一水 发自 凹非寺
量子位 | 公众号 QbitAI
用百万亿Token揭示今年AI发展趋势,硅谷的这份报告火了!
无论是分析问题的角度,还是里面得出的一些结论,都被𝕏网友热烈讨论。
而且里面还公开肯定了中国开源模型,其每周Token用量占比一度高达30%。并且除了DeepSeek,编程领域的新秀MiniMax也被特意cue到。
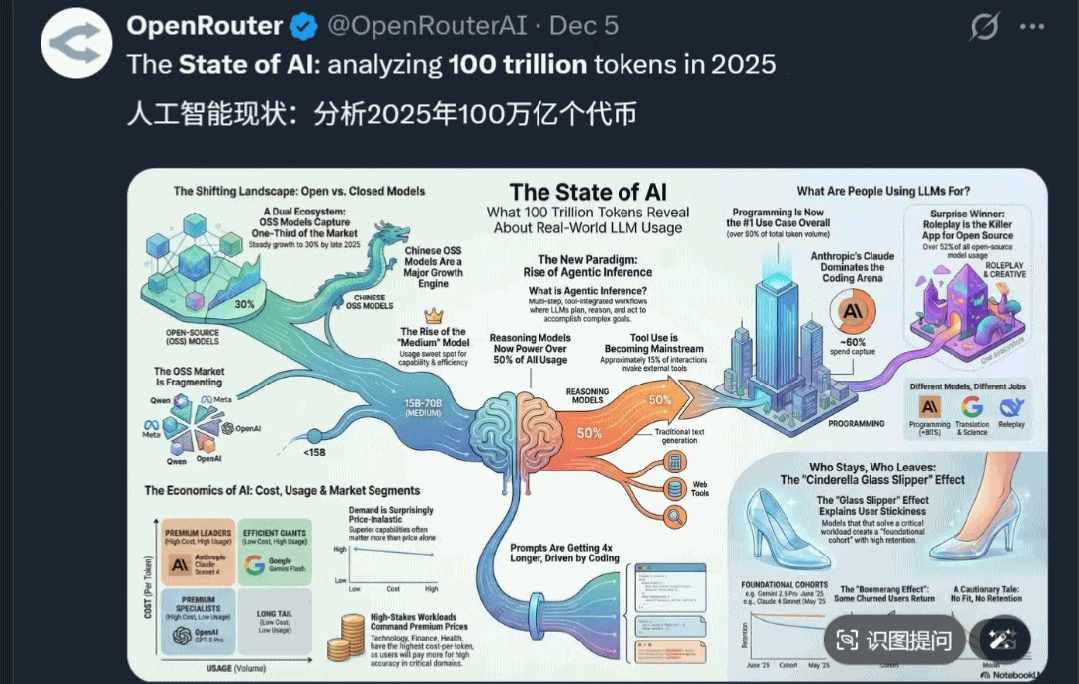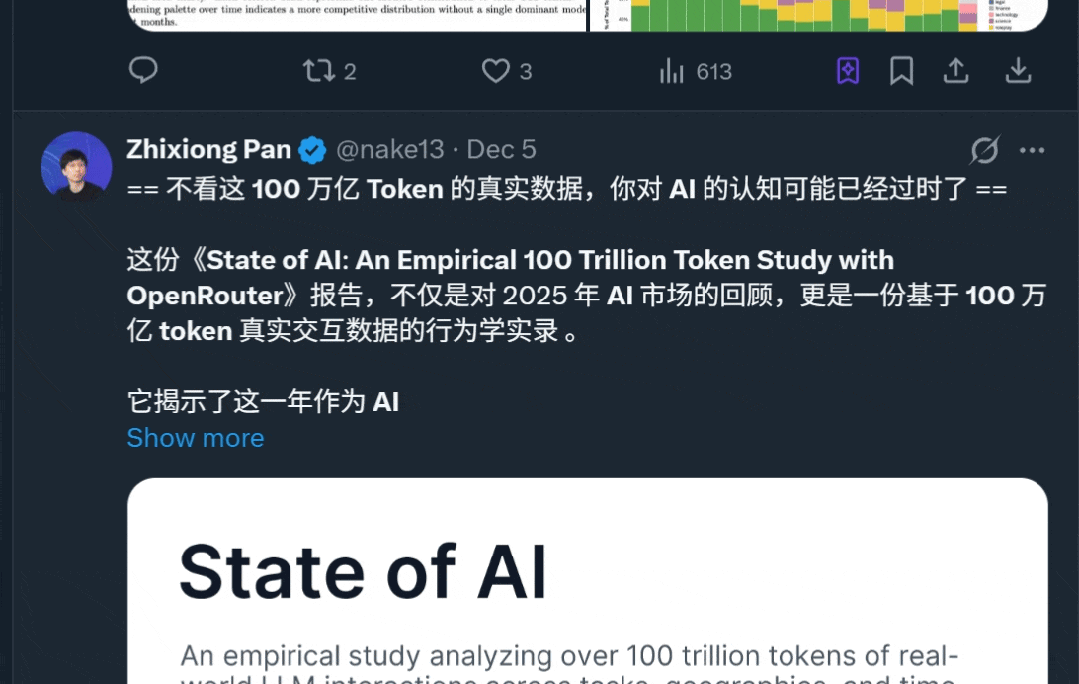