
【编者按】
本文深度剖析了AI算力爆发背后的关键技术循环与产业链变局。文章聚焦于HBM(高带宽内存)的演进、内存墙的挑战、先进封装与光互联技术的突破,以及TSMC、NVIDIA、OpenAI等巨头在其中的战略定位。通过对2026年产业拐点的前瞻,揭示了算力、带宽、功耗与封装之间的深层耦合关系。这不仅是一场技术竞赛,更是一场涉及供应链、资本与地缘政治的全面重构。适合关注AI硬件、半导体与未来算力架构的读者深入阅读。
2026:带宽、电力与封装重新定价之年
到2026年,电力、水资源、先进封装能力和光互连能力都将被重新定价。赢家将是那些能够将带宽工程转化为生产力和定价杠杆的参与者。这不仅是一场技术竞赛,更是供应链和基础设施层级的权力重组。

风险与挑战依然存在:
·AI扩展定律可能面临收益递减。
·CPO(共封装光学)的热管理和可维护性问题尚未完全解决。
·CXL(计算快速链接)的NUMA(非统一内存访问)软件开销可能延缓商业化进程。
·HBF(高带宽光纤)的延迟限制了其在训练场景中的实用性。
随着导线变为天线、光子取代铜线,AI基础设施的未来权力结构将属于那些能够将带宽、热管理和能源系统协调为一个有机整体的参与者。
AI超级周期与HBM供应链的重构——从非线性能力跃迁到内存行业的权力转移

AI能力曲线的断点:2026年的关键非线性跃迁
2026年有望成为全球AI发展轨迹中的一个主要拐点。一种计算驱动的“能力曲线断裂”正在浮现——这不仅源于模型的扩展,更源于跨越技术栈、基础设施和资本市场的系统性转型。回顾过去,2012年深度学习的兴起和2022年大语言模型(LLMs)的爆发重塑了整个科技和产业格局。如今,随着领先模型开发者预计到2025年底将训练计算量提升约10倍,预计在2026年初将出现一波集中的突破,作为整个生态系统的强大催化剂。
AI能力的增长并非线性。过去十年中,计算、数据和模型参数的同步增加遵循了扩展定律——随着模型规模增大,错误率呈次线性下降。然而,一旦总计算量达到exaFLOPs至zettaFLOPs范围,改进可能从缓慢曲线转变为阶跃式跃迁。一个1吉瓦规模的数据中心可以提供相当于数千台超级计算机组合的计算能力,显著提升语言模型在推理链长度、记忆、工具使用、多模态集成和逻辑一致性方面的能力。这代表系统级的质变,而不仅仅是量变。
然而,这种非线性跃迁并非必然。该领域长期争论着“扩展墙”假说:超越某个阈值后,性能提升可能趋于平缓或停滞,进入收益递减阶段。悲观者认为算法和架构限制将制约模型性能,训练成本和能源使用将飙升。乐观者则反驳称,合成数据和迁移学习可以维持训练效率,而如专家混合(MoE)、检索增强生成和多代理系统等创新可以突破饱和点。在大规模合成数据环境中,模型未显示崩溃迹象,表明扩展墙可能比预期遥远得多。

即使能力曲线持续上升,物理世界的瓶颈也必须面对。随着吉瓦级数据中心成为标准,能源消耗、冷却、光互连带宽和土地基础设施将带来前所未有的挑战。一个巨型训练中心可能消耗相当于一个小国的电力。为维持稳定运行,数据中心必须采用微通道液冷、金刚石散热器和直接液冷冷板。铜线已无法满足带宽需求,使得CPO(共封装光学)和OIO(光学I/O)成为必然。此外,选址必须转向更靠近水电或核能源以支撑如此巨大的电力水平。基础设施不再仅仅是IT开支——它已成为国家战略资产。
计算激增驱动的市场重新定价与供应链重组
当AI能力在2026年实现阶跃式跃迁时,一波强大的多行业、多资产市场重新定价浪潮将随之而来。
首先,AI基础设施供应商将成为直接受益者。提供先进冷却、光互连、封装和电力解决方案的公司将不再被视为“后端成本”,而是计算曲线上的战略节点。

其次,供应链将经历进一步重组。在地缘政治压力下,美国将加强其在内存、芯片、封装和能源领域的战略自主性。与此同时,亚洲——特别是韩国和中国台湾地区——将成为技术和产能不可或缺的枢纽。
第三,AI采用将在终端用户中分化。并非每家企业都能平等受益于能力跃迁;只有那些能够将AI效率增益转化为实际生产力或定价权的企业将成为赢家。这种能力到价值的转换将重绘各行业的利润池。
第四,稀缺资产将被重新定价。电力基础设施、关键矿物、水资源、港口和受监管的特许权,由于其不可复制性,相对价值将急剧上升。同时,AI难以复制的人类经验、品牌信任和专有数据,将成为长期价值重新评估的核心。

