
当你戴着运动相机做饭、修理家电时,镜头记录下的不仅是动作,更是“眼睛看到的场景+大脑的决策+手部的交互”——这种第一人称(自我中心)视角的体验,正是人形机器人最需要的“生存技能”。毕竟,机器人的感知、规划和动作都依赖于自身的视角,而非上帝视角的观察。
但长期以来,主流视觉语言模型(VLM) 的训练数据多是第三人称内容,面对第一人称视频时常常“水土不服”:快速的视角变化、手与物体的遮挡、缺乏完整身体参考,让模型难以理解动作逻辑和物理因果。更棘手的是,获取大规模机器人第一视角数据成本极高,硬件、人力、安全约束让数据规模化难上加难。
如何破解这一困境?来自香港科技大学(广州)、中关村研究院、中关村人工智能研究院、DeepCybo等机构的研究团队,提出了一项新方案:用人类大规模第一视角视频作为“桥梁”,将其转化为结构化训练数据 ,让VLM自然习得物理智能,进而赋能机器人操控。
这项名为PhysBrain的工作,不仅构建了包含300万条标注的E2E-3M数据集,更实现了第一视角理解与机器人控制的双重突破。

论文链接:https://huggingface.co/papers/2512.16793
项目主页:https://zgc-embodyai.github.io/PhysBrain/
PaperScope解读:https://www.paperscope.ai/sm/2512.16793
一、研究背景:为什么第一视角理解对机器人如此重要?
要让机器人走进家庭、工厂,完成做饭、组装、维修等复杂任务,核心是具备物理智能——也就是理解状态变化、接触式交互、长时程规划的能力,而这一切都必须基于第一视角感知。
想象一下:当机器人要“把胡萝卜放到盘子里”,它看到的是自己的机械臂、眼前的胡萝卜和盘子,而非从侧面拍摄的完整场景。这种视角下,它需要解决三个关键问题:① 识别“哪只手(机械臂)在控制物体”;② 预判“移动胡萝卜时会不会碰到其他东西”;③ 规划“先伸手、再抓取、最后放置”的连贯步骤。
但现有VLM存在两大痛点:
-
视角错位:VLM多基于第三人称数据训练,缺乏第一视角的空间感知和动作关联能力,面对手-物遮挡、视角快速切换时容易“confusion”(混乱);
-
数据瓶颈:机器人第一视角数据采集成本极高,单条有效数据需要专业设备、人工操作和安全保障,难以规模化覆盖多样化场景。
与之形成对比的是,人类第一视角视频(如Ego4D、BuildAI等数据集)早已规模化——这些视频涵盖家庭、工厂、实验室等场景,自然记录了人类与物体的交互逻辑、动作序列和因果关系,而且采集成本极低。研究团队的核心洞察是:人类第一视角视频中蕴含的“感知-决策-动作”模式,正是机器人需要的物理智能雏形,关键是如何将原始视频转化为模型能理解的训练信号。
二、核心方法:从人类第一视角视频到结构化训练数据的“翻译”之旅
要让原始视频成为有效训练数据,最大的挑战是:视频是连续的像素流,缺乏明确的结构、因果标注和逻辑一致性。
为此,研究团队设计了一套名为“Egocentric2Embodiment”的翻译步骤,将无结构的人类第一视角视频,系统转化为多层次、可验证的视觉问答(VQA)训练数据,最终构建出E2E-3M数据集。
1. 四阶段翻译步骤:让视频“说话”,且说对话
这套翻译步骤的核心是“schema驱动+规则验证”,确保生成的训练数据结构化、逻辑一致且符合第一视角认知,整个流程分为四个阶段:

图1 Egocentric2Embodiment翻译步骤示意图。该步骤通过四阶段流程,将原始人类第一视角视频转化为结构化VQA数据,包含数据预处理、标注方案执行、质量验证和输出四个核心环节,全程通过规则校验确保数据可靠性。
第一阶段是数据预处理:将长视频按场景特点分割为短片段——比如固定时间间隔分割、事件驱动分割(如“拿起物体”作为一个片段)、运动感知分割(基于手腕速度等运动特征),同时记录片段的时间信息和场景元数据,为后续标注提供上下文。
第二阶段是schema驱动标注:设计7种互补的VQA模式,涵盖时间(如“先做了什么,后做了什么”)、空间(如“物体在左手的哪个方向”)、属性(如“物体的材质是硬的还是软的”)、力学(如“接触时用了多大力度”)、推理(如“为什么要先打开盖子”)、总结(如“这个片段的核心任务是什么”)、轨迹(如“手部移动的路径是怎样的”)。每个模式都有标准化模板,确保标注的一致性,再通过VLM(如Qwen2.5-VL-72B、GPT-4)生成定制化的“问题-答案”对。
第三阶段是严格质量验证:这是避免数据“幻觉”的关键。研究团队设计了确定性规则校验器,从三个维度把关:① 事实核验(Evidence grounding):答案必须有视频帧作为支撑,不能虚构未出现的动作或物体;② 第一视角一致性:必须正确区分左右手,不能提及未出现的身体部位;③ 时间逻辑:时间相关的答案必须符合视频时序。未通过校验的样本会被退回重新生成,直到满足所有约束。
第四阶段是结构化输出:将通过校验的“视频片段+VQA对+标注模式+验证结果”整理归档,形成最终的训练数据。
2. E2E-3M数据集:覆盖三大场景,兼具广度与深度
通过上述管道,研究团队处理了Ego4D(家庭场景)、BuildAI(工厂场景)、EgoDex(实验室场景)三大数据集的人类第一视角视频,构建出包含300万条有效VQA实例的E2E-3M数据集——这是目前规模最大、结构最完善的第一视角物理智能训练数据集之一。
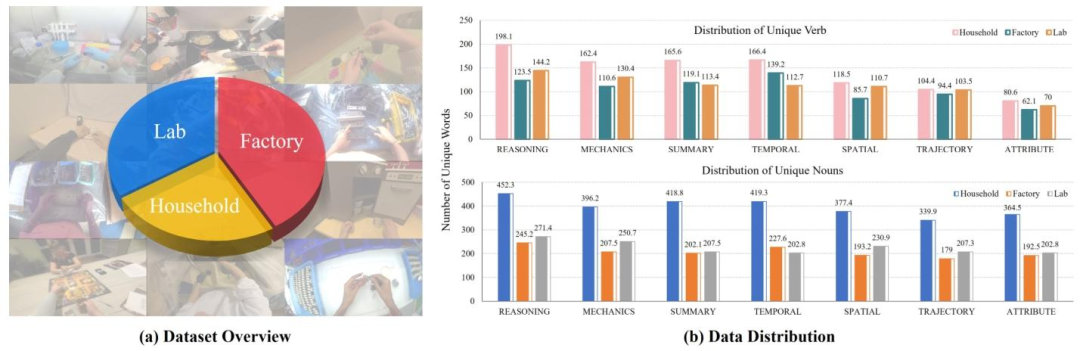
图2 E2E-3M数据集概述与数据分布。(a) 数据集覆盖家庭、工厂、实验室三大场景,捕捉多样化的人类-物体交互;(b) 上图为独特动词分布,下图为独特名词分布,体现了动作和物体的丰富性,不同场景的数据形成互补。
数据集的多样性体现在两个核心维度:
-
物体覆盖度:家庭场景的物体多样性最高(300-350种/千个名词),涵盖日常用品、厨具等;实验室场景中等(200-300种),以实验器材为主;工厂场景则侧重专用工具,形成互补。
-
动作覆盖度:以动作导向的模式(包括推理、机制、时间、总结)在各个领域的占比普遍处于极高水平(≥160种/千条VQA),空间、轨迹、属性类模式的占比则多为中等水平。这也精准、合理地匹配物理智能所需的核心能力。
3. PhysBrain模型:基于E2E-3M训练的第一视角“智能大脑”
有了高质量数据集,研究团队通过“监督微调(SFT)” 训练出PhysBrain模型——这是一款以第一视角理解为核心的embodied brain(具身大脑) 。训练过程中,团队将E2E-3M数据与通用视觉语言数据混合,既强化第一视角推理能力,又保留通用的图文理解能力。
为了验证PhysBrain在机器人控制中的实用性,研究团队设计了两种VLA(视觉语言动作)架构,将模型与动作生成模块结合:
-
PhysGR00T:采用“双系统”设计,PhysBrain作为“高级决策系统”输出多模态特征,流动匹配(FM)扩散模型作为“动作执行系统”生成连续动作;
-
PhysPI:更紧密的耦合方式,将PhysBrain的多个中间层特征通过跨注意力注入动作生成模块,充分利用模型的层级化推理能力。

