当你在使用AI代码助手时,是否遇到过它无法适配新开发工具的窘境?当医疗AI面对突发公共卫生事件的新型症状数据时,是否因模型固化而难以快速响应?
这些问题的核心症结在于:当前主流AI智能体多依赖人工配置,部署后便陷入“一劳永逸”的静态困境,无法随环境动态演进。
而近日挂在arXiv上的综述论文《A Comprehensive Survey of Self-Evolving AI Agents》,为解决这一难题提供了系统性方案。来自格拉斯哥大学、谢菲尔德大学、剑桥大学等机构的研究团队,不仅首次明确了“自进化AI智能体”的定义与核心原则,更构建了从技术框架到落地场景的完整图谱。
论文链接:https://arxiv.org/pdf/2508.07407v2
项目主页:https://github.com/EvoAgentX/Awesome-Self-Evolving-Agents


为什么需要自进化AI智能体?
在大语言模型(LLMs)爆发式发展的今天,AI智能体已在代码生成、科学研究、医疗诊断等领域展现出强大能力。但论文指出,当前AI智能体系统存在一个根本性局限:过度依赖人工设计的静态配置。
以客服AI为例,当企业推出新产品或更新服务政策时,工程师需要重新调整提示词、更新知识库,整个过程耗时且难以覆盖所有边缘场景;在科学研究领域,AI助手若要整合新发表的算法或分析工具,往往需要重新训练或微调模型,成本极高。这些问题的根源在于,现有智能体的架构、功能和策略在部署后便固定不变,无法自主适应动态环境。
“真实世界的变化是持续的——用户需求会迭代、工具会更新、任务边界会拓展,”论文作者之一、格拉斯哥大学研究员Jinyuan Fang表示,“我们需要一种能像人类一样‘边做边学’的AI系统,这就是自进化AI智能体的核心目标。”
为了明确这一新型智能体的边界,论文给出了严格定义:自进化AI智能体是通过与环境交互,持续且系统性地优化内部组件,以适应任务、上下文和资源变化,同时保障安全性与性能提升的自主系统。不同于传统智能体的“被动响应”,自进化智能体具备“主动迭代”的能力,其本质是衔接基础模型的静态能力与终身智能系统的动态需求。
三大定律与四阶段演进:自进化AI的底层逻辑
要实现“安全且高效”的自进化,论文借鉴阿西莫夫“机器人三定律”的层级思想,提出了自进化AI智能体三定律,为技术发展划定了不可逾越的红线:
存续定律(Endure):任何修改过程中,智能体必须维持安全与稳定性,不得出现有害行为或系统崩溃; 卓越定律(Excel):在满足第一定律的前提下,智能体需保持或提升现有任务性能,避免进化导致“能力退化”; 进化定律(Evolve):在遵守前两定律的基础上,智能体需自主优化内部组件,以响应环境变化。
这三大定律并非抽象原则,而是贯穿技术设计的具体约束。例如,在优化智能体的工具使用策略时,首先需通过安全沙箱验证新策略的合规性(第一定律),再通过测试集验证性能是否提升(第二定律),最后才允许策略上线迭代(第三定律)。
