本文给大家带来 ICCV 2025 中「阿里巴巴达摩院」相关论文,论文选择 P 站(PaperScope.ai)ICCV 2025 数据库,解读由闻星使用 Intern-S1 等 AI 生成!
(1) 2.5 Years in Class: A Multimodal Textbook for Vision-Language Pretraining
论文简介:
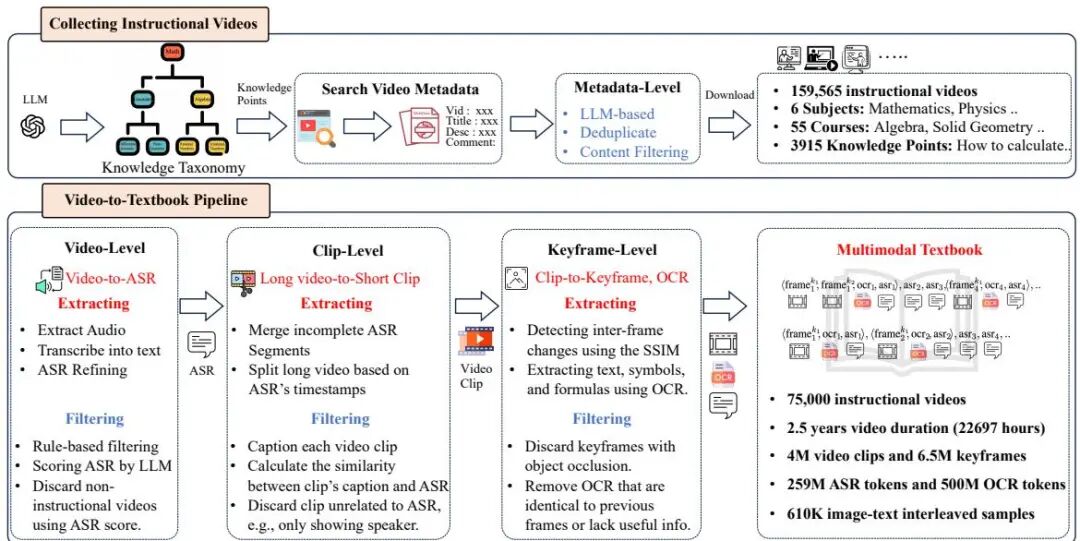
由浙江大学、阿里巴巴达摩院等机构提出了Multimodal Textbook,该工作构建了一个基于教学视频的高质量多模态预训练数据集,通过系统性收集2.5年(22,000小时)在线教学视频,覆盖数学、物理等6大基础学科,采用LLM驱动的知识分类体系和多级过滤流程,提取6.5百万关键帧、0.75亿文本token(ASR+OCR),形成图文交错的教材级语料库。该数据集通过时间序列对齐的关键帧与教学文本,显著提升视觉语言模型(VLM)在ScienceQA、MathVista等知识密集型任务的表现,实验表明相比传统图文对齐数据集,其预训练模型在7个基准任务上平均提升3.2%-8.3%。研究还发现该教材能增强VLM的上下文感知能力,使其在少样本场景中更有效利用图文线索进行推理,例如在MathVista的2-shot测试中作弊识别准确率达94.1%,显著优于现有数据集。该工作验证了视频教学资源作为预训练数据源的潜力,为构建高质量多模态语料提供了新的技术路径。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.1364
(2) StableDepth: Scene-Consistent and Scale-Invariant Monocular Depth

论文简介:
由香港大学、阿里巴巴达摩院、香港中文大学和湖畔实验室提出了StableDepth,该工作针对单目深度估计中相对深度模型存在的视频闪烁和3D不一致性问题,提出了一种场景一致且尺度不变(SCSI)的深度估计方法。通过双解码器架构联合处理有标签图像和无标签视频数据,该方法在保持单帧尺度不变性的同时实现跨帧3D一致性,解决了传统相对深度模型的帧间不一致与度量深度模型泛化能力不足的矛盾。核心创新包括:1)利用预训练视频扩散模型生成具有时序一致性的伪标签,替代传统光度约束;2)双分支网络设计,主分支处理有标签数据的度量深度监督,辅分支通过场景级归一化对齐无标签视频伪标签;3)半监督联合优化策略,同步提升域间泛化能力和消除闪烁伪影。实验显示,该方法在Sintel、Bonn、ScanNet和KITTI等基准上分别实现13.2%、86.8%、39.3%和8.2%的精度提升,同时支持13倍于视频扩散模型的实时推理速度(5.77FPS),在动态场景、复杂纹理和大尺度物体等挑战场景中保持几何细节稳定,为3D重建、机器人导航和增强现实等应用提供了兼具精度与时效性的解决方案。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.332
