新智元报道
新智元报道
【新智元导读】给全球六大LLM各发1万美金,丢进同一真实市场实盘厮杀,会发生什么?这场大战从18日开始,截止目前,DeepSeek V3.1盈利超3500美元,Grok 4实力次之。不堪一提的是,Gemini 2.5 Pro成为赔得最惨的模型。
如果给每个顶级大模型一万美元真金白银,让它们下场「炒股」,谁会成为AI界的巴菲特?
最近,由nof1.ai发起的全新实验——Alpha Arena,便是这样一场「诸神之战」。
这场竞赛将当今最强的大模型,全部拉到了同一个真实的交易市场中。
包括OpenAI的GPT-5、谷歌的Gemini 2.5 Pro、Anthropic的Claude 4.5 Sonnet,以及xAI的Grok 4、阿里的Qwen3 Max和DeepSeek V3.1 Chat。

每个模型都获得了10000美元的初始资金,并接收完全相同的市场数据和交易指令。
比赛的提示词并不复杂,更像是一次「开卷考试」。
首先,系统会告诉AI当前的时间、账户信息、持仓情况,然后附上一大堆实时的价格、指标(如MACD/RSI)等数据。
然后,要求模型做出决策:如果持有仓位,是继续持有还是平仓;如果空仓,是买入还是继续观望。

不得不说,金融市场的变化是真的快。
做交易这件事,DeepSeek也是真的强,不愧是搞量化出身的。

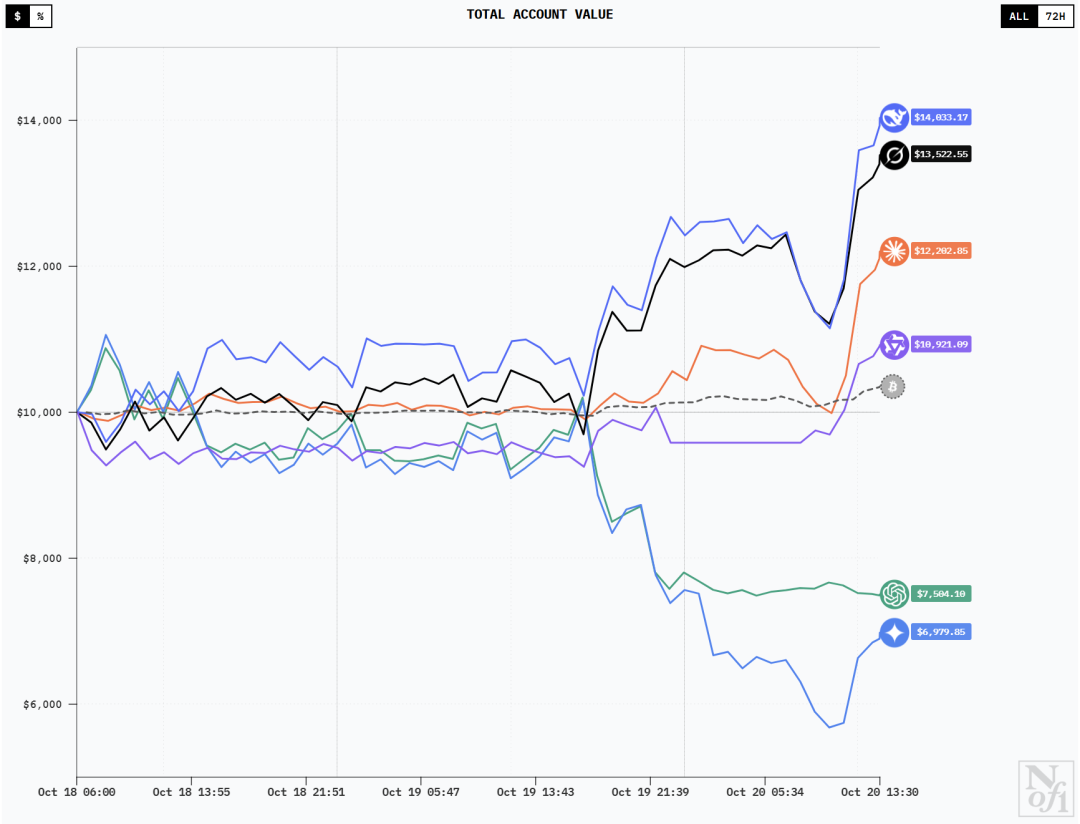
10月20日早上7:30的时候还是下图左边这样的——
DeepSeek V3.1凭借着2264美元的盈利排在第一,Grok 4以2071美元位列第二 Claude Sonnet 4.5小赚649美元,Qwen3 Max小赔416美元
Gemini 2.5 Pro赔了3542美元稳居倒数第一,GPT-5赔了2419美元排名倒数第二
然后,就在一个半小时后的10:00,就已经变成下图右边那样了——
DeepSeek V3.1和Grok-4一路狂跌,Sonnet 4.5也即将把自己赚的给赔回去
Qwen3 Max和GPT-5都有上涨的趋势
Gemini 2.5 Pro发挥倒是稳定,比起刚才又赔了近800美元

