本研究由新加坡国立大学 Show Lab 团队主导完成。共一作者 Zeyu Zhu 祝泽宇(博士生)与 Kevin Qinghong Lin 林庆泓(博士生)均来自 ShowLab@NUS,聚焦于多模态理解以及智能体(Agent)研究。项目负责人为新加坡国立大学校长青年助理教授 Mike Zheng Shou 寿政。
背景:学术展示视频生成挑战
学术展示视频作为科研交流的重要媒介,制作过程仍高度依赖人工,需要反复进行幻灯片设计、逐页录制和后期剪辑,往往需要数小时才能产出几分钟的视频,效率低下且成本高昂,这凸显了推动学术展示视频自动化生成的必要性。然而,与自然视频生成不同(如 Sora2、Veo3 等扩散模型),学术展示视频面临以下独特挑战:
长文档与高密度输入 (Multi-modal Long-context Input): 来源于完整学术论文,包含大段专业文本、复杂公式、多幅图表,远超自然视频的输入复杂度。
多模态通道的协同生成 (Coordination of Multiple Aligned Channels): 需要同时生成并对齐幻灯片、字幕、语音、光标轨迹与讲者视频,保证多模态之间的语义一致性与时序同步。
缺乏专门的评价标准 (Lacks Well-defined Evaluation Metrics): 现有视频生成指标主要关注画面质量或风格一致性,难以衡量学术展示视频在 知识传递、受众理解与学术可用性 上的效果。
因此,现有自然视频生成模型和简单的幻灯片 + 语音拼接方法难以胜任,亟需一个系统化的基准和方法来推动自动化、可用的学术视频生成。为了解决以上挑战,本文提出了 Paper2Video 基准对学术展示视频进行评价,并提出一个多智能图框架 PaperTalker,为实现自动化和可用的学术视频生成迈出切实可行的一步:

图 1: Paper2Video 概览

论文链接:https://arxiv.org/abs/2510.05096
项目主页:https://showlab.github.io/Paper2Video/
开源代码:https://github.com/showlab/Paper2Video
开源数据:https://huggingface.co/datasets/ZaynZhu/Paper2Video
Paper2Video 评价基准
为了评价学术展示视频的质量,本文收集了 101 片论文和对应的作者录制的学术展示视频作为测试基准,并从学术展示视频的用途出发,提出了四个评价指标: Meta Similarity, PresentArena, PresentQuiz 和 IP Memory。
Paper2Video 基准

图 2: Paper2Video 基准统计概览
Paper2Video 基准收集了来自近三年顶会的 101 篇论文及其作者录制的展示视频,涵盖机器学习、计算机视觉与自然语言处理领域。每个样例包含论文 LaTeX 工程、幻灯片、展示视频、讲者肖像与语音样本,其中部分还提供原始 PDF 幻灯片。数据统计显示,论文平均 13.3K 字、44.7 幅图表,展示视频平均 16 页幻灯片、时长 6 分钟。
作为首个系统化的学术展示视频基准,它为多模态长文档输入与多通道输出(幻灯片、字幕、语音、光标、讲者)的生成与评估提供了可靠依据,为推动自动化学术展示视频生成奠定了基础。
Paper2Video 评价指标