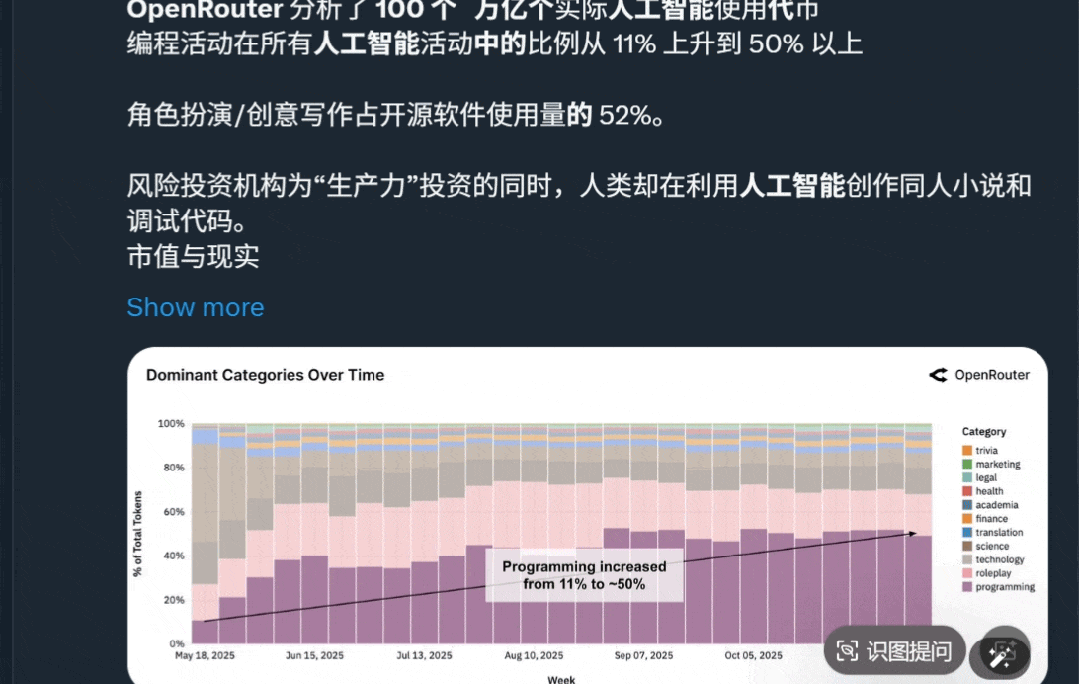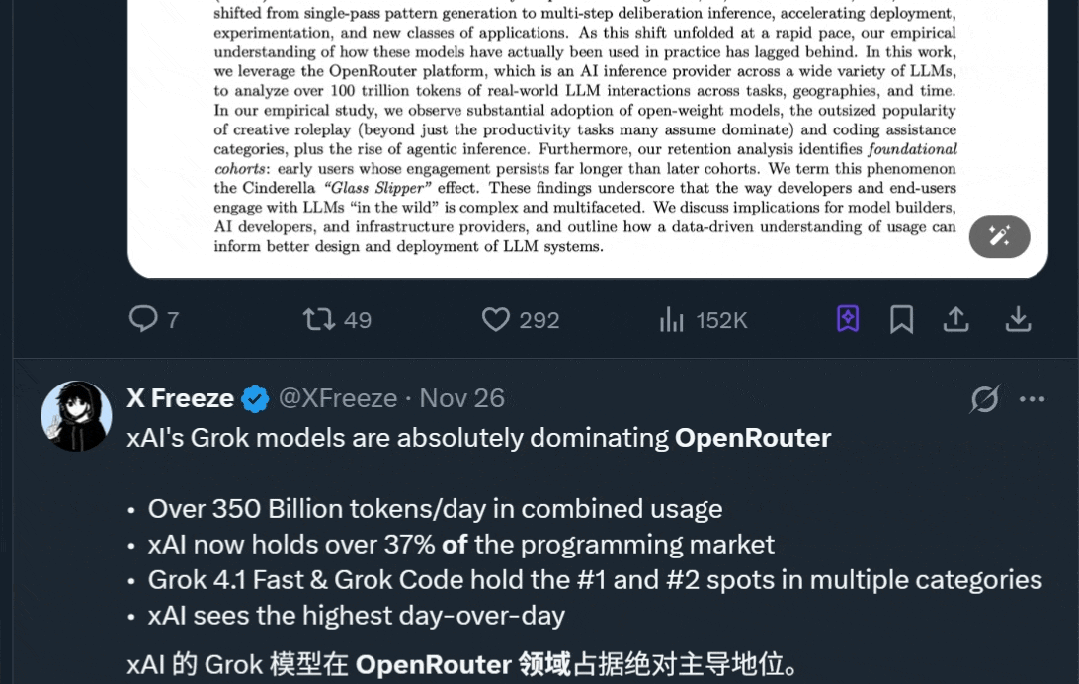
这份报告由OpenRouter和a16z联合出品,标题为《State of AI:An Empirical 100 Trillion Token Study with OpenRouter》。
里面分析了自2024年11月至2025年11月,OpenRouter平台上300+模型的使用情况,涵盖GPT系列、Claude、Gemini、DeepSeek、Qwen、Kimi等国内外主流开源与闭源模型。

