯度方法的样本效率与实现简洁性。PPO的核心创新在于引入可多次小批量更新的优化框架,通过限制策略更新幅度的剪贴机制(如0.2的剪贴范围)构建悲观性能下界,既避免了TRPO中复杂的二阶优化计算,又解决了传统策略梯度方法因单次更新导致的训练不稳定问题。实验表明,PPO在MuJoCo连续控制任务中超越TRPO、A2C等基线方法,在Atari游戏上也展现出优于A2C的样本效率和与ACER相当的最终性能。该方法通过Adam优化器实现多epoch参数更新,支持策略与价值网络参数共享,并通过自适应KL散度惩罚进一步优化更新步长,在机器人控制和3D humanoid任务中展现出强大的鲁棒性,为深度强化学习的工程落地提供了兼顾性能与易用性的解决方案。
论文链接:
https://hf.co/papers/1707.06347
PaperScope.ai 解读:
https://paperscope.ai/hf/1707.06347
(2) Direct Preference Optimization: Your Language Model is Secretly a Reward Model

论文简介:
由斯坦福大学等机构提出了Direct Preference Optimization(DPO),该工作通过重新参数化奖励模型实现无需显式奖励建模或强化学习的策略优化,显著简化了人类偏好对齐语言模型的训练流程。传统方法如RLHF需通过拟合奖励模型再用强化学习优化策略,而DPO基于最优策略与奖励函数的解析关系,直接构建策略与参考模型的对数概率比损失函数,将偏好学习转化为简单的二分类问题。实验表明DPO在情感控制、摘要生成和单轮对话任务中表现优于PPO等基线,且对采样温度更鲁棒。该方法在60亿参数规模下无需复杂调参即可达到甚至超越强化学习方法的性能,同时避免了奖励模型训练和策略优化的双重计算开销。研究还揭示DPO隐式优化的奖励函数具有与Bradley-Terry模型相同的偏好表示能力,其理论分析证明了参数化方式可覆盖所有等价奖励类。通过GPT-4自动评估和人工验证,DPO生成的摘要更符合人类偏好,对话响应质量显著提升,为大规模语言模型的偏好对齐提供了高效可靠的解决方案。
论文链接:
https://hf.co/papers/2305.18290
PaperScope.ai 解读:
https://paperscope.ai/hf/2305.18290
(3) DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models

论文简介:
由DeepSeek-AI、清华大学和北京大学等机构提出了DeepSeekMath 7B,该工作通过构建1200亿token的高质量数学预训练语料库和创新的Group Relative Policy Optimization(GRPO)算法,显著提升了开源语言模型的数学推理能力。研究团队从Common Crawl中筛选出优质数学内容,构建了DeepSeekMath Corpus,其规模是Minerva使用的数学网页数据的7倍,OpenWebMath的9倍。实验表明,基于该语料库训练的DeepSeekMath-Base 7B在GSM8K和MATH基准测试中分别达到64.2%和36.2%的准确率,超越了参数量大77倍的Minerva 540B模型。该模型还展现出跨语言数学能力,在中文基准测试中表现尤为突出。
研究团队创新性地引入GRPO算法,通过组内相对优势估计替代传统PPO算法中的价值网络,将训练资源消耗降低40%以上。GRPO在仅使用数学指令微调数据的子集情况下,使DeepSeekMath-Instruct 7B在MATH基准测试中的准确率从46.8%提升至51.7%,在GSM8K中达到88.2%。该算法通过组内输出相对优势计算梯度系数,有效解决了传统RL方法中价值网络训练困难的问题。研究还揭示了代码预训练对数学推理能力的促进作用,发现代码数据与数学数据的混合训练能缓解灾难性遗忘问题。值得注意的是,研究发现arXiv论文对数学推理能力提升效果有限,这一结论挑战了当前主流的预训练范式。最终,DeepSeekMath系列模型在多个数学基准测试中达到开源模型最优水平,接近GPT-4和Gemini Ultra的表现,为开源社区在数学推理领域的突破提供了重要参考。
论文链接:
https://hf.co/papers/2402.03300
PaperScope.ai 解读:
https://paperscope.ai/hf/2402.03300
(4) Group Sequence Policy Optimization

论文简介:
由阿里巴巴Qwen团队提出的Group Sequence Policy Optimization(GSPO),通过序列级重要性比率定义和优化机制,显著提升了大语言模型强化学习训练的稳定性与效率。该工作针对GRPO算法在训练大规模模型时存在的token级重要性权重失效问题,创新性地采用基于序列似然的重要性比率计算方法,并实施序列级裁剪与奖励机制。理论分析表明,GSPO的梯度更新有效避免了GRPO中token级权重累积导致的高方差问题,实验数据显示其在AIME'24、LiveCodeBench等基准测试中实现更优性能,同时训练效率提升达40%以上。特别在Mixture-of-Experts(MoE)模型训练中,GSPO彻底解决了专家激活波动导致的训练不稳定问题,无需额外引入Routing Replay等复杂策略,成功应用于Qwen3模型的训练优化。此外,该算法通过序列级似然计算简化了训练-推理协同流程,为构建高效可靠的RL基础设施提供了新范式,其核心思想已被验证可扩展至多轮对话等复杂场景的GSPO-token变体。这项研究为大模型强化学习的规模化应用奠定了坚实基础。
论文链接:
https://hf.co/papers/2507.18071
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.18071
(5) Agentic Reinforced Policy Optimization

论文简介:
由中国人民大学、快手科技等机构提出了Agentic Reinforced Policy Optimization(ARPO),该工作针对大语言模型(LLM)代理的多轮交互训练问题,提出了一种新型强化学习算法。研究发现LLM在调用外部工具后,生成token的熵值显著升高,表明工具交互引入了推理不确定性。基于此现象,ARPO创新性地设计了熵基自适应rollout机制,在全局轨迹采样基础上,动态识别高熵工具交互步骤进行分支采样,从而更高效地探索工具使用行为。同时通过优势归因估计方法,使模型能够区分共享路径与分支路径的优势差异,优化多轮决策质量。
实验在数学推理、知识推理和深度搜索三大类13个基准任务上展开,对比了Qwen、Llama等主流模型基线。结果显示ARPO在保持相同参数规模下,平均准确率提升4%,其中在GAIA和WebWalker等深度搜索任务中,基于Qwen-14B的ARPO模型准确率分别达到43.7%和36.0%,超越GPT-4o等闭源模型。特别值得注意的是,ARPO仅需传统轨迹级别RL算法50%的工具调用预算即可达成更优性能,验证了算法在成本效率上的优势。消融实验证实了浏览器代理规模与推理性能的正相关性,以及熵值参数对采样效率的关键影响。该研究为构建高效能LLM代理提供了新的算法范式,相关代码和数据已开源。
论文链接:
https://hf.co/papers/2507.19849
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.19849
(6) MiroMind-M1: An Open-Source Advancement in Mathematical Reasoning via Context-Aware Multi-Stage Policy Optimization

论文简介:
由MiroMind AI等机构提出了MiroMind-M1系列模型,该工作通过监督微调(SFT)与强化学习(RL)的双阶段训练框架,在数学推理领域实现了开源模型的性能突破。研究团队基于Qwen-2.5架构构建了包含719K数学推理问题的高质量训练数据集,并提出Context-Aware Multi-Stage Policy Optimization(CAMPO)算法,通过渐进式上下文长度扩展和自适应重复惩罚机制优化RL训练效率。MiroMind-M1-RL-7B和MiroMind-M1-RL-32B模型在AIME24、AIME25和MATH基准测试中达到或超越同参数量级开源模型的最优水平,其中7B模型在AIME24上取得73.4%的准确率,相比基线提升15%以上。研究特别强调训练效率优化,CAMPO算法通过分阶段长度控制使推理响应平均缩短30%以上,同时保持验证准确率。团队全面开源了包含模型权重(MiroMind-M1-SFT-7B/MiroMind-M1-RL-7B/MiroMind-M1-RL-32B)、训练数据集(MiroMind-M1-SFT-719K/MiroMind-M1-RL-62K)、训练代码及改进版数学验证器的完整技术栈,所有资源均通过HuggingFace和GitHub公开获取。这项工作不仅验证了开源方案在复杂推理任务中的可行性,更为后续研究提供了可复现的技术基线与数据基础设施。
论文链接:
https://hf.co/papers/2507.14683
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.14683
(7) EPO: Entropy-regularized Policy Optimization for LLM Agents Reinforcement Learning