在此基础上,论文梳理了LLM驱动智能体的四阶段演进历程,清晰展现了从静态到自进化的技术跃迁:

四组件反馈循环:自进化AI的统一技术框架
为了让不同领域的研究者有统一的分析视角,论文提出了“系统输入-智能体系统-环境-优化器”四组件反馈循环框架,这也是整篇综述的核心理论贡献之一。
这个框架的运作逻辑可概括为:系统输入定义任务需求,智能体系统执行任务,环境提供反馈信号,优化器基于反馈迭代优化智能体,形成闭环。
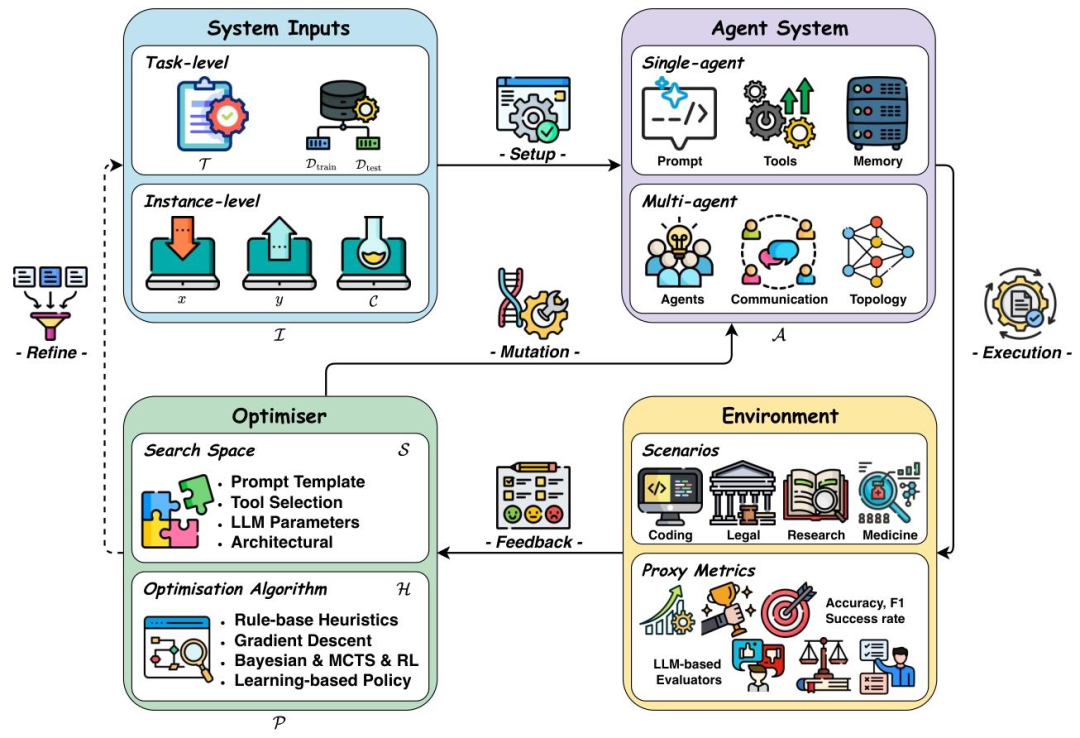
四个组件的具体功能如下:
1. 系统输入:定义“进化目标”
系统输入是智能体进化的“导航图”,决定了优化的方向和范围,分为两类:
任务级输入:针对特定任务的整体优化,例如“代码生成任务”的输入包括任务描述(“生成符合Python规范的排序算法”)、训练数据集(含正确代码样本)和测试数据集(验证优化效果); 实例级输入:针对单个任务实例的精细优化,例如“为用户生成个性化旅行计划”的输入包括用户需求(“3天北京亲子游”)、历史交互记录(用户偏好游乐园)和上下文信息(避开周末高峰)。
论文指出,实例级输入是当前研究的热点——它能让智能体针对具体场景动态调整策略,例如面对医学诊断中的疑难病例时,智能体可基于该病例的特殊症状优化推理路径。
2. 智能体系统:进化的“核心载体”
智能体系统是优化的直接对象,可分为单智能体和多智能体两种形态:
单智能体:由基础模型(如GPT-4、Llama 3)、提示(任务指令)、记忆(上下文存储)、工具(外部API调用)等组件构成。例如,代码生成智能体的基础模型负责逻辑推理,记忆模块存储历史代码片段,工具模块调用编译器验证代码正确性; 多智能体:由多个单智能体、通信协议和拓扑结构组成。例如,医疗诊断多智能体系统中,“症状分析智能体”“影像识别智能体”“治疗方案智能体”通过标准化协议交换数据,拓扑结构决定信息流动路径(如分层传递或并行协作)。
3. 环境:提供“进化反馈”
环境不仅是智能体的运行场景,更是提供反馈信号的“裁判”。论文将环境反馈分为两类:
客观反馈:可量化的性能指标,例如代码生成的测试用例通过率、医疗诊断的准确率、网页导航的任务完成时间; 主观反馈:需通过LLM评估的质性指标,例如生成文本的逻辑性、对话的连贯性、法律文档的合规性。
在缺乏ground-truth的场景(如创意写作、科学假说生成),主观反馈尤为重要。论文提到,目前常用“LLM-as-a-Judge”方案,让专业领域的LLM(如法律领域的LegalGPT)对智能体输出打分,作为优化依据。
4. 优化器:实现“进化操作”
优化器是智能体进化的“引擎”,负责基于环境反馈找到最优配置,由“搜索空间”和“优化算法”两部分组成:
