在人形机器人控制领域,强化学习(RL)虽已实现从仿真到现实的迁移,但高维动作空间、强域随机化需求导致训练周期冗长,严重制约迭代效率。
亚马逊 FAR 实验室团队提出的快速强化学习方案,以优化后的离线 RL 算法(FastSAC、FastTD3)为核心,通过 “算法调优 - 极简奖励设计 - 大规模并行仿真” 的三位一体技术体系,首次实现单 GPU 15 分钟训练出鲁棒人形机器人 locomotion 政策,同时支持全身运动追踪任务的快速部署,彻底重构了人形机器人 sim-to-real 的迭代范式。
论文题目:Learning Sim-to-Real Humanoid Locomotion in 15 Minutes
FastSAC-Humanoid — Project Page:https://younggyo.me/fastsac-humanoid
核心亮点:单 GPU 15 分钟训练、离线 RL 算法规模化、极简奖励函数(<10 项)、支持 29 自由度人形机器人、强域随机化适配(崎岖地形 / 推力扰动)
问题根源:人形机器人强化学习的四大效率瓶颈
该方案的设计源于对现有 sim-to-real 训练痛点的精准拆解,四大核心挑战构成技术突破的起点:
算法样本效率低
传统主流的在线 RL 算法(如 PPO)需丢弃大量历史数据,在高维人形机器人控制中样本利用率低,训练周期动辄数小时甚至数天。
高维控制稳定性差
人形机器人(29 自由度)动作空间复杂,关节限制、力矩平衡等约束导致离线 RL 算法易出现训练振荡,难以稳定收敛。
奖励设计冗余繁琐
传统方案依赖 20 + 项奖励 shaping 条款,既增加调参难度,又易导致政策 “过拟合” 特定场景,降低真实环境适配性。
域随机化适配难
真实场景中的地形变化、外力扰动、动力学参数波动等,要求政策在强随机化仿真中学习,进一步加剧了训练难度与耗时。

方案设计:三位一体的快速训练技术体系
针对上述挑战,该方案构建了 “算法优化 - 奖励设计 - 并行仿真” 的完整技术闭环,层层递进实现高效 sim-to-real 训练:
第一层:算法优化 —— 离线 RL 的规模化适配
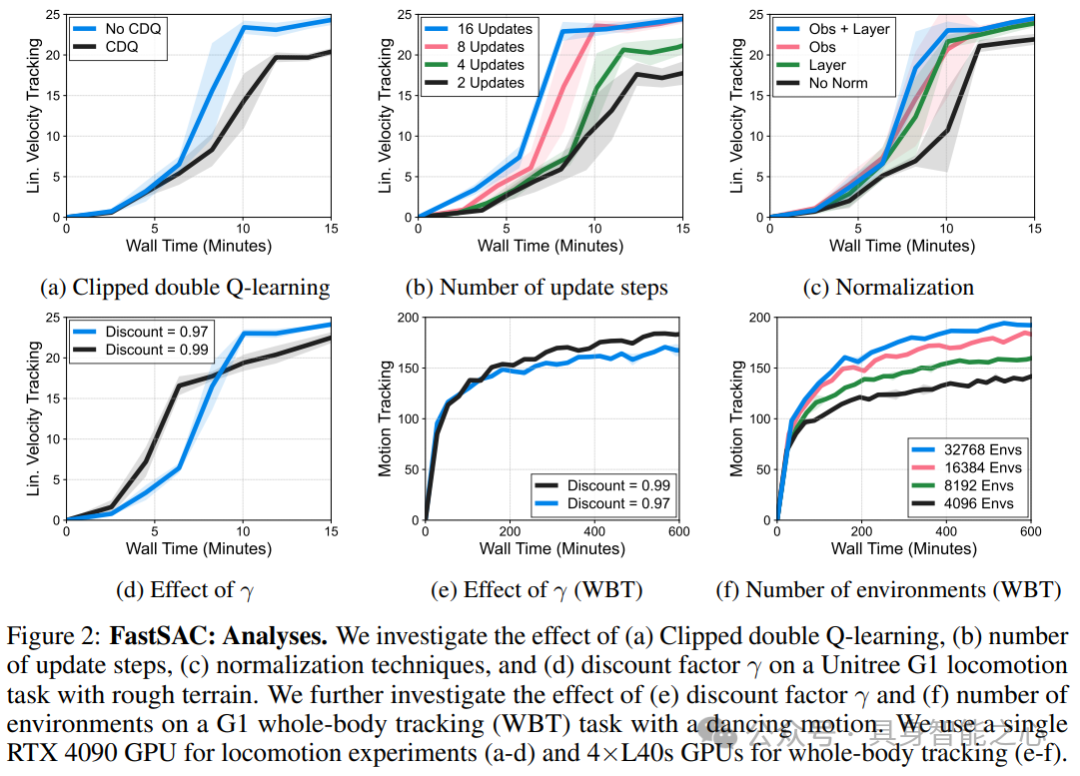
基于 FastSAC(Soft Actor-Critic 优化版)与 FastTD3(TD3 优化版),通过关键技术调优实现高维控制的稳定与高效:
-
关节限制感知动作边界:根据机器人关节极限与默认姿态的差值设定动作边界,替代传统固定边界,减少调参成本,同时避免扭矩不足问题;
-
双重归一化稳定训练:结合观测归一化与层归一化,解决高维任务中的梯度爆炸问题,尤其提升 FastSAC 在复杂场景下的稳定性;
-
critic 网络优化:采用 Q 值平均替代裁剪双 Q 学习(CDQ),避免层归一化与 CDQ 的兼容性冲突,搭配 C51 分布式 critic 提升价值估计精度;
-
探索与优化超参调优:FastSAC 设置最大标准差 1.0、初始温度 0.001,采用自动温度调优;FastTD3 使用混合噪声策略(σ_min=0.01, σ_max=0.05);优化器采用 Adam(学习率 3e-4,权重衰减 0.001,β₂=0.95),适配大规模批次训练。
第二层:奖励设计 —— 极简主义的鲁棒性导向
摒弃冗余奖励条款,设计仅含核心要素的奖励函数(<10 项),兼顾政策鲁棒性与泛化能力:
-
Locomotion(速度追踪)奖励:核心包含线速度 / 角速度追踪奖励(驱动步态生成)、足高追踪奖励(引导摆动动作)、默认姿态惩罚(避免极端关节角)、足部朝向惩罚(防止交叉)、躯干直立惩罚、动作速率惩罚(平滑控制),以及存活奖励(鼓励非摔倒状态); -
全身运动追踪奖励:基于 BeyondMimic 框架,以运动追踪目标为主,辅以轻量化正则化,新增速度推力扰动项提升 sim-to-real 鲁棒性; -
自适应课程学习:随着训练进程逐步提升惩罚项权重,降低探索难度,加速收敛; -
对称性增强:通过对称数据增广鼓励机器人形成自然对称步态,进一步提升训练效率。
第三层:并行仿真 —— 大规模环境的吞吐量提升
依托 GPU 加速仿真框架,通过环境并行化突破训练瓶颈:
-
环境规模伸缩:Locomotion 任务采用单 RTX 4090 GPU,支持数千并行环境;全身运动追踪任务扩展至 4×L40s GPU,并行环境数达 16384,大幅提升数据采集吞吐量; -
强域随机化集成:仿真中融入动力学随机化(质量、摩擦、质心)、PD 增益随机化、动作延迟、崎岖地形、推力扰动(每 1-3 秒一次强扰动)等,确保政策适配真实场景变异; -
数据复用机制:利用离线 RL 算法的核心优势,充分复用历史交互数据,避免在线算法的数据浪费,在同等环境吞吐量下实现更快收敛。
验证逻辑:从定量指标到真实部署的四级性能验证
该方案通过 “Locomotion 训练 - 全身追踪训练 - 消融分析 - 真实硬件部署” 的完整验证体系,充分证明其有效性:
Locomotion 任务:15 分钟实现鲁棒步态