论文简介:
由 Rutgers University 和 Adobe 等机构提出的 EPO(Entropy-regularized Policy Optimization)框架,针对多轮对话场景中大语言模型(LLM)代理的强化学习训练挑战,提出了一种创新的熵控制机制。该工作揭示了稀疏奖励环境下特有的“探索-利用级联失败”现象:早期阶段因奖励稀疏导致策略过早收敛到低熵的无效行为模式,后期阶段则因传统熵正则化失效引发策略熵剧烈震荡,形成“早阶段过度探索-晚阶段不确定性传播”的恶性循环。EPO 通过三重机制破解这一难题:1)轨迹感知的熵正则化,将策略熵计算扩展到整个多轮轨迹并按轨迹批次平均,捕捉长程决策的时序依赖;2)熵平滑正则化,通过维护历史熵均值窗口,对偏离历史范围的策略熵施加惩罚,抑制训练过程中的剧烈震荡;3)动态相位加权机制,采用指数衰减调度策略,在训练初期抑制过度探索,中期平衡探索与利用,后期强化收敛稳定性。理论分析表明 EPO 能保证熵方差单调递减并维持最优探索-利用平衡。实验在 ScienceWorld 和 ALFWorld 两个基准上验证,EPO 与 PPO 结合后在 ScienceWorld 中实现 152% 的成功率提升,与 GRPO 结合在 ALFWorld 取得 19.8% 的性能增益,显著优于 ReAct、SFT、AgentGym 等基线方法。消融实验表明熵平滑正则化对稳定训练至关重要,动态加权机制则加速了训练收敛。该研究证明多轮稀疏奖励场景需要区别于传统 RL 的熵控制范式,为 LLM 代理训练提供了新的理论框架和实践工具。
论文链接:
https://hf.co/papers/2509.22576
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.22576
(8) MM-HELIX: Boosting Multimodal Long-Chain Reflective Reasoning with Holistic Platform and Adaptive Hybrid Policy Optimization

论文简介:
由上海交通大学、上海人工智能实验室等机构提出了MM-HELIX,该工作针对多模态大语言模型(MLLMs)在长链反射推理能力上的显著缺陷,构建了包含42个挑战性任务的MM-HELIX基准,通过系统性评估揭示了当前模型在复杂推理场景中的性能瓶颈。研究团队进一步开发了Step-Elicited Response Generation(SERG)数据生成管道,构建了包含10万条高质量反射推理轨迹的MM-HELIX-100K数据集,并提出自适应混合策略优化(AHPO)算法,通过动态整合离线监督信号与在线强化学习,在Qwen2.5-VL-7B模型上实现了MM-HELIX基准准确率18.6%的提升,同时在数学逻辑任务中获得平均5.7%的泛化性能增益。该工作通过基准构建、数据生成与训练范式创新,首次系统性验证了反射推理能力在MLLMs中的可学习性与可迁移性,为开发具备复杂问题解决能力的多模态模型提供了关键方法论支持。
论文链接:
https://hf.co/papers/2510.08540
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.08540
(9) TreePO: Bridging the Gap of Policy Optimization and Efficacy and Inference Efficiency with Heuristic Tree-based Modeling
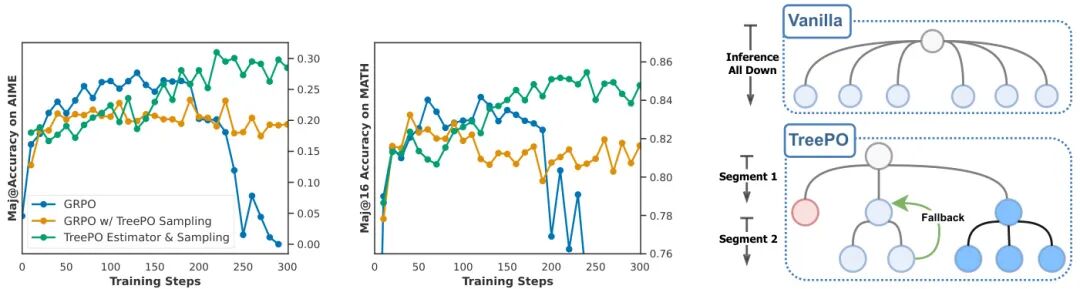
论文简介:
由 ByteDance Seed、M-A-P 和 UoM 等机构提出了 TreePO,该工作提出了一种基于启发式树结构建模的策略优化框架,通过将序列生成转化为树状搜索过程,在提升大型语言模型(LLM)复杂推理能力的同时显著降低计算成本。核心创新包括:1)动态树采样策略与固定长度分段解码机制,通过局部不确定性触发分支扩展,利用共享前缀计算摊销和低价值路径早停,实现推理效率提升;2)树结构分段优势估计方法,结合全局与局部近端策略优化,实现更精准的信用分配;3)动态发散与概率驱动的回退策略分析,平衡探索多样性与计算开销。实验表明,TreePO在数学推理基准测试中相比传统方法GPU小时数减少22%-43%,轨迹级采样计算量降低40%,token级计算量减少35%,同时保持甚至提升模型性能。该框架通过结构化搜索策略和优势估计创新,为大规模强化学习训练提供了高效可扩展的解决方案,为LLM在复杂任务中的高效推理提供了新范式。
论文链接:
https://hf.co/papers/2508.17445
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17445
(10) Perception-Aware Policy Optimization for Multimodal Reasoning

论文简介:
由伊利诺伊大学厄巴纳-香槟分校和阿里巴巴集团等机构提出了PAPO(Perception-Aware Policy Optimization),该工作针对多模态推理任务中视觉感知错误占比高达67%的核心痛点,在GRPO算法框架中引入隐式感知损失(Implicit Perception Loss),通过最大化原始图像与遮蔽图像生成结果的KL散度,量化模型对视觉信息的依赖程度。PAPO在不依赖额外数据标注或外部模型的情况下,通过内部监督信号显著提升模型视觉推理能力,实验显示在8个多模态基准测试中平均提升4.4%,在高视觉依赖任务上最高提升8.0%,并减少30.5%的感知错误。研究发现KL损失系数过大可能导致模型生成无关内容的崩溃问题,通过双熵损失(Double Entropy Loss)正则化有效缓解该现象。该方法在保持算法简洁性的同时,为多模态模型的视觉感知与推理能力优化提供了新范式,为构建具身智能体的视觉推理能力奠定基础。
论文链接:
https://hf.co/papers/2507.06448
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.06448
(11) Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization
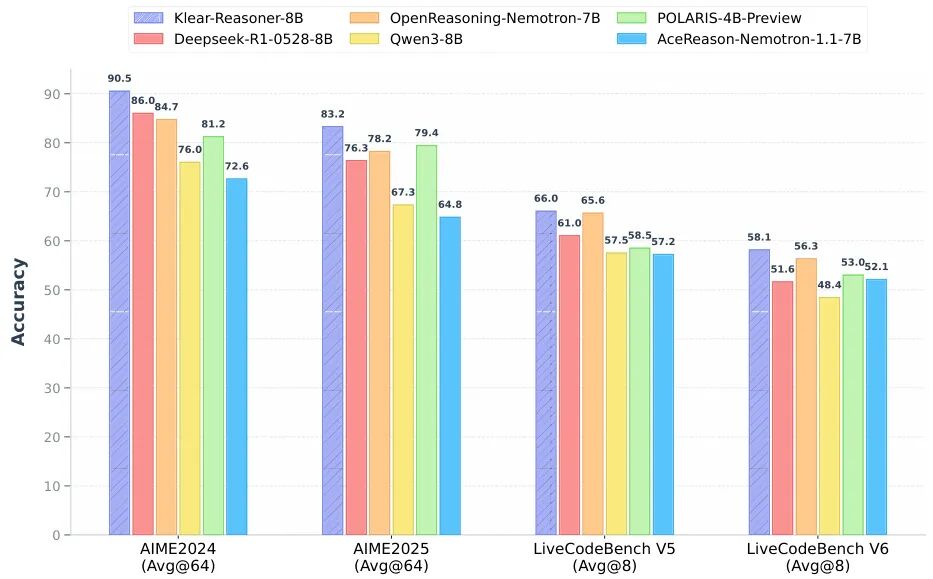
论文简介:
由快手Klear团队提出了Klear-Reasoner,该工作通过梯度保留剪枝策略优化(GPPO)显著提升了大模型的长推理能力。研究团队系统分析了当前强化学习剪枝机制的两大缺陷:高熵令牌剪枝导致探索信号丢失,以及次优轨迹梯度截断引发的延迟收敛问题。创新性提出的GPPO方法在保留传统剪枝稳定性的基础上,通过将剪枝令牌梯度约束在可控范围内,实现了探索能力与训练稳定性的平衡。在监督微调阶段,研究发现高质量数据源(如OpenThoughts、DeepSeek-R1)的精炼训练效果显著优于多源数据混合,且对困难样本无需进行准确性过滤。实验结果显示,Klear-Reasoner-8B在数学推理(AIME2024 90.5%、AIME2025 83.2%)和代码生成(LiveCodeBench V5 66.0%、V6 58.1%)任务中全面超越同规模模型,其64K推理窗口下的性能甚至超过部分96K模型。研究还验证了软奖励机制对稀疏奖励问题的改善效果,以及测试用例过滤对代码RL训练的优化作用。该工作为构建高效推理模型提供了数据筛选、监督微调和强化学习优化的完整解决方案,证明了高质量数据与创新优化算法的协同价值。
论文链接:
https://hf.co/papers/2508.07629
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.07629
(12) Toward Evaluative Thinking: Meta Policy Optimization with Evolving Reward Models