而且统计的角度相当特别——不看各种基准得分,而是看模型的真实Token消耗量。
Token消耗量直接反映了模型被使用的方式和程度,因此比测试分数更能揭示其本质价值。
这一次,他们基于100万亿Token,在报告里得出了以下主要结论(省流版):
-
预计到年底,开源模型的使用量将达到约1/3,与闭源模型形成互补而非零和博弈; -
开源力量中,中国模型尤为受到青睐,流量份额从1.2%激增至30%; -
模型正在从“语言生成系统”转变为“推理执行系统”,推理模型成为新范式; -
编程和角色扮演是模型的主要使用方式; -
用户留存情况呈现“水晶鞋效应”(一旦合脚就能大放光彩),新模型发布时能否完美解决某类痛点成为关键; -
模型价格下降固然重要,但远没有你想象的那么重要。
如果你也想一览2025年AI发展详情,那就快来和量子位一起深度学习吧。

开源不再是闭源平替,中国力量上大分
关于开源模型(OSS模型),报告主要回答了这样几个核心问题:
问题1:过去一年,开源模型和闭源模型的力量对比变化如何?
问题2:有哪些关键的开源参与者?
问题3:开源模型的形态正在发生哪些变化?
首先,以前大多认为开源模型是闭源模型的“平替”,开发者往往需要二选一。但现在,开源模型已经找到了自己的独特定位,成为某些特定场景的首选。
因此,如今二者的关系更接近互补,开发者也往往同时在使用这两类模型。
而且值得一提的是,开源模型的使用量一直在稳步增长——随着DeepSeek V3、 Kimi K2等主要开源模型的发布,预计到2025年底将达到约三分之一的用量。

与此同时,中国开源模型正在成为这一增长背后的主要引擎。
国产开源模型的每周使用量占比,从去年底的1.2%最高上涨至30%,平均下来也有13%。作为对比,其他地区开源模型的平均份额为13.7%。

不过需要说明,开源模型的格局已经发生显著变化——
虽然按照总使用量计算,DeepSeek仍是最大贡献者。但随着更多开源模型涌入,其主导地位已经被削弱。
以“夏季拐点(2025年中)”为界线,上半年开源力量高度集中于DeepSeek V3和R1(约占一半以上),下半年却呈现多元化趋势,包括MiniMax M2、Kimi K2、GPT-OSS等相继发布。
预计到2025年底,没有一个单一模型能持续占比超25%Token用量,整个开源市场将由5~7个模型均分。
总之,2025年开源领域的竞争明显更加激烈了,而且未来大概率不会出现一家独大的情况。

