

自动驾驶汽车需要实时响应,避免数据传输延迟。医疗和工业应用通常依赖于无法与第三方共享的敏感数据。尽管边缘人工智能应用速度更快、更安全,但它们的计算资源却非常有限。它们无法拥有TB 级的内存空间或几乎无限的计算能力。
对于数据中心来说,这些限制可能有些抽象,但却对边缘人工智能施加了严格的限制。在2025年IEEE国际内存研讨会的一篇受邀论文及其后续预印本中,苏黎世联邦理工学院计算机科学教授Onur Mutlu及其同事指出,在典型的移动工作负载中,数据在内存中的移动占总能耗的62%,这一比例令人震惊。内存是硬件资源的最大消耗者,而且遥遥领先,但内存延迟往往是执行时间的最大贡献者。
多年来,器件规模的扩大一直是降低功耗的关键,但现在却使问题更加严重。Mutlu 表示,规模庞大的 DRAM 稳定性较差,需要更频繁的刷新周期。大型内存阵列的访问难度也更大,因为带宽的增长速度不如内存条本身的增长速度快。
内存和近内存计算提供了可能的解决方案。即使是商用的现成DRAM,只要软件基础设施支持,也可以执行原始的数据复制、初始化和按位逻辑运算。
 混合解决方案结合了RRAM和铁电体
混合解决方案结合了RRAM和铁电体
然而,DRAM刷新功率的问题仍然存在。在神经网络模型中,训练和推理任务都会重复使用存储的权重矩阵。然而,两者的要求却截然不同。
正如CEA-Leti 的 Michele Martemucci 及其同事所解释的那样,训练任务涉及对权重矩阵进行多次小幅更新,使其逐渐收敛到稳定值。这些任务需要具有高写入耐久性和存储精确值能力的内存。相比之下,推理任务使用稳定不变的权重矩阵,但可能会将其多次应用于输入数据。推理任务受益于具有高读取耐久性的非易失性存储器。在这两种情况下,近内存计算都需要与标准 CMOS 逻辑工艺兼容的设备。
RRAM 是一种简单的器件,依靠氧化层中形成的导电细丝来实现极高的读取耐久性。通过精心设计的编程方案,它们可以存储模拟值,从而减小存储器阵列的大小。Martemucci 表示,RRAM 技术已经足够成熟,可以在边缘推理场景中进行商业部署。
遗憾的是,RRAM 的写入耐久性相对较低。随着时间的推移,编程脉冲会模糊存储值之间的电阻差异。设计人员通常使用传统硬件训练模型,然后将预先计算的权重加载到 RRAM 阵列中。然而,在许多应用中,边缘设备需要具备“学习”能力。它要么需要根据用户的特定需求进行训练,要么需要修改模型以反映实际流程的变化。
与此同时,铁电电容器支持非常快速的开关和极高的写入耐久性。它们可以轻松承受训练任务中遇到的频繁写入操作。然而,虽然存储的值是非易失性的,但读取操作却具有破坏性。Martemucci 表示,这些设备不适合长期存储权重矩阵,也不适合需要频繁读取操作的推理任务。
将铁电晶体管集成到CMOS工艺中非常复杂,需要高温工艺和额外的掩模层。铁电电容器和隧道结则简单得多,这使得多个研究小组能够将RRAM和铁电结构结合起来。例如,在今年的VLSI技术研讨会上,SK海力士的研究人员展示了一种兼具电阻和铁电开关功能的混合铁电隧道结(FTJ)。