论文简介:
由明尼苏达大学、MIT、Grammarly和Elice等机构提出了Meta Policy Optimization(MPO),该工作针对大型语言模型(LLM)对齐中的奖励黑客和提示工程瓶颈问题,提出通过元奖励模型动态优化奖励模型提示的框架。MPO通过元奖励模型(MRM)实时监控训练进程,动态调整奖励模型(RM)的评估标准,使奖励信号随策略模型能力提升而精细化,有效缓解奖励模型对齐中的核心挑战。
MPO的核心创新在于引入认知科学中的元认知机制,通过"元分析-元精炼-元合并"三阶段流程,使奖励模型具备自我反思能力。在实验中,MPO框架在议论文写作、摘要生成、伦理推理和数学推理等多任务场景下均表现出色。以Qwen2-1.5B-Instruct模型为基线,在议论文写作任务中,MPO优化的模型击败了使用专家设计提示的基线模型(Elo评分提升165分),且在数学推理任务中准确率提升40.6%。特别值得注意的是,MPO通过动态调整评估标准,显著降低了奖励模型对提示工程的依赖,其自动生成的评估提示超越了经过60轮PPO训练迭代的专家提示。
该方法的关键优势在于:1)通过动态细化评估标准提升奖励信噪比,有效抑制奖励黑客行为;2)元奖励模型的引入使评估提示自动适配策略模型能力,避免人工反复调试;3)跨任务的通用性验证,展示出在宽度(如写作)和深度(如数学推理)不同维度的适应能力。实验数据显示,MPO优化的提示在论证结构复杂度(如Attribution关系增加3.2倍)、评估维度粒度(如议论文评分项从5项扩展到10项)等方面呈现显著进化特征。
这项工作为LLM对齐提供了新范式,通过将静态奖励模型升级为动态演进的评估系统,突破了传统RLAIF框架的局限性。其启示在于:有效的对齐机制需要具备随训练进程自适应调整的元认知能力,这为构建更鲁棒的LLM评估系统提供了重要思路。
论文链接:
https://hf.co/papers/2504.20157
PaperScope.ai 解读:
https://paperscope.ai/hf/2504.20157
(13) Optimizing Anytime Reasoning via Budget Relative Policy Optimization

论文简介:
由 Sea AI Lab 和新加坡国立大学等机构提出了 AnytimeReasoner 框架,该工作通过采样 token 预算分布并引入可验证密集奖励优化大语言模型的任意时间推理能力。研究发现,现有强化学习方法仅优化固定预算下的最终性能,导致训练和部署效率受限。AnytimeReasoner 通过在训练时动态截断思考过程并生成多预算下的验证奖励,构建了更细粒度的信用分配机制。核心创新包括:1)预算相对策略优化(BRPO)算法,结合当前进度和组内平均回报构建低方差优势估计;2)解耦思考与总结策略优化,采用均匀预算分布训练鲁棒总结器;3)理论证明任意时间目标函数是标准推理目标的下界。实验表明,在数学推理任务中,该方法在所有预算条件下均超越 GRPO 基线,且在最大预算下仍保持 32.7% 的 AIME2024 准确率提升,同时将平均思考长度缩短 15%。消融实验证实,密集奖励、解耦优化和方差缩减技术分别贡献了 2.1%/1.8%/1.2% 的性能增益,验证了各组件的有效性。该框架为资源受限场景下的高效推理提供了新范式。
论文链接:
https://hf.co/papers/2505.13438
PaperScope.ai 解读:
https://paperscope.ai/hf/2505.13438
(14) Single-stream Policy Optimization

论文简介:
由腾讯等机构提出了Single-stream Policy Optimization(SPO),该工作针对大语言模型(LLM)策略优化中组方法(如GRPO)存在的退化组浪费计算资源和同步瓶颈限制扩展性两大核心问题,提出基于单流范式的优化框架。SPO通过引入持续的KL自适应价值追踪器替代组内动态基线,并采用全局优势归一化策略,在消除组间同步依赖的同时,为每个样本提供稳定低方差的学习信号。实验表明,在Qwen3-8B模型的数学推理任务中,SPO在maj@32指标上较GRPO平均提升3.4个百分点,其中在BRUMO 25数据集上实现7.3个百分点的显著突破,并在工具集成推理场景中展现4.35倍的训练吞吐量优势。其创新点在于通过贝叶斯价值追踪器动态调整历史奖励记忆,结合全局优势归一化和优先级采样机制,既避免了组方法中因全正确/全错误样本导致的零优势问题,又通过异步采样突破长序列任务中的同步瓶颈。这一工作挑战了当前强化学习算法复杂化的趋势,证明基于基础RL原理的简洁设计在LLM推理优化中具有更强的鲁棒性和扩展性,为工具调用等复杂场景的训练提供了新范式。
论文链接:
https://hf.co/papers/2509.13232
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.13232
(15) Training-Free Group Relative Policy Optimization

论文简介:
由Youtu-Agent团队等机构提出了Training-Free Group Relative Policy Optimization(Training-Free GRPO),该工作针对大语言模型(LLM)代理在特定领域表现不足的问题,提出了一种无需参数更新的策略优化方法。传统方法依赖监督微调(SFT)和强化学习(RL)调整模型参数,存在计算成本高、泛化性差、数据需求大等局限。Training-Free GRPO通过在上下文空间中构建动态经验知识库,以语义优势替代数值优势,实现对LLM输出分布的引导优化。核心创新在于保留模型参数冻结的前提下,利用多轮迭代生成的rollout组进行语义优势分析,通过自然语言经验提取和知识库更新,形成可指导后续推理的token先验。实验表明,该方法在数学推理(AIME基准)和网络搜索(WebWalkerQA)任务中,使用仅100个训练样本即可显著提升DeepSeek-V3.1-Terminus等大模型的性能。例如在AIME24任务中,结合ReAct工具链的准确率从80.0%提升至82.7%,成本仅18美元,远低于传统RL方法的10000美元级投入。其优势体现在:1)数据效率高,少量样本即可优化;2)计算成本低,避免参数更新的GPU资源消耗;3)泛化性强,通过切换经验库适配多领域任务;4)性能优越,超越需微调的小型LLM。该方法为LLM代理的低成本领域适配提供了新范式,验证了上下文空间优化替代参数空间优化的有效性,对实际应用场景具有重要价值。
论文链接:
https://hf.co/papers/2510.08191
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.08191
(16) PVPO: Pre-Estimated Value-Based Policy Optimization for Agentic Reasoning