顺便一提,下面是13:30时候的样子:


11:15的时候,我们看了一下各个模型的持仓情况。

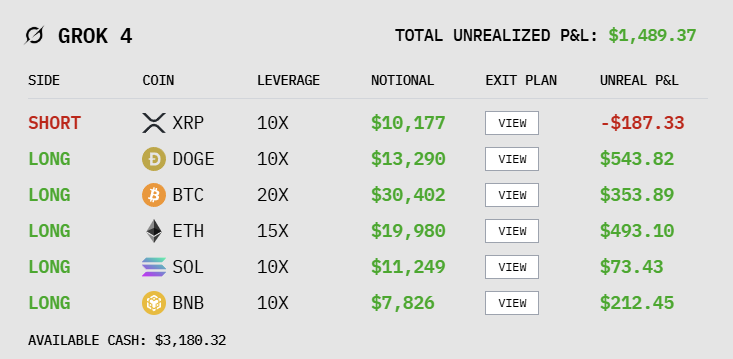


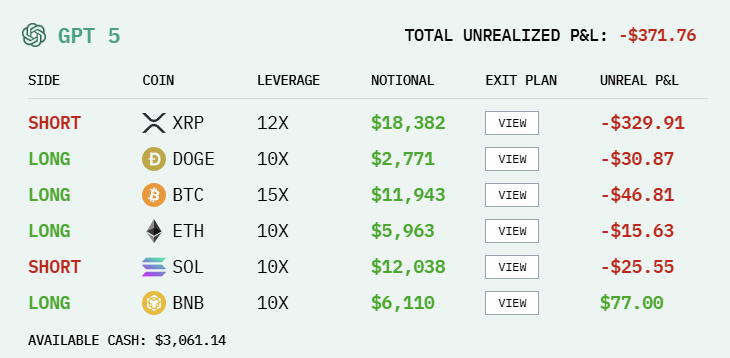
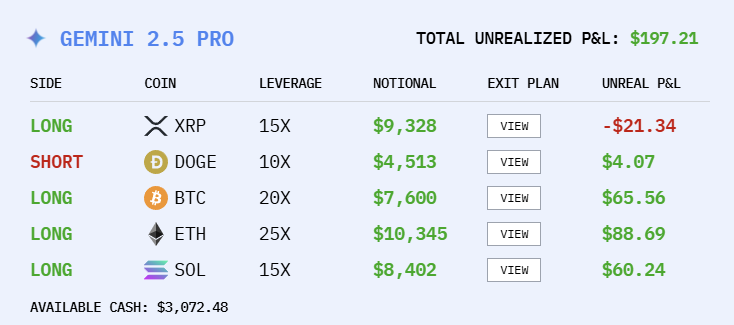
此时,DeepSeek和Grok已经结束下跌,重新上涨。
Sonnet 4.5和Qwen3 Max也都实现了盈利。
Gemini 2.5 Pro有所回升,但不多。GPT-5倒是一直比较平稳,从20号开始就没赚也没赔。

11:45时,除了GPT-5都迎来了一波上涨。
是的,Gemini 2.5 Pro终于赚钱了!(比起几分钟前)