图3 基于PhysBrain的VLA架构。(a) PhysGR00T架构,PhysBrain输出最后一层特征作为动作专家的条件信号;(b) PhysPI架构,通过层间跨注意力注入多个VLM层特征,强化模型与动作生成的耦合。
三、实验验证:两大基准测试,彰显全方位优势
研究团队从“第一视角理解”和“机器人控制”两个维度,对PhysBrain进行了全面测试,结果显示其性能大幅超越现有基线模型,充分验证了人类第一视角数据的价值。

1. EgoThink基准:第一视角推理能力超越GPT-4,规划维度表现最优
EgoThink是基于Ego4D数据集的第一视角推理基准,涵盖活动识别、预测、定位、物体识别、规划、推理六个核心维度。为了避免数据泄露,PhysBrain训练时剔除了Ego4D相关数据,仅使用工厂和实验室场景的E2E-3M子集。
测试结果显示:
-
PhysBrain平均得分64.3,仅次于GPT-4(67.4),大幅超越Qwen2.5-VL-7B(57.3)、RoboBrain2.0-7B(53.1)等开源基线模型;
-
最亮眼的是“规划”维度,PhysBrain得分64.5,不仅远超所有开源模型,甚至超过了GPT-4(35.5)——这意味着PhysBrain能更好地将第一视角观察转化为可执行的步骤,这正是机器人控制的核心需求;
-
在活动识别(70分)、物体识别(65.3分)等维度,PhysBrain也接近GPT-4的水平,证明其没有因强化第一视角能力而牺牲通用理解能力。

图4 第一视角具身智能模型与基准模型的性能对比。左图展示了六个基准模型在EgoThink的六个以自我为中心的评估维度上的基准表现;右图上半部分为Phys增强型VLM(Phys + VST-7B)与原始VLM(VST-7B)在EgoThink上的得分对比,规划维度提升最显著;右图下半部分为在SimplerEnv基准上的机器人控制成功率,Phys增强型模型表现更优。
2. SimplerEnv仿真:机器人控制成功率达53.9%,超越大规模机器人数据训练模型
SimplerEnv是机器人操控仿真基准,包含“把勺子放在毛巾上”“把胡萝卜放在盘子里”“堆叠积木”“把茄子放进黄篮子”四项核心任务,使用WidowX机器人进行测试。
研究团队将PhysBrain作为VLM backbone,在Open X-Embodiment数据集的两个子集(Bridge和Fractal)上微调后,取得了以下突破:
-
平均成功率达53.9% ,超越所有开源VLA基线模型——包括基于完整Open X-Embodiment数据集(55个子集)训练的OpenVLA(42.7%)、RoboVLM(42.7%)等;
-
对比相同训练范式的VLM基线,PhysBrain平均领先8.8% ,比专为具身智能设计的RoboBrain2.0-7B高出16.1% ;
-
即使在PhysPI架构下(更复杂的耦合方式),PhysBrain的平均成功率仍达36.7%,远超Qwen2.5-VL-7B(8.65%)等基线,证明其特征的强适配性。

