
OpenAtom openEuler(简称“openEuler”或“开源欧拉”)作为全场景的开源操作系统,是连接底层异构硬件和上层应用的桥梁。面对通智算融合负载(大数据,生成式推荐,AI训推等)日益增长的算力需求,openEuler的核心任务之一是融合异构(CPU+XPU)算力,保障负载所需资源最优分配,同时实现资源可靠供应,降低故障造成的资源开销。
随着大语言模型(Large Language Model, LLM)的模型参数和训练数据量的持续增长,LLM训练所需的硬件规模显著扩大,导致设备故障的概率显著增加。例如,LLaMA3.1在使用 16,000 个GPU训练405B参数模型时,54天内遭遇了419次意外中断;DeepSeek的Fire-Flyer AI-HPC集群在一年内总共遭遇了12,970 次GPU错误。这些数据表明,如何有效应对软硬件故障引发的算力浪费已成为亟需解决的关键技术问题。
为应对这一问题,主流的LLM训练故障恢复技术依赖于周期性检查点机制。这类方法需要频繁保存模型状态,增加了额外的I/O开销,显著拖慢了训练进程。其次,在恢复过程中,由于需要重放多轮历史迭代数据,大量计算资源被重复消耗。
本文介绍XPU迁移框架XMIG,旨在解决XPU资源迁移与故障快速恢复问题,提高计算资源利用率。XMIG 采用即时检查点(Just-in-Time Checkpointing,JIT)技术,利用数据并行特性实现快速恢复,降低了周期性保存检查点的开销,并限制了最多重放一个mini-batch,减少资源浪费。此外,针对集合通信恢复过程,XMIG提出集合通信局部重建链技术,避免通信后端全局重建,降低XPU恢复时延。
如下图所示,XMIG采用client-server架构,client托管 CPU侧训练进程,发起XPU调用;server执行XPU调用请求,负责集合通信快速恢复重建链。
XMIG 核心特点如下:

图1:XMIG整体框架
1.快速故障恢复:XMIG采用及时检查点技术,无需周期性保存检查点,大幅缩短了故障后的重启和环境重建时间(设备代理组件)。
2.应用透明性:XMIG对上层训练框架(如PyTorch、Megatron 等)透明。开发者无需训练框架代码,XMIG能够自动拦截错误并静默完成恢复,实现训练框架无感知的容错(设备代理组件)。
3.支持运行时调整通信组:CCL局部重建链提供灵活的集合通信组成员调整功能,适应动态训练需求(Flexible CCL 组件)。
为了解决传统LLM训练中XPU故障导致整个进程崩溃并丢失状态的痛点,XMIG通过“设备代理”组件,解耦训练进程的CPU与XPU上下文,确保了XPU故障不会被上层框架感知,从而实现透明的故障恢复。设备代理采用“客户端-服务器”的双进程架构。训练框架运行在客户端进程中,而所有的XPU资源(如显存、XPU 对象)则由独立的服务器进程托管。
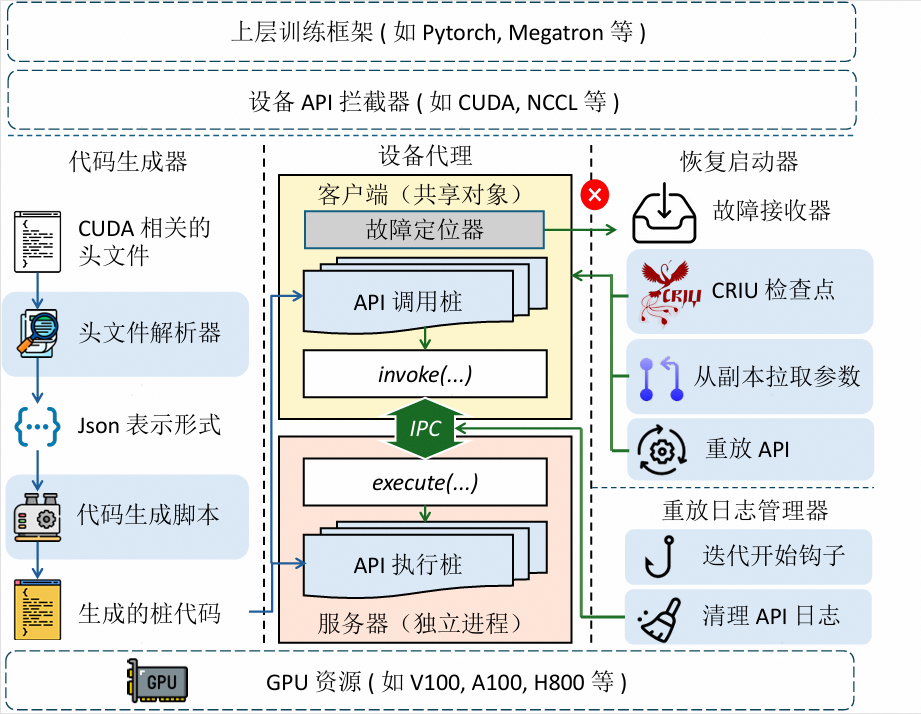
图2:XMIG设备代理架构