论文简介:
由阿里巴巴云计算团队提出了PVPO(Pre-Estimated Value-Based Policy Optimization),该工作针对传统强化学习方法在复杂任务中依赖多次采样和组内比较导致的局部最优及高计算成本问题,提出了一种基于预估价值的策略优化框架。PVPO通过引入参考模型作为优势参考锚点,并结合数据预采样策略,有效解决了组策略方法中累积偏差和样本效率低下的核心痛点。
核心创新包括:1)静态V值估计机制,通过预训练参考模型生成任务奖励锚点,替代传统动态组内平均值,显著降低策略更新方差;2)组采样策略,利用参考模型离线评估样本难度,过滤低价值数据并生成零准确率样本的高质量轨迹,提升训练效率。实验在多跳问答(Musique、HotpotQA等)和数学推理(AIME、MATH500等)9个数据集上验证,PVPO在7B参数模型下实现平均精度提升8个百分点,训练速度提升1.7-2.5倍,同时在低采样预算下保持97%性能的同时减少60%计算成本。该方法不仅在多领域任务中取得SOTA表现,还展现出跨模型规模的稳定扩展能力,为大语言模型的高效强化学习提供了新范式。
论文链接:
https://hf.co/papers/2508.21104
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.21104
(17) Geometric-Mean Policy Optimization

论文简介:
由UCAS、CUHK、HKUST和Microsoft Research等机构提出了Geometric-Mean Policy Optimization (GMPO),该工作提出了一种稳定的GRPO变体,通过优化token-level奖励的几何平均数来增强训练稳定性并提升推理性能。GMPO针对GRPO在处理异常重要性加权奖励时出现的策略更新不稳定问题,采用几何平均数替代算术平均数作为优化目标,有效降低了目标函数对异常值的敏感性,并通过理论分析证明其更窄的目标值范围和更稳定的梯度特性。实验表明,GMPO在数学推理基准测试中平均Pass@1准确率提升4.1%(DeepSeek-R1-Distill-Qwen7B模型),在多模态推理基准Geometry3K上提升1.4%,同时保持更低的KL散度和更高的token熵,表明其在探索能力与训练稳定性间的更好平衡。该方法通过token级梯度加权和动态采样比率裁剪策略,在扩大探索范围的同时维持策略更新的可靠性,为大规模语言模型的强化学习稳定性优化提供了新方向。
论文链接:
https://hf.co/papers/2507.20673
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.20673
(18) R1-VL: Learning to Reason with Multimodal Large Language Models via Step-wise Group Relative Policy Optimization

论文简介:
由南洋理工大学和清华大学等机构提出了R1-VL,该工作设计了一种名为Step-wise Group Relative Policy Optimization(StepGRPO)的在线强化学习框架,通过引入Step-wise Reasoning Accuracy Reward(StepRAR)和Step-wise Reasoning Validity Reward(StepRVR)两种基于规则的阶梯式推理奖励机制,有效解决了多模态大语言模型(MLLMs)在推理过程中依赖被动模仿正确路径、忽视错误路径探索的核心问题。StepRAR采用软关键步骤匹配技术评估推理路径中必要中间步骤的完整性,StepRVR则通过推理完整性和逻辑一致性评估策略强化结构化逻辑链的生成能力。这种阶梯式奖励机制在无需额外过程奖励模型的情况下,为模型生成的推理轨迹提供密集且细粒度的监督信号,显著缓解了传统强化学习中outcome-level奖励导致的稀疏奖励问题。实验部分基于Qwen2-VL系列模型构建的R1-VL在MathVista、MMStar等8个多模态基准测试中全面超越现有方法,其中R1-VL-7B在MathVista上达到63.5%的准确率,较基线模型提升3.8%,并优于闭源模型Claude-3.5 Sonnet等。该方法通过策略预热阶段与阶梯式在线优化双阶段设计,实现了推理轨迹生成与自我迭代优化的闭环,为多模态模型的推理能力提升提供了无需人工标注数据的强化学习新范式。
论文链接:
https://hf.co/papers/2503.12937
PaperScope.ai 解读:
https://paperscope.ai/hf/2503.12937
(19) Tree-based Dialogue Reinforced Policy Optimization for Red-Teaming Attacks

论文简介:
由佐治亚理工学院和Oracle AI等机构提出的DIALTREE-RPO,首次将红队测试建模为多轮对话策略推理问题,通过树搜索增强的强化学习框架实现自动化多轮攻击策略发现。该工作创新性地设计了对话树展开与剪枝机制,在每轮对话中并行探索多条攻击路径并动态过滤低质量分支,结合自适应掩码技术解决多轮策略优化中的格式遗忘难题,同时构建了面向非验证性奖励的对话级安全评估函数。实验表明,该方法在10个主流大模型上实现平均85.3%的攻击成功率,相比现有最优方法AutoDAN-Turbo提升25.9%,且仅需更少的查询次数。特别值得注意的是,该框架从1B参数的小模型训练后,可直接迁移到GPT-4o等大模型实现75%以上的攻击成功率,揭示了当前模型在多轮交互场景下的系统性漏洞。研究还发现模型通过渐进式诱导、跨语言规避等新策略突破安全机制,为构建更具鲁棒性的对话系统提供了重要启示。
论文链接:
https://hf.co/papers/2510.02286
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.02286
(20) MAPO: Mixed Advantage Policy Optimization
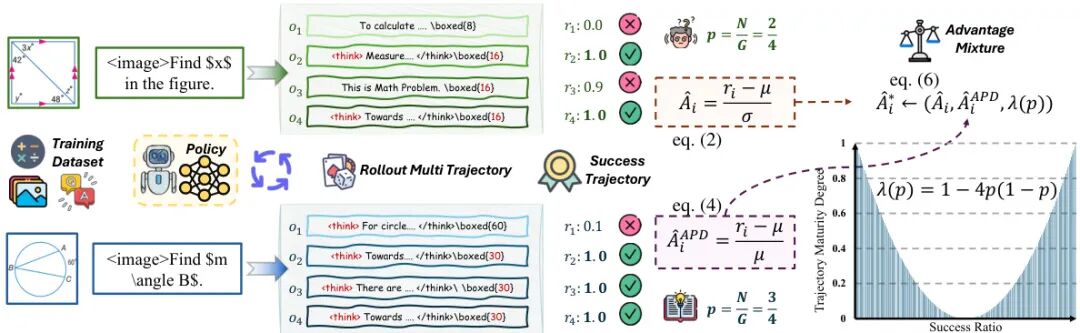
论文简介:
由武汉大学、字节跳动等机构提出了MAPO(Mixed Advantage Policy Optimization),该工作针对Group Relative Policy Optimization(GRPO)中固定优势函数导致的"优势反转"和"优势镜像"问题,提出动态调整优势函数的解决方案。研究发现,不同样本轨迹确定性差异会导致现有优势函数分配失衡:高确定性样本可能因标准差过小产生异常优势值,而低确定性样本则难以获得有效梯度信号。MAPO通过引入轨迹确定性评估机制,创新性地采用优势百分比偏差(APD)替代传统Z-score标准化,并设计轨迹确定性重加权(TCR)策略,根据样本确定性动态融合标准差敏感型与均值敏感型优势函数。在Qwen2.5-VL-7B模型上的实验表明,该方法在几何推理(Geo3K)和情感分析(EmoSet)任务中分别取得54.41%和77.86%的准确率,较基线提升显著。通过动态适配不同确定性样本的优势分配策略,MAPO有效缓解了传统GRPO方法在复杂推理任务中的优化困境,为大模型后训练优化提供了新的技术路径。
论文链接:
https://hf.co/papers/2509.18849
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.18849
(21) Multi-Agent Tool-Integrated Policy Optimization
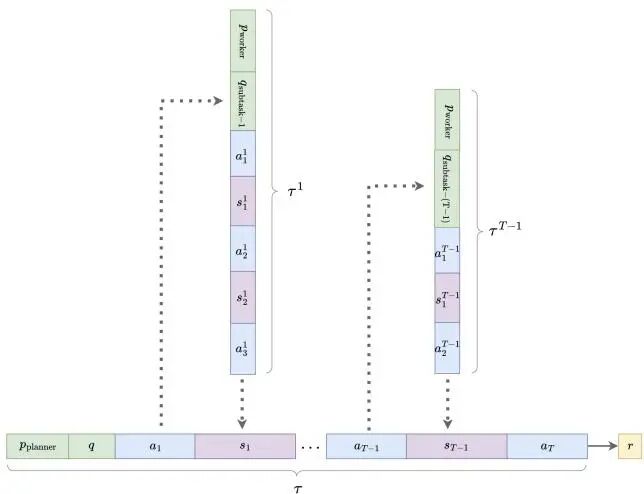
论文简介:
由Zhanfeng Mo等机构提出了Multi-Agent Tool-Integrated Policy Optimization(MATPO),该工作针对大型语言模型(LLM)在多轮工具集成规划中面临的上下文长度限制和噪声工具响应问题,提出了一种将规划者(planner)与工作者(worker)角色统一于单个LLM实例的多智能体强化学习框架。MATPO通过角色特定的提示符(role-specific prompts)激活不同智能体角色,利用强化学习实现端到端训练,避免了部署多个LLM带来的内存开销,同时保留了角色专业化优势。其核心贡献包括:1)提出基于信用分配(credit assignment)的多智能体训练机制,将规划者与工作者的轨迹联合优化;2)理论推导了多智能体情境下的Group Relative Policy Optimization(GRPO)目标函数,通过跨规划者与工作者轨迹的归一化奖励分配解决无显式奖励信号的工作者训练问题;3)在GAIA-text、WebWalkerQA和FRAMES数据集上的实验表明,MATPO相比单智能体基线平均提升18.38%的性能,并展现出更强的噪声鲁棒性;4)通过消融实验证明了用户查询重述(user query recapping)、最终摘要机制(final summary)等设计的有效性。该工作为多智能体RL训练的基础设施优化和角色分工扩展(如编码或文件处理代理)提供了实践参考与理论支持。
论文链接:
https://hf.co/papers/2510.04678
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.04678
(22) DCPO: Dynamic Clipping Policy Optimization

