
2025 年 8 月,OpenAI 发布了 gpt-oss,作为继 GPT-2 之后再次开源的 open-weights model,提供了 120b 和 20b 两个 reasoning models。一经推出,迅速获得 AWS、GCP 等云厂商,以及 Ollama、LM Studio、vLLM、Transformers 和 TensorRT-LLM 等推理引擎的广泛支持。出于对 LLM 底层的好奇,并受到 llama.cpp,llama2.c 等聚焦在 edge device 上做 inference 项目的灵感激发,我尝试使用 Java 移植(port)gpt-oss 推理引擎在 CPU 上运行。最终用约 1000 行有效代码,实现了一个小巧精简的高性能纯 CPU 推理引擎。于是就诞生了 https://github.com/amzn/gpt-oss.java ,发布在了亚马逊官方 github 上。本文分享一些开发过程中的实践体会。
gpt-oss 在模型架构上没有引入过多创新,延续了主流设计。模型使用 tiktoken 做 tokenization 分词,采用 decode-only MoE 架构,RoPE 做位置编码,并选用了性价比更好的 RMSNorm 做 normalization。在注意力层,使用了 Grouped Query Attention,相比于 MHA 大幅减少了 kv cache 内存占用的同时,保证了模型能力,Sliding Window Attention 和 full context 交替做注意力计算,进一步降低了计算复杂度。在 MLP FFN 层,不用 dense 稠密结构,采用 MoE 架构,例如 20b 共有 24 层,每层包含 32 个专家,而每次 forward pass 仅激活 4 个专家来降低计算压力,另外,使用 SwiGLU 作为激活函数。特别的是,模型参数采用了 mxfp4 量化,20b 模型文件大小仅约 13GB。所有这些设计都是兼顾模型能力和推理效率,这样 120b 可以在单卡 80GB GPU,20b 可以在单卡 16GB GPU 上运行。
下图转自 Sebastian Raschka 的博客,写的非常好,概括了自 GPT-2 以来的一些关键技术演进,推荐深入阅读。

要从 0 到 1 用 Java 打造一个推理引擎,就需要 port gpt-oss 原生的 PyTorch 实现 model.py。gpt-oss 之所以被称为 open-weight model,就是开源了这个模型架构的 model.py 以及公开了模型参数。至于训练细节和数据没有披露(如果再公开这些才能叫做真正的 open-source,例如 OLMo 2)。
在 Java 移植过程中,代码结构参照了 model.py 的设计,主要包括以下模块:
模型加载:使用原生 gpt-oss model.safetensors 格式
基础算子:矩阵运算 matmul,RMSNorm,softmax
Attention block: QKV 计算,GQA 注意力计算,结合 sliding window 和多头注意力的 scaled dot product,RoPE 位置编码
MLP block:专家路由,SwiGLU 激活函数,MLP projection
采样 sampling:目前只使用基础的 temperature,没有加入 top p,repeat penalty