另外,开源模型的形态也正在发生变化,目前中型模型更加获得市场青睐。报告给出的分类是:
-
大型:参数为700亿或更多的模型 -
中型:参数在150亿到700亿之间的模型 -
小型:参数少于150亿的模型
之前开源模型大多在两种极端之间平衡——要么“快而弱”,要么“强而贵/慢”,没有太多“又快又足够强”的中间选择。
但是现在,虽然大、中、小类别的模型数量都在增长,但数据显示小模型正在失宠,而中型和大型模型正在补位。
报告提到,在2024年11月Qwen2.5-Coder-32B发布之前,这个细分市场几乎可以忽略不计。但之后又涌入了Mistral Small 3和GPT-OSS 20B等模型,于是这个细分市场逐渐成为又一个竞技场。报告表示:
小模型主导开源生态系统的时代可能已经过去。市场现在正分化为两类,用户要么倾向于一个新兴的、强大的中型模型类别,要么将其工作负载整合到最强大的单个大型模型上。

推理模型成新范式
其次,语言模型正在从一个对话系统升级为推理系统、执行系统。
年初时,模型使用推理的Token用量还可以忽略不计,但现在已经超过50%。

在所有推理模型中,目前马斯克xAI旗下的Grok Code Fast 1用的推理流量份额最大,领先于Gemini 2.5 Pro和Gemini 2.5 Flash。
而大约几周前,Gemini 2.5 Pro才是主力,另外像DeepSeek R1和Qwen3也在使用前列。报告表示:
推理模型正在成为真实工作负载的默认选择。

同时,模型调用工具的占比也在上升。
该功能最初仅集中于一小部分模型,包括GPT-4o-mini和Claude 3.5、3.7系列,它们在年初占了大头。
而到了年中,有越来越多的模型开始支持工具调用,这反映出一个更具竞争性和多样化的生态系统。
从9月底开始,Claude 4.5 Sonnet模型迅速获得了份额,同时像Grok Code Fast和GLM 4.5这样的新玩家也取得了肉眼可见的进展。
报告表示,这对模型运营商来说信号相当明确:
工具使用在高价值工作流中呈上升趋势。没有可靠工具的模型有在企业采用和编排环境方面落后的风险。

编程和角色扮演成AI主要使用方式
此外,过去一年里,AI模型的使用方式发生了根本变化,主要体现在以下三点:
一是任务变复杂了——从“写短文”到“解难题”。
以前大家主要让AI生成文章或简单回答,现在更多的是让它分析一整份文档、一个代码库或很长的对话记录,从中提炼关键信息。
二是输入输出都变“重”了。
报告提到,用户平均每次给模型的提示词增加了约4倍,这反映出工作负载越来越依赖上下文信息。

并且由于模型推理消耗更多Token,模型完成任务需要的用量也增加了近3倍。

三是模型正变成“自动Agent”。
用户不再满足于问一句答一句。现在的典型用法是,给模型一个复杂目标,让它自己规划步骤、调用各种工具(如搜索、运行代码)、在长时间对话中记住状态,最终完成任务。
就是说,AI正在从“聊天机器人”转变为能独立完成工作的“智能Agent”。
而且值得一提的是,在所有任务类别中,编程和角色扮演目前是AI的主要使用方式。
编程是所有类别中增长最稳定的,其查询用量从年初的11%上涨至最近的超50%。

在所有编程模型当中, Claude系列模型始终占据主导地位,大部分时间其占比超过60%。
但这一地位正在被动摇。2025年11月,Anthropic在该领域的市场份额首次跌破60%,而在7月以来,OpenAI的市场份额已从约2%增长至近几周的约8%。
同期,谷歌的市场份额保持稳定,约为15%。另外几个开源模型(比如Qwen和Mistral)也正在稳步提升市场份额。报告还特意提到:
尤其是MiniMax,已成为快速崛起的新秀,近几周取得了显著增长。