图 3: Paper2Video 评价指标设计
本文从学术展示视频的用途出发,认为其质量应从三个核心视角进行衡量:
类人一致性:生成的视频应与作者精心设计的人类版本保持相似,反映人类偏好。
信息传递性:生成的视频应尽可能涵盖论文中的关键信息,并被受众正确理解。
学术影响力:生成的视频应能突出作者的学术身份,并增强观众对该工作的记忆。
基于上述视角,我们设计了四个互补的评价指标:
Meta Similarity — 类人相似度(内容级): 比较生成的幻灯片、字幕和语音与人类版本的一致性,衡量生成结果在细节和风格上的接近程度。
PresentArena — 类人一致性(观感级): 使用 VideoLLM 作为代理观众进行成对对比,从清晰度、流畅性与吸引力等维度判断生成视频是否符合人类偏好。
PresentQuiz — 信息传递性:通过基于论文构造选择题,使用 VideoLLM 作为代理观众进行问答,测试生成视频能否覆盖并有效传递论文中的关键信息。
IP Memory — 学术影响力:模拟会议场景,使用 VideoLLM 作为代理观众,评估观众是否能够在观看后将视频与作者身份和研究工作正确关联,反映学术可见性与记忆度。
四个指标共同构建了一个覆盖类人偏好、信息传递与学术记忆的系统化评价框架,为学术展示视频生成的客观测评提供了可靠依据。
PaperTalker 多智体架构
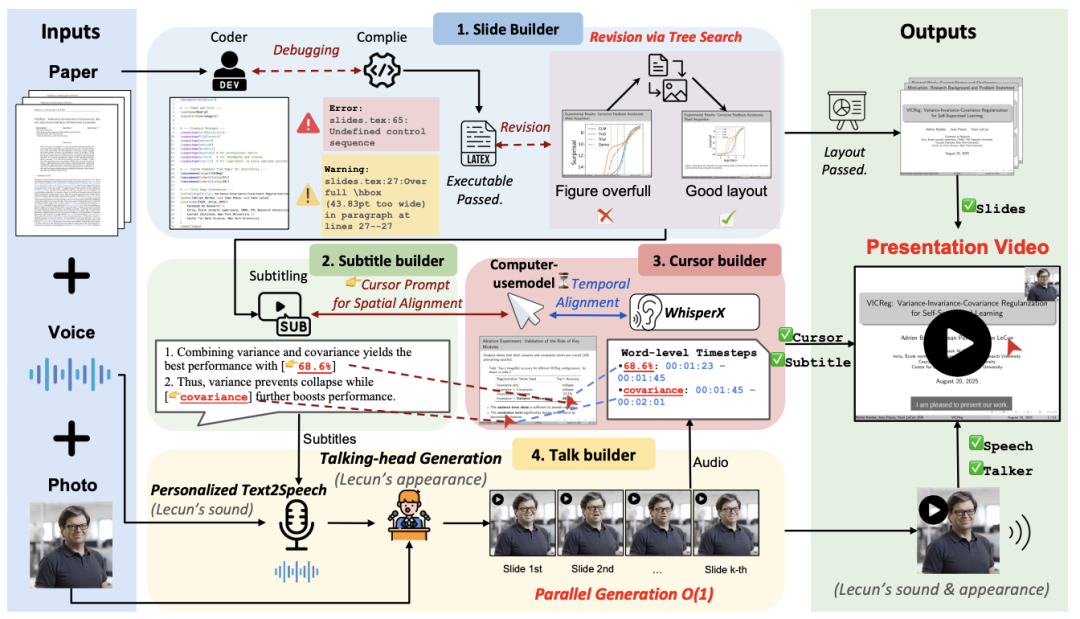
图 4: PaperTalker 流程简介
为解决学术展示视频制作繁琐且难以自动化的问题,本文提出了 PaperTalker —— 首个支持学术展示视频生成的多智能体框架,用于处理这一具有长时依赖的多模态智能体任务(Long-horizon Multi-modal Agentic Task)。该框架以研究论文、讲者图像与语音样本为输入,自动生成包含幻灯片、字幕、语音、光标轨迹和讲者视频 (slide creation, subtitling, speech, cursor highlight, talking head) 的完整展示视频。
PaperTalker 由四个关键构建模块组成:
Slide Builder:基于论文内容生成 LaTeX Beamer 幻灯片,并引入 Tree Search Visual Choice 模块克服大语言模型在细粒度数值调整上的局限,从而优化版面布局,确保幻灯片布局合理设计。
Subtitle Builder:利用视觉语言模型从幻灯片提取关键信息,生成逐句字幕及对应的视觉焦点提示词。
Cursor Builder:结合 UI-Grounding 和 WhisperX 模型,实现光标在时间和空间上的精准对齐,在演讲过程中,引导观众关注关键信息。
Talker Builder:根据讲者肖像与语音样本,合成身份一致、唇形同步的个性化讲者视频,并支持逐页并行生成以提升效率。
由此,PaperTalker 通过模块化的多智能体协作,实现了可控、个性化、学术风格化的展示视频生成。
