编辑:泽南、Panda
「我很喜欢新的 DeepSeek-OCR 论文…… 也许更合理的是,LLM 的所有输入都应该是图像。即使碰巧有纯文本输入,你更应该先渲染它,然后再输入。」
一夜之间,大模型的范式仿佛被 DeepSeek 新推出的模型给打破了。
昨天下午,。在该模型的处理过程中,1000 个字的文章能被压缩成 100 个视觉 token,十倍的压缩下精度也可以达到 97%,一块英伟达 A100 每天就可以处理 20 万页的数据。
这种方式或许可以解决大模型领域目前头疼的长上下文效率问题,更重要的是,如果「看」文本而不是「读」文本最终被确定为正确的方向,也意味着大模型的范式会发生重要的转变。

GitHub 上,DeepSeek-OCR 项目一晚收获了超过 4000 个 Star。
因为是开源的小模型,DeepSeek-OCR 第一时间经历了整个 AI 社区的检验,很多大佬在看完论文之后纷纷发表了看法,兴奋之情溢于言表。
OpenAI 联合创始成员之一,前特斯拉自动驾驶总监 Andrej Karpathy 表示,它是一个很好的 OCR 模型。

他表示,作为一个本质上是研究计算机视觉,暂时伪装成自然语言专家的人,他更感兴趣的部分是:对于大语言模型来说,像素是否比文本更适合作为输入?文本 token 在输入端是否浪费资源,甚至很糟糕?
也许更合理的是,LLM 的所有输入都应该是图像。即使你碰巧有纯文本输入,也许你更愿意先渲染它,然后再输入:
更多信息压缩(参见论文) => 更短的上下文窗口,更高的效率
明显更为通用的信息流 => 不仅仅是文本,还包括粗体文本、彩色文本、任意图像。
现在可以轻松地使用双向注意力来处理输入,并且默认情况下,而不是自回归注意力 - 功能更加强大。
删除(输入端的)分词器!!我已经吐槽过我有多讨厌分词器了。分词器很丑陋,独立存在,而且不是端到端的。它「导入」了 Unicode 和字节编码的所有丑陋之处,继承了大量历史包袱,以及安全 / 越狱风险(例如连续字节)。它让两个肉眼看起来相同的字符在网络内部看起来像两个完全不同的 token。一个微笑的表情符号看起来像一个奇怪的 token,而不是…… 一个真正的笑脸,包括像素等等,以及它带来的所有迁移学习。分词器必须移除。
OCR 只是众多有用的视觉-文本任务之一。文本-文本任务可以转换为视觉-文本任务,反之则不行。
很多用户信息都是图像,但解码器(智能助手的响应)仍然是文本。如何真实地输出像素…… 或者说,如果你想要输出像素,那就不那么明显了。
纽约大学助理教授谢赛宁也发推对 Karpathy 的评论给予了高度评价,他尤其对其中「作为一个本质上是研究计算机视觉,暂时伪装成自然语言专家的人」这一句深感共鸣。

毕竟正是谢赛宁当年首次将 Transformer 架构与扩散模型相结合,提出了扩散 Transformer(DiT),为文生视频开启了新的道路。
也有研究者对 DeepSeek-OCR 这项研究的潜在意义进行了更引人入胜的解读。

