编辑丨机智流
当我们用手机拍摄一段 "拿起杯子放进抽屉" 的视频时,大脑能瞬间从 2D 画面中捕捉到杯子的位置、距离、手的运动轨迹等 3D 空间信息。但对于依赖视觉-语言-动作(VLA)模型的机器人来说,这却是一个巨大的挑战——它们只能从 2D 像素中解读语义,却难以建立与 3D 物理世界的有效关联,就像蒙上双眼在三维空间中摸索,常常出现“抓空”“放偏”等操作失误的尴尬局面。
这一“2D 感知与 3D 动作脱节”的问题,长期制约着机器人技术的落地应用。现有 VLA 模型大多依赖 2D 视觉输入制定行动策略,却要在真实的 3D 物理环境中执行任务,这种感知与行动的割裂,导致机器人的空间定位精度低、任务通用性差,难以适应复杂多变的现实场景。如何让机器人像人类一样,从 2D 视觉信息中精准推断 3D 空间关系,成为机器人学习领域亟待突破的核心难题。
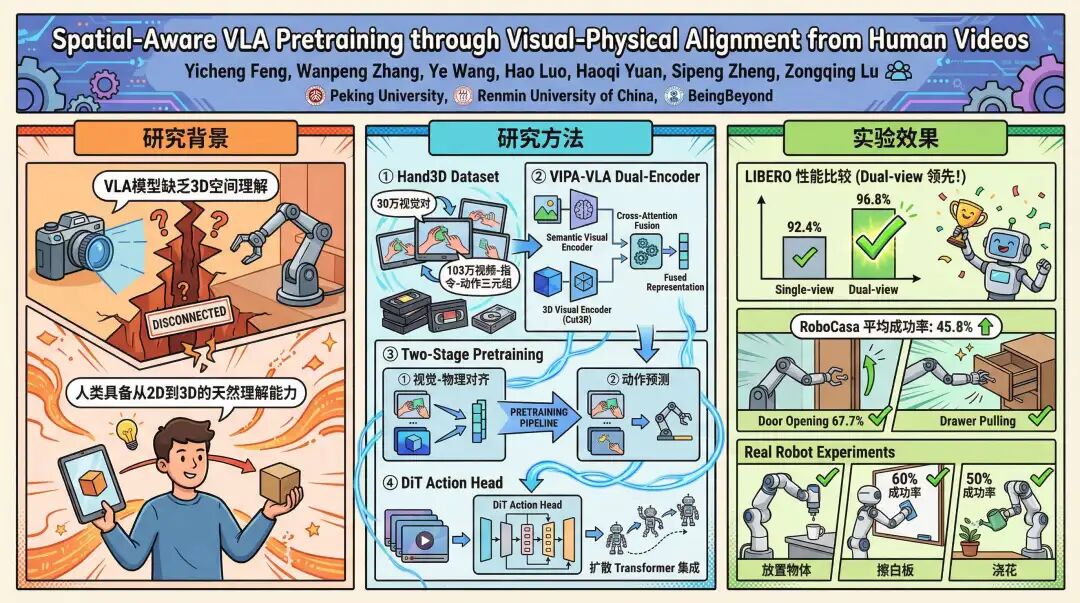
针对这一问题,来自北京大学、中国人民大学和BeingBeyond(北京智在无界)的研究团队提出了一种全新的空间感知VLA预训练范式,通过人类演示视频的视觉-物理对齐,让模型在学习机器人策略前就掌握3D空间理解能力。他们构建了Hand3D数据集,设计了双编码器架构VIPA-VLA,在模拟环境和真实机器人任务中均取得了突破性成果。

论文标题:Spatial-Aware VLA Pretraining through Visual-Physical Alignment from Human Videos
论文链接:https://huggingface.co/papers/2512.13080
项目主页:https://beingbeyond.github.io/VIPA-VLA
PaperScope解读:https://www.paperscope.ai/hf/2512.13080
一、研究背景:为什么人类视频是机器人学习的“金钥匙”?
