MVGGT团队 投稿
量子位 | 公众号 QbitAI
试想一下,如果你在一个未曾去过的杂乱房间,你只能快速地看三次房间里的布置,接下来就要求你去定位墙角的一张木桌子。
这就是具身智能体目前所面对的真实处境。在真实世界里,机器人缺少上帝视角,获得的往往只有几张稀疏、破碎的RGB照片。
面对这一难题,现有的3D指代分割方法往往难以奏效。
于是,来自厦门大学、上海创智学院、复旦大学、字节跳动等机构的研究团队提出了一种全新的解决方案——MVGGT。
该工作根据上述问题定义了更符合需求的MV-3DRES任务,并且通过几何和语言双分支Transformer架构和创新的PVSO优化策略,实现了在稀疏多视角下对3D场景的高效理解和精确分割。



从理想点云到现实稀疏视角
三维指代表达分割(3DRES)是具身智能领域的一个重要任务,要求模型根据文本描述分割出三维场景中的目标对象。
尽管近年来的方法已经取得了显著成果,但他们都基于理想化假设:能够获取到密集、完整且可靠的点云输入。
而真实世界的智能体的感知,仅能通过少量随机拍摄的RGB图片来实现。而由这种稀疏的多视图图片生成的三维重建结果往往存在噪声而且是不完整的、模糊的。
于是引发了核心问题:当必须从稀疏、不一致的视图中推理时,该如何实现基于语言的三维感知?
为了解决上述问题,研究团队定义了一个贴近实际应用的新任务——多视图3D指代分割(MV-3DRES),即要求模型模型在没有稠密点云作为输入的情况下,直接利用稀疏的多视角RGB视图和文本指令,联合重建场景并分割被指代对象。
MVGGT——几何与语言的深度交融
针对稀疏视角下的感知难题,论文提出了一种端到端的双分支架构:Multimodal Visual Geometry Grounded Transformer(MVGGT)。
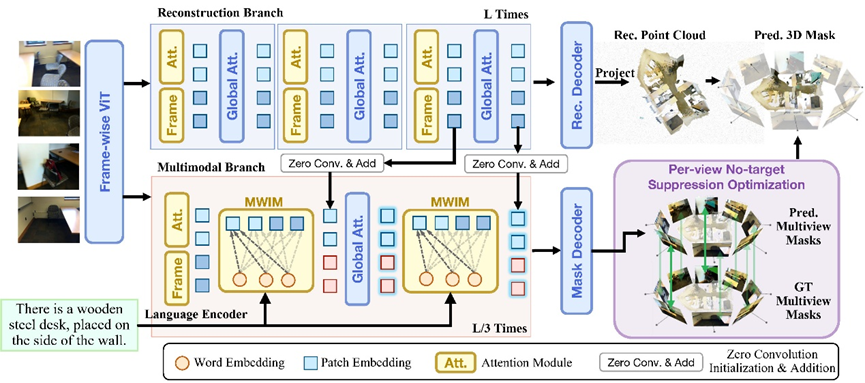
MVGGT的架构如上图所示,采用互补的双分支范式:
冻结的几何重建分支(Reconstruction Branch)
该分支以预训练的几何模型(Pi3)为基础,提供三维几何先验信息(相机位姿、深度图、粗糙点云结构)。
关键在于,该分支中的所有参数保持冻结,保证了训练过程中几何特征的稳定性,并消除了从稀疏图像中重新学习3D几何的需要。
可训练多模态分支(Multimodal Branch)
该分支接收几何特征,并利用交叉注意力机制将语言指令注入到视觉特征中。
简单来说,就是利用文本里的语义信息来辅助视觉判断,在画面不完整的时候,引导模型推断出正确的空间位置。
核心优化障碍:PVSO策略
但是,稀疏的多视图学习会带来一个棘手的优化挑战。
目标实例往往仅有极少数分散的点来表示,这远少于传统的3DRES方法中所使用的密集点云。
在这种较为极端的情况下,硬用Dice Loss这种标准损失函数是行不通的—前景的梯度信号极其微弱,容易被背景信号淹没,使得模型难以收敛。
这也就是研究团队在训练过程中发现的核心优化障碍:前景梯度稀释(Foreground Gradient Dilution,FGD)。
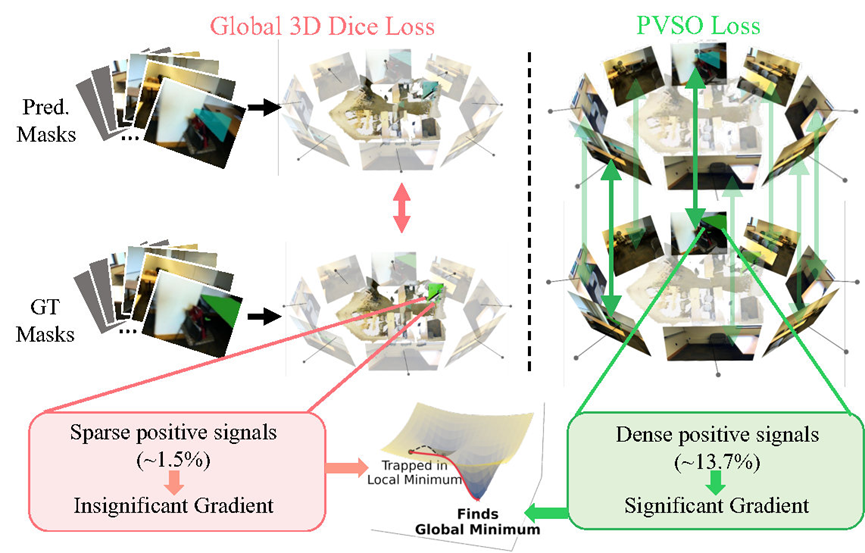
于是,研究团队引入了逐视图无目标抑制优化方法(PVSO):
2D梯度集中:将3D预测结果投影回2D图像空间。在2D视图中,目标占据的区域更大且更可靠,远高于3D空间,从而能够放大目标区域的梯度信号。
无目标视图的抑制:由于在稀疏视角中存在大量无目标视图(No-target views),PVSO引入了加权抑制机制,放大来自有效视图的有意义梯度,同时抑制来自无目标视图的误导性信号,有效防止了训练过程中的梯度偏差。
实验结果
为了填补评估标准的空白,研究团队构建了首个为多视图三维指代表达分割(MV-3DRES)定义设置、指标和数据协议的基准测试集——MVRefer。
该基准基于经典的ScanRefer和ScanNet数据集构建,模拟了在场景中随机采集8个稀疏视角的情况。
实验结果显示,MVGGT在各项指标上均显著优于现有的基线方法(如2D-Lift和Two-stage方法):
在MVRefer基准上,MVGGT在各项关键指标上均大幅领先于现有基线(如图中的2D-Lift和Two-stage方法)。在目标像素占比极低的困难(Hard)模式下,MVGGT依然保持了较高的分割精度,展现了极强的鲁棒性。

