(1) ReasonRank:赋予段落排序强大的推理能力!(80 票)
论文原始英文标题:
ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability
论文链接:
https://huggingface.co/papers/2508.07050
paperscope.ai 解读:
https://paperscope.ai/hf/2508.07050
简要介绍:
该研究由中国人民大学、百度等机构提出,旨在解决现有段落重排模型在处理需要复杂推理的查询时能力不足的问题。传统的大语言模型(LLM)重排器虽然在列表排序(listwise ranking)上表现出色,但由于缺乏推理密集型的训练数据,它们在面对复杂问答、编程、数学等场景时常常表现不佳。
为解决这一难题,作者们首先提出了一个自动化的推理密集型训练数据合成框架。该框架能从不同领域(复杂问答、编程、数学、网页搜索)收集查询和段落,并利用强大的推理模型 DeepSeek-R1 生成高质量的训练标签,包括推理链和黄金排序列表。为了保证数据质量,他们还设计了一种自洽性数据过滤机制。
有了高质量的数据,作者进一步提出了一个两阶段训练框架 ReasonRank 来赋能列表排序重排器。第一阶段是“冷启动”监督微调(SFT),让模型学习列表排序中的推理模式。第二阶段是强化学习(RL),通过设计一种新颖的“多视角排序奖励”(multi-view ranking reward)来进一步提升模型的排序能力。这种奖励机制不仅考虑单轮排序的NDCG指标,还兼顾了滑动窗口策略下多轮排序的特性,比单一指标奖励更有效。
实验结果非常亮眼,ReasonRank 在两个推理密集型信息检索基准 BRIGHT 和 R2MED 上均取得了当前最佳(SOTA)性能,并且在 BRIGHT 排行榜上达到了 40.6 的高分。更重要的是,相比逐点排序(pointwise)的 Rank1 模型,ReasonRank 在实现更高精度的同时,推理延迟也大大降低,展示了其在效果和效率上的双重优势。
核心图片:

(2) WideSearch:为“广域信息搜寻”智能体立下新标杆!(76 票)
论文原始英文标题:
WideSearch: Benchmarking Agentic Broad Info-Seeking
论文链接:
https://huggingface.co/papers/2508.07999
paperscope.ai 解读:
https://paperscope.ai/hf/2508.07999
简要介绍:
来自字节跳动(ByteDance)的研究团队推出了 WideSearch,这是一个全新的基准测试,专门用于评估 AI 智能体在“广域信息搜寻”任务中的可靠性和完整性。这类任务的特点不是认知难度高,而是需要大规模、地毯式地搜集所有满足特定条件的原子信息,并将其整理成结构化输出,例如“找出某个行业所有收入和增长率达标的公司”。这种任务对人类来说极其繁琐,而 AI 智能体正是理想的自动化解决方案。
然而,现有基准大多关注“深度搜索”(DeepSearch,寻找难找的特定事实)或“深度研究”(DeepResearch,综合信息写报告),忽视了 WideSearch 这种“广度优先”的场景。为此,研究团队构建了 WideSearch 基准,包含 200 个横跨超过 15 个不同领域(如金融、教育、医疗等)的真实用户问题(中英文各 100 个)。每个任务都要求智能体收集大量可被客观逐一验证的信息,并通过了严格的五阶段质量控制流程来确保其难度、完整性和可验证性。
研究团队在该基准上测试了超过 10 个顶尖的智能搜索系统,包括单智能体、多智能体框架和商业闭源系统。结果令人震惊:**大多数系统的整体成功率接近 0%,表现最好的也仅有 5%**。相比之下,人类测试者在有足够时间和交叉验证的情况下,成功率能接近 100%。这一巨大差距表明,当前的 AI 智能体在处理大规模信息搜集任务时存在严重缺陷,主要体现在规划不完整、缺乏对失败搜索的反思与迭代、以及无法正确利用检索到的证据。这项工作为未来智能体搜索技术的发展指明了亟待改进的关键方向。
核心图片:

(3) Omni-Effects:一统江湖!统一且空间可控的视觉特效生成!(45 票)
论文原始英文标题:
Omni-Effects: Unified and Spatially-Controllable Visual Effects Generation
论文链接:
https://huggingface.co/papers/2508.07981
paperscope.ai 解读:
https://paperscope.ai/hf/2508.07981
简要介绍:
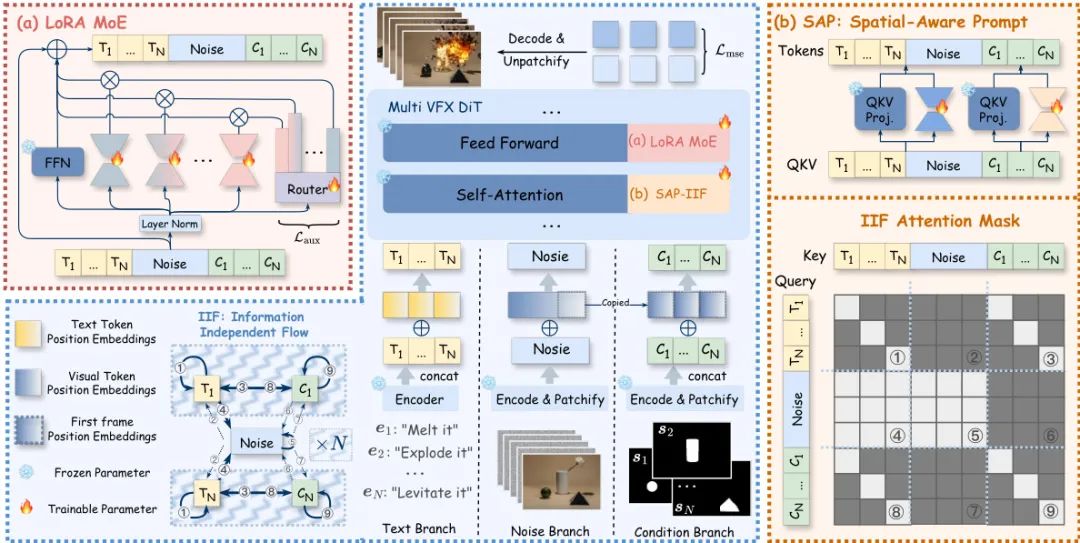
阿里巴巴AMAP团队提出了一种名为 Omni-Effects 的统一视觉特效(VFX)生成框架,首次实现了在单个模型中生成多种由文本提示引导的、并且可以在空间上精确控制的复合视觉特效。目前的视频生成模型在处理VFX时,通常需要为每种特效单独训练一个LoRA模型,这使得同时在不同位置生成多种特效(如左边的椅子融化,右边的椅子悬浮)变得极为困难,存在“跨适配器干扰”和“空间-语义错位”两大核心挑战。
为了解决这些问题,Omni-Effects 框架引入了两大创新:
基于LoRA的专家混合(LoRA-MoE):该模块使用一组“专家LoRA”来分别处理不同的特效,通过一个门控路由器动态激活相关的专家,从而在一个统一模型中集成多种特效,同时有效避免了任务间的相互干扰,保证了特效的保真度。 空间感知提示(Spatial-Aware Prompt, SAP):该技术将空间掩码(mask)信息直接编码到文本token中,实现了对特效位置的像素级精准控制。为了防止在生成多种特效时控制信号之间互相“串扰”,作者还设计了独立信息流(Independent-Information Flow, IIF)模块,通过特制的注意力掩码隔离不同特效的控制信号,确保它们独立作用。
为了支持这项研究,团队还构建了一个全面的VFX数据集 Omni-VFX,并通过一种新颖的数据生产线,结合图像编辑和首尾帧到视频(FLF2V)合成技术,涵盖了 55 种不同的特效类别。实验证明,Omni-Effects 在单特效、多特效和可控特效生成任务上均表现出色,能够让用户精确指定所需特效的类别和位置,为电影制作、游戏开发等领域带来了极具潜力的工具。
核心图片:
(4) Klear-Reasoner:梯度裁剪策略优化,推动推理能力新高度!(24 票)
论文原始英文标题:
Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization
论文链接:
https://huggingface.co/papers/2508.07629
paperscope.ai 解读:
https://paperscope.ai/hf/2508.07629
简要介绍:
来自快手 Klear 团队的研究者们推出了 Klear-Reasoner,一个在解决问题时展现出深思熟虑的长推理链能力的模型,并在多个数学和编程基准测试中取得了卓越性能。尽管社区中已有许多优秀的推理模型,但由于训练细节不透明,复现高性能模型仍充满挑战。这份报告深入剖析了推理模型的整个训练流程,从数据准备、长思维链监督微调(long CoT SFT)到强化学习(RL),并对每个环节进行了详尽的消融研究。
研究发现,在 SFT 阶段,少数高质量数据源比大量多样化数据源更有效,并且对于难题,即使不过滤掉不正确的样本也能取得更好效果,因为这些困难的错误可能反而促进了模型的探索。
在 RL 阶段,研究者指出现有 PPO 算法中的裁剪机制存在两大问题:一是裁剪会抑制关键的探索信号,尤其是在关键决策点上的高熵(高不确定性)词元;二是裁剪会忽略次优轨迹,导致模型从负样本中学习的效率降低。
为了解决这些问题,他们提出了梯度保留裁剪策略优化(Gradient-Preserving clipping Policy Optimization, GPPO)。GPPO 即使对被裁剪的词元也允许温和的梯度反向传播,从而在保持训练稳定性的同时,保留了宝贵的梯度信息,增强了模型的探索能力和从负样本中学习的效率。
基于 Qwen3-8B-Base 模型,通过 long CoT SFT 和 GPPO 强化学习,训练出的 Klear-Reasoner-8B 在多个推理基准上表现出色,例如在 AIME 2024/2025 上分别取得了 90.5% 和 83.2% 的高分,在 LiveCodeBench V5/V6 上也达到了 66.0% 和 58.1% 的准确率,性能超越了同规模的 SOTA 模型。
核心图片:

(5) SONAR-LLM:会用句子嵌入思考,用词元说话的自回归Transformer!(22 票)
论文原始英文标题:
SONAR-LLM: Autoregressive Transformer that Thinks in Sentence Embeddings and Speaks in Tokens
论文链接:
https://huggingface.co/papers/2508.05305
paperscope.ai 解读:
https://paperscope.ai/hf/2508.05305
简要介绍:
该研究由 AIRI、莫斯科国立大学等多家机构合作提出,介绍了一种名为 SONAR-LLM 的新型解码器-专用(decoder-only)Transformer 模型。它巧妙地结合了两种主流文本生成范式的优点:既能像“大概念模型”(LCM)一样在连续的句子嵌入空间中进行“思考”,又能像传统自回归语言模型一样,通过词元级别(token-level)的交叉熵损失进行监督和生成“说话”。
传统 LLM 逐词元生成文本,虽然简单有效,但在处理长序列时速度很慢。最近提出的 LCM 模型通过预测句子级别的嵌入序列来加速,但它使用均方误差(MSE)或扩散目标进行训练,放弃了基于概率的训练信号,导致优化不稳定。
SONAR-LLM 的核心创新在于其混合训练目标:模型在自回归过程中预测下一个句子的 SONAR 嵌入向量,然后将这个预测的向量通过一个冻结的 SONAR 解码器转换回词元级别的概率分布。最终,模型的损失是在词元级别计算的,但梯度会通过这个冻结的解码器反向传播,从而指导句子嵌入的预测。这种设计既保留了 LCM 的语义抽象能力,又恢复了传统 LLM 基于概率的稳定训练信号,并且无需扩散采样器,使得单次前向传播就能生成一个完整的句子。
研究团队训练了从 39M 到 1.3B 参数不等的多个尺寸的 SONAR-LLM 模型,并在文本生成和摘要任务上进行了评估。结果显示,SONAR-LLM 在生成质量上具有竞争力,其扩展定律(scaling law)也表现良好。此外,理论分析表明,在处理长序列时,SONAR-LLM 的推理效率远高于标准 LLM。
核心图片:

(6) UserBench:一个面向用户的交互式智能体Gym环境!(21 票)
论文原始英文标题:
UserBench: An Interactive Gym Environment for User-Centric Agents
论文链接:
https://huggingface.co/papers/2507.22034
paperscope.ai 解读:
https://paperscope.ai/hf/2507.22034
简要介绍:
Salesforce AI Research 和伊利诺伊大学香槟分校的研究者们推出了 UserBench,一个以用户为中心的基准测试环境,旨在评估大语言模型(LLM)智能体在与用户进行多轮、偏好驱动的交互时的协作能力。
现有的大模型智能体在推理和工具使用方面取得了长足进步,但它们往往忽略了用户的核心作用,尤其是在用户目标模糊、不断变化或表达间接时。为了弥补这一差距,UserBench 设计了一个模拟用户环境,这些模拟用户起始目标不明确,并会逐步透露自己的偏好。这要求智能体必须主动提问以澄清意图,并结合工具做出有根据的决策。
UserBench 基于标准的 Gymnasium 框架构建,提供模块化、可扩展的设置。它以旅行规划为核心任务,涵盖了航班、酒店、租车等五个方面,并精心设计了超过4000个场景。这些场景的核心特点是模拟了真实人类沟通的三大特质:目标不明确(Underspecification)、意图渐进式展现(Incrementality)和表达间接(Indirectness)。
研究团队对多个顶尖的开源和闭源大模型进行了测试,发现了一个显著的问题:模型的任务完成能力与其用户对齐能力之间存在巨大脱节。例如,模型给出的答案完全符合所有用户意图的平均情况仅为 **20%**。即便是最先进的模型,通过主动交互发现的用户偏好也不到 **30%**。这些结果凸显了当前智能体虽然是能干的“任务执行者”,但远未成为真正的“协作伙伴”。UserBench 为衡量和提升这种关键能力提供了一个重要的交互式平台。
核心图片:

(7) AI智能体自演化全面综述:连接基础模型与终身学习的新范式!(20 票)
论文原始英文标题:
A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems
论文链接:
https://huggingface.co/papers/2508.07407
paperscope.ai 解读:
https://paperscope.ai/hf/2508.07407
简要介绍:
由格拉斯哥大学、谢菲尔德大学、剑桥大学等多所顶尖高校联合发布的这篇综述,全面回顾了自演化AI智能体(Self-Evolving AI Agents)这一新兴领域。随着大语言模型(LLM)的发展,AI智能体在解决复杂现实任务上取得了显著进展。然而,大多数现有智能体系统依赖于部署后保持静态的手动配置,这限制了它们在动态变化环境中的适应能力。
为了克服这一局限,研究者们开始探索智能体演化技术,使系统能根据交互数据和环境反馈自动进行优化。这催生了“自演化AI智能体”的新范式,它旨在将基础模型的静态能力与终身智能体系统所需的持续适应性连接起来。
这篇综述提出了一个统一的概念框架,抽象出自演化智能体系统设计的核心反馈循环,该循环包含四个关键组成部分:系统输入(System inputs)、智能体系统(Agent System)、环境(Environment)和优化器(Optimisers)。基于此框架,论文系统地梳理了针对智能体系统不同组件(如基础模型、提示、记忆、工具、工作流和通信机制)的各种自演化技术。此外,它还探讨了在生物医学、编程和金融等特定领域的演化策略,并专门讨论了评估、安全和伦理等关键问题。
作者还提出了自演化AI智能体的三定律,作为其安全有效演化的指导原则:
忍耐(安全适应):在任何修改过程中必须保持安全和稳定。 卓越(性能保持):在遵守第一定律的前提下,必须保持或增强现有任务性能。 演化(自主优化):在遵守前两条定律的前提下,必须能够自主优化内部组件以响应不断变化的任务、环境或资源。
这篇综述为研究人员和从业者提供了对自演化AI智能体的系统性理解,为开发更具适应性、自主性和终身学习能力的智能体系统奠定了基础。
核心图片:

(8) BrowseComp-Plus:一个更公平、透明的深度研究智能体评测基准!(15 票)
论文原始英文标题:
BrowseComp-Plus: A More Fair and Transparent Evaluation Benchmark of Deep-Research Agent
论文链接:
https://huggingface.co/papers/2508.06600
paperscope.ai 解读:
https://paperscope.ai/hf/2508.06600
简要介绍:
滑铁卢大学等机构的研究者们推出了 BrowseComp-Plus,这是一个旨在解决当前“深度研究”(Deep-Research)智能体评测基准痛点的新框架。深度研究智能体结合了大语言模型(LLM)和搜索工具,擅长处理需要迭代式搜索和推理的复杂查询。然而,现有的评测基准(如 BrowseComp)大多依赖于实时的、黑盒的网页搜索API,这带来了三大问题:
公平性受损:动态变化的网页内容和不透明的搜索API使得不同模型间的公平比较和实验复现变得极为困难。 透明度不足:由于无法控制检索的文档语料库,很难将检索器(Retriever)的贡献与LLM智能体本身的推理能力分离开来,导致评测结果混杂。 可及性差:依赖商业搜索API带来了高昂的成本和不稳定的检索质量。
为了解决这些问题,BrowseComp-Plus 采用了一个固定的、精心策划的文档语料库。它源自 BrowseComp,但为每个查询都配备了经过人工验证的“支持性文档”和精心挖掘的“困难负样本”(hard negatives)。这种设计使得研究者可以进行受控实验,独立评估检索器和LLM智能体的性能,从而实现对深度研究系统各组件的解耦分析。
实验表明,该基准能有效地区分不同深度研究系统的性能。例如,开源模型 Search-R1 配合 BM25 检索器的准确率仅为 3.86%,而 GPT-5 则能达到 55.9%。如果将 GPT-5 与更强的 Qwen3-Embedding-8B 检索器结合,准确率能进一步提升至 70.1%,同时搜索次数也更少。BrowseComp-Plus 不仅促进了对深度研究智能体和检索方法的全面、可复现的评估,还为深入理解检索效果、引用准确性和上下文工程等关键问题提供了宝贵的洞见。
核心图片:

(9) OmniEAR:评测智能体在具身任务中的推理能力!(14 票)
论文原始英文标题:
OmniEAR: Benchmarking Agent Reasoning in Embodied Tasks
论文链接:
https://huggingface.co/papers/2508.05614
paperscope.ai 解读:
https://paperscope.ai/hf/2508.05614
简要介绍:
浙江大学的研究团队推出了 OmniEAR,一个全面用于评估大语言模型在具身任务(embodied tasks)中推理能力的框架。尽管大语言模型在抽象推理上表现出色,但它们在需要与物理世界交互的具身智能(如机器人操作)方面的推理能力仍是未解之谜。
现有的具身智能基准存在明显不足:它们要么提供预定义的工具集,要么给出明确的协作指令,而无法评估智能体是否能根据任务需求动态获取能力和自主决定协作策略。此外,它们通常将环境状态离散化(如门是开/关),忽略了重量、温度等连续物理属性,而这些属性恰恰是决定行动可行性的关键。
OmniEAR 的核心洞见是,真正的具身推理源于对物理约束的理解。为此,该框架通过基于文本的环境表示,高效地建模了连续的物理属性和复杂的空间关系,涵盖了家庭和工业两大领域的 1500 个场景。其任务设计要求智能体:
根据物体的物理属性(如重量、材质)进行推理。 识别自身能力差距,并主动规划获取和使用工具。 在没有明确指令的情况下,自主判断何时需要多智能体协作。
系统性评估揭示了当前模型的严重短板:在有明确指令时,模型成功率高达 85-96%;但当需要自主推理时,性能急剧下降——工具推理成功率降至 56-85%,隐式协作降至 63%,而复合任务的失败率超过 50%。一个令人惊讶的发现是,提供完整的环境信息反而会损害协作性能,表明模型无法有效筛选出与任务相关的关键约束。这项工作证明了具身推理对当前模型提出了根本性的新挑战,并将 OmniEAR 建立为一个严格的基准,以推动具身AI系统的发展。
核心图片:

(10) MolmoAct:能在空间中推理的行动推理模型!(14 票)
论文原始英文标题:
MolmoAct: Action Reasoning Models that can Reason in Space
论文链接:
https://huggingface.co/papers/2508.07917
paperscope.ai 解读:
https://paperscope.ai/hf/2508.07917
简要介绍:
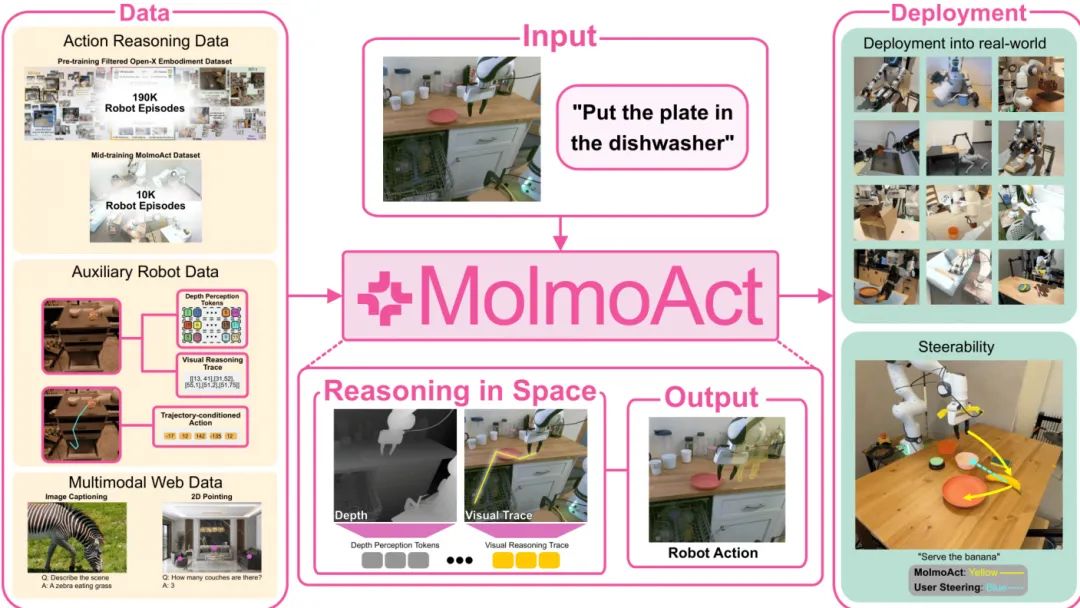
艾伦人工智能研究所(AI2)和华盛顿大学的研究者们共同推出了 MolmoAct,一类新型的视觉-语言-行动(VLA)模型,被称为行动推理模型(Action Reasoning Models, ARMs)。该模型旨在通过在感知和控制之间引入结构化的推理过程,来提升机器人的适应性、泛化能力和语义基础。
传统机器人基础模型通常直接将感知(图像)和指令(语言)映射到控制命令,缺乏中间的规划和推理环节,导致模型行为“黑盒”且脆弱。MolmoAct 创新地提出了一个三阶段的推理流水线:
感知:将观察到的图像和指令编码成带有深度信息的“感知词元”(depth-aware perception tokens)。 规划:生成中等层次的空间规划,表现为可在图像上编辑的“轨迹追踪”(trajectory traces)。 行动:基于规划,预测精确的低层次机器人动作。
这种结构化的设计使得机器人的行为不仅可解释,而且可引导。例如,用户可以通过直接编辑图像上的轨迹来修正机器人的动作,这比模糊的语言指令更可靠。
MolmoAct-7B-D 模型在多个模拟和真实世界基准上取得了优异性能,在 SimplerEnv 视觉匹配任务上零样本准确率达到 70.5%,超越了闭源的 π₀ 和 GR00T N1;在 LIBERO 基准上平均成功率达 86.6%;在真实世界微调中,其任务进展也显著优于 π₀-FAST。
此外,研究团队还首次发布了 MolmoAct 数据集,包含超过 10,000 条高质量的机器人轨迹,用于模型的中期训练(mid-training),使用该数据集能使基础模型的通用性能平均提升 5.5%。所有模型权重、训练代码和数据集均已开源,为构建能够通过结构化推理将感知转化为有目的行动的机器人智能体提供了开放的蓝图。
核心图片:
(11) Grove MoE:伴生专家结构,实现更高效、更卓越的MoE大模型!(12 票)
论文原始英文标题:
Grove MoE: Towards Efficient and Superior MoE LLMs with Adjugate Experts
论文链接:
https://huggingface.co/papers/2508.07785
paperscope.ai 解读:
https://paperscope.ai/hf/2508.07785
简要介绍:
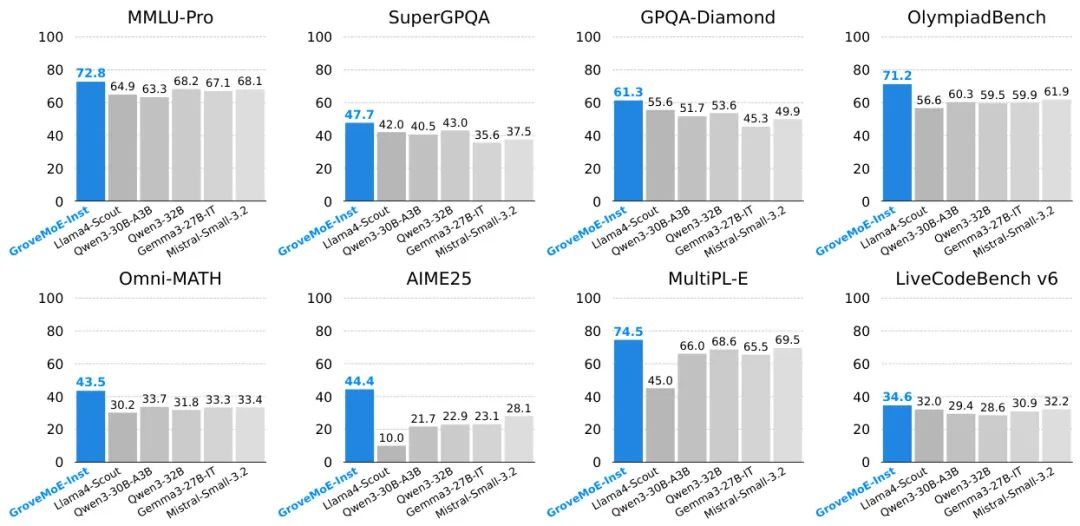
来自 Inclusion AI、香港中文大学、浙江大学等机构的研究者们提出了一种名为 Grove MoE 的新型专家混合(Mixture of Experts, MoE)架构,旨在解决传统 MoE 模型计算效率的局限性。
传统 MoE 架构通过稀疏激活参数来扩展模型规模,但其所有“专家”大小相同,无论输入词元(token)的复杂程度如何,都激活固定数量的参数,这限制了计算资源的有效利用。受到 big.LITTLE CPU 架构(使用不同大小的核心来高效处理计算负载)的启发,Grove MoE 引入了大小异构的专家。
其核心创新是伴生专家(adjugate experts)和动态激活机制。具体来说,所有专家被分成若干组(Grove),每组专家共享一个伴生专家。当路由器激活了同一组内的多个专家时,它们共享的那个伴生专家只会被计算一次,其输出会被加到每个激活专家的输出上。这种设计允许模型根据词元的复杂性动态地激活 3.14B 到 3.28B 的参数,实现了计算资源的动态分配,从而在扩展模型容量的同时保持了可控的计算开销。
基于这一新架构,研究团队通过对 Qwen3-30B-A3B-Base 模型进行“升级再造”(upcycling),开发出了 33B 参数的 GroveMoE-Base 和 GroveMoE-Inst 模型。实验表明,GroveMoE 模型在多个基准测试中取得了与同等甚至更大规模的 SOTA 开源模型相媲美的性能,验证了该架构在效率和效果上的双重优势。
核心图片:
(12) 时序自奖励语言模型:通过过去与未来解耦“选择-拒绝”对!(10 票)
论文原始英文标题:
Temporal Self-Rewarding Language Models: Decoupling Chosen-Rejected via Past-Future
论文链接:
https://huggingface.co/papers/2508.06026
paperscope.ai 解读:
https://paperscope.ai/hf/2508.06026
简要介绍:
北京大学、清华大学等机构的研究者们提出了一种名为时序自奖励语言模型(Temporal Self-Rewarding Language Models) 的新框架,旨在解决现有自奖励(Self-Rewarding)范式中的一个关键缺陷。
自奖励语言模型通过让大语言模型(LLM)同时扮演“生成者”和“评判者”的角色,利用直接偏好优化(DPO)进行迭代式自我提升。然而,研究者通过理论和实证分析发现,随着模型的迭代,其生成的“被选择的”(chosen)和“被拒绝的”(rejected)回答在表示上会变得越来越相似。这种相似性的增加会削弱偏好学习的有效信号,最终导致训练过程崩溃。
为了解决这个问题,新提出的框架通过策略性地协调过去、现在和未来的模型生成来维持有效的学习信号。其核心是一个双阶段框架:
锚定拒绝(Anchored Rejection):使用过去的初始模型(SFT模型)的输出作为固定的“被拒绝”样本。这可以防止负样本的质量随着迭代而“通货膨胀”,从而保持了清晰的负向信号。 未来引导选择(Future-Guided Chosen):利用未来一代模型的预测来动态地筛选高质量的“被选择”样本。具体做法是,在当前模型上先用锚定的拒绝样本进行一次临时的DPO训练,得到一个“未来模型”,然后用这个更强的未来模型生成更好的回答作为正样本。
通过这种“过去-未来”的时间解耦策略,该方法有效地维持了正负样本之间的质量差距。实验在 Llama、Qwen、Mistral 等多个模型家族和不同尺寸(3B/8B/70B)上都取得了显著的性能提升。例如,Llama3.1-8B 使用该方法在 AlpacaEval 2.0 上的胜率达到了 29.44%,远超自奖励基线的 19.69%。该方法甚至在没有专门训练的情况下,在数学推理、知识问答和代码生成等分布外任务上也表现出优越的泛化能力。
核心图片:

(13) 视觉强化学习综述!(7 票)
论文原始英文标题:
Reinforcement Learning in Vision: A Survey
论文链接:
https://huggingface.co/papers/2508.08189
paperscope.ai 解读:
https://paperscope.ai/hf/2508.08189
简要介绍:
来自新加坡国立大学、浙江大学等机构的研究者们共同完成了一篇关于视觉强化学习(Visual Reinforcement Learning, RL) 的全面综述。近年来,强化学习与视觉智能的交叉融合取得了显著进展,催生了能够感知、推理、生成并在复杂视觉场景中行动的智能体。
这篇综述系统地梳理了该领域的最新进展。首先,它形式化地定义了视觉RL问题,并追溯了策略优化策略的演变,从基于人类反馈的强化学习(RLHF)到可验证奖励范式,以及从近端策略优化(PPO)到组相对策略优化(GRPO)等算法的进步。
接着,论文将超过200篇代表性研究工作划分为四大主题支柱:
多模态大语言模型(Multimodal LLMs) 视觉生成(Visual Generation) 统一模型框架(Unified Model Frameworks) 视觉-语言-行动模型(Vision-Language-Action Models, VLA)
在每个支柱下,综述详细探讨了算法设计、奖励工程(reward engineering)、基准测试进展,并提炼出了领域内的核心趋势,如课程驱动训练、偏好对齐的扩散模型以及统一奖励建模等。
最后,文章回顾了覆盖集合保真度、样本偏好和状态稳定性的评估协议,并指出了当前面临的开放性挑战,包括样本效率、泛化能力和安全部署等。这篇综 述旨在为研究人员和从业者提供一张清晰的、与时俱进的视觉RL领域发展地图,并为未来的研究指明了有前景的方向。
核心图片:

(14) Follow-Your-Shape:沿轨迹引导区域控制,实现形状感知的图像编辑!(6 票)
论文原始英文标题:
Follow-Your-Shape: Shape-Aware Image Editing via Trajectory-Guided Region Control
论文链接:
https://huggingface.co/papers/2508.08134
paperscope.ai 解读:
https://paperscope.ai/hf/2508.08134
简要介绍:
香港科技大学、伊利诺伊大学香槟分校等机构的研究者提出了 Follow-Your-Shape,一个无需训练、无需掩码(mask-free)的图像编辑框架,它能够精确且可控地修改物体形状,同时严格保持非目标区域的内容不变。
现有的基于流模型(flow-based)的图像编辑方法虽然通用,但在处理大规模形状变换这类具有挑战性的任务时常常力不从心。它们要么无法实现预期的形状改变,要么会无意中修改背景,导致图像质量下降。
Follow-Your-Shape 的核心创新在于轨迹散度图(Trajectory Divergence Map, TDM)。研究者发现,在图像编辑过程中,从原始图像的噪声潜变量进行重构的轨迹,与根据目标提示进行去噪生成的轨迹之间存在差异。通过计算这两条路径在词元(token)级别上的速度差异,可以生成 TDM,这个图能精确地定位出需要编辑的区域。
然而,在去噪的早期阶段,由于噪声较大,TDM 可能不稳定。为此,研究者提出了一种计划性键值注入(Scheduled KV Injection)策略。该策略分阶段进行:
初始稳定阶段:在去噪的前几个步骤,进行无条件的键值(Key-Value)注入,以稳定初始轨迹。 TDM引导阶段:当潜变量结构变得清晰后,再应用 TDM 来引导编辑,确保修改只作用于目标区域。
为了对该方法进行严格评估,团队还推出了一个新的基准测试 ReShapeBench,包含了 120 张专为形状感知编辑而设计的图像和提示对。实验证明,Follow-Your-Shape 在编辑能力和视觉保真度方面均表现出色,尤其在需要大尺度形状替换的任务上,其背景保真度(PSNR 35.79)和文本对齐度(CLIPSim 33.71)都达到了 SOTA 水平。
核心图片:

(15) 技巧还是陷阱?深入探讨用于大模型推理的强化学习(第一部分)!(5 票)
论文原始英文标题:
Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning
论文链接:
https://huggingface.co/papers/2508.08221
paperscope.ai 解读:
https://paperscope.ai/hf/2508.08221
简要介绍:
阿里巴巴集团联合多所高校的研究者们,对当前用于提升大语言模型(LLM)推理能力的强化学习(RL)技术进行了一次系统性的“大摸底”。尽管 RL 在增强 LLM 推理方面展现了巨大潜力,但社区中缺乏标准化的使用指南,对各种“技巧”(tricks)的底层机制理解也较为零散。不一致的实验设置、训练数据和模型初始化导致了许多相互矛盾的结论,让从业者在选择技术时感到困惑。
这篇论文的核心工作是在一个统一的开源框架下,对广泛采用的 RL 技术(如优势归一化、裁剪策略、损失聚合等)进行了严格的复现和隔离评估。通过在不同难度的数据集、不同规模和架构的模型上进行细粒度实验,研究者们深入剖析了每种技术的内部机制、适用场景和核心原理,并在此基础上为从业者提供了清晰的技术选型指南和可靠的路线图。
研究得出了几个关键结论:
归一化策略的敏感性:组级别(Group-level)的优势归一化在不同奖励设置下表现稳健;而批次级别(Batch-level)的归一化在奖励规模较大时更稳定。 裁剪策略的偏好:Clip Higher 技巧更适合于已经对齐过的模型,能促进高质量的探索。 损失聚合的差异:词元级别(Token-level)的损失聚合对基础(Base)模型效果显著,但对已经对齐过的模型提升有限。
最引人注目的发现是,一个极简的组合——仅使用两种技术(优势归一化 + 词元级别损失聚合),就能在不依赖评论家网络(critic-free)的情况下,使用原始的 PPO 损失函数解锁策略的学习能力。这个被命名为 Lite PPO 的简单组合,其性能稳定地超越了像 GRPO 和 DAPO 这样包含更多复杂组件的主流策略。
核心图片:

(16) 少即是多:无需训练的稀疏注意力机制,兼顾全局与局部以实现高效推理!(5 票)
论文原始英文标题:
Less Is More: Training-Free Sparse Attention with Global Locality for Efficient Reasoning
论文链接:
https://huggingface.co/papers/2508.07101
paperscope.ai 解读:
https://paperscope.ai/hf/2508.07101
简要介绍:
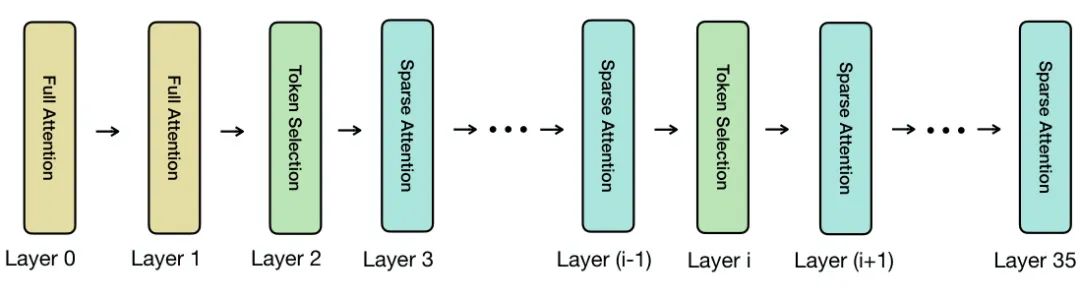
普林斯顿大学、卡内基梅隆大学等机构的研究者们提出了 LessIsMore,一种无需训练的稀疏注意力机制,专为大型推理模型(LRMs)设计,旨在解决其在生成长篇推理链时计算开销巨大的问题。
大型推理模型通过在测试时生成大量词元(token)来提升性能,但这带来了高昂的计算成本。稀疏注意力机制通过只关注一小部分关键词元来降低延迟和内存使用,但现有方法在长序列推理中容易因累积误差而导致准确性大幅下降,通常需要高词元保留率或昂贵的重训练。
LessIsMore 的核心思想源于对推理模型注意力模式的两个关键观察:
空间局部性(Spatial Locality):在同一解码层中,不同注意力头(attention head)关注的“重要”词元高度重叠。这挑战了传统观点,即每个头功能专门,需要不同的词元子集。 近期局部性(Recency Locality):在解码过程中,最近生成的词元在后续步骤中会持续获得高注意力。
基于这些发现,LessIsMore 提出了一种统一的全局词元选择策略,而非传统的各注意力头独立优化的局部策略。在每个选择层,它会聚合所有头的词元选择,并结合近期上下文信息,进行统一的跨头词元排序。这种全局选择避免了为每个头维护独立的词元子集,从而提高了泛化能力和效率。
实验在 Qwen3-8B 和 Qwen3-4B 模型上进行,涵盖了 AIME、GPQA-Diamond 等多个推理基准。结果表明,LessIsMore 在实现平均 1.1 倍解码加速的同时,保持了与全注意力相当甚至更高的准确率。与现有的稀疏注意力方法相比,LessIsMore 在不损失准确性的情况下,关注的词元数量减少了2倍,端到端速度提升了1.13倍。
核心图片:
(17) MoBE:基于基专家混合,压缩MoE大模型!(4 票)
论文原始英文标题:
MoBE: Mixture-of-Basis-Experts for Compressing MoE-based LLMs
论文链接:
https://huggingface.co/papers/2508.05257
paperscope.ai 解读:
https://paperscope.ai/hf/2508.05257
简要介绍:
来自 Inclusion AI、中国人民大学、西湖大学等机构的研究者们提出了一种名为 MoBE(Mixture-of-Basis-Experts) 的新方法,旨在高效压缩基于专家混合(MoE)架构的大语言模型(LLM),以解决其部署时巨大的内存需求问题。
像 DeepSeek-V3 和 Kimi-K2 这样的大型 MoE 模型虽然性能强大且计算高效,但其庞大的参数量给实际应用带来了严峻挑战。现有的 MoE 压缩方法,无论是剪枝还是分解,都常常导致显著的性能下降(相对准确率下降 7%-14%)。
MoBE 的核心思想是一种新颖的矩阵分解策略。对于 MoE 层中的每个专家,其上/门控投影矩阵 W 首先被进行秩分解为 W = AB,其中 A 矩阵是每个专家独有的。关键创新在于,相对较大的 B 矩阵被进一步重参数化为一组基矩阵 {Bⁱ} 的线性组合,而这些基矩阵在整个 MoE 层的所有专家之间是共享的。通过最小化重构误差来学习这种分解,MoBE 能够在大幅减少参数量的同时,最大程度地保留原始模型的知识。
实验结果非常出色。在对 Qwen3-235B、DeepSeek-V3-0324 (671B) 和 Kimi-K2-Instruct (1T) 等大型模型的压缩测试中,MoBE 能够将参数量减少 **24%-30%**,而准确率仅下降 **1%-2%**(相对下降约 2%),远优于现有方法。这一技术为在资源受限的环境中部署超大规模 MoE 模型提供了切实可行的解决方案。
核心图片:

(18) VisR-Bench:面向多语言长文档理解的视觉检索增强生成实证研究!(3 票)
论文原始英文标题:
VisR-Bench: An Empirical Study on Visual Retrieval-Augmented Generation for Multilingual Long Document Understanding
论文链接:
https://huggingface.co/papers/2508.07493
paperscope.ai 解读:
https://paperscope.ai/hf/2508.07493
简要介绍:
布法罗大学、马里兰大学和 Adobe Research 的研究者们共同推出了 VisR-Bench,这是一个专为长文档中的多语言、多模态检索设计的基准测试。现实世界中,大量知识以文档形式(如PDF)存在,而视觉检索对于从中提取信息至关重要。然而,现有的基准测试存在明显短板:要么只关注纯英文文档检索,要么只处理单页图像的多语言问答。
为了弥补这一差距,VisR-Bench 被构建为一个以问题为驱动的多模态检索基准。它包含超过 3.5 万个高质量问答对,覆盖了 1200 多份文档和 16 种语言。这个基准测试的独特之处在于:
多语言与多模态:它首次将多语言环境与包含文本、表格和图表等多种视觉元素的长文档结合起来。 精细化评估:通过将问题类型分为图表、文本和表格三类,VisR-Bench 能够对模型的不同能力(如多模态推理、OCR 鲁棒性、表格理解)进行细粒度评估。 避免浅层匹配:与以往的数据集不同,VisR-Bench 包含了一些没有明确答案的查询,这可以防止模型仅仅依赖关键词匹配来“作弊”。
研究团队在 VisR-Bench 上评估了多种检索模型,包括基于文本的方法、多模态编码器和多模态大语言模型(MLLM)。实验结果显示,MLLM 的性能显著优于其他两类模型,但它们在处理结构化表格和低资源语言时仍然面临巨大挑战。这揭示了当前多语言视觉检索领域的关键难点,并为未来模型的改进指明了方向。
核心图片:

(19) 通才机器人策略中的捷径学习:数据集多样性与碎片化的作用!(3 票)
论文原始英文标题:
Shortcut Learning in Generalist Robot Policies: The Role of Dataset Diversity and Fragmentation
论文链接:
https://huggingface.co/papers/2508.06426
paperscope.ai 解读:
https://paperscope.ai/hf/2508.06426
简要介绍:
来自电子科技大学和同济大学的研究者们深入探讨了为什么在像 Open X-Embodiment (OXE) 这样的大规模数据集上训练的“通才”机器人策略,虽然在训练任务上表现出色,但却难以泛化到训练分布之外的新场景。
研究的核心发现是,捷径学习(Shortcut Learning)——即模型依赖于与任务无关的虚假相关性特征——是限制其泛化能力的关键障碍。例如,模型可能学会了将特定的摄像机视角或背景与某个特定动作关联起来,而不是真正理解语言指令和目标物体之间的因果关系。
通过全面的理论和实证分析,研究揭示了导致捷径学习的两个主要原因:
单个子数据集内部的多样性有限:在每个独立收集的数据集(如 OXE 中的 Bridge 或 RT-1)中,场景、视角等无关因素变化不大。 子数据集之间的分布差异显著:不同子数据集之间存在巨大的分布鸿沟,导致整个大规模数据集呈现出碎片化(fragmentation)状态。
这些问题源于大规模机器人数据集(如OXE)通常由多个在不同环境、不同机器人上独立收集的子数据集拼接而成。研究结果为如何收集更好的机器人数据集提供了关键见解,例如应确保子数据集内部因素的多样性和独立性,同时减少子数据集之间的无关因素差异。
此外,对于无法重新收集数据的情况,研究表明,通过精心选择的机器人数据增强策略(如视角增强和物体增强),可以有效缓解现有离线数据集中的捷径学习问题,从而提升 π₀ 等通才机器策略在模拟和真实世界环境中的泛化能力。
(20) Speech-to-LaTeX:用于转换口语化公式和语句的新模型与数据集!(2 票)
论文原始英文标题:
Speech-to-LaTeX: New Models and Datasets for Converting Spoken Equations and Sentences
论文链接:
https://huggingface.co/papers/2508.03542
paperscope.ai 解读:
https://paperscope.ai/hf/2508.03542
简要介绍:
来自 AIRI、斯科尔科沃科技学院等俄罗斯研究机构的团队,针对将口语化的数学表达式和句子转换为结构化的 LaTeX 代码这一挑战性任务,发布了新的模型和大规模数据集。这项任务在教育和研究领域(如讲座转录、笔记创建)有直接应用,但由于数学语言发音的模糊性,一直未得到充分研究。
现有工作(如 MathSpeech)存在一些局限:依赖两次转录的后处理流程、只关注孤立的方程式、测试集有限,且没有提供训练数据和多语言支持。为解决这些问题,该研究团队推出了首个完全开源的大规模数据集 S2L,包含超过 66,000 个人工标注的英语和俄语数学音频样本,涵盖了方程式和包含数学公式的句子。
在模型方面,研究者不仅沿用了自动语音识别(ASR)后处理和少样本提示(few-shot prompting)的方法,还首次将音频语言模型(Audio Language Models)应用于此任务。实验结果表明,他们的方法在 MathSpeech 基准测试上取得了与原模型相当的性能(字符错误率 CER 28% vs. 30%)。而在新提出的 S2L-equations 基准上,他们的模型表现远超 MathSpeech 模型,即使在处理了 LaTeX 格式伪影后,CER 仍有超过 40 个百分点的优势(27% vs. 64%)。
此外,该工作还首次为数学句子的识别建立了基准(S2L-sentences),并取得了 40% 的方程式 CER。这项研究为未来多模态AI,特别是数学内容识别领域的发展,奠定了坚实的基础。
核心图片:

(21) Fact2Fiction:针对智能体事实核查系统的定向投毒攻击!(2 票)
论文原始英文标题:
Fact2Fiction: Targeted Poisoning Attack to Agentic Fact-checking System
论文链接:
https://huggingface.co/papers/2508.06059
paperscope.ai 解读:
https://paperscope.ai/hf/2508.06059
简要介绍:
香港浸会大学、香港大学及微软公司的研究者们提出了 FACT2FICTION,这是首个针对智能体式事实核查系统(agentic fact-checking systems) 的投毒攻击框架。
当前最先进的事实核查系统,如 DEFAME 和 InFact,利用自主的 LLM 智能体来处理复杂声明。它们会将一个复杂的声明分解为多个可验证的子声明,独立核查每个子声明,最后综合所有结果给出最终结论和理由。这种“分而治之”的策略虽然提高了核查的准确性和鲁棒性,但也暴露了新的安全漏洞。
现有的针对 RAG 系统的攻击方法(如 PoisonedRAG)通常只针对主声明生成宽泛的恶意证据,难以对付这种分解式的核查流程。Fact2Fiction 的高明之处在于,它模仿了智能体核查系统的工作模式:
模拟分解:攻击框架首先将目标声明分解为一组代理子问题,确保攻击能覆盖所有核查角度。 利用“理由”反制:它利用了事实核查系统生成“理由”(justification)这一特性。这些理由暴露了系统做出判断所依赖的关键证据和推理模式。Fact2Fiction 通过分析这些理由,可以精准地制造出与系统原始推理逻辑直接矛盾的恶意证据。 预算规划:根据理由的重要性,将有限的投毒预算优先分配给对最终结论影响最大的子声明。
实验表明,Fact2Fiction 的攻击成功率比现有 SOTA 攻击高出 **8.9% - 21.2%**,并且攻击效率极高,仅需少量恶意证据就能达到相当的效果。这项研究揭示了当前事实核查系统在安全上的薄弱环节,并强调了开发相应防御措施的紧迫性。
核心图片:

(22) 利用步骤熵压缩大语言模型中的思维链!(2 票)
论文原始英文标题:
Compressing Chain-of-Thought in LLMs via Step Entropy
论文链接:
https://huggingface.co/papers/2508.03346
paperscope.ai 解读:
https://paperscope.ai/hf/2508.03346
简要介绍:
香港中文大学与华为公司的研究者们提出了一种基于步骤熵(step entropy) 的新颖框架,用于压缩大语言模型(LLM)中的思维链(Chain-of-Thought, CoT)。
使用 CoT 的 LLM 在复杂推理任务上表现出色,但其生成的思维过程通常冗长且包含大量冗余信息,这不仅增加了推理成本,也降低了效率。为解决此问题,研究者引入了“步骤熵”这一指标,它通过量化每个推理步骤对最终答案的信息贡献来识别冗余。
核心假设是:熵值较低的步骤代表模型在生成该步骤时具有较高的确定性,因此信息量较少,也更可能是多余的。
通过在数学推理基准上的大量实证验证,研究者惊人地发现,在 DeepSeek-R1-7B/14B 和 Qwen3-8B 等模型上,高达 80% 的低熵中间步骤可以被剪除,而对最终答案的准确性影响甚微。与之形成鲜明对比的是,随机剪除或剪除高熵步骤会严重损害模型的推理性能。
基于这一发现,研究者提出了一种新颖的两阶段训练策略,结合了监督微调(SFT)和组相对策略优化(GRPO)强化学习。该策略能让 LLM 自主学习在推理时生成压缩后的 CoT,通过策略性地插入 [SKIP] 标记来跳过不必要的步骤。经过训练的模型在保持甚至提高准确率的同时,显著减少了 35%-57% 的生成词元(token),极大地提升了 LLM 的推理效率。这项工作为 LLM 的实际部署提供了重要启示,并加深了对模型推理结构的理解。
核心图片:

(23) Bifrost-1:用补丁级CLIP潜变量连接多模态大模型与扩散模型!(1 票)
论文原始英文标题:
Bifrost-1: Bridging Multimodal LLMs and Diffusion Models with Patch-level CLIP Latents
论文链接:
https://huggingface.co/papers/2508.05954
paperscope.ai 解读:
https://paperscope.ai/hf/2508.05954
简要介绍:
北卡罗来纳大学教堂山分校(UNC Chapel Hill)与 Lambda 公司的研究者们提出了 BIFROST-1,一个新颖的统一框架,旨在将预训练的多模态大语言模型(MLLM)和扩散模型高效地连接起来,以实现高保真的可控图像生成,同时保留 MLLM 强大的推理能力。
现有方法要么直接训练 LLM 生成图像,计算成本高昂;要么通过生成一维的文本描述或查询词元来桥接 LLM 和扩散模型,难以传递丰富的二维空间信息。BIFROST-1 的核心创新在于使用补丁级别(patch-level)的 CLIP 图像嵌入作为两者之间的“桥梁”。这些补丁级的潜变量与 MLLM 自带的 CLIP 视觉编码器在表示上是原生对齐的,使得 MLLM 能够自然地生成丰富且精确的空间引导信号。
具体来说,BIFROST-1 的工作流程如下:
保留 MLLM 推理能力:为 MLLM 配备一个视觉生成分支,该分支的参数从原始 MLLM 初始化,专门用于预测补丁级的 CLIP 图像嵌入。这保证了模型原有的多模态理解能力不受损害。 高效连接扩散模型:生成的补丁级图像嵌入被送入一个轻量级适配的 ControlNet 中,以引导预训练的扩散模型(如 FLUX.1-dev)进行图像合成。
通过这种方式,BIFROST-1 实现了 MLLM 和扩散模型之间的无缝集成,极大地提高了训练效率。实验证明,与现有方法相比,BIFROST-1 在视觉保真度和多模态理解方面取得了相当甚至更好的性能,而训练所需的计算资源则大大降低。
(24) 当善意之声变为恶意之器:用良性输入越狱音频语言模型!(1 票)
论文原始英文标题:
When Good Sounds Go Adversarial: Jailbreaking Audio-Language Models with Benign Inputs
论文链接:
https://huggingface.co/papers/2508.03365
paperscope.ai 解读:
https://paperscope.ai/hf/2508.03365
简要介绍:
来自 AIM Intelligence、LG 电子等机构的研究者们提出了一种名为 WHISPERINJECT 的两阶段对抗性音频攻击框架,它能够操纵最先进的音频语言模型(ALM)生成有害内容,而输入的音频对人类听者来说却是完全良性的。
随着音频成为人机交互的关键接口,其安全漏洞也日益凸显。现有音频对抗研究要么专注于破坏语音识别(ASR)的转录准确性,要么使用的攻击载荷是固定的、从文本攻击中改编而来的有害句子,这些“外来”的有害内容与模型自身的输出分布不符,导致攻击成功率不高。
WHISPERINJECT 框架创新地解决了这个问题:
第一阶段:原生目标发现(Native Target Discovery)。该阶段不使用外部的有害文本,而是采用一种新颖的、基于奖励的优化方法——带投影梯度下降的强化学习(RL-PGD),来引导目标模型自己生成一个原生的、符合其语言风格的有害回答。这个回答作为后续攻击的“完美”载荷。 第二阶段:载荷注入(Payload Injection)。使用标准的投影梯度下降(PGD)方法,将第一阶段发现的原生有害回答作为目标,生成微小的、人耳难以察觉的扰动,并将其嵌入到一个良性的音频载体中(如“今天天气怎么样?”)。
最终产生的对抗性音频,人类听起来是无害的日常问候,但输入到音频语言模型中,却能稳定地触发其生成预设的有害内容。在 StrongREJECT、LlamaGuard 以及人类评估等严格的安全评估框架下,该攻击对 Qwen2.5-Omni 和 Phi-4-Multimodal 等模型的成功率超过 **86%**。这项工作揭示了一类全新的、实用且隐蔽的音频原生威胁。
(25) GLiClass:面向序列分类任务的通用轻量级模型!(1 票)
论文原始英文标题:
GLiClass: Generalist Lightweight Model for Sequence Classification Tasks
论文链接:
https://huggingface.co/papers/2508.07662
paperscope.ai 解读:
https://paperscope.ai/hf/2508.07662
简要介绍:
来自 Knowledgator Engineering 的研究者们提出了 GLiClass,一种专为序列分类任务设计的新型模型,其灵感来源于 GLiNER 架构。分类是人工智能应用中最普遍的任务之一,对效率和准确性要求极高,尤其是在需要零样本(zero-shot)能力的动态场景中。
现有的方法各有优劣:
生成式大语言模型(LLM):虽然通用,但遵循指令不稳定且计算效率低下。 交叉编码器(Cross-encoders):通常用于 RAG 管道中的重排,但处理大量标签时需要逐对处理,效率低下。 基于嵌入的方法:效率高,但在处理复杂的逻辑和语义约束时表现不佳。
GLiClass 旨在结合上述方法的优点,它采用了一种统一编码器(uni-encoder)架构,将输入文本和所有候选标签拼接在一起,通过单个 Transformer(如 DeBERTa-v3)进行联合处理。这种设计使得模型能够在一次前向传播中完成多标签分类,并能够捕捉标签之间的相互关系,从而在复杂场景下做出更准确的预测。
该方法不仅实现了与基于嵌入方法相媲美的高效率和非线性扩展性(即推理时间不随标签数量成比例增加),还在准确性上达到了甚至超过了交叉编码器的水平。此外,GLiClass 保持了强大的零样本和少样本学习能力。研究者还成功地将近端策略优化(PPO)强化学习算法应用于多标签文本分类,使得模型能在数据稀疏或需要人类反馈的条件下进行训练。
核心图片:

(26) 深度无知:过滤预训练数据,为开源模型构建抗篡改的防护措施!(1 票)
论文原始英文标题:
Deep Ignorance: Filtering Pretraining Data Builds Tamper-Resistant Safeguards into Open-Weight LLMs
论文链接:
https://huggingface.co/papers/2508.06601
paperscope.ai 解读:
https://paperscope.ai/hf/2508.06601
简要介绍:
来自 EleutherAI、英国AI安全研究所、牛津大学等机构的研究者们进行了一项开创性的研究,探讨了通过过滤预训练数据来防止开源大语言模型(LLM)学习不必要或有害的能力,从而构建更强的、抗篡改的安全防护。
开源模型虽然带来了透明、开放研究等诸多好处,但也面临被恶意修改(如对抗性微调)以引出有害行为的风险。现有的安全微调等后训练方法往往难以抵御超过几十步的对抗性微调。
该研究的核心假设是:如果模型在预训练阶段就没有学到某些危险知识,那么攻击者后续想引出相关有害行为就会困难得多。为了验证这一点,研究者们以生物威胁代理知识(biothreat proxy knowledge) 为例,设计了一个多阶段的可扩展数据过滤管道,从训练数据中移除相关文本。
他们从头开始预训练了多个 6.9B 参数的模型,结果发现:
知识预防有效:经过数据过滤的模型,其生物威胁代理知识显著减少,效果与 SOTA 的后训练安全措施相当,且没有损害其他通用能力。 强大的抗篡改性:过滤后的模型对长达 10,000 步、3 亿词元的生物威胁相关文本的对抗性微调表现出极强的抵抗力,比现有后训练方法的抵抗能力高出一个数量级以上。 深度防御的必要性:尽管过滤后的模型内部不含危险知识,但当这些信息通过上下文(如通过搜索工具)提供时,模型仍然可以利用它们。这表明需要结合其他防御措施(如“熔断机制”)形成纵深防御。
这项研究为开源模型的风险管理提供了一个有前景的新方向,证明了在预训练阶段进行数据管理是构建更安全、更可信AI系统的一个关键层次。
核心图片:

结语
从智能体的“自我进化”到模型的“高效推理”,再到“精准可控”的AIGC,本周的论文再次展示了AI技术在深度、广度和精度上的全面飞跃。我们看到,研究者们不仅在追求更强大的模型能力,也在积极探索如何让AI更智能、更高效、更安全地融入现实世界。这些前沿探索不仅是学术上的里程碑,也为未来的技术应用描绘了激动人心的蓝图。
无论是为模型赋予推理能力的 ReasonRank,还是为智能体能力划定新边界的 WideSearch,亦或是为安全防护提供新思路的“深度无知”研究,都让我们对AI的未来充满了期待。让我们共同期待下一周的智慧火花!🔥










