随着RISC-V架构在高性能计算与边缘智能领域的快速崛起,构建高效、可靠的AI软件栈成为RISC-V高性能生态发展的核心命题。虽然GPU和专用NPU承担了模型推理的主要算力,CPU依然是AI工作流中不可或缺的“粘合剂”——负责数据预处理、后处理、批量调度、轻量推理以及与系统其他组件的协同。若CPU侧性能优化不足,极易成为整个AI工作流的瓶颈。
在此背景下,中国科学院软件研究所智能软件研究中心工程师张飞和实习生夏卓昭围绕PyTorch-CPU(简称Torch-CPU)在RISC-V平台上实现全栈支持与深度优化,从“基础可用→原生加速→上游贡献”的三阶段技术路径,形成了完整的RISC-V Torch-CPU解决方案。该方案不仅确保在RISC-V CPU侧能“跑通”AI模型,更使其具备“高效执行”AI计算的能力,为RISC-V在边缘AI、端侧智能等场景的落地奠定坚实基础。
PyTorch作为全球最广泛使用的深度学习框架之一,其对 RISC-V的原生支持是吸引开发者、模型和工具链的关键前提。随着张飞向PyTorch上游社区提交及合并三个关键支持PR,完成了Torch-CPU对RISC-V架构的初始支持。
⚙️ 应用场景
-
支撑CI/CD流水线中的编译验证 -
为后续向量化加速和库集成提供可靠基座
💡 核心挑战与技术突破
- 构建系统适配:
深入PyTorch构建流程,解决三方库依赖编译问题,如优化Sleef库交叉编译构建方式(Sleef PR: )。 - CI体系从零构建:
针对RISC-V硬件稀缺现状,设计“交叉编译 + QEMU仿真”标准化流程,保障代码长期可维护性。(PyTorch PR: #143979) -
社区协作机制建立:推动上游社区接受RISC-V为正式支持架构,为后续贡献铺平道路。(PyTorch RFC: )

PyTorch RISC-V CI
流程图
在基础运行能力之上,亟需面向RISC-V向量扩展(RVV)的原生加速路径。由于上游PyTorch尚未接纳补丁(PyTorch PR:),软件所与蓝芯算力合作,在如意开源社区维护一套独立但兼容的VEC(Vector Execution Core)后端,实现对关键算子的RVV 优化。
⚙️ 应用场景
-
在支持RVV 1.0的RISC-V芯片上运行轻量级CNN、Transformer推理
-
作为AI工作流中CPU侧计算的补充加速方案
-
为国产RISC-V芯片厂商(如蓝芯算力)提供可集成的高性能CPU侧推理后端
💡 核心挑战与技术突破
-
自研VEC后端架构:在不修改PyTorch主干的前提下,通过ATen算子注册机制注入RVV优化内核。
-
RVV Intrinsics高效实现:基于RVV指令集手动编写向量化算子,提升数学、内存操作、量化等函数的性能。
-
社区隔离与协同:因上游暂未接纳该后端,我们在如意社区独立维护代码,同时保持与RISE协作开发,便于未来合并。
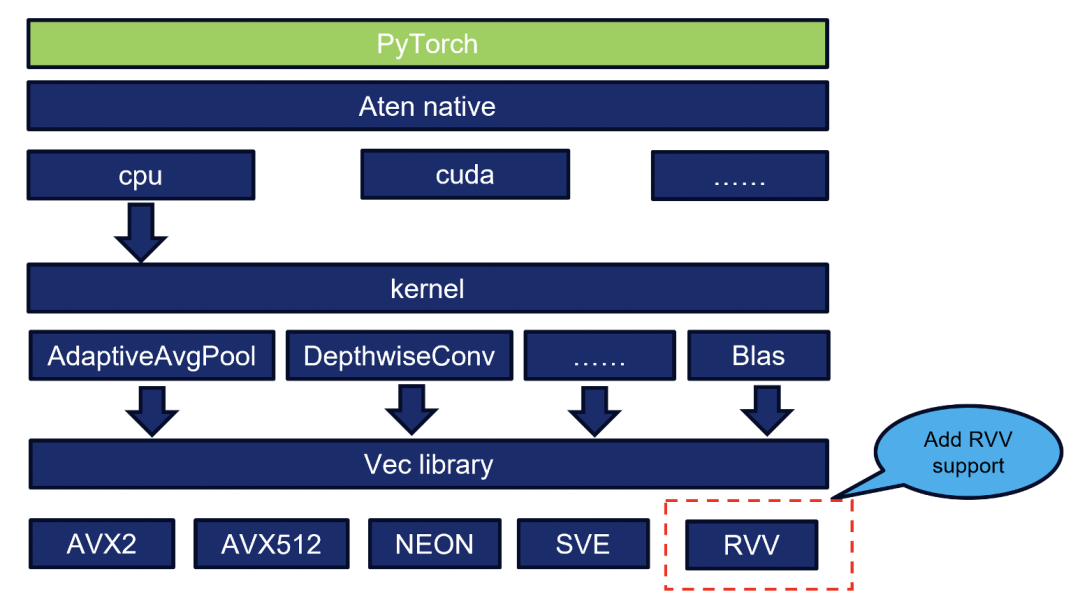
PyTorch VEC架构图
为实现跨平台、可复用、社区共建的高性能AI软件栈,软件所团队通过将RISC-V支持并入Intel主导的oneDNN项目,并成功在PyTorch上游启用该后端,实现了“工业级”的性能表现,并与算能科技在SG2044服务器上合作验证。张飞因此被推荐为oneDNN项目RISC-V架构的Code Owner,持续在该国际开源社区推进RISC-V架构优化工作。
⚙️ 应用场景
-
在支持RVV的通用RISC-V服务器(如算能SG2044)或边缘设备上部署工业级AI模型。
-
与ONNX Runtime、OpenVINO等其他oneDNN用户共享优化成果。
-
作为PyTorch 官方推荐的CPU加速路径,适用于各类生产环境。
💡 核心挑战与技术突破
-
启用oneDNN后端支持:修改PyTorch构建系统,使其在RISC-V上可启用oneDNN算子调度(PyTorch PR )。
-
RVV算子深度优化:基于oneDNN的Dispatch机制,重写Reorder、GEMM、Convolution等核心kernel,使用RVV intrinsics实现高性能向量化。优化算子包括:
-
Reorder(FP32→INT8重排)
-
GEMM
-
Convolution
-
Deconvolution
-
NCHW Pooling
-
Group Normalization
-
CI与测试覆盖:新增针对VLEN=128/256的QEMU仿真测试,确保功能正确性与向后兼容。
-
上游贡献:累计提交20+PR,合并代码超5000行,使oneDNN对RISC-V的支持从“实验性”迈向“工程可用”。