现有VLA模型的局限主要源于两个核心问题:一是训练数据依赖机器人数据集,这类数据采集成本高、场景单一,难以覆盖真实世界的复杂情况;二是缺乏显式的3D空间建模,仅靠2D视觉特征无法精准映射物理空间中的动作逻辑。
研究团队发现,人类演示视频恰好能解决这两个问题:一方面,人类日常操作的视频(如做饭、整理、工具使用)易于大规模获取,涵盖了多样化的场景、物体和动作模式;另一方面,这些视频中蕴含着天然的“视觉-物理对应关系”——手部与物体的3D相对位置、动作的空间轨迹、任务目标与运动的关联,都是机器人学习3D空间理解的优质监督信号。
与直接对齐人类与机器人动作空间的方法不同,该研究的核心洞察是:无需纠结于人类与机器人的“身体差异”(embodiment mismatch),而是提取人类动作中不变的3D空间逻辑——比如“抓取物体需靠近其重心”“旋转抽屉需沿特定轴运动”,这些空间先验知识可以跨载体迁移到机器人身上。
二、核心支撑:Hand3D数据集——给机器人的“3D空间教科书”
要让模型学习视觉-物理对齐,首先需要高质量的标注数据。研究团队构建了Hand3D数据集,分为Hand3D-visual(3D视觉标注)和Hand3D-action(3D动作标注)两部分,堪称机器人的“3D空间教科书”。
Hand3D的数据源涵盖9个异构人类操控数据集,包括动作捕捉数据(如Arctic、HOI4D)、VR录制数据(EgoDex)和伪标注视频数据(Taste-Rob),确保了场景和任务的多样性。为了统一标注格式,团队将所有手部姿态对齐到MANO参数模型——这是一种标准化的人类手部形状与姿态表示,能精准描述21个手部关节的3D位置。
1. 3D视觉标注:让2D图像“长出”3D结构
Hand3D-visual的核心是将2D视频帧与3D物理空间关联起来。具体来说,团队通过三步实现:
首先,用Cut3R模型估计每帧的密集点云,获取每个像素的3D坐标;其次,用Gemini-2.5-flash生成物体提议,结合GroundingDINO得到2D边界框,再通过点云的深度信息定位物体的3D位置;最后,利用MANO手部姿态和相机参数计算3D关节位置,并通过“尺度校准”解决点云相对尺度与物理空间不匹配的问题——以手部关节的绝对深度为基准,调整点云尺度,确保手部和物体处于统一的3D坐标系中。
在此基础上,团队用Gemini-2.5-flash生成四类视觉问答(VQA)标签,将3D空间信息转化为模型可学习的语言监督:包括物体与手部的3D空间关系(如“杯子在手掌前方5厘米”)、任务完成所需的3D动作(如“将勺子向上移动10厘米”)、手部运动轨迹(方向+距离)和相机运动(旋转+平移)。最终,Hand3D-visual包含约30万条指令-答案对,覆盖四大任务类型。

图1:Hand3D-visual构建流程示意图。通过点云估计、物体定位和手部姿态标注的融合,将2D视觉观测与3D物理空间关联,为VLA模型提供视觉-物理对齐监督。

图2:Hand3D-visual数据示例。