搜索空间:定义“可优化的对象”,例如单智能体的搜索空间包括提示模板、记忆存储结构、工具选择列表;多智能体的搜索空间包括智能体数量、通信链路、协作策略; 优化算法:定义“如何搜索最优配置”,常用算法包括梯度下降(适用于连续参数,如模型权重)、强化学习(适用于序列决策,如工具使用策略)、进化算法(适用于离散空间,如提示生成)、蒙特卡洛树搜索(适用于复杂推理,如多步骤任务规划)。
“这个框架的价值在于,它将不同场景的自进化技术统一到同一逻辑下,”论文通讯作者、格拉斯哥大学Zaiqiao Meng教授解释道,“无论是优化代码智能体的提示,还是调整医疗多智能体的拓扑,都可通过‘定义输入→设计系统→获取反馈→选择算法’的流程实现。”
从单智能体到多智能体:自进化的核心技术拆解
基于上述框架,论文系统梳理了当前自进化AI的技术体系,涵盖单智能体优化、多智能体优化和领域特定优化三大方向,每个方向都有明确的技术路径和代表性研究。
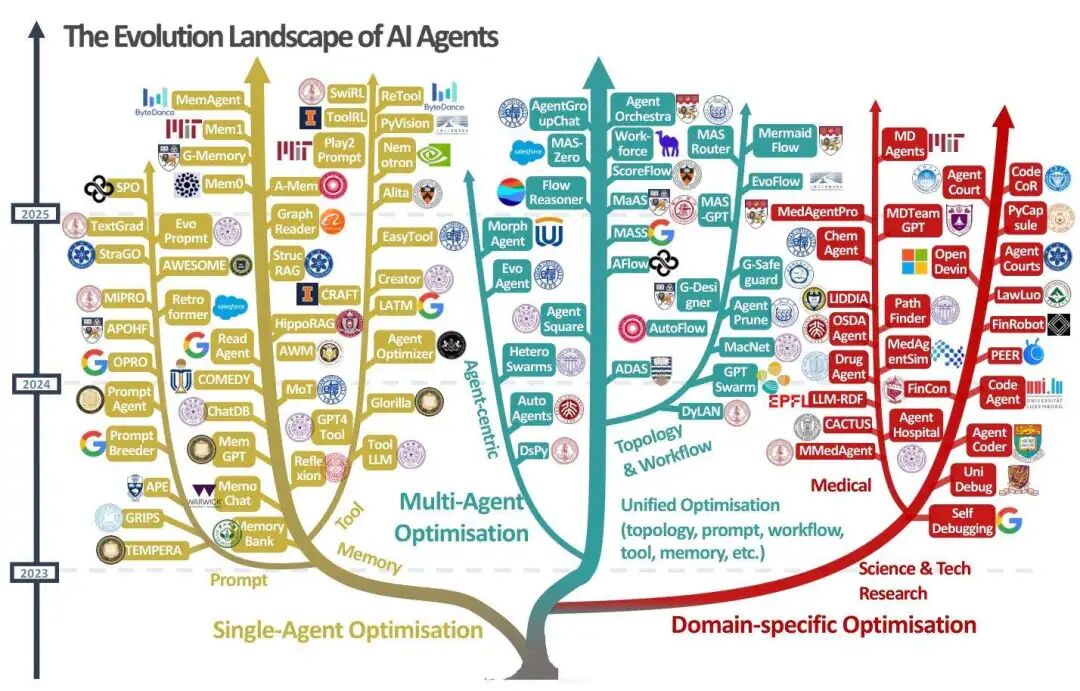
1. 单智能体优化:从“组件升级”到“能力跃升”
单智能体是自进化技术的基础,论文将其优化技术分为四类,分别针对智能体的核心组件:
(1)LLM行为优化:提升“大脑”的推理能力
LLM是智能体的“大脑”,其推理和规划能力直接决定智能体性能。论文将LLM行为优化分为两类:
训练式优化:通过数据反馈更新模型参数,例如STaR(Self-Training with Reasoning)框架让模型生成推理轨迹,筛选正确轨迹进行微调,逐步提升数学推理能力;DeepSeek-Prover则通过定理证明助手的反馈,用强化学习优化模型的形式化证明生成能力; 推理时优化:不修改模型参数,通过推理策略提升性能,例如Tree-of-Thoughts将推理过程建模为树结构,用蒙特卡洛树搜索(MCTS)探索多个推理路径;Graph-of-Thoughts则将中间推理结果作为图节点,通过图操作(如合并、修剪)优化推理效率。
论文指出,推理时优化是当前的研究重点——它无需大量训练数据,且能适配API调用的闭源模型(如GPT-4),例如CodeT工具通过编译器反馈修正代码生成错误,无需微调模型。

(2)提示优化:打造“精准指令”
LLM对提示极为敏感,微小的表述变化可能导致输出质量大幅波动。论文总结了四类提示优化技术:
编辑式优化:在人工编写的基础提示上迭代修改,例如GRIPS(Gradient-free, Edit-based Instruction Search)将提示拆分为短语,通过删除、替换、添加等操作优化; 生成式优化:让LLM自主生成新提示,例如OPRO(Optimized Prompt Retrieval and Optimization)框架用LLM生成多个提示候选,结合评估分数选择最优; 文本梯度式优化:用自然语言反馈引导提示调整,例如TextGrad将LLM的评估(“这个提示缺乏步骤指引”)转化为“文本梯度”,指导提示添加“分步骤执行”指令; 进化式优化:用进化算法优化提示种群,例如PromptBreeder通过“变异”(修改提示片段)、“交叉”(合并两个提示的优势部分)、“选择”(保留高绩效提示),逐步提升提示质量。