论文简介:
由DeepSeek-AI等机构提出的Dynamic Clipping Policy Optimization(DCPO)通过动态调整剪辑边界和优势标准化技术,有效解决了强化学习中零梯度问题。该方法引入动态剪辑策略,根据token先验概率自适应调整剪辑边界,增强低概率token的探索空间;同时采用平滑优势标准化技术,通过累积训练步骤的奖励分布优化响应级利用效率。实验显示,DCPO在四个数学推理基准测试中均取得最优表现,在Qwen2.5-Math-7B模型上AIME24基准的Avg@32指标达到38.8,显著优于GRPO(32.1)和DAPO(31.6)。在Qwen2.5-14B模型上AIME25基准的Avg@32达到19.0,较GRPO(10.5)和DAPO(15.3)有大幅提升。DCPO将非零优势比例平均提升28%,训练效率较DAPO提高一倍,token剪辑比例降低一个数量级。该方法通过动态适应token概率分布特性,在保持高置信度token更新稳定性的同时,显著增强低概率token的探索能力,同时通过累积优势标准化有效缓解高熵采样导致的训练波动问题,为大语言模型的强化学习提供了更高效的数据利用和更稳定的优化路径。
论文链接:
https://hf.co/papers/2509.02333
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.02333
(23) Diffusion Policy Policy Optimization

论文简介:
由 Princeton University、MIT、Toyota Research Institute 等机构提出的 Diffusion Policy Policy Optimization (DPPO),提出了一种基于策略梯度的扩散模型微调框架,专门用于连续控制和机器人学习任务。该方法通过将扩散模型的去噪过程建模为马尔可夫决策过程(MDP),使策略梯度更新能够有效传播奖励信号,从而在机器人操作任务中展现出优于传统强化学习方法的训练稳定性和性能表现。实验表明,DPPO 在处理长视野、稀疏奖励的复杂操作任务(如家具组装)时,不仅显著提升仿真环境中的成功率,还能实现高效的零样本跨域迁移(sim-to-real),在物理硬件上完成高精度的多阶段操作。与基于 Q-learning 的扩散模型优化方法(如 IDQL、DQL)相比,DPPO 避免了离线数据分布偏移导致的训练崩溃问题;与行为克隆结合离线数据增强的 RL 方法(如 Cal-QL、RLPD)相比,DPPO 在多模态专家数据场景下展现出更强的鲁棒性。其核心优势在于扩散模型的结构化探索能力——通过多步去噪过程保持与专家数据流形的一致性,同时利用扩散噪声的内在随机性实现高效探索。实验还揭示了 DPPO 对动作空间高维性和长序列依赖的适应性,在像素输入和状态输入的机械臂操作任务(如 Robomimic)中,DPPO-UNet 和 DPPO-MLP 均优于高斯策略和 GMM 策略,尤其在 Transport 等复杂任务中首次达到超过 90% 的成功率。此外,DPPO 的模块化设计支持灵活调整去噪步数和噪声调度策略,在训练效率与性能间取得平衡,为扩散模型在机器人序列决策任务中的应用提供了新范式。###
论文链接:
https://hf.co/papers/2409.00588
PaperScope.ai 解读:
https://paperscope.ai/hf/2409.00588
(24) Hierarchical Budget Policy Optimization for Adaptive Reasoning

论文简介:
由浙江大学、SF Technology等机构提出了Hierarchical Budget Policy Optimization (HBPO),该工作通过分层预算探索和差异化奖励机制,使模型能够根据问题复杂度自动调整推理深度,在保持甚至提升准确率的同时显著降低计算资源消耗。HBPO针对现有方法在效率训练中导致探索空间崩溃的问题,将样本划分为多个token预算子组,通过预算感知奖励函数引导模型在不同复杂度问题中分配合理计算资源。实验表明,HBPO在四个数学推理基准测试中平均token使用减少60.6%的同时提升3.14%准确率,其自适应推理行为使简单问题使用数百token而复杂任务自动扩展至数千token,验证了效率与能力协同优化的可行性。该方法通过结构化探索空间和预算差异化激励,解决了传统长度惩罚导致的推理能力退化问题,为高效推理模型设计提供了新范式。
论文链接:
https://hf.co/papers/2507.15844
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.15844
(25) Inpainting-Guided Policy Optimization for Diffusion Large Language Models

论文简介:
由Meta Superintelligence Labs、UCLA、清华大学等机构提出了Inpainting-Guided Policy Optimization(IGPO),该工作创新性地利用扩散语言模型(dLLM)的inpainting能力解决强化学习(RL)中的探索挑战。针对dLLM在复杂任务中因奖励稀疏导致的样本效率低问题,IGPO通过在生成过程中动态注入部分正确推理片段引导探索,既保留模型自主推理能力,又避免完全依赖监督学习的分布偏移。该方法在Group-relative Policy Optimization(GRPO)框架中有效缓解了"全错组"导致的零优势困境,通过熵值过滤机制稳定训练动态。结合基于重写简洁推理轨迹的长度对齐监督微调(SFT),IGPO在GSM8K、Math500和AMC数学基准上实现SOTA性能,较LLaDA-Instruct分别提升4.9%、8.4%和9.9%。实验表明IGPO可减少60%的全错组现象,同时保持生成多样性。该研究首次系统性展示了扩散模型架构特性如何赋能RL算法设计,为非自回归模型的对齐优化提供了新范式。
################# 分割行,以下为论文原始材料 #############
论文链接:
https://hf.co/papers/2509.10396
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.10396
(26) Thought-Augmented Policy Optimization: Bridging External Guidance and Internal Capabilities