具体实现可参阅项目源码。这部分工作相对来说比较直接,虽然 PyTorch 封装抽象的层次很高,但是借助已有的成熟实现和互联网资料,经过一些时间的调试,最终可以正确执行推理。下文聚焦在一些关键实现与性能优化。
gpt-oss 的模型文件(model.safetensors)采用 mxfp4 量化了 MLP 层的参数,并使用 u8 类型做 block level 的 scale 缩放参数,其余参数采用 bf16,具体参考 huggingface model card,4-bit 量化极致优化了推理时所需要的内存要求。由于 CPU 不支持这些特殊的数据类型,对于计算密集型的注意力计算以及 MLP 层的 projection,最终都需要转换成 IEEE 754 单精度浮点数在 CPU 上运算,由于原始模型时 4-bit 量化,如何加载并高效的计算这些浮点数对于性能至关重要。
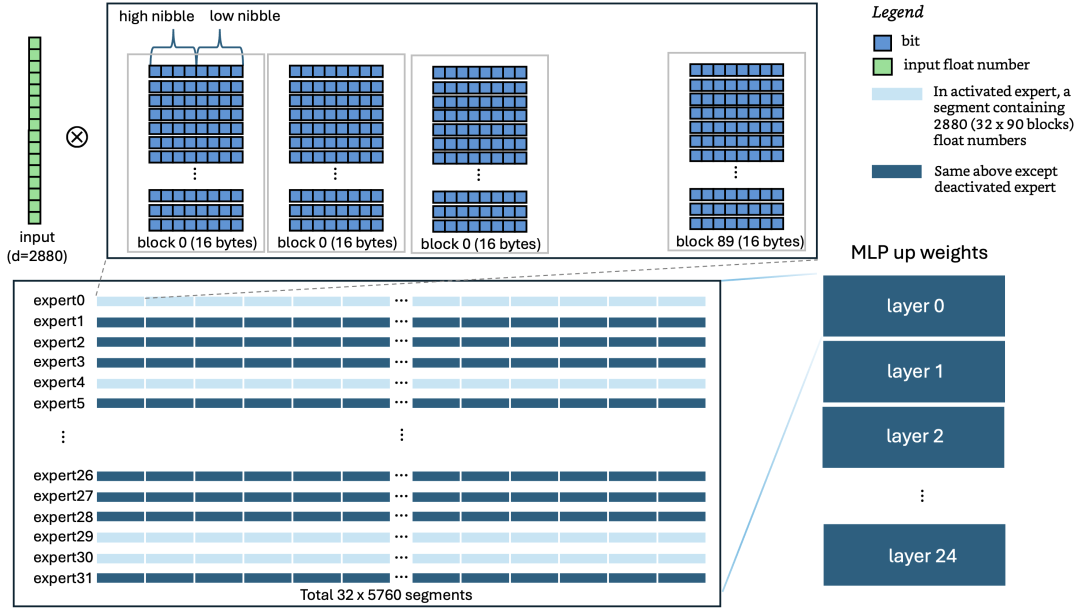
首先介绍一下计算过程,以 gpt-oss 20b 的 MLP up projection 为例。在 decode 阶段,需要经过 24 层(每层 32 个专家),每层内部先通过 RMSNorm 将输入 tensor 转换为 2880 维的 vector。随后每层再选择 4 个专家做 up projection,输出 5760 维的 vector。这是整个 forward pass 计算量很大的一个环节,每个专家的 tensor 维度是 [5760, 2880],2880 维的 vector 要和一个 5760 x 2880 的矩阵做乘法(ps:这 2880 一列的数据顺序存储在一个 shape 为 [90, 16] 的 U8 类型 tensor 中)。参考 3blue1brown 的一个可视化展示,类比来说,2880 维的 vector 是 E,和 [5760, 2880] 维的矩阵 R 做乘法。

注:图片转自 3blue1brown
接下来,分析下实现考量。通常如果工作在 GPU 上,可以使用 cuBLAS、CUTLASS 库或者手工 CUDA 编程来做矩阵运算,而在 CPU 上基本思想类似,同样依赖线程级与指令级并行,并且需最大化流水线效率避免 memory stall。mxfp4 把每个浮点数参数仅用 4-bit 表示,2 个浮点数参数以小尾端存储在一个 byte 里面,分别存储在 high nibble(高 4 位)和 low nibble(低 4 位)中。在 C++ 中,可利用 mm_shuffle_epi8 等 SIMD 指令横跨多个 bytes 并行提取 nibbles 存储在 CPU 的 vector unit 中,每个 nibble 存的是下面 look up table 字典的索引 index。
MXFP4_VALUES = {+0.0f, +0.5f, +1.0f, +1.5f, +2.0f, +3.0f, +4.0f, +6.0f,-0.0f, -0.5f, -1.0f, -1.5f, -2.0f, -3.0f, -4.0f, -6.0f};
并行做查表转换成浮点数的参数,并行乘以 block level 的 scale 系数后,交错(interleave)高低位并利用 FMA(fused multiply–add)指令与输入的 vector 并行进行点积累加,这样各个计算环节都做了充分的指令级并行。Java 的 Project Panama 同样提供了使用 CPU 指令级并行的 Vector API,在这个项目中深度发挥了其威力。在这之上,再加上多线程并行可以大大加速计算。