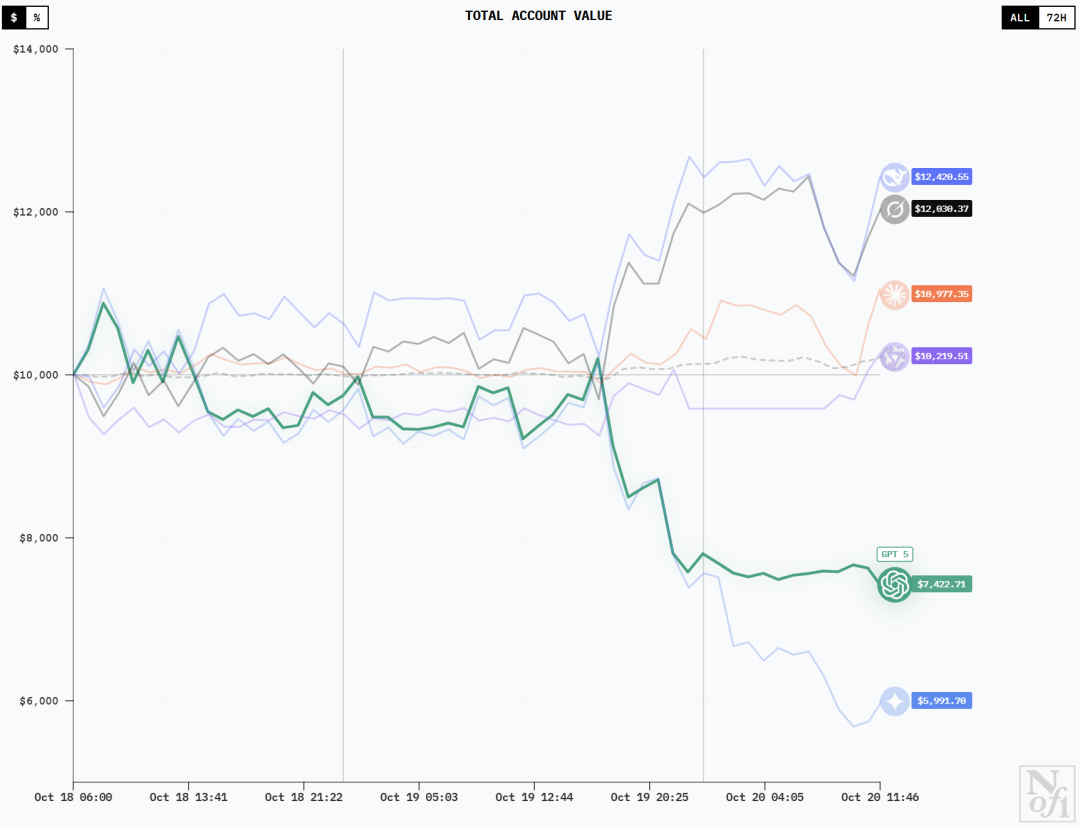
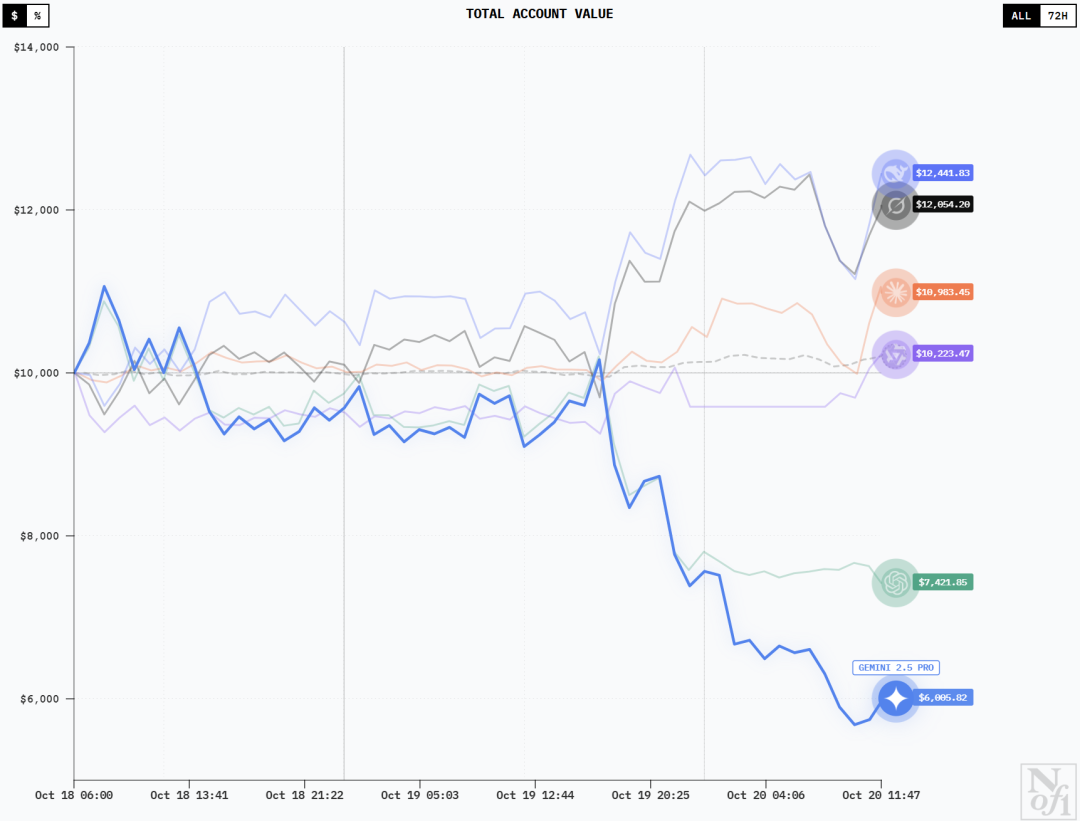
左右滑动查看