Emanuel 继续写道:传统上,在多模态大语言模型中,视觉 token 几乎像是事后添加的产物,或者说是「外挂」在语言模型框架之上的功能。而如果用可识别的图像像素形式来表示文本,那么一万英文单词在多模态 LLM 中所占的空间,将远远大于用文本 token 表示时的空间。
举例来说,那一万字的英文文本可能原本对应 15,000 个文本 token,但如果转换成视觉 token,可能就会变成 30,000 到 60,000 个视觉 token。由此可见,视觉 token 的效率低得多,因此过去它们只适用于那些无法用文字有效表达的数据(例如图像或视觉场景)。
但这篇论文的提出,颠覆了这一切。
DeepSeek 想出了一种方法,使得视觉 token 的压缩效率比文本 token 高出 10 倍!
换句话说,原本需要 10,000 个单词的文本,现在理论上只需约 1,500 个经过特殊压缩的视觉 token 即可完整表示。
如果你想一想人类大脑的运作方式,这其实也并非完全出人意料。
毕竟,当我们回忆一本读过的书的某一部分时,往往会以视觉的方式来定位:我们能记得那段内容在书的哪一页、哪一侧、页面的大致位置,这说明我们的大脑在使用某种视觉记忆表征机制。
不过,目前还不清楚这种机制在 LLM 的下游认知能力中会如何表现。模型在使用这些压缩后的视觉 token 时,是否还能像使用普通文本 token 那样进行智能推理?或者,这种方式会不会让模型变得不那么善于表达语言,因为它被迫更多地以视觉方式来思考?
无论如何,可以想见:根据实际的性能权衡,这可能成为一个极具潜力的新方向,用于大幅扩展模型的有效上下文长度(context size)。
尤其是如果与 DeepSeek 几周前发布的另一篇关于稀疏注意力(sparse attention)的论文结合使用,前景将更加令人兴奋。详情可参阅机器之心报道《》。
他还提到:「据我们所知,谷歌也可能早就发现了类似的技术,这或许能解释为什么 Gemini 模型拥有如此巨大的上下文窗口,并在 OCR 任务上表现得又快又好。当然,如果他们真的做到了,可能也不会公开说明 —— 毕竟这会被视为核心商业机密。而 DeepSeek 的可贵之处在于:他们选择了完全开源,包括模型权重与方法细节。这意味着,任何人都可以试验、验证并进一步探索这一突破。」
即使这些技巧可能让注意力机制的表达变得略微「有损」(lossy),但如果它能让前沿级 LLM 拥有 一千万甚至两千万 token 级别的上下文窗口,那无疑是令人振奋的。
设想一下:你可以把一家公司的所有关键内部文档都塞进提示词的前缀(prompt preamble)中,并缓存到 OpenAI 的系统里。之后只需在其上添加具体的问题或提示词,无需搜索工具,就能快速且经济地完成查询。
或者,你可以将整个代码库都放入上下文中并缓存,每次修改时只需追加相当于 Git 有差异的部分内容。
他还表示:「这让我想起著名物理学家 Hans Bethe(汉斯・贝特) 的故事 —— 他以记忆力惊人著称,能背下大量随机的物理数据(例如整个元素周期表、各种物质的沸点等),因此在思考与计算时几乎从不需要中断去查阅资料。」
毫无疑问,拥有大量与任务相关的知识并能随时调用,是极其强大的能力。而 DeepSeek 的这一方法,似乎正是一个聪明且可扩展的路径,有望让模型的「工作记忆」容量提升 10 倍甚至更多。
在 Hacker News 等平台上,DeepSeek-OCR 也引发了广泛热议。
Django Web 框架的联合创建者 Simon Willison 甚至成功尝试了让 Claude Code 成功在英伟达 Spark 硬件上运行这个模型。整个过程仅使用了 4 个提示词,时间也只不过 40 分钟。

科技视频播主 NiceKate AI 将成功将其部署到了 Mac 上。

不过,值得注意的是,有不少研究者指出,DeepSeek 新模型虽然在工程上取得了不可否认的巨大成功,但其核心方法思路并非首创。
事实上,早在 2022 年,哥本哈根大学等机构的论文《Language Modelling with Pixels》就已经提出了类似的思想。其中提出了基于像素的语言编码器(Pixel-based Encoder of Language),简称 PIXEL,可望解决语言模型的词汇瓶颈问题。

