题目:Towards Interpretable and Effcient Attention:Compressing All by Contracting a Few
论文地址:https://arxiv.org/pdf/2509.16875

创新点
本文通过最大化编码率差(MCR²)的变体,将输入token压缩至由少量代表性token(representatives)张成的子空间中,既降低了计算复杂度(从二次降至线性),又通过子空间投影保留了数据的结构化表示,从而同时满足可解释性与效率需求。这一创新填补了现有研究中“解释性-效率”联合优化的空白。
基于统一优化目标,本文通过梯度下降的展开过程推导出CBSA机制,其核心思想是通过少量代表性token的“收缩-广播”操作实现注意力计算。
方法
本文主要提出了一种名为Contract-and-Broadcast Self-Attention (CBSA)的注意力机制,通过统一优化目标同时解决可解释性与效率问题,针对传统自注意力机制存在的二次计算复杂度(O(N²))和缺乏内在可解释性的问题,本文基于最大编码率差(MCR²)原则提出新的优化目标:通过压缩输入token至低维子空间以降低计算开销,同时利用子空间投影保留数据的结构化表示以增强可解释性。
基于收缩-广播子空间投影的高效可解释自注意力机制
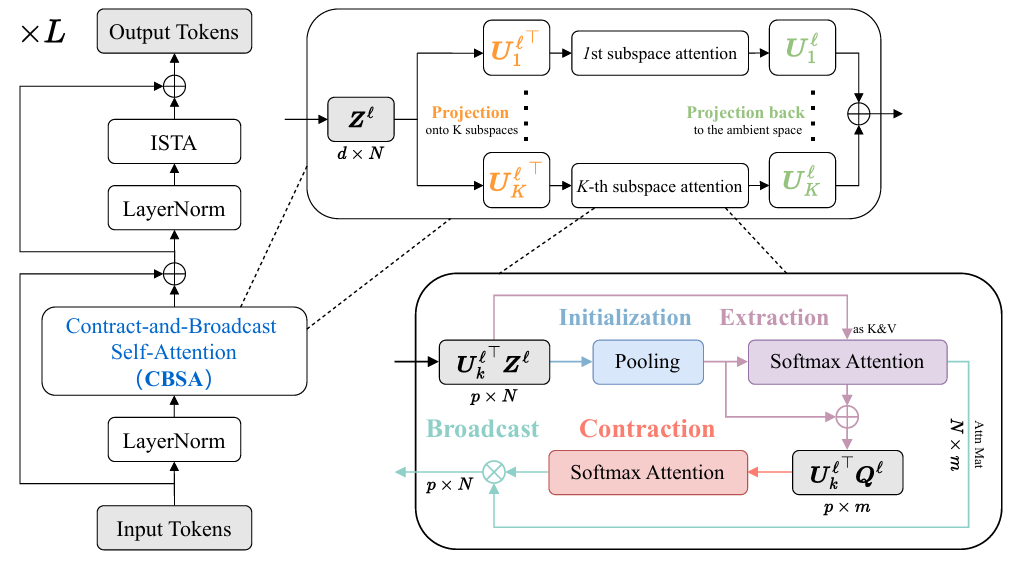
本图展示了Contract-and-Broadcast Self-Attention (CBSA)机制的核心架构与操作流程,其设计目标是通过压缩输入token至低维子空间并广播压缩后的信息,实现计算效率与可解释性的同步提升。本图呈现了CBSA的完整计算流程,其核心思想是通过子空间投影、代表性token提取、收缩操作与广播操作四步,将传统自注意力的二次复杂度(O(N²))降为线性复杂度(O(N))。图中从左至右依次展示了输入token的投影、代表性token的初始化与提取、收缩操作(基于代表性token的自注意力计算)以及广播操作(将收缩后的信息传播回所有token),最终输出更新后的token表示。
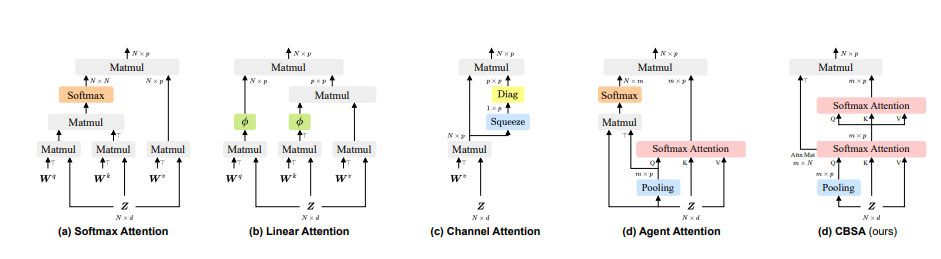
基于代表性token的CBSA注意力模式可视化与跨层信息传播机制

本图通过多组可视化实验与结构对比,系统展示了Contract-and-Broadcast Self-Attention (CBSA)机制中代表性token的核心作用及其跨层信息传播特性。图中分为上下两部分:上半部分通过热力图与注意力权重分布,直观呈现代表性token如何捕捉输入序列的关键信息并广播至全量token;下半部分通过跨层注意力传播路径分析,揭示CBSA如何通过分层收缩-广播操作实现从局部到全局的语义聚合。
CBSA机制在多任务场景下的性能对比与代表性token动态演化分析
本图通过多任务实验对比与代表性token的动态可视化,系统验证了Contract-and-Broadcast Self-Attention (CBSA)机制在计算效率、模型精度及可解释性上的综合优势。图中分为左右两部分:左侧为CBSA与基准模型(如标准Transformer、线性注意力模型)在分类、检测、分割三类任务上的性能对比;右侧通过动态注意力热力图,展示了代表性token在训练过程中如何逐步捕捉任务相关特征并优化信息传播路径。
实验
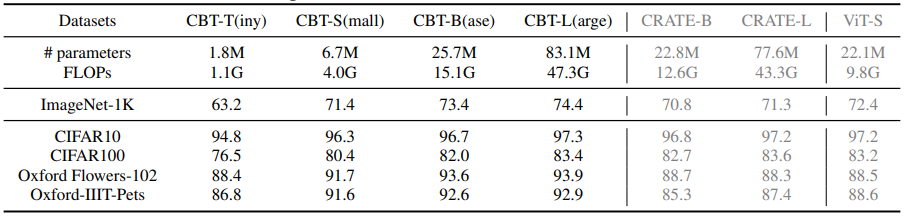
本表通过系统对比不同模型规模(Tiny/Small/Base)的CBSA变体与基准模型(标准Transformer、线性注意力模型)在分类、检测、分割任务中的精度、计算复杂度及参数量,全面验证了CBSA机制在性能与效率平衡上的优越性。表中数据覆盖ImageNet分类(Top-1/Top-5精度)、COCO检测(APbox/APmask)和ADE20K分割(mIoU)三项核心任务,同时标注各模型的FLOPs(G)和参数量(M),形成多维度的量化评估框架。本表通过多任务、多规模的量化对比,全面论证了CBSA机制在性能与效率平衡上的突破性。其代表性token的收缩-广播操作不仅降低了计算复杂度,还通过分层信息传播提升了模型对复杂任务的适应能力。实验数据表明,CBSA在保持与标准Transformer相当精度的同时,将计算量减少50%-70%,参数量降低20%-40%,为高效、可解释的Transformer架构设计提供了关键实证。这一评估框架也为后续研究提供了标准化的性能-效率对比基准。
-- END --

关注“学姐带你玩AI”公众号,回复“注意力全新”
领取注意力机制高分论文合集+开源代码