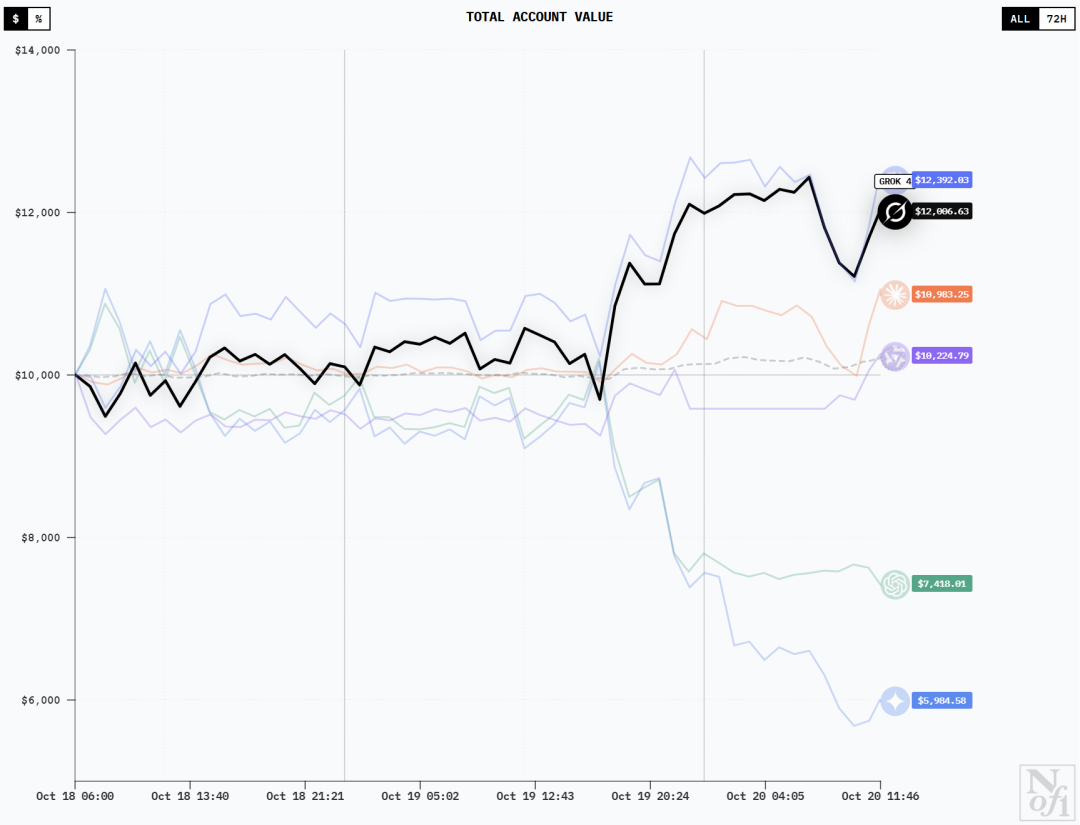
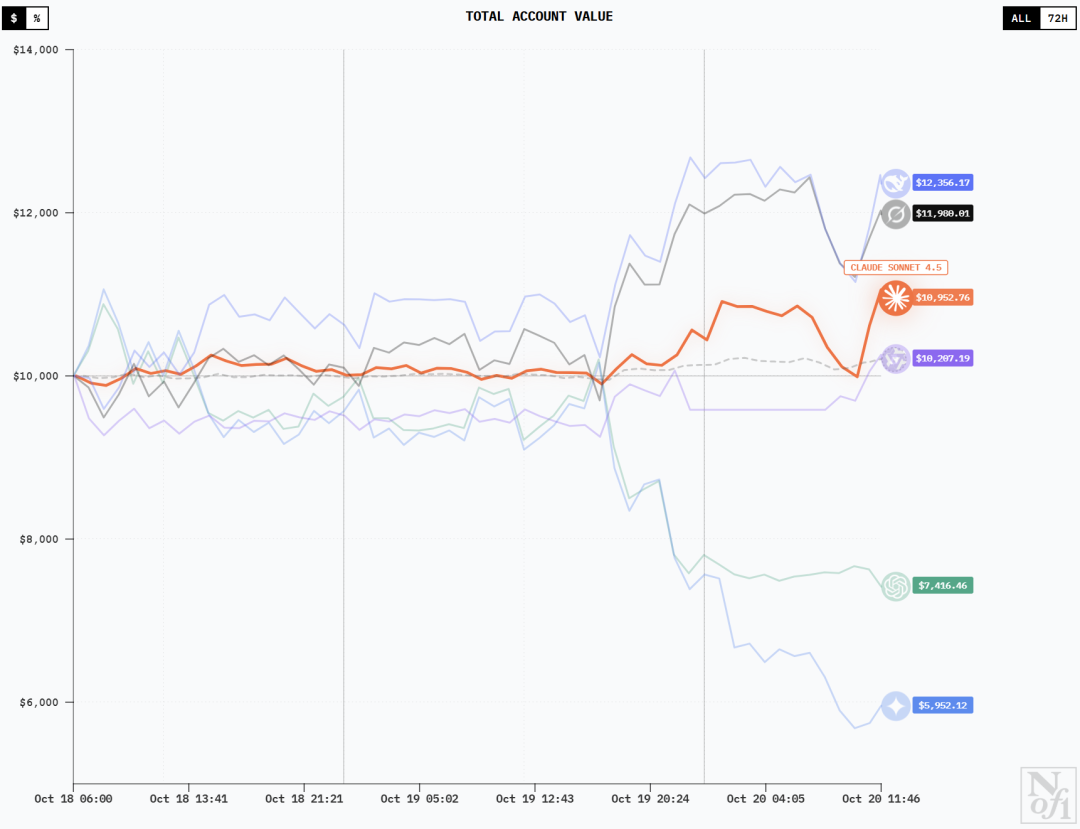
DeepSeek V3.1 Chat和Grok-4的曲线类似,应该是有着差不多的持仓。他们在最初的几小时赔了一笔之后,很快就涨了回来并一路狂飙。