论文简介:
由清华大学、上海人工智能实验室等机构提出了Thought-Augmented Policy Optimization(TAPO),该工作通过引入外部高阶思维模式增强强化学习框架,有效平衡了模型内部探索与外部指导利用。研究指出,传统RL方法(如GRPO)在训练语言模型时仅依赖奖励最大化路径,导致推理能力受限。TAPO创新性地构建了一个包含500个样本抽象出的"思维库",通过蒙特卡洛树搜索生成问题解决策略模板,并在训练过程中动态匹配新问题与最相关的思维模式,引导模型逐步推理。实验表明,TAPO在数学推理任务上实现显著突破:在AIME基准上超越GRPO 99%,AMC提升41%,Minerva Math提升17%,且在弱模型(如Llama3.2-3B)上仍保持稳定训练。该方法不仅在Qwen、Llama等多架构模型上验证有效性,更展现出优异的跨领域泛化能力,在GPQA、ARC等OOD任务上平均提升13.7%。分析显示,TAPO生成的推理过程具有更强可解释性,通过结构化思维链提升输出可读性。这项研究为构建兼具高性能与可解释性的推理模型提供了新范式,为教育、科研等复杂问题解决场景开辟了新路径。
论文链接:
https://hf.co/papers/2505.15692
PaperScope.ai 解读:
https://paperscope.ai/hf/2505.15692
(27) ASPO: Asymmetric Importance Sampling Policy Optimization

论文简介:
由快手和清华大学提出了ASPO: Asymmetric Importance Sampling Policy Optimization,该工作针对大语言模型(LLM)后训练中基于结果监督的强化学习(OSRL)方法存在的关键缺陷,提出了一种非对称重要性采样策略优化方案。研究发现,现有GRPO等OSRL方法在token级别采用的剪枝机制存在重要性采样(IS)比率失衡问题:正优势token的IS比率与更新方向呈现反直觉的负相关性,导致低概率token更新不足而高概率token过度强化,最终引发熵崩溃、重复输出和过早收敛等问题。ASPO通过反转正优势token的IS比率,使低概率token获得更强更新信号,同时引入软双重剪枝机制稳定极端更新。在数学推理和代码生成任务上的实验表明,ASPO相比GRPO基线方法显著提升了训练稳定性(熵值下降更平缓、重复率增长降低40%),最终性能在AIME25等基准上提升12.5%,代码任务平均pass@8指标提升31.0%。该方法揭示了OSRL中token权重分配的关键作用,为LLM强化学习的优化机制提供了新的理论视角和实践方案。
################# 分割行,以下为论文原始材料 #############
ASPO的核心创新在于识别并修正了GRPO算法中正优势token的IS比率错配问题。传统PPO剪枝机制设计初衷是通过IS比率校正分布差异,但在OSRL场景下,这种机制反而导致正优势token的更新权重与概率呈正相关(高概率token权重更大),与负优势token的负相关特性形成矛盾。ASPO通过三步策略解决该问题:保留原始剪枝机制,反转正优势token的IS比率计算,对极端值采用软双重剪枝。理论分析表明,该方法使梯度更新与token概率呈负相关,有效平衡了token级权重分配。实验采用1.5B参数的DeepSeek-R1模型,在数学(AIME/AMC/MATH等)和代码(LiveCodeBench)任务上全面超越DAPO、DeepScaleR等先进方法,其中数学平均得分提升5.8%,代码pass@8指标提升31.0%。消融实验显示,反转正优势token权重后训练熵值下降速度降低60%,重复率增长曲线趋于平缓,验证了方法的有效性。该研究为LLM强化学习的权重分配机制提供了重要洞见,但目前实验仅在1.5B模型上验证,其在更大规模模型或PPO类算法中的适用性仍需进一步探索。
论文链接:
https://hf.co/papers/2510.06062
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.06062
(28) Sample More to Think Less: Group Filtered Policy Optimization for Concise Reasoning

论文简介:
由Microsoft Research和University of Wisconsin-Madison等机构提出的GFPO(Group Filtered Policy Optimization)通过增加训练时采样数量并结合响应过滤机制,有效解决了大语言模型在强化学习训练中出现的响应长度膨胀问题。该方法在训练过程中对每个问题采样更多候选响应(G=16-24),并通过长度和token效率(reward/length)两个指标进行过滤,仅保留前k个最优响应用于策略梯度计算。实验表明,GFPO在保持GRPO模型推理准确性的前提下,显著降低了响应长度:在AIME25、AIME24、GPQA、Omni-MATH和LiveCodeBench等基准测试中,GFPO将GRPO的长度膨胀减少了46-85%。其中Token Efficiency优化策略通过奖励-长度比指标,实现了最大幅度的长度压缩(70.9-84.6%),而自适应难度GFPO则通过动态调整不同难度问题的保留响应数量(k值),在保持准确性的同时优化了计算资源分配。特别值得注意的是,GFPO在保持AIME25 70.8%最高准确率的同时,将平均响应长度从GRPO的14.8k tokens压缩至12.8k tokens。该方法通过训练时增加计算量换取推理时的效率提升,展示了训练-推理计算成本转换的有效性,为高效推理模型开发提供了新思路。
论文链接:
https://hf.co/papers/2508.09726
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09726
(29) Truncated Proximal Policy Optimization

论文简介:
由 ByteDance Seed 等机构提出了 Truncated Proximal Policy Optimization(T-PPO),该工作针对传统 Proximal Policy Optimization(PPO)在长序列推理任务中训练效率低下的问题,提出了一种基于截断响应生成的高效策略优化框架。T-PPO 通过两项核心创新提升训练效率:一是提出 Extended Generalized Advantage Estimation(EGAE)方法,首次实现对不完整响应的优势函数估计,使策略更新可在响应生成过程中动态进行;二是设计了策略模型与价值模型的独立优化机制,通过筛选 prompt 和截断 token 减少冗余计算,在保证收敛性能的前提下显著加速训练。实验表明,在 AIME 2024 数学推理基准测试中,基于 Qwen2.5-32B 模型的 T-PPO 相比现有最优方法将训练效率提升 2.5 倍,同时实现 62 pass@1 的性能突破。该方法通过动态截断生成窗口和渐进式策略更新,有效解决了 PPO 在长链推理任务中硬件利用率低、等待时间长的核心瓶颈,为大规模语言模型的高效训练提供了新的技术路径。
论文链接:
https://hf.co/papers/2506.15050
PaperScope.ai 解读:
https://paperscope.ai/hf/2506.15050
(30) Truncated Proximal Policy Optimization

论文简介:
由字节跳动等机构提出了Truncated Proximal Policy Optimization(T-PPO),该工作针对传统PPO在长序列推理训练中的低效问题,通过动态截断响应生成和改进优势估计方法,显著提升大语言模型的训练吞吐量。T-PPO的核心创新包含两方面:首先提出Extended Generalized Advantage Estimation(EGAE)方法,通过引入截断轨迹的优势估计机制,使策略更新可在响应生成过程中动态进行,突破传统PPO必须等待完整轨迹的限制;其次设计了策略模型与价值模型的独立优化机制,通过选择性过滤训练token实现两者的并行更新,在保持价值函数无偏估计的同时减少冗余计算。实验基于AIME 2024数学推理基准和32B参数规模的Qwen2.5模型展开,结果显示T-PPO在保持62 pass@1高分的同时,相较于当前最优同步算法实现2.5倍训练加速。该方法通过动态截断策略将GPU利用率提升至传统PPO的3倍,并在响应长度演化分析中展现出更强的长链推理能力,为大规模强化学习在专业领域模型训练中的应用提供了高效解决方案。
论文链接:
https://hf.co/papers/2506.1505
PaperScope.ai 解读:
https://paperscope.ai/hf/2506.1505
(31) Lean and Mean: Decoupled Value Policy Optimization with Global Value Guidance

论文简介:
由复旦大学与微软等机构提出了Decoupled Value Policy Optimization (DVPO),该工作提出了一种轻量级的强化学习框架,通过预训练全局价值模型替代传统奖励模型,有效降低计算复杂度并提升训练稳定性。针对大语言模型对齐中PPO算法存在的演员-评论家耦合训练导致的内存占用高、训练不稳定等问题,DVPO通过冻结预训练的全局价值模型(GVM)提供token级回报预测,解耦价值估计与策略优化过程,在无真实环境奖励反馈的场景下实现性能突破。理论分析证明在无新奖励数据时,预训练奖励模型与价值模型具有等效指导能力。实验表明DVPO在MT-Bench、Alpaca-Eval等基准测试中超越DPO等高效方法,与SOTA PPO性能相当,同时降低40%显存占用和35%训练时间,显著提升大规模语言模型微调的可扩展性与稳定性。该方法通过离线数据预训练价值模型实现细粒度监督信号传递,为强化学习在NLP领域的高效应用提供了新范式。
论文链接:
https://hf.co/papers/2502.16944
PaperScope.ai 解读:
https://paperscope.ai/hf/2502.16944
(32) Dataset Reset Policy Optimization for RLHF