2. 3D动作标注:捕捉人类动作的3D动态逻辑
Hand3D-action聚焦于动作的动态特征,从人类视频中提取手腕的3D轨迹,将其离散化为“运动令牌”(motion tokens)。具体来说,团队将每帧手腕的(x,y,z)坐标映射到预定义的3D空间范围(x/y轴:-0.5~0.5米,z轴:0~1米),并均匀离散为1024个区间,每个坐标对应一个令牌,最终形成序列化的运动表示。
同时,团队用Gemini-2.5-flash为视频生成任务指令,并设计了三类动作相关任务:指令驱动的运动生成、运动翻译(如将自然语言描述转化为运动令牌)和上下文运动预测。经过筛选,Hand3D-action包含103万条视频-指令-运动三元组,为模型提供细粒度的3D动作监督。
值得一提的是,Hand3D数据集无需依赖昂贵的3D扫描设备,仅通过现有视频和算法就能生成高质量标注,大幅降低了3D空间监督数据的获取成本。
三、模型架构:VIPA-VLA——双编码器解锁空间-语义融合
为了充分利用Hand3D的3D监督信息,研究团队设计了VIPA-VLA(Visual-Physical-Alignment VLA)双编码器架构,核心是将语义视觉特征与3D空间特征深度融合,让模型既能“看懂”场景语义,又能“感知”3D结构。
1. 双编码器设计:语义与空间的双向奔赴
VIPA-VLA的编码器包含两个核心模块:
-
语义视觉编码器:基于预训练的视觉-语言模型(InternVL3.5-2B),负责提取图像的高层语义特征(如“这是一个杯子”“手部在抓取物体”),输出语义嵌入V_sem;
-
3D视觉编码器:采用Cut3R模型,这是一种在人机交互数据上预训练的连续3D感知模型,能从单张2D图像中估计密集点云,输出包含几何信息的空间嵌入V_spa。
为了融合这两种互补特征,团队设计了基于交叉注意力的融合层:首先将V_sem和V_spa投影到同一特征空间,然后让语义视觉令牌对3D空间令牌进行查询,捕捉两者的关联;最后通过残差连接(带可学习缩放参数α)将融合后的空间特征F_spa与原始语义特征V_sem结合,得到最终的融合特征V_f = V_sem + α·F_spa。这种设计既能保留预训练VLM的语义理解能力,又能注入3D空间信息。
2. 运动令牌与动作生成
在动作建模方面,VIPA-VLA将3D动作轨迹转化为运动令牌序列,扩展了语言模型的词汇表。在预训练阶段,模型学习从融合的视觉-语言特征中预测运动令牌;在下游任务中,团队引入扩散Transformer(DiT)作为动作头,结合机器人状态嵌入,生成可执行的动作块(action chunk)。
整个模型架构的逻辑可以概括为:用双编码器打通“看”(2D语义+3D空间),用运动令牌和扩散模型打通“做”(3D动作生成) ,实现从感知到动作的端到端对齐。

图3:VIPA-VLA模型架构示意图。左半部分为双编码器与融合层,实现语义-空间特征融合;右半部分为预训练与后训练流程,通过运动令牌对齐3D动作,最终生成机器人可执行动作。