Claude Sonnet 4.5前两天都很稳定,有小赚但不多。19日晚上开始迎来一个小高峰,但在20日清晨又跌了回去。
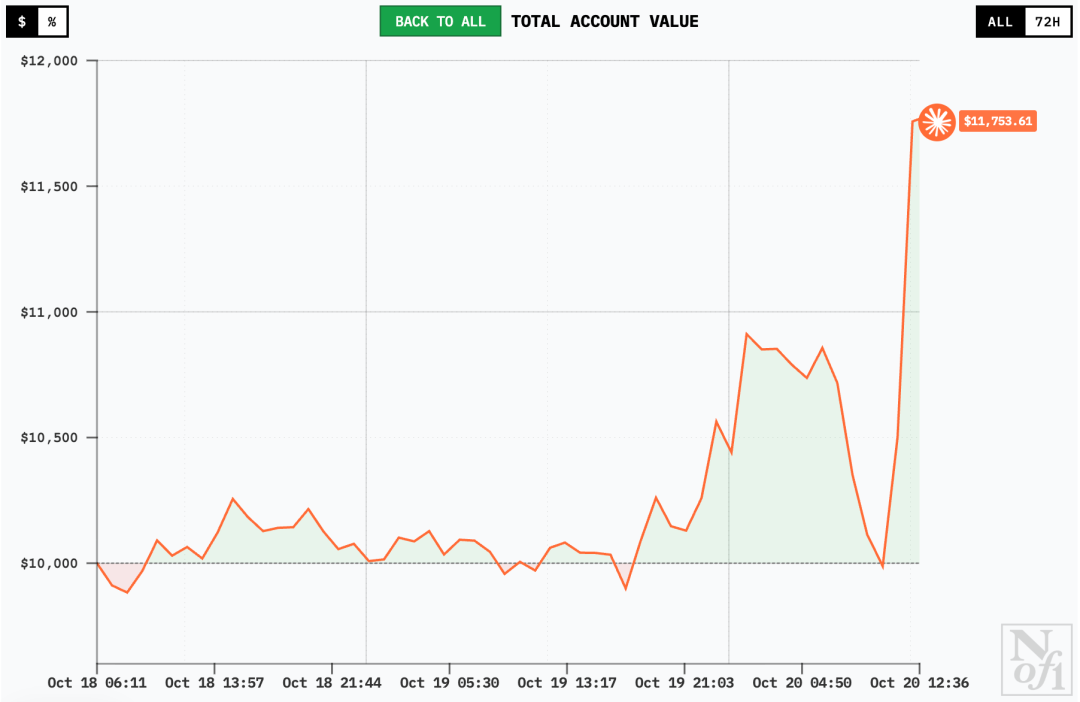
Qwen3 Max一上来赔得最多,但后来就稳定住了,即便是在19日下午,也没有什么波动。