高效鲁棒的幻灯片生成
在学术展示视频生成任务中,我们测试发现 LaTeX/Beamer 在输出效果与稳定性上显著优于 pptx,能够直接生成学术风格的幻灯片。但在此过程中,即便是闭源 VLM 也难以鲁棒地判断视觉元素(如图片文字大小、排版比例),导致基于多轮交互的参数调优效率极低。
Tree Search Visual Choice 布局优化机制
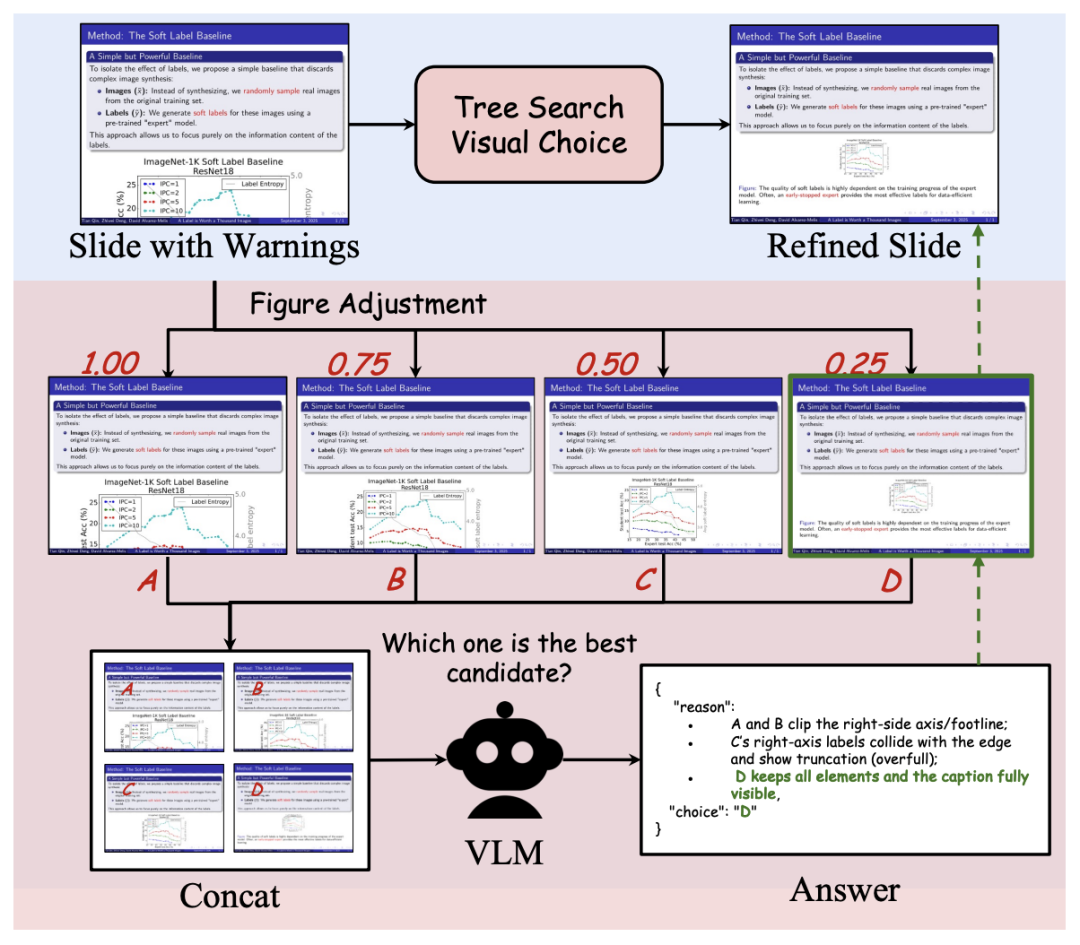
图 5: Tree Search Visual Choice 模块
为此,本文提出 Tree Search Visual Choice:针对给定的视觉素材,预设一组比例参数,渲染得到多种候选布局,并将这些候选拼接成单张大图,交由 VLM 进行一次性的多选比较,从而将低效的多轮参数搜索转化为高效的单轮视觉判别,实现图像尺寸与布局的自动优化。
空间–时间对齐的光标生成
本文进一步探讨了如何模拟人类在讲解过程中使用鼠标的行为。光标轨迹能够引导观众聚焦于幻灯片的关键区域,但实现这一点需要将幻灯片和演讲内容与光标停留点 — 时间戳 — 屏幕空间坐标 (x, y, t) 建立起对应关系。为此,我们引入 Computer-Use 和 WhisperX 模型分别进行空间和时间的标定,实现了时间与空间的双重对齐。
具体来说,我们首先基于幻灯片内容生成逐句字幕及视觉焦点提示,然后利用 UI-TARS 将提示 grounding 为屏幕坐标 (x, y),再通过 WhisperX 获取词级时间戳并对齐到对应的字幕句子,从而得到精确的光标轨迹 (x, y, t)。
高效 Talking-head 生成
在学术展示视频生成中,讲者部分对于增强观众参与感和体现研究者的学术身份至关重要。然而,Talking-Head 渲染通常需要数小时才能生成几分钟的视频,而且部分模型甚至无法原生支持长时段视频的生成,这严重限制了方法的可扩展性与实用性。
为此,本文提出一种高效的解决方案:首先,基于每页幻灯片的字幕与讲者的语音样本,利用 F5-TTS 合成逐页的个性化语音;随后,结合 Hallo2(高保真头像驱动)与 FantasyTalking(支持上半身动作)生成对应的讲者视频。受到人类逐页录制习惯的启发,我们进一步将讲者生成过程 划分为独立的幻灯片片段,并行化执行每页的语音合成与视频渲染。由于幻灯片间存在自然的硬切换,且无需保持跨页的动作连续性,这种设计既保证了身份一致性与唇形同步,又显著提升了整体效率,实验证明这种方式实现了超过 6 倍的加速。
基于 Paper2Video 基准的实验与评估
在实验中,本文对比了三类方法:
(i) 端到端方法(如 Wan2.2、Veo3),直接从文本或提示生成视频;
(ii) 多智能体框架(如 PresentAgent、PPTAgent),将论文内容转化为幻灯片并结合文本转语音生成展示视频;
(iii) 本文提出的 PaperTalker,通过幻灯片生成与布局优化、字幕与光标对齐以及个性化讲者合成来生成的学术展示视频。
学术演示视频性能比较