四、训练流程:两阶段预训练+后训练,循序渐进掌握3D能力
VIPA-VLA的训练分为三个阶段,遵循“先空间理解,再动作接地,最后任务适配”的逻辑,确保模型循序渐进地掌握3D空间能力。
1. 阶段1:3D视觉预训练——对齐语义与空间
模型初始化时,继承预训练VLM(InternVL3.5-2B)的语义编码器参数和Cut3R的3D编码器参数,融合层随机初始化。此阶段冻结所有预训练参数,仅训练融合层,利用Hand3D-visual的VQA数据,让模型学习从2D语义特征和3D空间特征中推理3D关系(如物体位置、手部与物体距离)。目标是让模型建立“看到的2D图像”与“实际的3D结构”之间的关联。
2. 阶段2:3D动作预训练——学习动作的空间逻辑
此阶段冻结语义编码器和3D编码器,扩展LLM的词汇表以包含运动令牌,并用Hand3D-action数据训练LLM。模型需要根据融合的视觉-语言输入,预测对应的3D运动令牌序列。这一步让模型学会“如何将视觉语义和空间信息转化为物理动作”,比如根据“拿起杯子”的指令和杯子的3D位置,预测手部的抓取轨迹。
3. 阶段3:后训练——适配机器人任务
预训练完成后,模型已具备2D-3D对齐能力,接下来需要适配具体的机器人任务。团队在模型中添加DiT动作头,冻结视觉编码器和3D编码器,仅训练LLM骨干和动作头。训练数据为机器人任务的视觉帧、语言指令和对应的动作标签,模型学习生成符合机器人运动学约束的动作块。
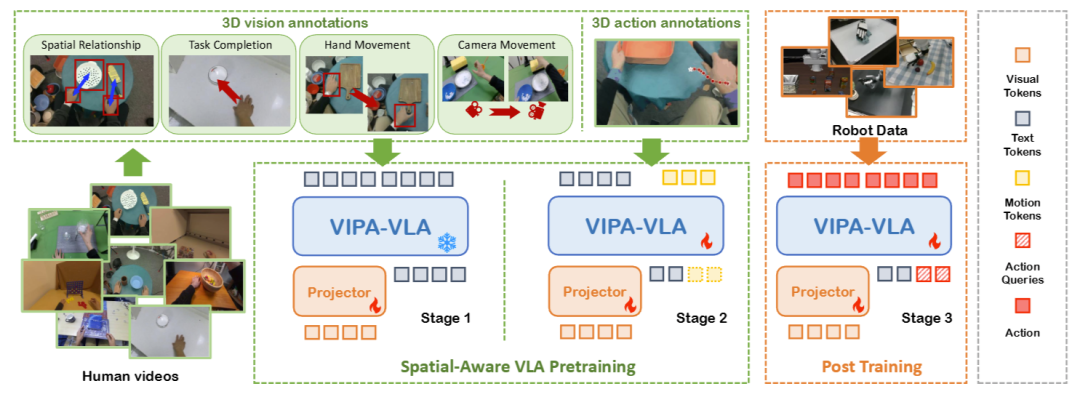
图4:VIPA-VLA训练流程示意图。从人类演示视频中提取3D标注,通过两阶段预训练实现视觉-物理对齐,最后通过后训练适配机器人操控任务。
五、实验结果:横扫模拟与真实场景,泛化性碾压基线
为了验证VIPA-VLA的性能,研究团队在三大类任务上进行了全面评估:模拟机器人任务(LIBERO、RoboCasa基准)、真实机器人任务,以及空间理解能力专项测试。结果显示,VIPA-VLA在几乎所有指标上都超越了现有基线,尤其在需要精准3D空间推理的任务中表现突出。
1. LIBERO基准:单/双视图均登顶,不依赖机器人预训练数据
LIBERO是机器人操控的标准基准,包含Spatial(空间)、Object(物体)、Goal(目标)、Long(长序列)四个任务套件,评估模型的鲁棒性和泛化性。在单视图输入设置下,VIPA-VLA的平均成功率达到92.4%,超过GR00T N1.5(92.1%)、4D-VLA(88.6%)等强基线;在双视图设置下,平均成功率高达96.8%,仅略低于π0.5(96.9%),但π0.5依赖大规模机器人数据预训练,而VIPA-VLA的预训练仅使用人类视频。
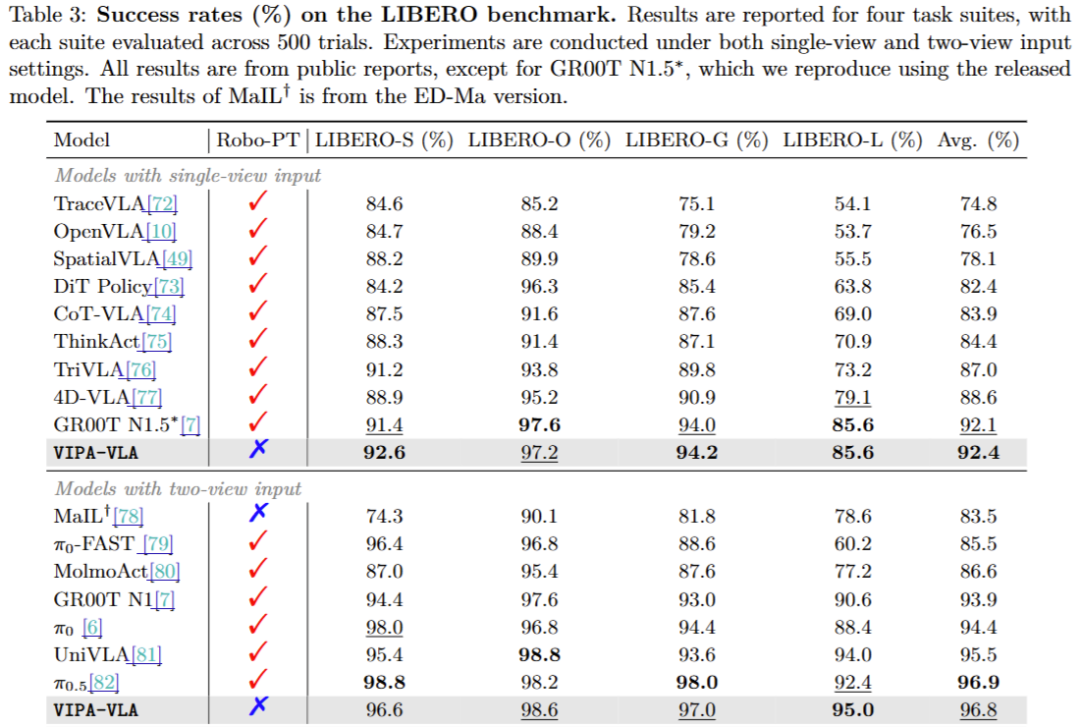
值得注意的是,在长序列任务(LIBERO-L)中,VIPA-VLA的成功率达到85.6%,显著高于SpatialVLA(55.5%)等专门优化空间推理的模型,证明其3D空间理解能力能有效支撑复杂多步任务。