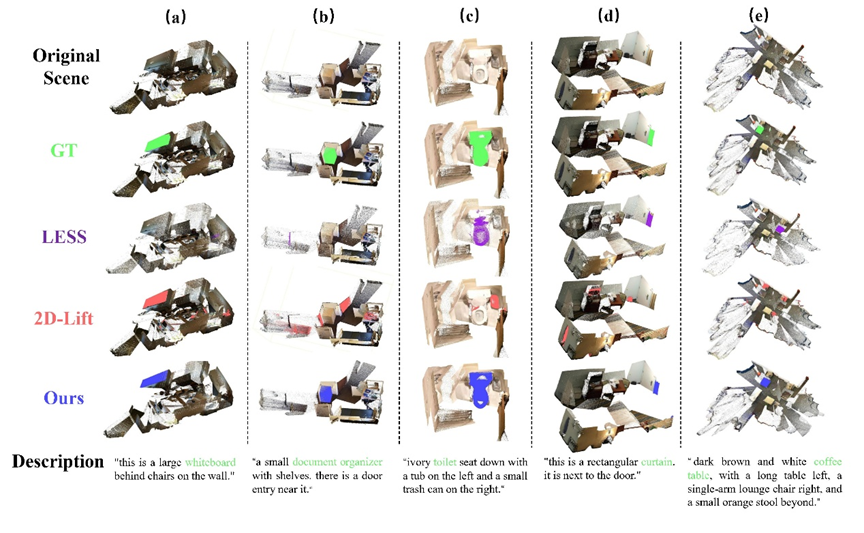
可视化结果进一步证明了模型的优势:
在深度噪声严重或遮挡复杂的场景中,基线方法往往会跟丢目标。
而MVGGT借助多模态语义的导航,往往能精准区分“墙面上的白板”等几何特征相似的目标。即使目标被杂物遮挡,它也能利用上下文信息实现精准定位目标实例。

总结
这项工作具有重要的实践意义,它提出了多视图三维指代表达分割(MV-3DRES)这一新任务设置,使三维接地与真实感知条件对齐,并提出了MVGGT和优化策略,实现了在没有稠密点云输入的情况下高质量的3D指代表达分割。这为具身智能在受限环境下的感知能力提供了新的思路与方向。
最后,研究团队诚挚邀请大家基于此基准进行测试与改进,共同探索稀疏感知在具身智能中的更多可能性,推动该领域向更高效、更通用的方向发展。
作者介绍
本论文共同第一作者为厦门大学与上海创智学院联合培养博士生吴昌鲡、厦门大学本科生王浩东,厦门大学博士后研究员纪家沂参与本研究,通讯作者为厦门大学多媒体可信感知与高效计算教育部重点实验室曹刘娟教授。该研究团队长期深耕3D视觉、多模态学习领域。