(3) Boosting Vision Semantic Density with Anatomy Normality Modeling for Medical Vision-language Pre-training
论文简介:
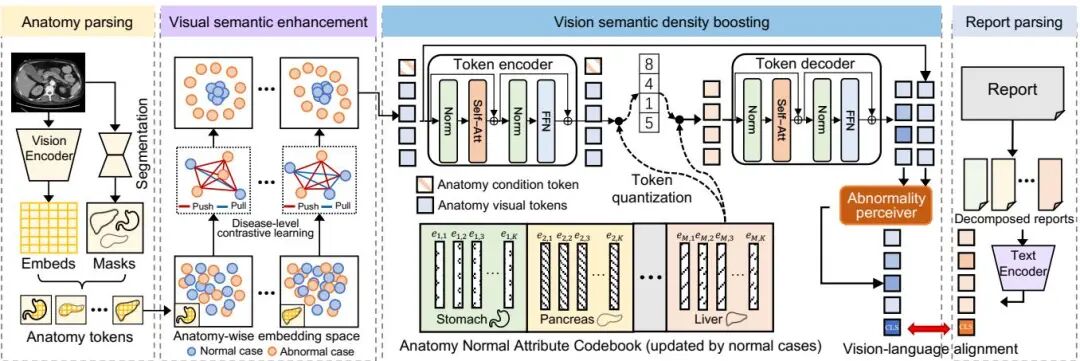
由浙江大学、阿里巴巴达摩院等机构提出了ViSD-Boost方法,该工作通过解剖正常性建模增强视觉语义密度,解决医学视觉语言预训练中的模态对齐偏差问题。针对医学图像低信噪比与报告高信噪比导致的语义密度差距,研究者提出双路径优化策略:首先通过疾病级别视觉对比学习,利用大语言模型提取解剖异常标签,使正常样本在嵌入空间聚类而异常样本保持差异性分布;其次设计轻量级VQ-VAE在潜在空间建模正常解剖分布,通过重建误差放大异常信号。在CT-RATE、Rad-ChestCT和MedVL-CT69K数据集上,该方法实现平均84.9%AUC的零样本诊断性能,较现有方法提升3.6%,在放射报告生成和多疾病分类等下游任务中也表现优异。核心创新在于首次引入医学场景的语义密度概念,通过解剖结构感知的视觉增强和异常信号强化机制,有效提升跨模态对齐精度,为3D医学影像分析提供新范式。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.2597
(4) AnyI2V: Animating Any Conditional Image with Motion Control
论文简介:
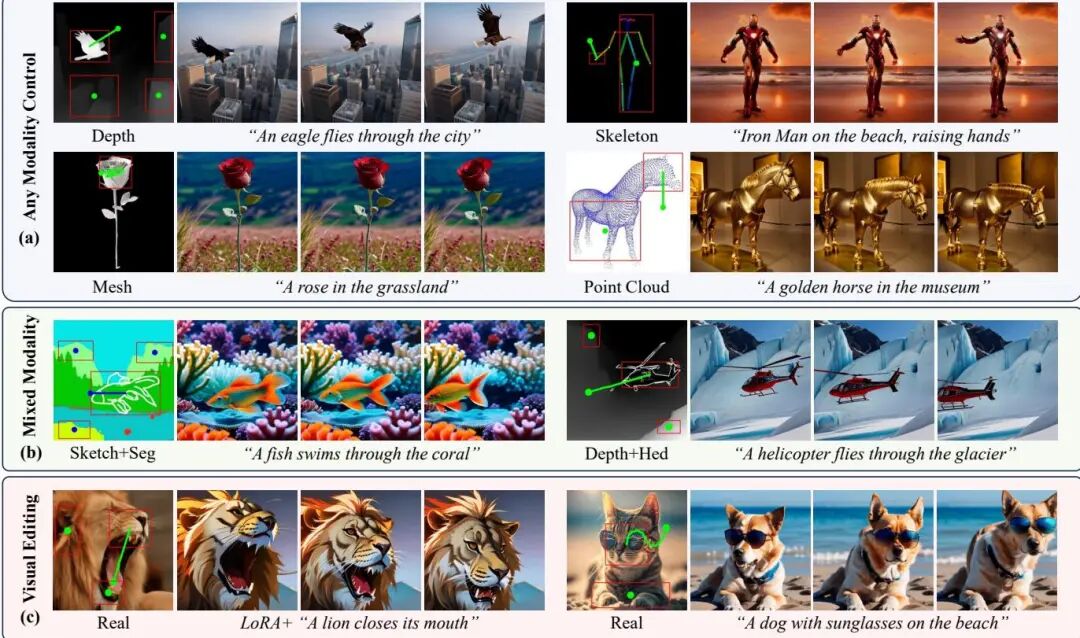
由复旦大学、阿里巴巴达摩院和湖畔实验室提出了AnyI2V,该工作提出了一种无需训练的图像到视频生成框架,能够通过用户定义的运动轨迹控制任意条件图像(如网格、点云、边缘图等)的动画生成。该方法突破了传统方法对真实RGB图像的依赖,支持混合模态输入(如深度图与线稿结合),并通过LoRA和文本提示实现内容编辑。核心创新包括:1)结构保持的特征注入机制,通过AdaIN局部特征调整实现多模态输入的结构保留与外观解耦;2)基于PCA降维分析的跨帧对齐策略,利用空间自注意力查询特征的时序一致性实现零样本轨迹控制;3)动态语义掩码生成技术,通过特征相似性聚类自适应捕捉形变物体区域。实验表明,该方法在FID、FVD和运动精度指标上优于ImageConductor、DragAnything等SOTA方法,且在Lavie、VideoCrafter2等不同视频生成模型上展现出良好泛化性。其训练-free特性不仅避免了高昂的训练成本,还支持跨模型迁移应用,为可控视频生成提供了灵活高效的解决方案。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.2581
