
腾讯微信 AI 团队提出 WeDLM(WeChat Diffusion Language Model),通过在标准因果注意力下实现扩散式解码,在数学推理等任务上实现相比 vLLM 部署的 AR 模型 3 倍以上加速,低熵场景更可达 10 倍以上,同时保持甚至提升生成质量。
引言
自回归(AR)生成是当前大语言模型的主流解码范式,但其逐 token 生成的特性限制了推理效率。扩散语言模型(Diffusion LLMs)通过并行恢复多个 mask token 提供了一种替代方案,然而在实践中,现有扩散模型往往难以在推理速度上超越经过高度优化的 AR 推理引擎(如 vLLM)。
问题的关键在于:大多数扩散语言模型采用双向注意力机制,这与标准的 KV 缓存机制不兼容,导致并行预测的优势无法转化为实际的速度提升。
近日,腾讯微信 AI 团队提出了 WeDLM(WeChat Diffusion Language Model),这是首个在工业级推理引擎(vLLM)优化条件下,推理速度超越同等 AR 模型的扩散语言模型。

论文标题:WeDLM: Reconciling Diffusion Language Models with Standard Causal Attention for Fast Inference
论文作者:刘瑷玮、何明桦、曾少勋、张思钧、张林昊、武楚涵、贾巍、刘源、周霄、周杰(腾讯微信 AI)
项目主页:https://wedlm.github.io
GitHub:https://github.com/tencent/WeDLM
模型权重:https://huggingface.co/collections/tencent/wedlm