2. RoboCasa基准:复杂场景下的“突围”
RoboCasa是比LIBERO更具挑战性的基准,场景布局更多样、环境更杂乱、视觉观测更复杂,对3D空间理解的要求更高。研究团队仅用每个任务50条人类演示数据训练,VIPA-VLA的平均成功率达到45.8%,超越GR00T N1(36.0%)和π0.5(41.4%)。尤其在“门/抽屉”类别中,VIPA-VLA的成功率达到67.7%,比π0.5高出9.9个百分点——这类任务需要精准的3D定位和轴对齐操作,恰好体现了视觉-物理对齐预训练的优势。
3. 真实机器人任务:从实验室走向现实
研究团队用7自由度Franka机械臂、6自由度Inspire手和两台RealSense L515相机搭建了真实实验平台,设计了三个核心任务:Put-Three-Obj(将三个水果放入抽屉)、Wipe-Board(擦拭白板笔迹)、Water-Plant(给植物浇水),并设置了“ unseen环境”(如更换桌布颜色、马克笔颜色)评估泛化性。
在真实任务中,VIPA-VLA的表现尤为亮眼:Wipe-Board任务的整体成功率达到60%,子任务成功率83%,远超GR00T N1.5(30%/57%)和InternVL3.5(10%/43%);Water-Plant任务的整体成功率50%,子任务成功率57%,同样大幅领先基线。即使在unseen环境中,VIPA-VLA的Wipe-Board任务整体成功率仍有50%,而其他模型的成功率普遍降至10%左右,证明其学到的3D空间逻辑具有极强的迁移能力。
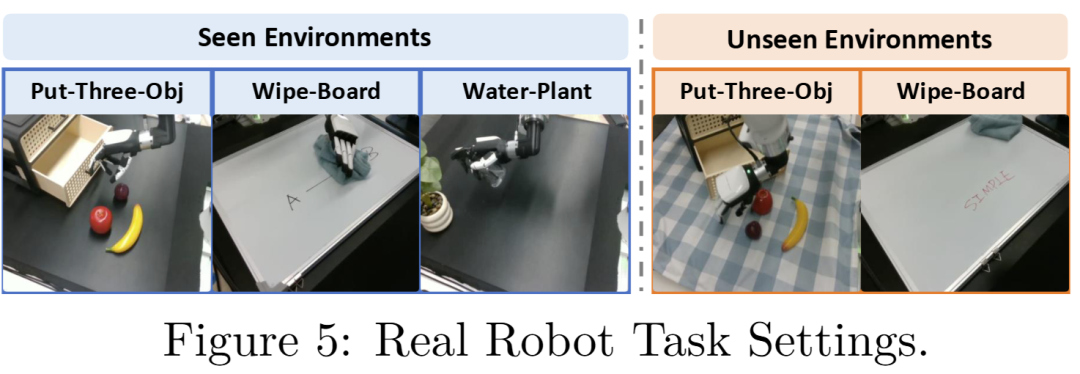
图5:真实机器人任务设置示意图。三个任务分别测试多物体操控、不规则区域作业和精细动作控制能力。

图6:VIPA-VLA执行真实机器人任务的定性示例。从上到下分别为Put-Three-Obj、Wipe-Board、Water-Plant任务,模型能精准定位物体、调整动作轨迹,适应不同场景布局。
4. 空间理解专项测试:更精准的3D推理
在Hand3D-test测试集(2000条 unseen VQA对)上,VIPA-VLA的距离预测误差仅为0.12米,方向预测准确率达到1.82/3(三轴平均),显著优于未经过空间预训练的InternVL3.5(误差0.18米,准确率1.22/3)。这表明,通过两阶段预训练,模型确实掌握了更精准的3D空间推理能力,而不仅仅是“记住”训练数据中的模式。
此外,在动作轨迹预测上,VIPA-VLA生成的轨迹比人类真实轨迹更平滑、更具目标导向性——人类轨迹往往包含冗余动作(如手部轻微晃动),而模型能提炼出核心运动逻辑,例如抓取木勺时会自动对准手柄位置,体现了对物体功能和物理约束的理解。

图7:第二阶段预训练后VIPA-VLA预测运动轨迹的可视化(蓝线)和ground-truth轨迹(即人类真实轨迹,红线)对比。