(5) Advancing Textual Prompt Learning with Anchored Attributes
论文简介:
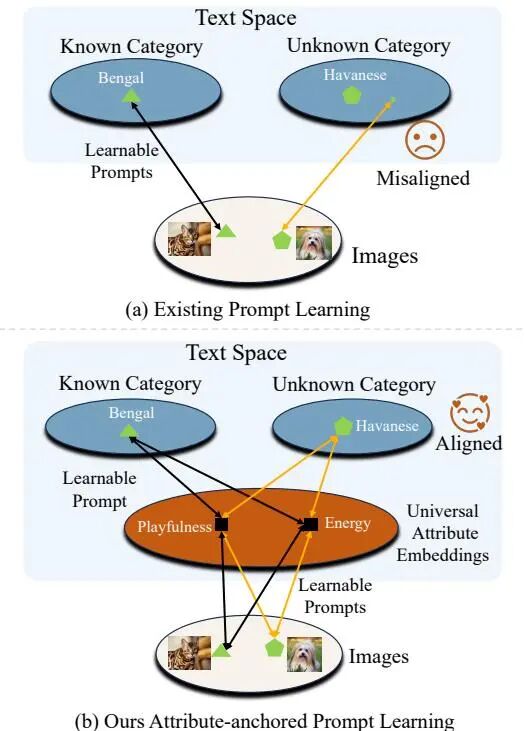
由南开大学与达摩院等机构提出了ATPrompt方法,该工作通过引入通用属性作为桥梁,增强图像与未知类别之间的对齐效果。该方法将传统文本提示学习中的一维类别级软提示扩展至多维属性级空间,通过在可学习的软提示中锚定多个固定通用属性令牌,使文本提示从类别中心形式转变为属性-类别混合形式。同时提出基于大语言模型的可微分属性搜索方法,为下游任务筛选代表性属性,该搜索仅需单次任务执行即可完成。ATPrompt提供浅层和深层两种版本,分别对应不同深度的提示学习方法,可无缝替换现有文本提示格式实现即插即用改进。实验在11个数据集上验证了方法有效性,与CoOp、CoCoOp等基线方法结合后平均性能提升显著,其中在基类-新类泛化实验中,CoOp+ATPrompt组合在11个数据集上平均HM指标提升2.99%,计算成本仅增加微小。该方法为提示学习的提示结构优化提供了新方向,代码已开源。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.2475
(6) LiON-LoRA: Rethinking LoRA Fusion to Unify Controllable Spatial and Temporal Generation for Video Diffusion

论文简介:
由浙江大学与阿里巴巴达摩院等机构提出了LiON-LoRA,该工作通过重新设计LoRA融合机制实现视频扩散模型的可控空间与时间生成。针对传统LoRA在融合多相机轨迹时存在的不稳定性和非线性缩放问题,研究团队提出线性可扩展性、正交性和范数一致性三大核心原则:首先通过分析浅层特征的正交性实现低级控制解耦,其次通过层间范数归一化稳定复杂运动组合的融合过程,最后引入可学习的控制token实现相机与物体运动幅度的线性调节。创新性地将静态相机视频数据与扩散Transformer的自注意力机制结合,通过扩展缩放token机制统一了4D时空生成控制。实验表明,LiON-LoRA在仅需4000次迭代训练的情况下,相较于MotionCtrl、CameraCtrl等方法,在旋转误差(↓24.8%)、平移误差(↓13.0%)和轨迹误差(↓21.5%)等指标上均取得显著提升,同时保持了视频生成质量(FVD降低37.8%)。该方法不仅解决了多LoRA模块融合时的特征冲突问题,还通过训练无关的融合框架实现了任意组合的独立控制,在极少训练数据条件下展现出优异的泛化能力和精准控制效果,为视频生成模型的可控编辑提供了高效解决方案。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.2278