以下是模型效果:
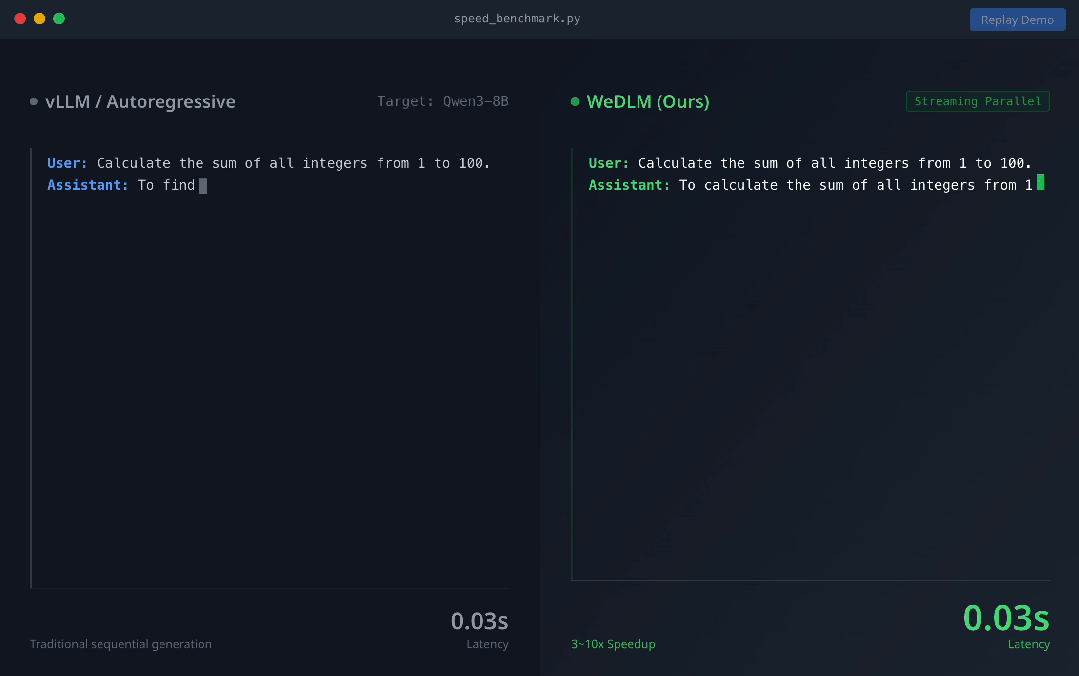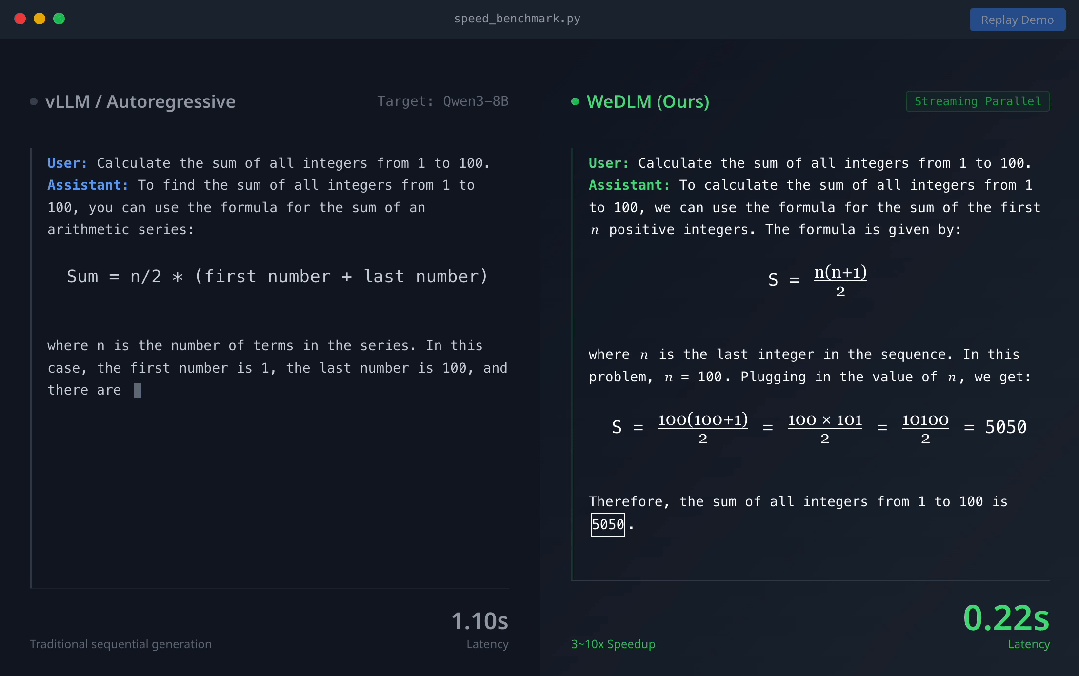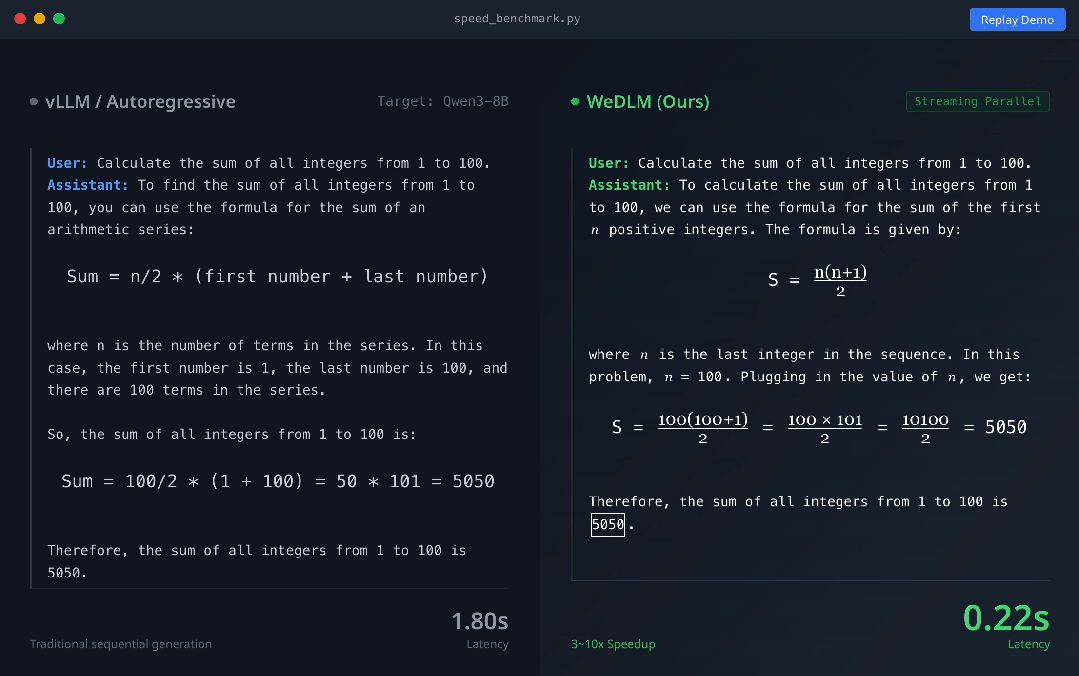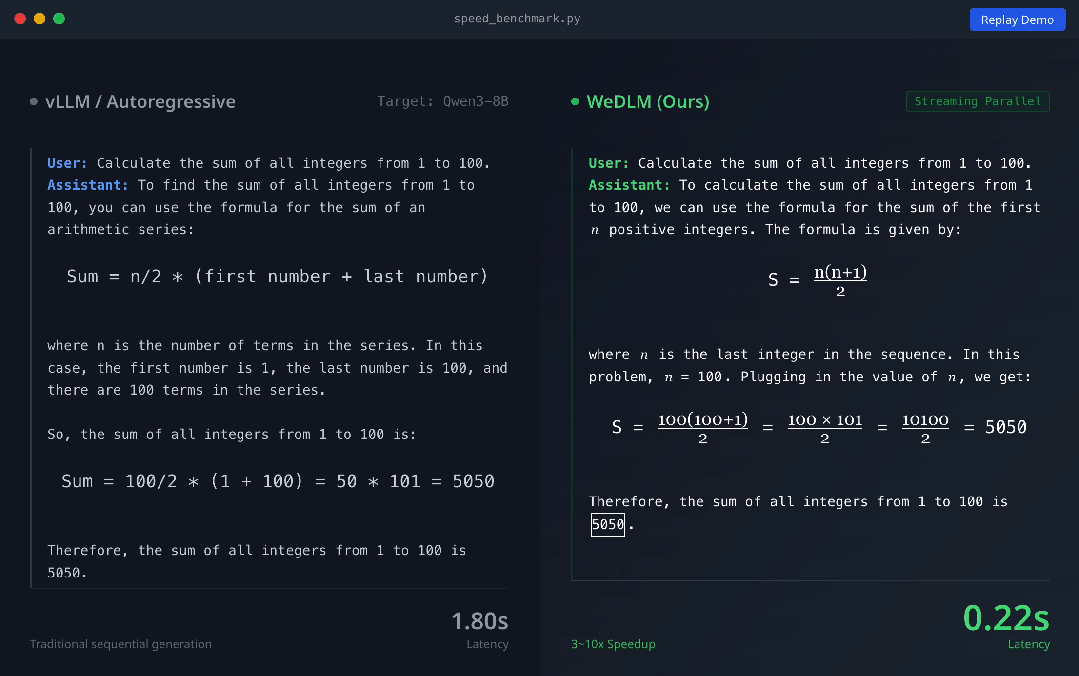
上图展示了vLLM 部署的 Qwen3-8B-Instruct(左) 与 WeDLM-8B-Instruct(右) 在相同 prompt 下的实时生成对比。可以直观看到,WeDLM 的生成速度明显更快。
核心思路:让扩散解码兼容 KV 缓存
WeDLM 的核心洞察是:mask 恢复并不需要双向注意力。扩散式解码只需要让每个 mask 位置能够访问所有已观测的 token,这完全可以在标准因果注意力下实现。
研究团队提出了一个关键指标 —— 前缀可缓存性(Prefix Cacheability):在 KV 缓存解码中,只有形成连续左到右前缀的 token 才能被缓存复用。因此,真正影响推理效率的不是「每步预测多少 token」,而是「有多少预测能够转化为可缓存的前缀」。
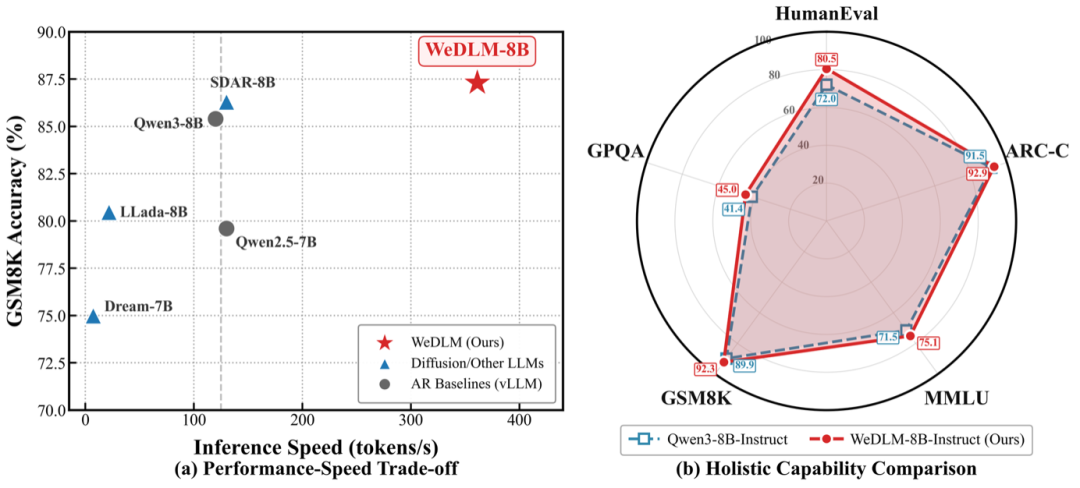
图:WeDLM-8B 在数学推理任务上实现约 3 倍加速,同时在准确率和推理速度上显著超越 LLaDA、Dream 等扩散模型。
技术方案
拓扑重排序(Topological Reordering)
WeDLM 通过拓扑重排序在保持因果注意力的同时,让 mask 位置能够访问完整的观测上下文。具体而言,将所有已观测 token 移动到物理序列的前端,同时通过 RoPE 位置编码保留其逻辑位置。这样,在标准因果 mask 下,每个待预测位置都能看到所有已知信息。