此外,角色扮演也几乎与编程持平。在开源模型中(一般限制会更小一点),它甚至占到52%的使用量。
在这一领域,中国开源模型和西方开源模型平分秋色。DeepSeek的流量中,有超过2/3是角色扮演和闲聊,显示了其在消费者端的极高粘性。

主流模型都有自己的打开方式
而除了喜欢在DeepSeek玩角色扮演,用户对于各大主流模型都有自己钟爱的“打开方式”。
Anthropic显然是当之无愧的程序员,其80%以上流量均用于编程和技术任务。

谷歌更像一位全才,用途相对宽泛,涵盖法律、科学、技术和一些常识性查询。

马斯克旗下的xAI也在死磕编程,其技术应用、角色扮演及学术用途在十一月下旬显著增长。

OpenAI的工作重点则随着时间发生明显偏移,从娱乐休闲活动逐渐转向编程和技术类任务。

Qwen模型同样发力编程端,角色扮演和科学类任务则随时间有所波动。

总之,用户使用最多的编程正在成为兵家必争之地。
用户留存呈现“水晶鞋效应”
BTW,报告专门针对用户留存问题还提出了一个有趣的“水晶鞋效应”。
它是指,大部分用户会快速流失,但每一代“前沿”AI模型发布时,都会锁定一小批“天选用户”。这些用户的任务需求恰好与这个模型的新能力完美匹配,就像灰姑娘穿上了刚好合脚的水晶鞋。一旦穿上,他们就很难换掉,即使后面有更好的模型出现。
典型的例子就是5月发布的Claude 4 Sonnet和6月发布的Gemini 2.5 Pro,其用户留存率在5个月后还保持着40%的高水平,而这也正是取决于它们在工具调用和推理能力上取得的突破。
这也提醒大家,有时候“快”比“好”更重要。第一个用突破性能力解决关键问题的模型,即使后来被全面赶超,也能凭借早期建立的用户习惯和系统集成,长期守住基本盘。

这里也用一些大家熟知的模型打个样,看看具体有哪几种模式:
-
成功锁定(如Claude、GPT-4o Mini):在刚发布时就抓住了一批核心用户,这些用户粘性极高。 -
从未合脚(如Gemini 2.0 Flash):模型发布时没有带来突破性的能力,所以用户留不住,表现平平。 -
回旋镖效应(如DeepSeek):一些用户试用后离开,但尝试了其他模型后又回来了。因为他们发现,DeepSeek在性价比或特定能力上仍然是更好的选择。
不过报告也提到,“水晶鞋效应”的窗口期很短,基本只在它刚发布、被视为“最前沿”的那段时间。
一旦后续竞品发布,能力差距被抹平,再想吸引和锁定新用户就非常困难了。
另外,除了上面这些,报告得出的其他结论还有:
-
AI不再是硅谷的独角戏,亚洲地区的付费使用量占比从13%翻倍至31%; -
北美的AI地位相对下降,虽然仍是最大市场,但份额已不足50%; -
英语依然占据82%的绝对主导,但简体中文以近5%的份额位居第二; -
模型定价对使用量的影响比想象中要小,价格下降10%,使用量仅增加0.5%-0.7%。
而且降价并不意味着用户花钱就少了,当某些模型变得足够便宜且好用时,人们会在更多地方、用更长上下文、更频繁地调用它。
于是总Token反而飙升,总支出可能并不降低,这也是报告中提到的“杰文斯悖论”。
最后需要提醒,这份报告也存在一定局限性。OpenRouter主要反映的是开发者和服务端API调用行为,但现实里还有大量用户通过App或Web直接访问(如ChatGPT App/Web),这些流量都不在OpenRouter内。
而且OpenRouter的定价策略也会左右开发者选择。例如,如果GPT-5.1在平台上贵,而Claude更便宜,那么使用数据很可能往Claude倾斜,但这无法真实代表“Claude就更受欢迎”。
但不管怎样,这份报告无疑为我们提供了一个新视角、一份新参考答案。
而这,或许是其最大的价值。
报告地址:
https://openrouter.ai/state-of-ai
参考链接:
[1]https://x.com/OpenRouterAI/status/1996678816820089131
[2]https://x.com/imxiaohu/status/1997489223486865912
— 完 —






![[生态进展] VSCode RISC-V 插件正式支持进迭时空(SpacemiT)AI 拓展指令集](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2026-03-02/69a57ce3423bf.jpeg)