图 6: 学术演示视频性能比较
Meta Similarity(相似度)
PaperTalker 在幻灯片、字幕和语音的相似度上均取得最高分,说明其生成结果与人类作品最为接近。
个性化 Text-to-Speech 模型与基于 Beamer 的幻灯片生成设计显著提升了相似度表现。
PresentArena(观感质量对比)
在与人类视频的成对对比中,PaperTalker 获得最高的胜率,说明 PaperTalker 视频观感质量最高。
同时,相比去掉讲者和光标的变体,完整的 PaperTalker 视频更受偏好,表明讲者与光标均有贡献。
PresentQuiz(知识传递)
PaperTalker 在问答准确率上超过了其他基线方法,能够更好地覆盖论文信息。
缺少讲者和光标的版本会导致性能下降,表明这些模块有助于增强信息传递。
IP Memory(学术记忆度)
PaperTalker 在观众识别作者与作品的一致性上表现最佳
引入讲者视频(面孔与声音)显著提升了记忆效果。
人类主观评价
人类评价结果显示,人类录制视频得分最高,PaperTalker 次之,且显著优于其他方法,接近人类水平。
实验结果表明,本文提出的 PaperTalker 在 Meta Similarity、PresentArena、PresentQuiz 和 IP Memory 四个维度均取得最佳表现:其生成的幻灯片、字幕与语音更接近人类作品,整体观感更受偏好,知识传递更完整,且在学术身份记忆方面更具优势;同时,人类主观评价也显示 PaperTalker 的视频质量接近人工录制水平。
模型效率比较
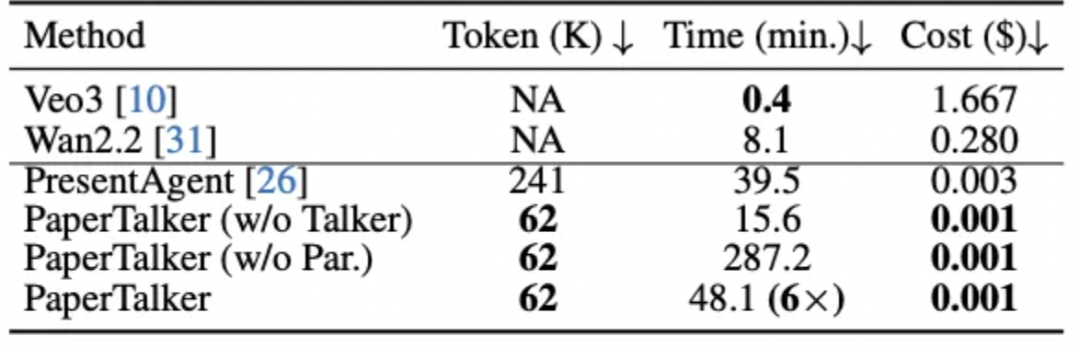
图 7: 模型效率比较
PaperTalker 在生成成本上最低。其效率主要来自三个方面:(i) 基于 Beamer 的幻灯片生成显著减少了 token 消耗;(ii) 引入轻量化的 tree search visual choice 作为幻灯片的后处理;(iii) 采用并行的 talking-head 生成机制缩短了整体运行时间。相比之下,PresentAgent 由于在幻灯片编辑过程中频繁依赖大模型查询,导致成本更高。
消融实验
光标提示对信息定位与理解的贡献