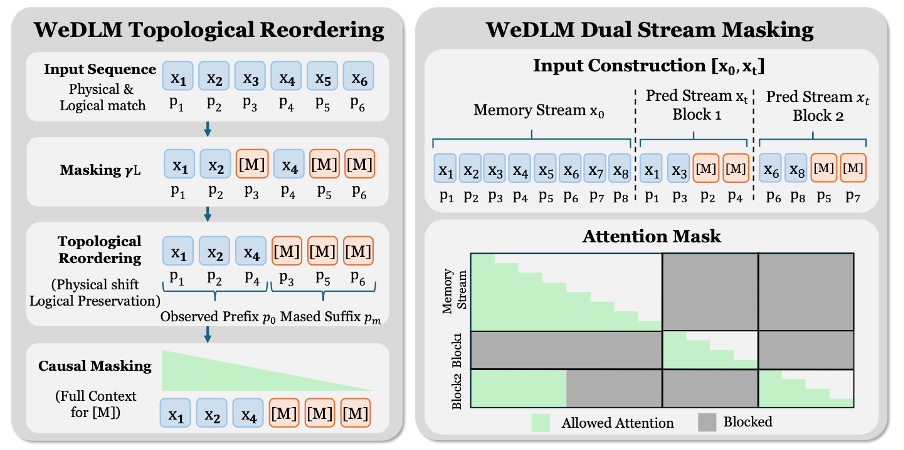
双流掩码(Dual-Stream Masking)
为缩小训练与推理的分布差异,WeDLM 设计了双流训练策略:构建一个干净的「记忆流」和一个带 mask 的「预测流」,两者共享位置编码。预测流中的每个 block 从记忆流获取干净的历史上下文,而非可能带噪的中间预测结果。
流式并行解码(Streaming Parallel Decoding)
推理阶段,WeDLM 采用流式并行解码策略:
距离惩罚机制:优先解码靠左的位置,促进左到右的前缀增长
即时缓存:在因果注意力下,已解码 token 立即成为有效缓存
动态滑动窗口:持续填充新的 mask 位置,避免 block 边界的等待开销

图:传统 block 解码需要等待整个 block 完成才能提交,而 WeDLM 的流式解码可以即时提交已解析的前缀。
实验结果
生成质量
WeDLM 基于 Qwen2.5-7B 和 Qwen3-8B 进行训练,使用 100B token 进行继续预训练,10B token 进行 SFT。

在 base 模型评测中,WeDLM-8B 平均得分 74.72,超越 Qwen3-8B(72.61)2.1 个点。在数学推理任务上提升尤为显著:GSM8K 提升 4.2 个点,MATH 提升 2.8 个点。

在 instruct 模型评测中,WeDLM-8B-Instruct 平均得分 77.53,超越 Qwen3-8B-Instruct(75.12)2.4 个点,也领先于 SDAR-8B-Instruct(74.22)等扩散模型。