(7) Bridging Local Inductive Bias and Long-Range Dependencies with Pixel-Mamba for End-to-end Whole Slide Image Analysis
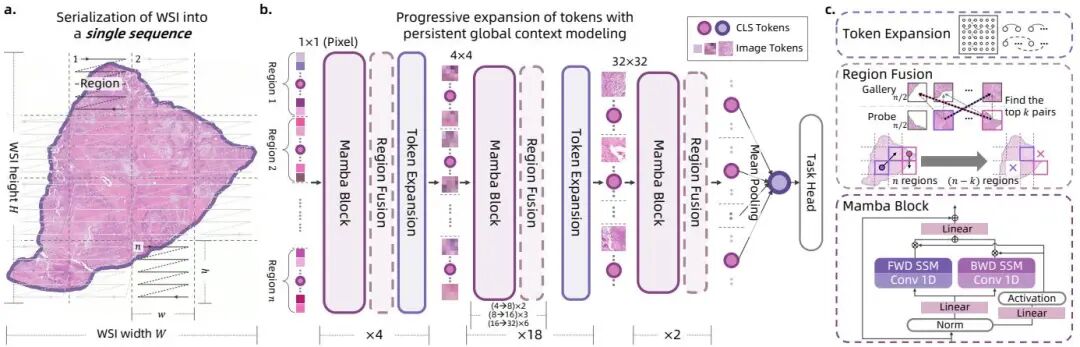
论文简介:
由浙江大学、阿里巴巴达摩院等机构提出了Pixel-Mamba,该工作通过结合Mamba模块和渐进式Token扩展机制,构建了首个高效处理全切片病理图像(WSI)的端到端深度学习架构。Pixel-Mamba针对WSI分析中计算复杂度高和多尺度信息整合难两大核心挑战,创新性地采用线性复杂度的状态空间模型(Mamba)替代传统Transformer,并引入区域融合模块动态合并相似区域以降低冗余计算。其核心贡献在于:1)通过逐层扩展Token感受野(从1×1至32×32),首次在端到端框架中同时建模局部归纳偏置与跨尺度长程依赖;2)在无需任何病理数据预训练的情况下,仅用ImageNet预训练参数即可超越基于百万级WSI预训练的CONCH、GigaPath等最先进基础模型;3)在膀胱癌、乳腺癌、肺癌等多癌种分期和生存分析任务中,以6M参数量实现Macro-F1 0.5334、C-index 0.6507等指标,较传统两阶段方法提升显著。该架构通过区域级扫描策略保持空间邻近性,并支持灵活调整显微镜视野倍率(0.6×至2.5×),在2.5×倍率下仍能处理完整WSI,为病理图像分析提供了兼具效率与性能的新范式。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.1316
(8) Preacher: Paper-to-Video Agentic System

论文简介:
由北京大学、阿里巴巴达摩院、普林斯顿大学等机构提出了Preacher,该工作首次实现了基于智能体的论文到视频摘要转换系统。Preacher通过创新的自顶向下-自底向上架构,解决了现有视频生成模型在处理长文本、领域知识表达和风格多样性上的局限。系统采用关键场景(key scenes)作为文本与视觉模态的中间桥梁,结合渐进式链式思考(P-CoT)机制实现细粒度内容规划,使多智能体协作完成从论文理解到视频生成的全流程。实验表明,Preacher在数学、分子生物学等五个领域均能生成专业级视频摘要,其生成的视频在准确性、专业性和与原文对齐度上全面超越当前最先进的大模型+视频生成器的组合方案。该系统通过集成领域专用可视化工具(如分子结构渲染、数学公式动画等),实现了学术内容的精准表达,为降低科研成果传播门槛提供了创新解决方案。代码和基准数据集即将开源,推动自动化知识传播技术的发展。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.1285
(9) TryOn-Refiner: Conditional Rectified-flow-based TryOn Refiner for More Accurate Detail Reconstruction