Intel oneAPI OneDNN高性能库支持的AI框架
📈 实验验证与性能评估
-
验证平台:算能SG2044(riscv64,支持RVV 1.0,128-bit向量寄存器)
在上述软硬件环境下,软件所团队对PyTorch api、oneDNN优化算子、神经网络模型进行了性能评估,关键结果如下:
1.PyTorch api加速性能对比
在引入RVV优化的VEC库后端后,PyTorch中多个核心张量操作的执行效率显著提升。如下图所示,所有测试算子在优化后均实现了不同程度的加速,其中二元逐元素运算(如torch.mul、torch.div)及部分数学函数(如torch.pow、torch.abs)表现出尤为突出的性能增益,加速比分别达到4.8×、5.1×、4.3×和4.4×。整体而言,实验结果验证了VEC RVV后端在提升PyTorch api执行效率方面的有效性,为RISC-V架构在深度学习框架中的部署提供了有力支持。

PyTorch api加速对比图
2. oneDNN算子加速性能对比
如下图所示,以下数据展示了RVV优化相对于通用实现的加速效果:

oneDNN算子加速对比图
从测试结果可以看出,RVV优化在多个算子操作上都取得了显著的性能提升:
-
Reorder:性能提升约21倍
-
Gemm:性能提升约9.5倍
-
Convolution:性能提升约8.4倍
-
Deconvolution:性能提升约1.6倍
-
NCHW Pooling:性能提升约1.4倍
-
Group Norm:性能提升约1.6倍
3. 神经网络模型加速对比
在基于PyTorch框架并采用oneDNN作为后端加速库的实验环境下,我们对多种主流轻量级与经典卷积神经网络模型(包括MobileNetV2、MobileNetV3-Large、VGG16、EfficientNet-B0和ShuffleNetV2)在RISC-V架构上的推理延迟进行了系统性评测,如下图所示:
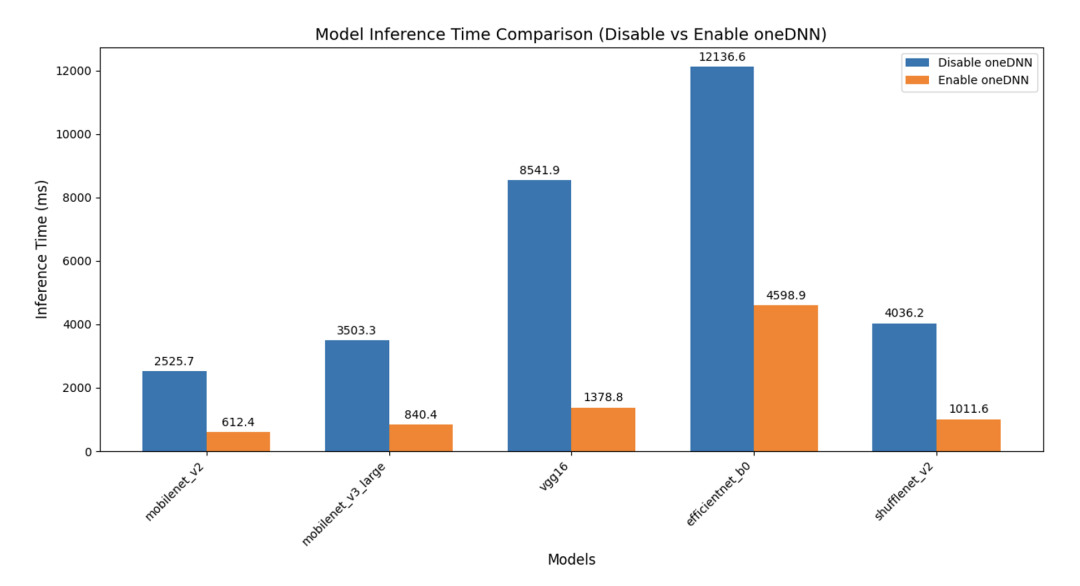
神经网络模型加速效果对比图
从测试结果可以看出,PyTorch在以oneDNN为后端在多个神经网络模型上取得了显著的性能提升:
-
mobilenet_v2:性能提升约4.12倍
-
mobilenet_v3_large:性能提升约4.17倍
-
vgg16:性能提升约6.19倍
-
efficientnet_b0:性能提升约2.64倍
-