推理速度
关键亮点:所有速度对比均基于 vLLM 部署的 AR 模型基线,而非未优化的实现。

研究团队在论文中展示了不同熵值场景下的速度差异:
低熵场景(如计数任务):由于输出高度可预测,模型可以大胆并行预测并接受多个 token,实测达到 1673.3 tokens/s
中熵场景(如数学推导):结构化的推理步骤仍然具有较好的可预测性,实测 745.2 tokens/s
高熵场景(如开放问答):语义多样性高,并行接受率下降,实测 197.8 tokens/s
快速上手
安装方式非常简单,只需通过 pip 从 GitHub 安装即可。安装完成后,可使用 Python API 快速调用模型进行推理。详细的使用文档和示例代码请参见项目 GitHub 主页。
总结
WeDLM 的贡献可以归纳为:
因果扩散框架:在标准因果注意力下实现 mask 恢复,天然兼容 KV 缓存和现有推理基础设施(FlashAttention、PagedAttention、CUDA Graphs 等)
流式并行解码:通过距离惩罚和动态滑动窗口,最大化前缀提交率
首次在速度上超越工业级推理引擎部署的 AR 模型:在 vLLM 优化条件下的公平对比中,数学推理实现 3 倍以上加速,低熵场景超过 10 倍
研究团队指出,这项工作表明「前缀可缓存性」应当作为并行文本生成的一等设计目标。未来的扩散语言模型应更多地被视为高效的多 token 预测机制 —— 并行生成 token 的价值,取决于这些 token 能多快地转化为可缓存的前缀。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