在传统的FTJ中,顶部和底部电极之间的隧道势垒取决于铁电极性。SK海力士的器件将铁电铪锆氧化物(HZO)层夹在两个电极之间,钽层用作氧空位储存器。钽层附近的导电细丝在器件顶部提供欧姆导电,从而降低了铁电隧道势垒的有效厚度。这些器件实现了精确的模拟乘法累加运算,效率高达每瓦224.4万亿次运算(TOPS/W)。
在另一种混合方法中,Martemucci 团队将掺杂硅的 HfO2电容器与钛氧清除层结合到标准 CMOS BEOL 工艺中。这些器件最初表现为铁电电容器,其中一些器件接收一次性“唤醒”脉冲以稳定铁电响应。同时,电容器阵列的另一部分经过一次性“成型”工艺,形成由氧空位构成的导电细丝。钛层充当氧空位储存器,防止细丝溶解。由此产生的忆阻器器件可以在高阻和低阻状态之间切换。
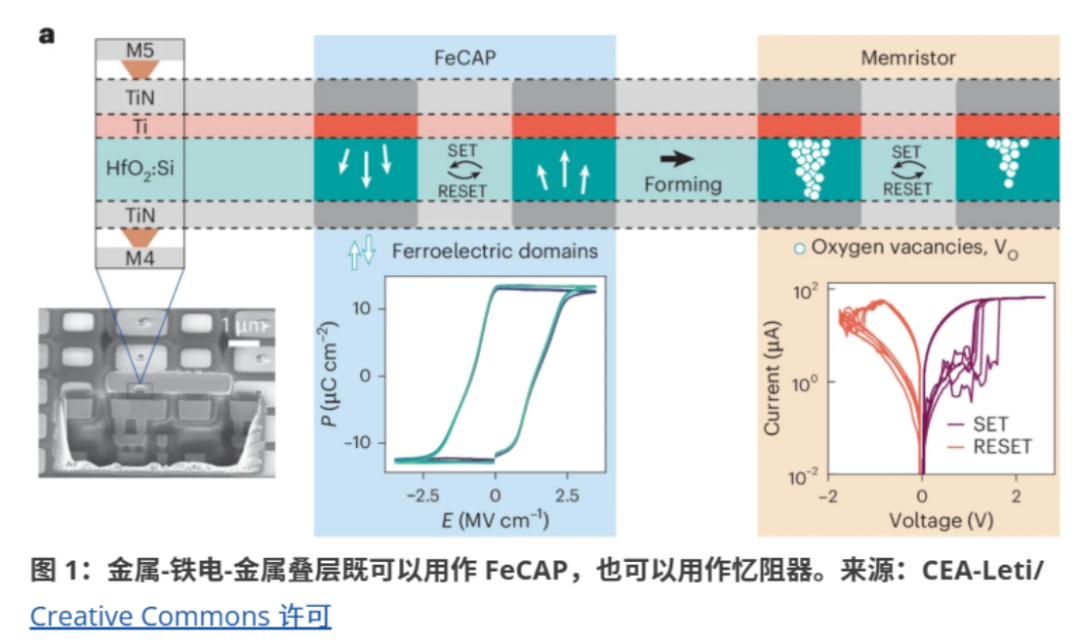
铁电电容器充当二进制元件,存储用于训练计算的高精度权重。忆阻器存储的模拟权重精度足以应对推理任务。在训练过程中,忆阻器阵列每完成100个输入步骤后更新一次,而铁电阵列则持续更新。训练此结构进行标准数字识别任务所需的写入操作总数比忆阻器耐久性小17倍,比铁电电容器耐久性小75倍,而能耗比持续更新忆阻器阵列所需能耗低38倍。
 人工智能不仅仅是神经网络
人工智能不仅仅是神经网络
内存计算不仅可以提高传统神经网络计算的能效,还能促进其他建模方法的发展。例如,许多计算难度高的问题可以建模为伊辛玻璃,即一组连接的节点共同演化到最低能量状态。现实世界中,这类问题可能涉及数千甚至数百万个连接。
解决伊辛玻璃问题是量子计算最引人入胜的潜在应用之一。更传统的方法是,在去年的IEEE电子设备会议上,德克萨斯大学研究员Tanvir Haider Pantha和他的同事们提出构建一个三维结构,将FeFET融入CMOS逻辑工艺的BEOL(后道工艺)。每个节点由四个交叉耦合的FeFET组成,可以存储一个有符号的模拟值,该值映射到待解决问题的伊辛耦合矩阵。每个节点的输出是其相邻节点的输入,从而在整个网络中建立振荡,最终达到稳定的最小能量配置。

 内存计算需要新框架
内存计算需要新框架

《2025 AI PC 产业研究报告》重磅发布
为帮助PC领域硬件层、软件层、模型层及终端层各类玩家更清晰地了解AI PC行业的发展现状及未来发展趋势,半导体产业纵横重磅发布《2025 AI PC产业研究报告》。报告主要围绕AI PC行业宏观环境、AI PC产业链、AI PC最终用户调研分析、AI PC产品评测以及AI PC未来发展趋势进行分析。AI PC最终用户调研覆盖了北京、上海及深圳等中国一线城市,共收集终端用户及门店销售人员有效样本数量千余份。调研内容涵盖用户基本信息、AI PC认知度、产品功能偏好及行业未来发展趋势判断等多个方面。AI PC产品评测针对联想ThinkPad X9 14(Intel)以及联想小新Pro16c AKP10(AMD)两大设备进行AI PC评测分析,评测维度包括同模型不同量化大小对比、同模型不同参数规模模型对比、同机器不同推理设备对比。
报告获取:
1.报告售价:纸质版599元/本
2.购买方式:请扫码填写报告购买意向表

3.报告咨询:
微信号icviews2 或者Joy8432211
报告目录:
