shufflenet_v2:性能提升约3.99倍
4. 与ARM对比
同样的,对 RISC-V(算能SG2044服务器)与ARM架构(泰山服务器搭载鲲鹏920处理器)在启用与禁用oneDNN后端情况下的典型神经网络模型推理性能进行了系统性对比,如下图所示:

RISC-V与ARM推理时间对比图
实验结果表明,无论在哪种架构上,PyTorch在启用oneDNN后端后均能显著加速模型推理过程,验证了高性能计算库对通用CPU平台推理效率的关键作用。尽管RISC-V在禁用oneDNN时普遍表现出较ARM更长的推理延迟,但在启用oneDNN后,两者性能差距显著缩小,RISC-V平台上的推理时间仅高出ARM平台约9%至39%,部分模型(如VGG16)甚至接近持平,表明优化后的软件栈可在一定程度上弥补RISC-V当前硬件生态尚不成熟的劣势。oneDNN的引入对提升RISC-V平台深度学习推理能力具有重要意义,不仅大幅缩小了其与成熟ARM生态的性能鸿沟,也为RISC-V在边缘AI场景中的实际部署提供了可行性支撑。
在当前以GPU/NPU为中心的AI算力架构中,Torch-CPU并非主力计算单元,却是服务闭环的关键环节。无论是图像解码、数据归一化、非极大值抑制(NMS),还是批量请求调度、结果后处理,都高度依赖CPU的高效执行。若CPU侧存在性能瓶颈,将直接拖累整体吞吐与延迟。
本工作通过三大技术路径——基础支持、原生加速、上游贡献——系统性解决了RISC-V平台上Torch-CPU “能跑、快跑、稳跑”的问题,不仅填补了生态空白,更展示了软件栈深度优化对新兴架构的赋能价值。未来,我们将继续推进zvfh半精度支持、算子融合、图优化等方向,助力RISC-V成为AI时代真正开放、高效、自主的计算底座。
携手共筑如意RISC-V软件生态
如意RISC-V软件生态是一个开放、透明、可持续发展的生态共建蓝图,能让每一位开发者和生态伙伴,清晰洞察当前RISC-V软件技术的布局与适配进展,共同参与、协力推动软件生态的繁荣与演进。
如果您对完善和共建如意RISC-V软件生态感兴趣,欢迎交流联系,我们期待与您共同探讨关于RISC-V的软件适配优化和应用解决方案。
生态主页:https://openruyi.cn/software/ecosystem
如意RISC-V高性能软件生态负责人:于佳耕,中国科学院软件研究所智能软件研究中心,正高级工程师,联系方式:jiageng08@iscas.ac.cn。
来源:如意社区