在不进行优化的情况下,原始 PyTorch 实现在一台 m5.4xlarge AWS EC2 实例(8 物理核心、16 vCPU)上的 decode 性能仅为 0.04 token/sec。尽管 Java 有强大的虚拟机和 JIT,但直接 port 过来不会跑很快。所以我做了下面的性能优化,最终在相同的环境上可以达到~7 tokens/sec 的 decode 和~10 tokens/sec 的 prefill。
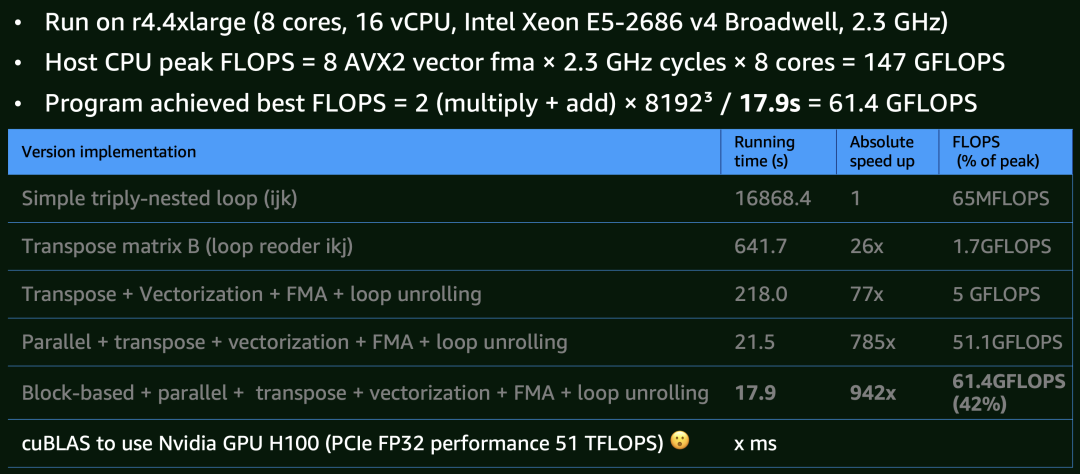
LLM 本质上由可执行程序与 model weights 两部分构成,程序依赖一些线性代数的算子,核心的算子大多需要矩阵计算。如下图所示,我在 m4.4xlarge AWS EC2 实例(8 物理核,16v CPU)对 8k x 8k 矩阵乘法进行了多轮实验。
基础版本:三循环(triply-nested loop)矩阵计算,性能表现较差。 CPU 缓存优化:提高 CPU cache spatial locality,例如做矩阵转置,模型参数在内存上顺序存放,会有 26x 的提升。 想量化加速:再进一步利用 Java Project Panama 提供的 CPU SIMD 向量化指令,同时做 4x loop unrolling 进一步降低指令依赖来加速,提速 77x。 多核并行:充分利用 16 vCPU(尽管超线程无法达到物理核心翻倍的性能),达到基准性能的 785 倍。 分块计算:进一步优化 CPU cache 命中率,使用 block/tile based 计算方式,提速 942 倍。这时候已经达到了这台物理机实际 147 GFLOPS 的 42% 的算力了。考虑到流水线可能还会因为 memory stall 打断而有些 choke point,当前优化暂告一段落。值得注意的是,即便 Intel MKL 库也未能完全打满硬件算力。
作为对比,如果使用 cuBLAS 跑在 Nvdia H100 GPU(即使不用 tensor core),其 FP32 理论算力可达 51 TFLOPS,较 CPU 实现高出三个数量级,这个数字直观的体现了 GPU 在并行计算方面的巨大优势,而 CPU 更适用于通用计算场景。
gpt-oss.java 中矩阵乘法实现参见 ParallelMatMul.java
为了让 CPU 达到尽量满的负荷,除了矩阵计算做并行,其他关键计算环节也做了并行化:GQA scaled dot product 以及 MLP 层的 4 个专家的并行执行。
项目采用了 Java Foreign Memory API 通过内存映射(mmap)方式加载 MLP weights,这样使得模型仅需 16GB 内存就可以运行。更大的内存容量可使 Page Cache 更有效地缓存 MLP weights,避免关键路径上的磁盘 I/O,从而提升推理性能。
在 MLP 层做 up & down projection 时,由于 MLP weights 都用了 mmap,而 Java SIMD API 提供了直接加载 mmap segment 到 CPU vector register 的指令,避免了 JVM 中间的内存拷贝。