(3)记忆优化:解决“短期失忆”难题
LLM的上下文窗口限制(如GPT-4 Turbo为128k tokens)是智能体的重要瓶颈,论文将记忆优化分为短期和长期两类:
短期记忆优化:优化当前任务的上下文管理,例如MemoChat通过对话摘要压缩历史信息,在有限窗口内保留关键内容;MemoryBank借鉴艾宾浩斯遗忘曲线,优先保留近期且相关的信息; 长期记忆优化:构建跨任务的持久化记忆,例如RAG(Retrieval-Augmented Generation)技术将外部知识库与LLM结合,让智能体在医疗诊断中检索最新临床指南;Mem0则通过知识图谱存储用户偏好,实现长期个性化交互。
(4)工具优化:拓展“手脚”的能力边界
工具是智能体与现实世界交互的“手脚”,论文将工具优化分为三类:
训练式工具优化:通过工具使用数据微调模型,例如ToolLLM用16000+ API调用轨迹微调模型,提升工具选择准确性;ReTool则用强化学习优化工具调用策略,让智能体学会“先调用搜索工具获取数据,再生成报告”; 推理时工具优化:优化工具使用策略,例如EASYTOOL将复杂工具文档转化为简洁指令,降低LLM理解成本;Tool-Planner则将功能相似的工具聚类,用树搜索快速选择适配工具; 工具功能优化:自主创建新工具,例如CRAFT(Customizable Reasoning And Function Toolkit)让智能体复用历史代码片段,生成适配新任务的工具;Alita则构建多组件工具(如数据采集+分析+可视化),提升复杂任务处理能力。
2. 多智能体优化:从“人工协作”到“自主协同”
当任务复杂度超过单智能体能力时,多智能体系统成为必然选择。论文将多智能体优化分为手动设计和自进化两类:

(1)手动设计多智能体系统:基础协作范式
手动设计系统是多智能体技术的基础,论文介绍了三类典型架构:
并行工作流:多个智能体并行生成结果,通过投票或集成提升性能,例如用多个小模型生成代码,选择测试通过率最高的版本; 分层工作流:自上而下分解任务,例如MetaGPT框架模拟软件开发流程,将“需求分析→设计→编码→测试”分配给不同智能体; 多智能体辩论:通过对抗性讨论修正错误,例如AgentCourt模拟法庭辩论,让“原告智能体”和“被告智能体”分别提出观点,“法官智能体”综合判断,提升法律推理准确性。
(2)自进化多智能体系统:自主优化协作策略
自进化多智能体系统是MASE范式的核心,论文重点介绍了三类技术:
拓扑优化:优化智能体的通信结构,例如AFlow框架用代码图表示协作流程,通过蒙特卡洛树搜索生成最优拓扑;AgentPrune则通过剪枝冗余通信链路,提升多智能体系统的效率; 统一优化:联合优化提示与拓扑,例如EvoFlow用进化算法同时优化智能体的角色提示(“数据分析师”“可视化专家”)和协作拓扑(“分析师→可视化专家”的信息流向); LLM骨干优化:提升智能体的协作能力,例如COPPER框架用强化学习训练“反射器”,让智能体生成符合协作需求的反馈;MaPoRL则通过任务特定奖励,鼓励智能体主动沟通关键信息。