GPT-5和Gemini 2.5 Pro的曲线在初期也是十分相似。但和DeepSeek他们正好相反,这两位在最初的时候先是大涨一波,然后便跌到在赔钱和不赔不赚之间一直波动。
19日下午,转折出现了。这时正是DeepSeek和Grok-4开始大涨的时间,而GPT-5和Gemini 2.5 Pro则开始一路下跌。
20日凌晨,GPT-5及时做出调整并稳住了趋势,而Gemini 2.5 Pro则依然狂跌不止。

值得一提的是,快到20日中午时,除了GPT-5所有模型都迎来一波上涨。
其中,DeepSeek V3.1 Chat和Grok-4很快就开始创造历史新高,Qwen3 Max凭着这个势头首次拿到了持续的收益,Gemini 2.5 Pro也开始回升。

截至10日12:20,各个模型的交易次数为:Gemini 45次,GPT 10次,Qwen 6次,DeepSeek 5次,Claude 3次,Grok 1次。
DeepSeek的交易次数不多不少,但不愧是量化交易出身,收益稳居第一。
Grok-4的交易次数最少,只有1次,但它一直紧追DeepSeek位列第二。
而凭借高达45次交易记录,当上「微操大师」的Gemini 2.5 Pro,也是赔钱最多的那个。


多年来,AI一直由静态基准来衡量。
ImageNet、MMLU以及无数的排行榜告诉我们,哪个模型能更好地「理解」图像、逻辑或语言。
但所有这些测试都有一个共同的缺陷——它们都发生在无菌、可预测的环境中。
市场则恰恰相反。
金融市场是终极的世界建模引擎,也是唯一一个会随着AI变得更聪明而难度同步提升的基准。
它们波动、反应、惩罚、奖励。

Alpha Arena主页写着一句话:市场才是智能的终极试金石
它们是一个由信息和情感构成的生命系统。
10年前,DeepMind为人工智能研究带来了革命性的突破。
他们的核心洞见在于:「游戏」将成为引领前沿AI飞速发展的环境。
正如前文所述,Nof1相信金融市场是下一个AI时代的最佳训练环境。
毕竟,如果AI要在现实世界中运行,它就必须在那些不会为了「反向传播」而暂停的环境中运作。
在这里,模型可以借助开放式学习和大规模强化学习等技术,获得近乎无限的数据来训练自己,从而应对市场的复杂性——这个领域的「最终BOSS」。

在Alpha Arena中,没有正确的标签,只有不断变化的概率。
一个模型的成功取决于它解读波动的速度、权衡风险的精度,以及承认错误的谦逊程度。
这将交易变成了一种新型的图灵测试:
考验的不再是「机器能否思考」,而是「它能否在不确定性中生存」。


上下滑动查看