论文简介:
由阿里巴巴达摩院等机构提出了TryOn-Refiner,该工作针对虚拟试穿中扩散模型难以保留精细细节的问题,提出了一种基于条件修正流的即插即用细化模块。该模块通过将传统的噪声-图像范式转换为从粗略结果到精细结果的确定性映射,避免了扩散模型引入的不确定性,仅需1-10步推理即可实现服装文字、纹理、人脸等细节的精准修复。研究团队创新性地构建了针对细化任务的数据生成流程:通过目标图像下采样、VAE编码解码破坏细节、超分辨率恢复的三阶段策略生成训练数据对,并提出数据平滑策略缓解高频信息过增强导致的块状伪影。实验表明,TryOn-Refiner在VITON-HD和Dresscode数据集上,对OOTD、StableVITON等主流模型的试穿结果进行细化后,LPIPS指标最高降低10.9%,FID指标最高提升9.7%,且在1024×768分辨率下仅需1步推理即可显著提升细节质量。该方法通过确定性流映射机制和针对性数据策略,在保持背景一致性的同时显著增强了服装纹理、文字图案等关键细节的呈现效果,为虚拟试穿技术的实用化提供了有效解决方案。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.1085
(10) Free-Form Motion Control: Controlling the 6D Poses of Camera and Objects in Video Generation

论文简介:
由复旦大学、阿里巴巴达摩院等机构提出的SynFMC数据集与FMC方法,首次实现了视频生成中相机与物体6D姿态的联合控制。针对现有数据集缺乏完整6D姿态标注导致的运动控制难题,SynFMC通过规则驱动的生成算法构建了包含62K视频的合成数据集,覆盖人类、动物、车辆等多类物体在街道、海洋等复杂环境中的多样化运动模式。该数据集不仅提供相机与物体的6D姿态标注,还包含实例分割、深度图等多模态信息,为模型学习解耦运动效应提供了关键支撑。基于SynFMC训练的FMC方法创新性地设计了相机运动控制器(CMC)与物体运动控制器(OMC),通过Plucker坐标嵌入和高斯模糊核处理,实现了对相机视角、距离、高度及物体位姿的独立操控。实验表明,FMC在CamTransErr(18.12)、ObjRotErr(0.96)等指标上显著优于MotionCtrl等现有方法,同时支持与ToonYou、Realistic Vision等个性化生成模型的无缝集成。该工作突破了传统图像空间轨迹控制的局限,为影视制作、虚拟现实等领域提供了更精准的三维运动控制范式。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.414

上 P 站,查看更多 ICCV 2025 论文解读:
https://www.paperscope.ai/zh?source=iccv2025