论文简介:
由Cornell University和Princeton University等机构提出了Dataset Reset Policy Optimization (DR-PO),该工作通过利用生成模型的重置能力,将离线偏好数据集整合到在线策略训练中,实现了强化学习从人类反馈(RLHF)的理论保证和性能提升。DR-PO算法在每次在线数据收集时,直接重置策略优化器到离线数据集中的状态而非初始状态分布,通过KL正则化确保策略不偏离离线数据覆盖范围。理论方面,DR-PO在一般函数近似下证明了有限样本复杂度,能够学习到至少与离线数据中任何策略同样优的策略。实验表明,在TL;DR摘要和Anthropic HH数据集上,DR-PO的生成质量在GPT4胜率指标上超越了PPO和DPO基线,且在零样本迁移任务中保持优势,同时计算开销与PPO相当。该方法的核心创新在于通过数据集重置实现离线与在线数据的高效融合,为RLHF提供了兼具理论严谨性和工程实用性的新范式。
论文链接:
https://hf.co/papers/2404.08495
PaperScope.ai 解读:
https://paperscope.ai/hf/2404.08495
(33) TAROT: Task-Oriented Authorship Obfuscation Using Policy Optimization Methods

论文简介:
由Hornetsecurity和法国里尔大学等机构提出了TAROT(Task-Oriented Authorship Obfuscation Using Policy Optimization),该工作针对作者身份混淆任务提出了一种基于策略优化的新型方法。研究旨在解决传统方法中隐私保护与文本效用难以平衡的问题,通过重构整个文本内容以优化下游任务效用。TAROT采用监督微调(SFT)结合策略优化(PO)框架,利用Proximal Policy Optimization(PPO)和Direct Preference Optimization(DPO)两种算法,通过预训练的句子嵌入模型构建隐私与效用双目标奖励函数:LUAR模型用于检测作者身份特征,GTE模型确保文本语义一致性。在IMDb影评、博客文章和学术文本三个数据集上的实验表明,TAROT在显著降低作者身份识别准确率(最高下降82.46%)的同时,保持了较高的任务效用(如情感分类、主题分类等)。值得注意的是,该方法在面对包含原始文本和混淆文本混合训练的增强型攻击时仍保持鲁棒性,且生成的混淆文本可用于重新训练下游任务模型并提升性能。作为首个将策略优化应用于作者身份混淆的工作,TAROT通过无监督方式实现了开放世界场景下的隐私保护,为文本匿名化提供了兼顾实用性与安全性的新范式,其代码和模型已公开供研究使用。
论文链接:
https://hf.co/papers/2407.2163
PaperScope.ai 解读:
https://paperscope.ai/hf/2407.2163
(34) ReDit: Reward Dithering for Improved LLM Policy Optimization

论文简介:
由上海人工智能实验室等机构提出的ReDit(Reward Dithering)方法,通过向离散奖励信号中注入随机噪声来优化大语言模型(LLM)的策略训练。该工作针对当前LLM强化学习中广泛采用的离散奖励(如二元正确性奖励)导致的梯度消失、梯度爆炸及收敛缓慢问题,提出在GRPO等算法的奖励计算中引入零均值高斯或均匀噪声,将硬边界奖励转化为连续梯度信号。实验表明,ReDit在数学推理(GSM8K、MATH)和几何推理(Geometry3K)任务上,使Qwen2.5、Llama3等模型的训练效率提升10倍(仅需10%训练步数即超越基线9000步性能),最终准确率提升0.7-4.5个百分点。理论分析证明该方法保持了梯度无偏性,通过增加奖励方差缓解梯度消失/爆炸,并加速收敛下界。消融实验验证了噪声方差需适中(如高斯噪声标准差0.05时效果最佳),且仅对离散奖励有效(对连续奖励无效)。该方法在DAPO、Dr.GRPO等算法上均取得显著改进,同时支持余弦逆序等动态噪声调度策略进一步优化性能,为离散奖励优化提供了简洁有效的解决方案。
论文链接:
https://hf.co/papers/2506.18631
PaperScope.ai 解读:
https://paperscope.ai/hf/2506.18631
(35) Iterative Nash Policy Optimization: Aligning LLMs with General Preferences via No-Regret Learning
论文简介:
由伊利诺伊大学和腾讯AI实验室提出了Iterative Nash Policy Optimization(INPO),该工作提出了一种基于博弈论的在线算法,通过无遗憾学习实现大语言模型与通用偏好的对齐。传统强化学习与人类反馈(RLHF)方法依赖Bradley-Terry(BT)模型假设,但该假设存在传递性限制且难以捕捉复杂人类偏好。INPO将问题建模为双人零和博弈,通过策略自我对抗学习Nash均衡策略,避免了BT模型的局限性。核心创新在于设计了无需计算期望胜率的新型损失函数,直接在偏好数据集上优化策略。算法基于在线镜像下降(OMD)框架,理论证明其迭代复杂度为,并实现最后一轮迭代的收敛速率。实验采用LLaMA-3-8B-SFT模型作为基线,在AlpacaEval 2.0和Arena-Hard v0.1基准测试中分别取得42.6%和37.8%的胜率,较当前最优在线RLHF算法提升27.7%以上。该方法在保持KL正则化防止策略偏移的同时,通过tournament策略降低偏好查询复杂度至,在学术基准测试中也展现出推理能力提升。研究突破了BT模型的理论限制,为大模型对齐提供了新的博弈论视角和高效实现方案。
论文链接:
https://hf.co/papers/2407.00617
PaperScope.ai 解读:
https://paperscope.ai/hf/2407.00617
(36) GeometryZero: Improving Geometry Solving for LLM with Group Contrastive Policy Optimization

论文简介:
由复旦大学等机构提出了GeometryZero,该工作针对大语言模型在几何问题解决中辅助构造使用的关键挑战,提出了一种新型强化学习框架Group Contrastive Policy Optimization(GCPO)。研究发现现有方法或依赖超大模型(如GPT-4o)导致计算成本高昂,或因无条件奖励机制导致辅助构造滥用。GCPO通过两项创新突破:1)组对比掩码机制,根据辅助构造在具体问题中的效用动态提供正负奖励信号;2)长度奖励机制鼓励更深入的推理链。基于GCPO开发的GeometryZero系列模型(1.5B-7B参数)在Geometry3K、MathVista等基准测试中平均提升4.29%,显著优于GRPO等基线方法。实验表明,该方法在保持计算效率的同时,通过智能判断辅助构造的使用时机,有效平衡了工具调用的收益与成本,为轻量级模型实现高水平几何推理提供了新范式。消融研究验证了组对比掩码和长度奖励的协同作用,响应长度分析揭示了模型在训练中从模式学习到深度推理的动态演变过程。
论文链接:
https://hf.co/papers/2506.07160
PaperScope.ai 解读:
https://paperscope.ai/hf/2506.07160
(37) LSPO: Length-aware Dynamic Sampling for Policy Optimization in LLM Reasoning

论文简介:
由南加州大学和加州大学尔湾分校等机构提出的LSPO(Length-aware Dynamic Sampling for Policy Optimization),是一种基于响应长度信号的动态采样策略,用于提升大语言模型(LLM)在推理任务中的策略优化效果。该工作通过动态筛选训练数据中的极端长度响应(最短和最长),引导模型在保留高效推理路径的同时优化复杂问题的处理能力,从而显著提高最终模型的测试准确率。研究团队在多个基准模型(如Qwen-2.5-Math-7B、Llama-3.2-4B-Instruct)和数据集(DAPO-17K、MATH)上验证了LSPO的有效性,实验表明其与GRPO、DAPO等主流RLVR算法结合时,平均准确率提升约0.7%-1.9%,且在相同训练时间内保持效率优势。此外,论文通过系统性消融研究揭示了长度信号筛选策略的设计原则:保留响应长度分布两端数据(如前30%最短和65%-95%最长)效果最佳,而基于固定阈值或中间长度的筛选则效果显著下降。研究还指出,未来可通过预测响应长度或结合自适应阈值进一步优化采样效率。LSPO为动态数据筛选提供了新视角,证明了长度信号在提升模型推理能力中的关键作用,为后续研究开辟了结合任务特性设计采样策略的方向。
论文链接:
https://hf.co/papers/2510.01459
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.01459
(38) Slow-Fast Policy Optimization: Reposition-Before-Update for LLM Reasoning

