🚀研究背景与核心创新点🧩
EMP通过上半身模仿 + 下半身平衡 + 可执行修正,实现安全稳定的人形控制
小编观点 💬
EMP 的亮点不只是控制策略本身,而是它代表了人形机器人强化学习的一个新范式:
不再让 RL 去“硬学全部物理”,而是在 RL 前插入一个“动作可行性网络”,帮它判断什么该做、什么不该做。
在未来,如果再结合 VLA(VLA-RL、Helix、ControlVLA),我们可能会看到——机器人在执行语言指令前,也会先“想一想自己能不能做到”。
🌟EMP创新点概览
一个完整的“上半身模仿框架”,由三部分构成:
1️⃣ 运动重定向网络基于图卷积,将人类上半身动作映射到机器人关节空间,生成可训练的上半身数据集。
2️⃣ 上半身强化学习控制策略使用 Isaac Gym 训练 RL 策略,专注于下半身平衡控制,同时跟踪上半身的模仿目标。
3️⃣ 可执行运动先验模块(Executable Motion Prior, EMP)一个 VAE(变分自编码器)结构的网络,实时调整上半身动作幅度与方向,确保动作在机器人物理能力范围内。
论文核心思想一句话总结
“让机器人像人一样挥动手臂——但又不至于把自己晃倒。”
EMP 通过融合模仿学习与强化学习,使得机器人能够:
稳站模仿人类上半身动作
自动调整过大的动作幅度
🧩 算法框架与核心机制
整体结构
论文提出的整体系统如图 2 所示:
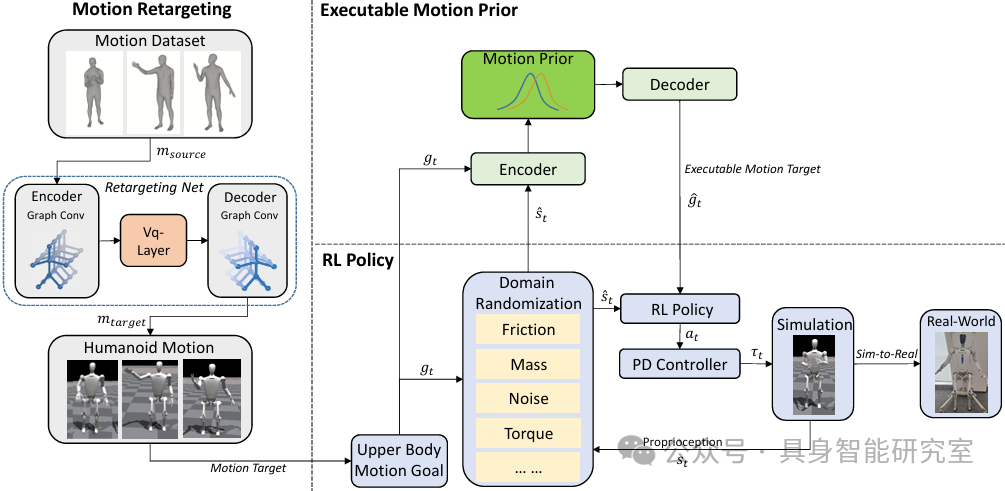
对应三阶段:
数据生成:用图卷积网络(GCN)将人类上半身动作映射到机器人结构;
策略训练:让机器人在 Isaac Gym 中学会在平衡状态下执行这些动作;
运动修正:判断当前状态是否超出执行极限,若是,则轻度修正动作。
Motion Retargeting
目标:解决人类与机器人骨架结构不匹配的问题。
方法:
采用 VQ-VAE(向量量化自编码器) 框架;
将人类上半身(肩、肘、腕、躯干)作为节点,建立骨架图结构;
利用图卷积编码器–解码器结构,将人类动作转换为机器人关节角度。
损失函数:
End-effector 误差(手的末端误差)
Orientation 姿态误差
Elbow 结构保持误差
Embedding 与 Commitment 损失(约束潜变量分布)
效果:在保持姿态自然的前提下,生成高质量的机器人动作数据集,为 RL 提供训练样本。
强化学习控制
(1) 任务分解
作者将策略拆分为:
π_lower:负责下半身的平衡控制(RL 训练)
π_upper:负责上半身模仿动作(由 EMP 指导)
强化学习的目标是:
让机器人在“站稳”的情况下,尽量模仿人类上半身的目标动作。
(2) 状态空间
状态包括:
当前关节角度 q_t
上一时刻动作 a_(t-1)
基座姿态 rpy_t
目标上半身动作 g_t
组合后历史窗口长度 T=15,用以捕捉连续时序信息。
(3) 奖励函数设计
奖励分三类:
稳定性奖励:姿态、速度、加速度、重心高度
运动一致性奖励:上半身模仿精度
能量与光滑度惩罚:动作过大、变化过快会被惩罚
强化学习算法采用 PPO 变体,运行于 Isaac Gym 环境中,训练 6 小时即可收敛。