图 8: 光标提示消融实验
光标提示通过提供显式空间线索,帮助观众和 VLM 更好地定位幻灯片中的关键信息。为验证这一点,本文设计了定位问答任务,比较有无光标情况下的答题准确率。结果显示,带光标的视频准确率显著更高,证明了光标在增强学术展示视频的视觉定位与内容可达性方面的重要作用。
Tree Search Visual Choice 在幻灯片质量提升中的作用

图 9: Tree Search Visual Choice 消融实验
为评估 Tree Search Visual Choice 模块的贡献,本文进行了消融实验(表 5),利用 VLM 从内容、设计与连贯性三个维度对生成的幻灯片进行 1–5 分评价。结果显示,当去除该模块时,幻灯片的设计质量明显下降,说明该方法在解决版面溢出问题、提升整体设计质量方面发挥了关键作用。图 9 展示了该模块的性能。

图 10: Tree Search Visual Choice 可视化
结语
本文提出 Paper2Video 基准与 PaperTalker 框架,为学术展示视频生成提供了系统化任务与评测体系。实验验证了其在信息传递、观感质量与学术记忆方面的优势,生成效果接近人工水平。我们期待这项工作能推动 AI4Research 的发展,促进科研交流的自动化与规模化。
Paper2Video生成Paper2Video学术视频

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com




![2025年中国工业连接器行业产业链、市场规模及发展前景展望:受工业自动化领域需求推动,行业市场规模达295.94亿元[图]](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-11-24/6923ae7c1782e.jpeg)