六、消融实验:关键组件的贡献验证
为了明确模型各组件的作用,研究团队进行了消融实验:
-
移除“空间感知预训练”:模型平均成功率下降1.2%,证明人类视频的3D监督能有效提升空间接地能力; -
移除“双编码器架构”:仅使用语义视觉编码器,平均成功率下降3.7%,说明3D编码器提供的几何信息是不可或缺的; -
仅移除“融合层”:平均成功率下降2.0%,验证了交叉注意力融合机制能有效结合语义与空间特征。
这些结果表明,空间感知预训练和双编码器架构是VIPA-VLA性能提升的核心,两者相辅相成——预训练提供3D监督信号,双编码器提供高效的特征融合方式,共同解决了2D-3D对齐问题。
七、研究意义与未来方向
VIPA-VLA的工作为机器人学习提供了一种新的范式:不依赖昂贵的机器人数据,而是利用海量、易获取的人类演示视频,让模型提前掌握3D空间理解能力,再适配具体的机器人任务。这种范式不仅降低了机器人学习的数据源成本,还大幅提升了模型的泛化性——因为人类演示视频涵盖的场景和动作远比机器人数据集丰富。
从应用价值来看,VIPA-VLA的技术可直接用于家庭服务机器人、工业机械臂、医疗机器人等领域,让机器人在复杂、动态的真实环境中更精准地执行任务。例如,家庭服务机器人能根据“整理桌面”的指令,自主识别不同物体的3D位置并规划抓取轨迹;工业机械臂能快速适配新的工件形状,无需重新大规模训练。
从研究角度来看,该工作首次系统地将人类视频的视觉-物理对齐用于VLA预训练,为解决“感知-动作鸿沟”提供了可复制的方案。未来,研究团队计划将这种预训练范式与机器人数据预训练相结合,进一步提升模型在特定机器人平台上的适配性;同时,他们还将扩展Hand3D数据集的场景覆盖范围,加入更多复杂的人机交互任务(如协作装配、精密操作)。
总结
VIPA-VLA的提出,标志着机器人学习在“空间理解”上迈出了关键一步。通过人类演示视频的视觉-物理对齐,模型终于能像人类一样“从2D中读懂3D”,打破了现有VLA模型的感知局限。这项来自北京大学、中国人民大学和BeingBeyond的研究,不仅在多个基准上取得了顶尖性能,更重要的是为机器人学习提供了一种更高效、更通用的训练范式——当机器人能从人类的日常行为中学习空间逻辑,它们离真正适应真实世界又近了一大步。
感兴趣的读者可以访问项目主页查看更多细节,或阅读论文原文深入了解技术细节。
论文标题:Spatial-Aware VLA Pretraining through Visual-Physical Alignment from Human Videos
论文链接:https://huggingface.co/papers/2512.13080
项目主页:https://beingbeyond.github.io/VIPA-VLA
PaperScope解读:https://www.paperscope.ai/hf/2512.13080
本文只做学术分享,如有侵权,联系删文