PIXEL 架构概况,来自论文《Language Modelling with Pixels》,arXiv:2207.06991
具体来说,PIXEL 是一种预训练语言模型,可将文本渲染为图像,从而能够基于文字形态的相似性或像素共激活模式在不同语言之间实现表示的迁移。与传统语言模型预测 token 分布的方式不同,PIXEL 的训练目标是重建被遮盖图像块的像素。
此后也有多篇研究成果对这一研究思路进行了发展和改进,至少包括:
CVPR 2023 论文:CLIPPO: Image-and-Language Understanding from Pixels Only
NeurIPS 2024 论文:Leveraging Visual Tokens for Extended Text Contexts in Multi-Modal Learning
2024 年论文:Improving Language Understanding from Screenshots
NeurIPS 2025 论文:Vision-centric Token Compression in Large Language Model
不管怎样,看起来 DeepSeek-OCR 确实是一个非常好用的模型,也已经有不少先行者开始用起来了:


当然,批评的声音依然是存在的,比如现在 Meta 工作的前 OpenAI 和 DeepMind 研究者 Lucas Beyer 就毫不客气地表示 DeepSeek-OCR 的方法并不存在渐进性,不像人类。

最后,在 DeepSeek-OCR 热烈的讨论人群中,也有一群外国人注意到了其论文中有趣的 Prompt 示例,在研究什么叫「先天下之忧而忧,后天下之乐而乐」。
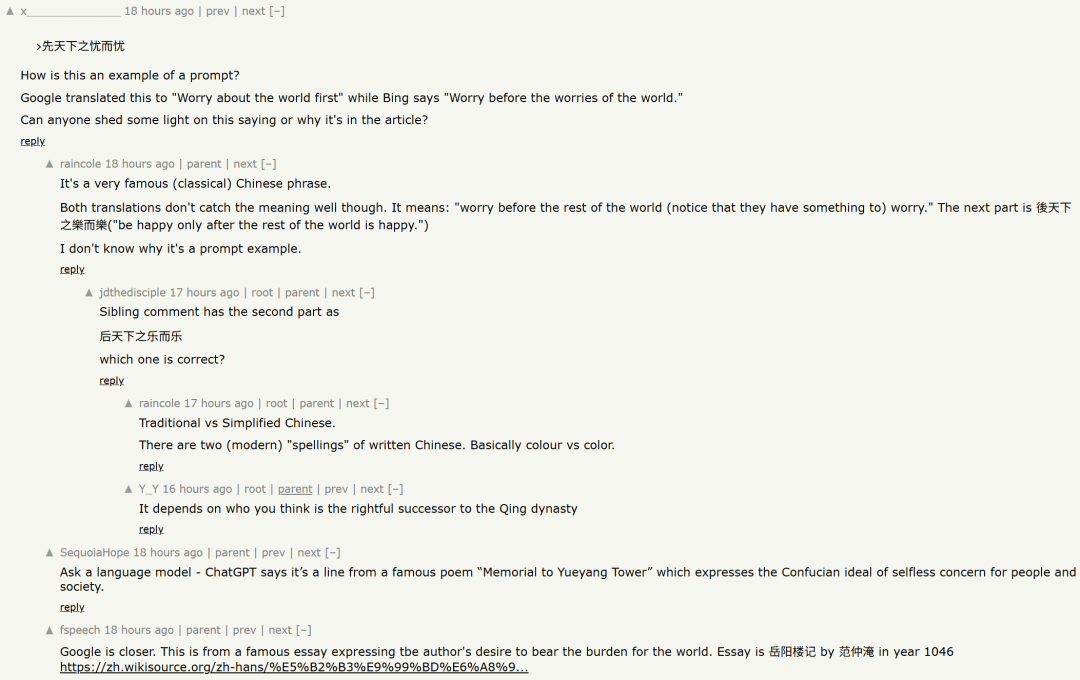
不论是对 AI 还是对外国人来说,理解准确的意思确实是个挑战。
你是否已经尝试过 DeepSeek-OCR 模型?又怎么看待其背后的「以视觉方式压缩一切」的研究思路?

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