以GPU训练为例,为了实现对上层框架的完全透明,设备代理必须拦截所有的GPU相关API调用。在正常训练期间,API调用指令及其执行结果被直接写入IPC共享缓冲区,同时该缓冲区用作重放日志记录。此外,设备代理为上层框架维护了一套“逻辑句柄”,而将底层的“物理句柄”隐藏在服务器进程中。即使GPU状态在故障后重新初始化,上层框架看到的逻辑句柄始终保持一致。这套句柄映射基于线性表实现,能以极快速度实现O(1) 时间复杂度的访问与更新操作。
设备代理执行恢复时,其技术核心在于显存托管支持下的状态重构与指令重放:代理利用显存托管将原本离散的模型状态整合为连续物理地址,从而在恢复阶段能以“大块传输”极速从DP副本拉取状态;随后,代理通过重放日志中记录的API指令,将GPU环境精确推回到故障前的一刻,配合逻辑句柄的一致性映射,实现了无需重启进程的即时无缝续接。
为了解决传统通信后端(如NCCL)因无法在运行期间修改通信组而必须全局重启的难题,XMIG提出集合通信局部重建技术 Flexible CCL,支持通信成员动态调整,当特定XPU发生故障时,该技术允许受影响的通信组在不关闭进程的情况下实现快速重新初始化,并能根据节点健康状况动态增减参与通信的成员,从而确保训练任务在硬件变动时仍能保持通信拓扑的完整性。
Flexible CCL通过持久化保存已构建的引导网络(Bootstrap Network)状态、拓扑探测结果及计算好的图信息,规避了原生NCCL在重连时繁琐的全局握手与拓扑搜索过程。这种机制使得故障节点在重启后能利用缓存信息瞬间恢复通信能力,显著降低了恢复延迟。

图3:Flexible CCL局部重建链
此外Flexible CCL能够根据每个Rank的原始状态在不同作用域内执行初始化操作,从而支持在运行时透明地剔除故障节点或加入备份节点。这一机制通过最小化数据交换量来优化调整过程,例如在增加新Rank时,只需由一个现有Rank提供集群信息,而非进行全量的全局数据交换,这确保了在大规模并行LLM训练场景下,即使通信成员发生变动,各梯度聚合操作仍能正确续接,保障了训练的持续性。
XMIG核心代码已经开源:
●AtomGit 仓库:
https://atomgit.com/openeuler/xmig
●Github 仓库:
https://github.com/Networked-System-and-Security-Group/Mnemosyne
●Paper:
Mnemosyne: Lightweight and Fast Error Recovery for LLM Training in a Just-In-Time Manner
本文围绕AI训练过程故障恢复问题,介绍了XPU迁移框架 XMIG设计思路与核心机制,XMIG不仅可以在故障恢复场景降低资源浪费减少恢复时间,还可以在主动任务迁移场景发挥作用,通过将分散任务迁移到同一节点上,实现资源整合,提高资源利用率。
当前XMIG完成基本的功能设计开发和验证,后续针对不同的迁移场景(如跨节点迁移)还需要进一步补齐,同时探索不同训练框架、训练类型下的故障快速恢复与XPU状态迁移,保障上层业务和负载和高效运行。