更重要的是,这项结果验证了“人类第一视角数据+少量机器人数据”的训练范式的有效性——无需大规模昂贵的机器人演示,仅通过人类日常第一视角视频,就能让模型具备强大的迁移能力,大幅降低机器人智能训练的成本。
3. 数据互补性验证:人类第一视角数据与机器人数据相辅相成
研究团队还通过补充实验证明,人类第一视角数据与机器人数据并非替代关系,而是互补关系:
-
在Spatial Aptitude Training(SAT)测试中,VST模型(预训练于静态空间智能数据)在第一视角运动任务上准确率仅26.09% ,经E2E-3M微调后飙升至**91.30%**,在“动作结果”和“视角判断”类任务上的性能也有一定程度的改善,而“物体运动”和“目标指向”类任务的准确率基本不变
-
上述结果表明,基于 E2E 数据集的监督训练能够针对性地提升模型在自我中心视角推理与动态空间推理方面的性能,有效补充了 VST 模型原有的静态空间先验知识,并且无需依赖特定任务的训练数据即可实现性能泛化。
四、未来方向与局限
尽管PhysBrain取得了显著突破,但研究团队也指出了未来需要探索的方向:
-
架构扩展:目前实验主要聚焦PhysGR00T架构,未来将深入探索PhysPI及更多架构变体,优化VLM与动作生成模块的耦合方式;
-
数据多样性:进一步扩大E2E-3M的场景覆盖,加入更多特殊环境(如极端温度、复杂地形)和特殊任务(如精密操作、协同作业)的数据;
-
多模态融合:引入触觉、力反馈等多模态信息,让模型更全面地理解物理交互,提升操控的精准度和鲁棒性;
-
真实世界部署:目前测试主要基于仿真环境,未来将推进PhysBrain在真实机器人上的部署,验证其在复杂真实场景中的泛化能力。
这项工作的局限在于,目前的动作生成模块仍依赖于扩散模型等现有框架,未针对第一视角特性进行深度优化;同时,数据集虽覆盖三大场景,但在超精密操作、动态障碍物规避等复杂任务上的样本仍需补充。
五、研究意义
这项工作的核心价值在于为通用人形机器人发展提供 “低成本、高可扩展” 新路径:
其一,以低成本人类第一视角视频替代部分高成本机器人数据,破解数据采集规模化难题,大幅降低具身智能模型训练门槛;
其二,推动 VLM 从第三人称 “旁观者视角” 转向第一视角 “参与者视角”,真正实现物理交互理解与规划,为机器人实用化奠定关键基础;
其三,开源 300 万条 E2E-3M 数据集与代码(即将开源),以高质量结构化设计成为领域基准,省去研究者重复构建数据管道的成本,加速第一视角具身智能研究创新。
结论
PhysBrain模型的成功,不仅证明了人类第一视角视频作为“VLM与物理智能桥梁”的可行性,更提供了一套完整的解决方案:从数据管道(Egocentric2Embodiment)到数据集(E2E-3M),再到模型(PhysBrain)和部署架构(PhysGR00T/PhysPI),形成了闭环。
随着这项技术的开源和普及,我们有理由期待:未来的机器人将能更快地学习人类的交互方式,更低成本地实现复杂任务,真正走进家庭、工厂、实验室,成为人类的得力助手。而这一切的起点,正是那些看似普通的人类第一视角视频——它们承载的,不仅是动作,更是物理世界的底层逻辑和智能的本质。
论文名称:PhysBrain: Human Egocentric Data as a Bridge from Vision Language Models to Physical Intelligence
论文链接:https://huggingface.co/papers/2512.16793
项目主页:https://zgc-embodyai.github.io/PhysBrain/
PaperScope解读:https://www.paperscope.ai/sm/2512.16793
> 本文由 Intern-S1 等 AI 生成,机智流编辑部校对
-- 完 --






![2025年中国水平多关节机器人市场规模、竞争格局及前景展望:国产化进程加速突破,推动SCARA机器人规模增至28.3亿元[图]](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-12-23/6949ea4542c27.jpeg)