在 Unitree G1(29 自由度)与 Booster T1(29 自由度)机器人上,FastSAC 与 FastTD3 表现突出:
-
训练效率:单 RTX 4090 GPU 仅需 15 分钟即可完成训练,线性速度追踪奖励显著超越 PPO,尤其在强推力扰动、崎岖地形场景下,PPO 难以稳定收敛而 FastSAC/TD3 表现稳健; -
泛化能力:政策能适应平坦 / 崎岖地形、随机动力学参数、频繁推力扰动等多种场景,无需额外微调即可迁移; -
算法对比:FastSAC 凭借最大熵探索机制,在复杂场景下略优于 FastTD3,验证了高效探索对高维控制的价值。
全身运动追踪:复杂动作的快速学习

在舞蹈、搬箱子、推力抵抗等任务中,方案展现出强大的复杂动作学习能力:
-
训练速度:4×L40s GPU 支持下,FastSAC/TD3 训练速度远超 PPO,舞蹈任务(时长超 2 分钟)的运动追踪奖励更快达到收敛阈值; -
sim-to-real 部署:训练后的政策成功部署到真实 Unitree G1 硬件,完成舞蹈、搬箱子、推力抵抗等复杂动作,验证了仿真到现实的迁移鲁棒性。
真实硬件部署:零微调的鲁棒迁移
在真实 Unitree G1 机器人上,仿真训练的政策无需额外微调即可稳定运行:

-
成功复现仿真中的速度追踪步态,在轻微不平坦地面保持稳定; -
全身运动追踪政策能精准执行舞蹈、搬箱子等复杂动作,抵抗环境中的轻微扰动,展现出强鲁棒性。
局限与未来方向
该方案作为快速人形机器人训练的突破性工作,仍存在可拓展空间:
-
复杂地形适配:当前主要验证平坦与崎岖地形,未来可扩展至台阶、斜坡等更复杂地形场景; -
动态障碍物避障:未融入避障逻辑,需结合视觉感知扩展奖励函数,实现感知 - 控制一体化; -
算法融合潜力:可集成最新离线 RL 优化技术(如样本效率提升、探索策略改进),进一步压缩训练时间; -
多机器人适配:当前聚焦双足人形机器人,未来可扩展至四足、多臂等更广泛机器人形态。
总结:快速迭代范式的行业影响
该方案的核心贡献不仅在于 15 分钟训练的效率突破,更在于建立了 “离线 RL 算法 - 极简奖励 - 大规模并行仿真” 的快速迭代范式:通过算法调优解决高维控制稳定性问题,通过极简奖励降低工程复杂度,通过并行仿真提升数据吞吐量。其开源实现(Holosoma 仓库)与硬件部署案例,为机器人研究者提供了开箱即用的快速开发工具,大幅降低人形机器人控制的研发门槛,加速了通用人形机器人从实验室走向真实应用的进程。