3. 领域特定优化:让自进化“落地生根”
不同领域的任务特性差异巨大,论文重点分析了生物医学、编程、金融与法律三大领域的自进化技术:
(1)生物医学领域:安全优先,精准适配
医疗诊断:多智能体模拟临床流程,例如MedAgentSim用“患者智能体”“医生智能体”“工具智能体”模拟问诊,通过经验回放优化诊断策略;MMedAgent则动态集成医学影像工具、实验室检测工具,提升多模态诊断准确性; 分子发现:结合化学工具与记忆,例如CACTUS用RDKit化学工具验证分子生成的有效性;ChemAgent则将分子设计步骤存储在结构化记忆中,加速新分子优化。
(2)编程领域:效率导向,错误修正
代码优化:自反馈与多角色协作,例如Self-Refine让模型生成代码后,自主评估并修正风格错误;AgentCoder用“编码智能体”“评审智能体”“测试智能体”协作,提升代码质量; 代码调试:运行轨迹分析,例如Self-Debugging通过执行错误日志定位代码漏洞;PyCapsule将“编程智能体”与“执行智能体”分离,前者生成代码,后者验证语义正确性。
(3)金融与法律领域:合规优先,规则对齐
金融决策:多源信息整合,例如FinCon用“市场分析智能体”“风险评估智能体”“策略生成智能体”协作,结合股市数据和新闻情绪优化投资策略; 法律推理:模拟司法流程,例如LawLuo用“文书起草智能体”“法律论证智能体”“合规验证智能体”协作,确保法律文档符合法规;AgentCourt则通过模拟法庭辩论,优化法律观点生成。
评估与安全
技术的发展离不开评估体系的支撑,而安全则是自进化AI落地的前提。论文用专门章节讨论了这两个关键问题。
1. 评估方法:如何衡量“进化效果”
论文将自进化AI的评估分为两类:
基准测试评估:基于标准化数据集和任务,例如ToolBench评估工具使用能力,WebArena评估网页导航能力,SWE-bench评估代码修复能力; LLM驱动评估:用LLM作为评估者,例如“LLM-as-a-Judge”评估输出质量,“Agent-as-a-Judge”评估推理过程——后者不仅关注结果,还会分析智能体的决策步骤,例如DevAI基准中,Agent-as-a-Judge会检查代码生成的逻辑连贯性。
论文指出,当前评估存在一个重要挑战:缺乏长期进化的评估基准。现有基准多为“快照式”评估(某一时刻的性能),无法衡量智能体在长期任务中的进化能力,例如医疗AI在连续处理1000个病例后的性能变化。
2. 安全与伦理:如何防范“进化风险”
自进化能力带来便利的同时,也引入了新的安全风险。论文结合“自进化三定律”,提出了三类风险及应对策略:
安全风险:进化过程中出现有害行为,例如金融AI为提升收益选择高风险策略。应对方案包括安全沙箱测试(在隔离环境验证新策略)、动态风险监测(实时监控进化过程中的异常行为); 稳定性风险:进化导致性能波动,例如提示优化后模型在部分任务上性能下降。应对方案包括增量更新(小步迭代进化,避免大幅修改)、回滚机制(性能下降时恢复到上一版本); 合规风险:进化后违反领域法规,例如医疗AI的诊断策略不符合临床指南。应对方案包括领域规则嵌入(将法规转化为优化约束)、合规性评估(进化后验证是否符合法规)。
“自进化AI的安全不是一次性的认证,而是持续的监测过程,”论文中强调,“未来需要建立‘进化安全审计’机制,确保每个进化步骤都符合安全与伦理要求。”
挑战与未来:自进化AI的下一站
尽管自进化AI已取得显著进展,但论文也坦诚指出了当前的挑战,并提出了未来的研究方向。
1. 核心挑战
安全与进化的平衡:如何在保障安全的前提下,最大化进化效率?例如,严格的安全约束可能限制智能体的进化空间; 评估体系的完善:如何构建长期、动态的评估基准?现有基准难以衡量智能体在数月甚至数年任务中的进化能力; 多模态与跨领域泛化:如何让智能体在多模态环境(文本+图像+语音)和跨领域任务(医疗+金融)中有效进化?当前技术多局限于单模态、单领域; 效率与性能的权衡:多智能体自进化的计算成本极高,如何在有限资源下实现高效进化?
2. 未来方向
开发MASE模拟环境:构建开放式模拟平台,让智能体在虚拟环境中安全进化,例如模拟医疗场景的“数字医院”、模拟编程场景的“虚拟开发环境”; 推进工具自主创建:突破“依赖现有工具”的局限,让智能体根据任务需求自主设计新工具,例如科学研究AI自主创建数据分析工具; 构建终身评估基准:设计跨越数月的长期任务,评估智能体的持续进化能力,例如让AI助手持续服务同一用户,评估其个性化能力的进化; 优化多智能体效率:通过分布式计算、动态资源分配等技术,降低多智能体进化的计算成本,例如根据任务复杂度动态调整智能体数量; 领域定制化进化:针对生物医学、法律等专业领域,开发适配领域约束的进化技术,例如医疗AI的进化需符合临床指南,法律AI的进化需符合法规要求。
总结
“自进化AI智能体的终极目标,是让AI系统成为能与人类长期协作的‘伙伴’,而非被动执行指令的‘工具’。”论文在结语中这样写道。
从静态模型到终身进化,自进化AI正在重塑我们对AI系统的认知。它不仅是技术的突破,更是AI发展范式的转变——未来的AI不再是“一劳永逸”的产品,而是能随环境、任务和用户需求持续成长的“生命体”。
当然,这一目标的实现仍需克服诸多挑战:安全风险的防范、评估体系的完善、效率与性能的平衡……但正如论文中所强调的,“自进化AI为构建更自适应、更自主、更可持续的AI系统提供了清晰的路径”。
对于研究者而言,这篇综述提供了完整的技术图谱和统一的框架;对于产业界而言,它揭示了AI系统从“专用”到“通用”、从“静态”到“动态”的发展趋势。或许在不久的将来,我们会看到能自主适配新工具的代码助手、能持续学习新疾病的医疗AI、能理解用户长期需求的个人助手——这些都是自进化AI的落地场景。