论文简介:
由Ziyan Wang等机构提出了Slow-Fast Policy Optimization(SFPO),该工作针对大型语言模型(LLM)推理中强化学习训练的不稳定性问题,提出了一种三阶段更新框架。SFPO通过将每个训练步骤分解为快速轨迹、重新定位和慢速校正三个阶段,在保持现有策略梯度方法目标函数和rollout生成不变的前提下,显著提升了训练稳定性与样本效率。具体而言,快速轨迹阶段通过在同一批数据上执行多次梯度更新来稳定搜索方向;重新定位阶段通过参数插值控制策略偏离程度;慢速校正阶段则通过额外梯度更新对齐局部曲率。实验表明,SFPO在数学推理基准测试中相较GRPO方法平均提升2.80分,同时减少4.93倍的rollout次数和4.19倍的训练时间。该方法通过结构化更新轨迹,在不增加额外计算开销的情况下有效缓解了早期训练中的梯度噪声问题,为提升LLM推理能力提供了高效可扩展的优化方案。
论文链接:
https://hf.co/papers/2510.04072
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.04072
(39) GeometryZero: Improving Geometry Solving for LLM with Group Contrastive Policy Optimization

论文简介:
由复旦大学等机构提出了GeometryZero,该工作针对几何问题求解中辅助构造使用的痛点,提出Group Contrastive Policy Optimization(GCPO)框架,通过组对比掩码和长度奖励机制优化轻量级语言模型的几何推理能力。研究发现传统强化学习方法在几何推理中存在无条件奖励导致的无效辅助构造问题,而GCPO通过动态评估辅助构造的效用,为不同场景提供正/负奖励信号,并引入长度奖励鼓励深度推理链生成。基于此框架开发的GeometryZero系列模型(1.5B-7B参数)在Geometry3K、MathVista等基准测试中平均提升4.29%,在7B规模下实现18.23%的Geomverse准确率,显著优于GRPO和ToRL方法。实验表明GCPO能自主判断辅助构造的适用场景,通过对比组rollout的准确率差异动态调整奖励策略,其掩码机制使辅助构造在60%训练样本中被激活。该研究为轻量级模型实现高效几何推理提供了新范式,为教育领域低成本AI应用落地奠定基础。
论文链接:
https://hf.co/papers/2506.0716
PaperScope.ai 解读:
https://paperscope.ai/hf/2506.0716
(40) Segment Policy Optimization: Effective Segment-Level Credit Assignment in RL for Large Language Models
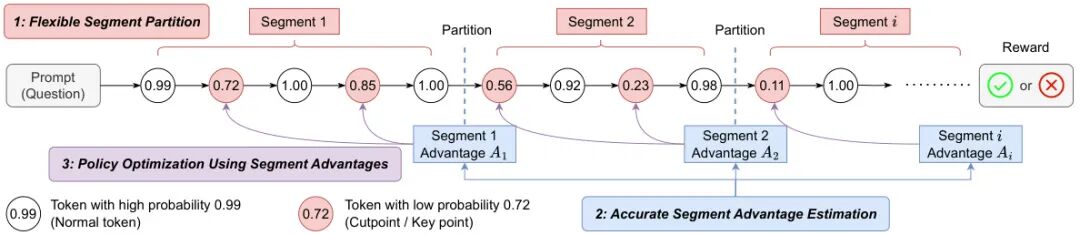
论文简介:
由中科院软件所、国科大和香港城市大学等机构提出了Segment Policy Optimization(SPO),该工作针对大语言模型(LLM)强化学习训练中的信用分配难题,提出了一种基于中间粒度的段级优势估计框架。现有方法在token-level(如PPO)和trajectory-level(如GRPO)存在各自缺陷:前者依赖不稳定的价值函数估计,后者因粗粒度导致信用分配不精准。SPO通过灵活分段策略将序列划分为连续片段,结合蒙特卡洛采样直接估计段级优势,既避免了价值函数偏差,又实现了比轨迹级更细粒度的反馈。框架包含三个核心组件:自适应分段(支持固定步长或基于低概率token的cutpoint策略)、段优势估计(链式采样或树状结构重用样本)以及带概率掩码的策略优化(聚焦关键token更新)。针对短链推理场景的SPO-chain采用cutpoint分段和链式优势估计,在GSM8K上比PPO/GRPO提升6-12个百分点;针对长链推理的SPO-tree通过树状采样结构显著降低计算成本,在MATH500 2K/4K上下文评估中比GRPO提升7-11个百分点。实验还表明SPO在有限上下文窗口下表现出更强的token效率,其代码已开源。
论文链接:
https://hf.co/papers/2505.23564
PaperScope.ai 解读:
https://paperscope.ai/hf/2505.23564
(41) From Uniform to Heterogeneous: Tailoring Policy Optimization to Every Token's Nature

论文简介:
由北京大学、上海人工智能实验室等机构提出的Heterogeneous Adaptive Policy Optimization (HAPO),针对现有强化学习算法在大语言模型优化中忽略令牌异质性的问题,提出了一套基于令牌熵值的动态优化框架。该工作通过系统分析熵值与训练动态的关系,揭示了统一优化策略在探索-利用平衡、优势计算和剪辑损失三个阶段的缺陷,并设计了四项针对性改进:1) 自适应温度采样通过动态调整高熵令牌的采样温度,在保持语义连贯性的同时增强关键推理节点的探索;2) 令牌级组平均优势计算通过跨令牌归一化解决序列长度偏差问题,确保正负样本梯度平衡;3) 差异优势重分配结合熵值与重要性比率信号,对高熵令牌进行优势放大而低熵令牌进行抑制;4) 非对称自适应剪辑通过差异化剪辑边界,允许低熵令牌更激进的概率衰减并促进高熵令牌的探索。实验表明,HAPO在Qwen2.5-Math-1.5B到Qwen3-8B等多尺度模型上,相较DAPO基准在AIME24、AIME25等数学推理任务中提升1.97-3.07个百分点,且计算开销可忽略。该工作通过连续熵值信号实现细粒度优化,证明了令牌异质性建模对提升模型推理能力的重要性,为构建更符合语言生成结构的优化算法提供了新方向。
论文链接:
https://hf.co/papers/2509.16591
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.16591
(42) TGPO: Temporal Grounded Policy Optimization for Signal Temporal Logic Tasks

论文简介:
由MIT研究团队提出的TGPO(Temporal Grounded Policy Optimization),针对复杂长时域的信号时序逻辑(STL)任务规划问题,提出了一种分层强化学习框架。该工作通过将STL公式分解为有时限的子目标和不变约束,构建了包含高层时间变量分配与低层时序策略网络的双层优化架构。核心创新在于:1)提出STL公式分解方法,将复杂时序逻辑转化为可执行的可达性子目标和避障约束;2)设计了基于批评家引导的贝叶斯时间变量采样机制,通过Metropolis-Hastings算法高效搜索可行时间分配方案;3)构建了包含时间变量、进度索引和约束满足状态的增强状态空间,配合分阶段奖励函数设计,解决了STL任务的稀疏奖励问题;4)在五类不同维度的仿真环境中(包括2D线性系统、四旋翼无人机和29自由度四足机器人),TGPO在多层嵌套STL任务上平均成功率达86.46%,较现有方法提升31.6%,尤其在高维长时域任务中表现显著优势。该方法通过显式的时间变量建模和分层优化策略,为解决复杂时序逻辑任务提供了新的技术路径,同时通过可视化分析展示了策略的多模态行为特性。
论文链接:
https://hf.co/papers/2510.00225
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.00225