
论文题目:Reward Reasoning Models
论文地址:https://arxiv.org/pdf/2505.14674
代码地址:https://thegenerality.com/agi/

创新点
与传统奖励模型直接输出标量分数不同,RRMs 在生成最终奖励前会先进行逐步推理,通过链式思考(chain-of-thought)过程,使模型能够更深入地理解问题和回答的内容,从而提高奖励判断的准确性。
该框架能够在基于规则的奖励环境中,鼓励 RRMs 自我进化奖励推理能力,而无需依赖显式的推理轨迹作为训练数据,降低了数据准备的难度和成本。
为适应不同的实际应用场景,文中引入了 ELO 评分系统和淘汰赛两种多回应奖励策略,使 RRMs 可以灵活地处理一个查询的多个候选回应,既可用于生成完整的评分,也可用于确定最佳回应。
方法
本文主要研究方法是提出奖励推理模型(RRMs),其核心在于将奖励建模视为一个推理任务,让模型在生成最终奖励前先进行链式思考推理过程,以提高奖励估计的准确性。具体而言,RRMs 接受包含查询和两个对应回应的输入,根据系统提示对两个回应进行多方面评估,通过逐步推理输出最终决策。
不同奖励模型在 Preference Proxy Evaluations 上的平均准确率

本图展示了在 MMLU-Pro、MATH 和 GPQA 子集上,各种奖励模型的平均准确率对比。RRM 在不同模型大小下均优于之前的奖励模型,并且在未标记数据上使用 RRM 作为奖励模型进行强化学习,也能显著提升 GPQA 的准确率,这表明 RRM 在多领域奖励建模基准测试中具有优越性能。
奖励推理模型
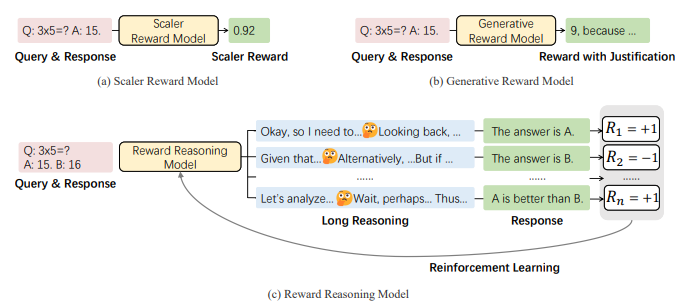
本图a展示了标量奖励模型的输入输出形式,直接输出一个标量奖励值;图b 展示了生成式奖励模型的输入输出形式,除了输出奖励值外,还会生成带有解释的奖励反馈;图c 展示了 RRMs 的输入输出形式,其输入是查询和对应的两个回应,输出是经过链式思考推理过程后,对两个回应的判断及最终决策。
使用 RRM 进行强化学习后 GPQA 的准确率

本图横坐标是强化学习训练步骤,纵坐标是 GPQA 的准确率。随着训练步骤的增加,GPQA 的准确率稳步提升,这表明即使在没有真实答案的情况下,使用 RRM 作为奖励模型的强化学习也能有效地提高模型的性能。
实验结果

本表总结了 RRMs 在与其他基线模型对比下的性能表现。总体来看,RRMs 在多个领域中表现出色,特别是在推理领域,其中 RRM-32B 的准确率达到了 98.6%。与直接生成判断的 DirectJudge 模型相比,RRMs 的性能明显更好,这说明 RRMs 通过在测试时进行推理能够有效提升模型表现。此外,RRMs 在与大规模模型如 GPT-4 和 Claude 3.5 Sonnet 的对比中也显示出竞争力。总体而言,RRMs 能够有效地产生与人类偏好一致的奖励信号,这表明将推理过程纳入奖励模型的设计中是一种有效的方法。
-- END --

关注“学姐带你玩AI”公众号,回复“2025大模型”
领取2025大模型创新方案合集+开源代码