这一转型的技术节奏已清晰可见:
·计算架构将从GPU主导转向多芯片并行和ASIC的崛起。
·内存技术将从HBM3E演进至HBM4E和HBM5。
·数据中心互连将从PCIe过渡至NVLink和CXL结合光学I/O。
·封装技术将从传统2.5D/FCBGA推进至CoWoS、SoIC和扇出光学封装。
这些转变将根本性地重塑供应链分工,提升芯片设计、先进封装、光子模块和材料供应商的战略重要性,并创造新的技术和产业格局。
日益明显的是,2026年将不是渐进、线性增长之年,而是能力曲线的一个急剧拐点。随着计算能力超越zettaFLOPs阈值,技术跃迁、基础设施压力和资本市场重新定价将同步发生。
对行业而言,这是一个“加速压缩”的时刻——更快的技术周期、更激烈的资本竞争,以及基础设施作为关键差异化因素。换言之,AI的未来将不仅是模型演进,更是技术-能源-产业-资本-地缘政治链的同步重构。
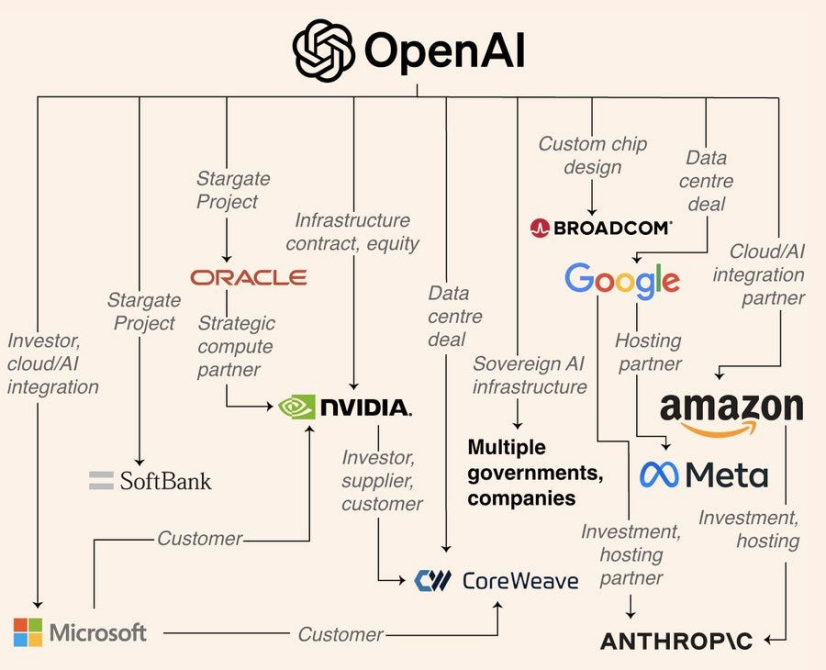
AI芯片行业格局正在经历深刻变革。多年来,供应链——从计算核心(GPUs)到HBM采购——几乎完全由英伟达主导,形成了高度集中的结构。然而,如今包括OpenAI、谷歌、Meta、亚马逊云服务(AWS)和华为在内的科技巨头正战略性地追求“去英伟达化”路径,开发自己的AI芯片,并重塑HBM供应链的权力动态。
HBM(高带宽内存)是AI芯片的核心组件之一,提供超高带宽(>1 TB/s)、高堆叠(12-24层TSV)、显著功耗(每堆栈20-30 W)和复杂的共封装要求。目前市场由SK海力士、三星和美光主导,英伟达占约70%的HBM总采购量。HBM3和HBM3E是当前主流规格,而HBM4E预计于2026年进入商业部署。
OpenAI最近转变了其技术战略,不再完全依赖GPUs。它正与博通合作,利用台积电3纳米工艺开发定制AI ASICs,并在CoWoS-L或SoIC平台上搭配HBM4/HBM4E。这标志着OpenAI从英伟达客户向直接HBM买家的转型,这一转变不仅是技术变化,更是供应链内部权力的根本性重新分配。
原文媒体:Substack
原文链接:
https://tspasemiconductor.substack.com/p/the-infinite-ai-compute-loop-hbm