(4) Domain Randomization
为了 Sim-to-Real 迁移:
随机化摩擦、惯量、扭矩、延迟;
加入推搡扰动;
改变手部负载(±1kg)。
这些让 RL 策略具备了“抗扰动性”,可直接迁移到真实硬件。
EMP 模块
(1) 核心思想
当上半身目标动作太大时(例如“举锤砸钉”),EMP 模块会:
判断动作是否会导致重心偏移;
若有危险,自动“收敛”动作幅度;
保持平衡而尽量不失去原始动作形态。
(2) 网络结构
EMP 基于 变分自编码器 (VAE),由三部分组成:
状态编码器
目标动作编码器
解码器
损失函数包括:
重构损失
姿态保持
自碰撞惩罚
重心约束
光滑性
正则化
其中,光滑性与姿态稳定是维持机器人平衡的关键。
世界模型
由于仿真环境(Isaac Gym)无法直接反传梯度,团队额外训练了一个 World Model fw 来预测状态转移,这使得 EMP 模块能在训练中“间接获得物理反馈”,让修正更符合动力学规律。
训练过程(Algorithm 1)
两阶段循环:
训练世界模型(预测下一状态);
训练 EMP 网络(根据预测梯度优化动作)。
整个过程在 RTX4060 上仅需 5 小时,显示出极高的工程实用性。
⚙️ 仿真与实机实验结果
仿真测试平台
模型:27 自由度人形机器人(1.65m,60kg)
环境:Isaac Gym
频率:RL 与 EMP 各 50Hz,PD 控制器 1kHz
数据:从 GRAB + AMASS 数据集中重定向生成的上半身动作
对比实验
实验基线包括:
Privileged Policy(理想上界)
Whole-body Policy(全身控制)
Decoupled Policy(仅 RL 下半身)
PMP(Predictive Motion Prior)
EMP(本文方法)
EMP when Danger(仅在危险时启用 EMP)
主要指标:
结果与对比分析
| EMP (Ours) | 98.1% | 0.15 | 0.69 | 最佳稳定性 |
📊 EMP 方法显著减少了自碰撞与振动,并保持动作光滑性;同时,几乎不牺牲模仿精度。
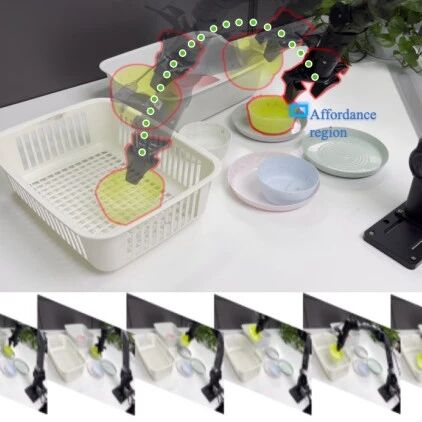
实验动画中(如“敲钉子”“拧灯泡”),当上半身动作幅度过大时,EMP 自动调整幅度,让机器人不再摔倒。
消融实验
取消部分 Loss 项的结果显示:
去掉Orientation Loss → 稳定性几乎完全崩溃(成功率仅 2.6%)
去掉Centroid Loss → 机器人重心频繁偏移(成功率 10.7%)
去掉Smoothness Loss → 动作突变明显(成功率 27%)
结论:EMP 能稳定站立的关键是多重损失的协同约束。
实机测试与迁移
在真实的人形机器人平台上部署(27DoF),实测包括“抓取”、“挥动”、“旋转”等动作,EMP 策略可直接运行,无需再训练。即使双手负载随机变化(±1kg),机器人仍能保持稳定。
团队还测试了第二款老旧平台(结构相似但动力学差),EMP 依旧能显著提升成功率至 97.8%。

本文只做学术分享,如有侵权,联系删文