在代码里面有大量的中间数据,可以提前预分配,后续只做原地的读写,避免频繁内存分配。虽然 JVM 有强大的 GC,但是如果可以做到 GC-less programming,那么这块的开销也可以避免。
由于很多计算都有依赖,所以可以合并操作,尽量减少计算量和迭代次数。但为保持代码可读性与可维护性,当前实现中仅有限度地采用了这个优化。
KV cache 是所有 LLM inference 的标配。本项目采用了最原始的根据 max tokens 来提前预分配 KV cache,由于采用了 Grouped-Query Attention (GQA),内存占用也大大降低。
在 MacOS - Apple M3 Pro 上,推理速度 decode 8.7 tokens/sec,prefill 11.8 tokens/sec。
在 AWS EC2 m5.4xlarge 实例,推理速度 decode 6.8 tokens/sec,prefill 10 tokens/sec。
性能高于 PyTorch 原始的 0.04 tokens/sec,Huggingface transformers 的~3.4 tokens/sec,但是低于 llama.cpp 工作在 mxfp4 GGUF v3 模型下的 16.6 tokens/sec,llama.cpp 同样采用了 mxfp4 量化计算,更直接的底层 SIMD 使用,更好的线程 scheduling,更深入的算子优化以及 C++ 本身的性能。更多数据详细 见此。
这次实践具有很高的学习价值,从 0 到 1 仅 1000 行代码实现一个 MoE 架构的 LLM,复刻 PyTorch 实现的同时,也深刻体会了 PyTorch 作为非生产环节的使用,极大了提高了模型架构的开发门槛,像搭乐高一样,通过组装 building blocks 即可搭建好模型,这些模块化设计也使得移植工作更加顺利。
在性能方面,达到了一个还不错的结果,可以运行在个人电脑和 EC2 上。当然如果想获得更好的体验和性能,还是需要 Ollama,LMStudio 等这些专业在端侧部署的单机推理引擎。LLM 推理是一个领域热点,不同于 pre-training,post-training,这里面主要依赖工程优化,vLLM,TensorRT-LM,ONNX 等正是工业界高性能推理的代表。
Java 在性能上在不断的提高:Project Leyden 致力于降低启动时间,Lilliput 优化对象存储空间,Loom 加入 virtual threads,Panama 桥接 Java 和 native code,Valhalla 提供 compact object 等等,更好的 ZGC,以及 AOT GraalVM。这些进步使得 Java 在计算效率和更底层的语言上差距越来越小,这一点在我前年做了 lama2.java port llama2.c 的时候已经证明了,Java port 可以达到一个 O3 优化程序性能的 95%。所以,Java 也可以跑的很快,只需要你识别好的 workload 和热点,并采用恰当优化手段。
张旭,Amazon Principal Software Engineer
后续我将通过微信视频号,以视频的形式持续更新技术话题、未来发展趋势、创业经验、商业踩坑教训等精彩内容,和大家一同成长,开启知识交流之旅
欢迎扫码关注我的微信视频号~

今日荐文

你也「在看」吗?👇










