
作者丨Zhixian Xie
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
>>
更多干货,欢迎加入国内首个具身智能全栈学习社区:(戳我),这里包含所有你想要的。
在接触密集型灵巧操作领域,机器人要像人类一样精准应对不同形状物体、稳定完成长时域任务,始终面临着数据需求大、虚实迁移难、泛化能力弱的三重挑战。现有端到端策略要么在复杂接触动力学中 “学不透”,要么在陌生物体几何面前 “水土不服”。而亚利桑那州立大学等团队提出的分层 RL-MPC 框架,灵感源自人类分层操作逻辑——先决策 “接触哪里、物体去哪”,再解决 “如何接触”,通过创新的 “接触意图” 接口,让高层强化学习(RL)专注几何与运动学推理,低层模型预测控制(MPC)专攻接触动力学执行,最终实现近 100% 任务成功率、10 倍数据效率提升与零样本虚实迁移,为几何感知型灵巧操作开辟了新路径。

痛点直击:传统灵巧操作方案的 “三大困境”
当前机器人灵巧操作技术始终难以平衡 “学习效率”“鲁棒性” 与 “泛化性”,核心问题集中在三点:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
这些方案忽略了灵巧操作的本质:几何-运动学推理(高层决策)与接触动力学推理(低层执行)的天然分离性。人类操作时从不会直接从视觉感知跳到手指关节控制,而是先明确 “接触哪里、要达成什么中间目标”,再通过物理直觉调整动作。分层 RL-MPC 框架正是复刻了这一逻辑,通过结构化设计破解传统方案的固有缺陷。
核心创新:“接触意图” 如何串联起分层推理?
框架的灵魂在于 “接触意图”(Contact Intention)—— 一个将高层决策具象化的中间接口,它像一座桥梁,让 RL 与 MPC 各司其职又紧密协同,具体设计可拆解为 “三层逻辑 + 两大模块”,每一处细节都为解决特定问题而生:

接触意图:定义 “接触哪里、去向何方” 的精准接口
接触意图是高层 RL 的输出,也是低层 MPC 的输入,是整个框架的 “沟通语言”,其数学定义为:
其中,:物体表面的接触位置集合,n为机器人主动接触点数量(如单杆末端执行器n=1,四指手n=4)。这些位置并非随机选择,而是从物体点云下采样的关键点中筛选,确保与物体几何形状精准适配;
:接触后的物体子目标姿态,属于SE(3)空间(包含位置与姿态信息)。它并非最终目标,而是朝向终点的关键中间态——比如推动字母 “L” 时,先将其短边对齐目标方向,再推进至指定位置,这种分步设计大幅降低了长时域任务的学习难度。
这一设计的精妙之处在于:将抽象的操作决策转化为 “接触位置 + 子目标姿态” 的结构化信息,让 RL 无需纠缠于复杂的接触力计算(如滑动摩擦、碰撞反弹等),MPC 也无需猜测高层意图,层级协同效率大幅提升。
高层 RL 策略:几何与运动学的 “决策大脑”
高层 RL 的核心任务是基于场景观测预测接触意图,即实现映射(为观测,为接触意图)。为实现高效学习与跨几何泛化,其设计暗藏三大巧思,每一处都经过精心优化:

(1)三组件观测空间:让策略充分感知环境
观测空间采用 “几何 + 目标 + 碰撞” 的设计,所有信息均基于物体坐标系构建,避免世界坐标系带来的额外学习负担:
-
几何组件:从物体点云均匀下采样N个关键点(字母类物体采样于垂直侧面,立方体采样于六个表面)。这些关键点既近似物体几何,又作为接触位置的离散候选集,实现 “形状表示” 与 “接触选择” 的统一; -
目标组件:定义物体坐标系下的关键点目标流,其中是关键点在目标姿态下的位置(转换到当前物体坐标系)。这一设计让策略直接感知 “每个点需要移动多少”,无需额外学习坐标系转换; -
碰撞组件:计算每个关键点到环境(地面、墙壁等)的最小欧氏距离。当≈0时(如立方体底面关键点),标记为无效接触位置,避免策略选择物理上不可行的接触点。
观测空间的数学表达为:,确保策略在统一语境下进行几何-运动学推理。
(2)MPC 权重间接定义子目标:平衡灵活性与学习效率
直接预测SE(3)空间的子目标姿态对 RL 来说探索难度极大,因此框架采用 “预测 MPC 权重” 的间接方式:
其中(位置权重)选自集合{0,50,100,150,200},(姿态权重)选自{0,2,4,6,8}。不同权重组合对应不同的子目标侧重:
-
当=(200,0)时,子目标仅关注位置精度(如推箱任务初期调整物体位置); -
当=(0,8)时,子目标仅优化姿态(如 3D 重定向任务中调整立方体朝向); -
当=(100,4)时,位置与姿态兼顾(如任务后期精准对齐目标)。
这种设计让 RL 无需直接探索高维姿态空间,而是通过离散权重组合实现子目标的灵活切换,学习效率大幅提升。
(3)双分支网络架构:兼顾局部细节与全局上下文
策略网络采用 “几何分支 + 全局运动学分支” 的双分支设计,基于 PointNet++ 实现特征提取:
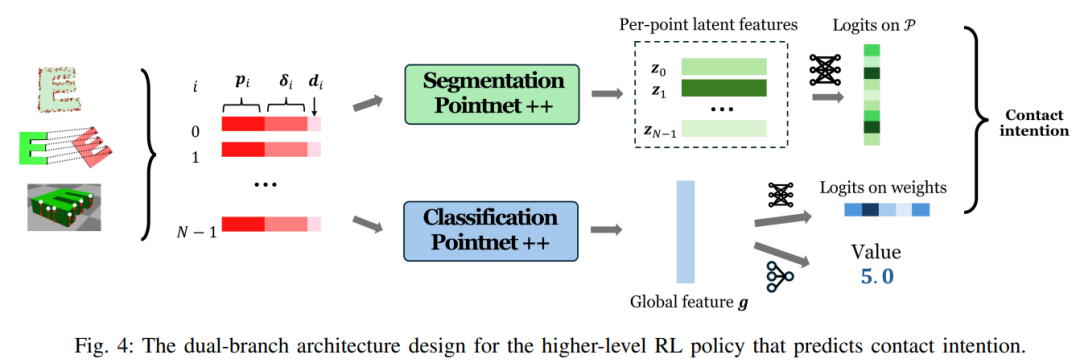
-
几何分支(分割型 PointNet++):对每个关键点的局部特征(位置、目标流、碰撞距离)进行处理,输出每个关键点作为接触位置的概率分布,专注 “微观接触选择”; -
全局运动学分支(分类型 PointNet++):将所有关键点特征聚合为全局物体嵌入,预测 MPC 权重组合与价值估计,专注 “宏观任务规划”。
网络训练采用 PPO 算法, reward 函数设计兼顾任务进度与接触可行性:
其中:
-
:稠密奖励,鼓励物体向目标姿态移动; -
:稀疏奖励,仅在物体达成最终目标时触发; -
(无效接触位置)或0(有效接触位置):惩罚无效接触选择。
低层 MPC 执行:接触动力学的 “高效引擎”
低层采用ComFree-MPC(互补自由模型预测控制),以 100Hz 高频重规划,确保接触动作的稳定性与适应性。其核心设计围绕 “精准执行接触意图” 展开:
(1)互补自由接触建模:兼顾速度与精度
采用准动态互补自由接触模型,无需求解复杂的互补约束(传统接触建模的核心难点),就能精准捕捉滚动、滑动、分离等接触模式:
其中:
-
:质量矩阵,为物体惯性,为机器人刚度; -
:驱动力向量,(u为末端执行器位移,为刚度系数); -
:接触力向量,通过弹簧-阻尼模型生成,自动适配不同接触模式。
该模型的优势在于计算速度快(满足 100Hz 重规划需求),同时物理精度足够支撑复杂接触交互。
(2)目标对齐优化:严格遵循高层意图
MPC 的优化目标分为运行成本与终端成本,双重保障接触意图的实现:
-
运行成本:,鼓励末端执行器贴近 RL 预测的接触位置(为物体坐标系到世界坐标系的变换矩阵,为权重系数); -
终端成本:,驱动物体在预测时域H=3步内达成子目标姿态。
优化求解后,仅将第一个控制输入发送给机器人,后续步骤随状态更新重新规划,确保对扰动的快速响应。
协同机制:多速率闭环让决策与执行 “无缝衔接”
框架采用 “慢决策、快执行” 的多速率耦合模式,具体工作流程如下:
高层 RL 每T=20个环境步(对应 0.2 秒)接收一次观测,预测接触意图;
低层 MPC 在每个环境步(100Hz,0.01 秒 / 步)基于当前系统状态与固定的,求解优化问题,输出末端执行器位移;
机器人通过操作空间控制器(OSC,500Hz)将转换为关节扭矩指令,执行接触动作;
当物体达成子目标姿态或T步结束后,高层 RL 基于新的观测更新接触意图,形成 “决策-执行-反馈” 的闭环。
这种机制既保证了高层决策的全局最优性,又通过低层高频重规划抵消扰动与建模误差,让操作在模拟与真实环境中都能保持稳定。
实验验证:在非抓握任务中 “大显身手”
框架在两大代表性非抓握任务中接受全面检验 ——几何泛化推箱(12 个字母形状物体,6 个训练、6 个未见过)和物体 3D 重定向(立方体随机初始姿态到目标姿态),硬件采用 7 自由度 Franka 机械臂 + 杆状末端执行器,实验设计覆盖 “模拟性能”“虚实迁移”“鲁棒性”“模块有效性” 四大维度:

核心性能:数据效率与泛化能力双突破
-
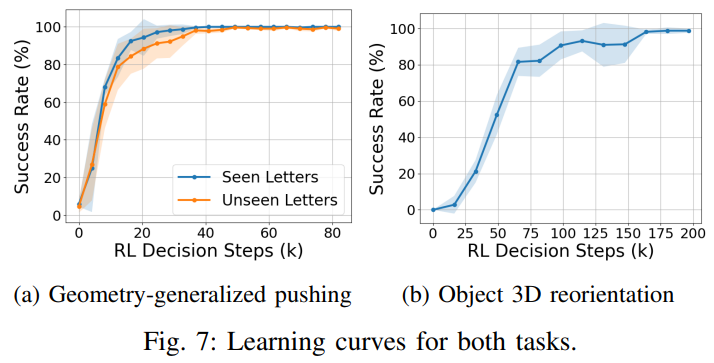
跨几何泛化能力强:推箱任务中,未见过的字母(F、I、K、V、Y、Z)成功率达 97.34%,与见过字母(E、H、L、N、T、X)的 100% 成功率接近,证明策略能适配未知物体形状;
-
数据效率碾压端到端:几何泛化推箱任务中,框架仅需 15K RL 决策步(约 300K 控制步)就能达到 100% 成功率(见过物体),而端到端策略需 600K RL 决策步(600K 控制步)才达到 92.5% 成功率,数据效率提升 40 倍;3D 重定向任务中,框架在 200K RL 决策步后成功率达 98.75%,远超 HACMan-style 分层 RL 策略;


-
任务执行效率高:模拟环境中,推箱任务平均完成步数仅 9-11 步,3D 重定向任务约 14 步,均满足实际应用需求。

鲁棒性:无惧扰动与环境变化
面对三类典型扰动,框架表现出极强的稳定性,而端到端策略在执行器变异下性能崩溃:

虚实迁移:零样本部署,性能稳定
模拟训练的策略直接部署到真实机器人,无需任何微调,表现如下:
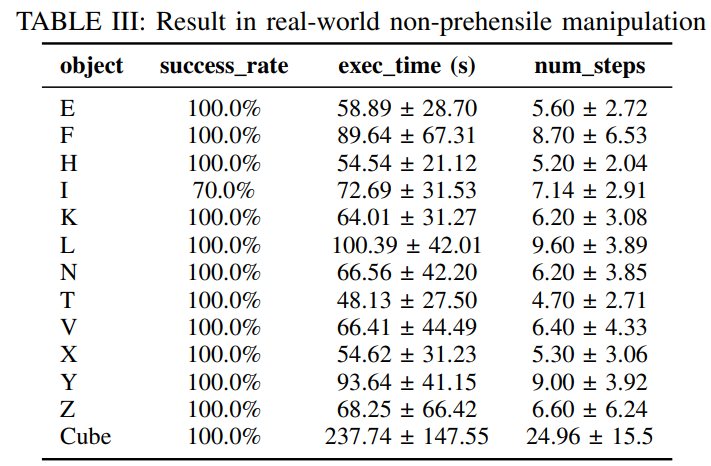
-
几何泛化推箱:12 个字母中 11 个达成 100% 成功率,仅字母 “I” 因细长形状导致姿态跟踪误差,成功率 70%; -
物体 3D 重定向:25 次独立试验全部成功,成功率 100%; -
接触策略多样化:真实场景中涌现出三类有效接触模式——顶面滑动(微调姿态)、边缘支点(大幅旋转)、角点支点(复杂姿态调整),证明策略能根据物体状态动态适配。
消融实验:关键模块的 “不可替代性”
通过禁用核心模块,验证各设计的必要性:

-
移除子目标预测(仅预测接触位置):推箱任务成功率从 100% 降至 26.56%,因 MPC 需同时优化位置与姿态,长时域操作效率骤降; -
观测坐标系不一致(目标流改用世界坐标系):学习完全失效,成功率接近 0,证明物体中心表示是几何推理的基础; -
移除碰撞组件:3D 重定向成功率从 98.75% 降至 85.94%,策略频繁选择被环境阻挡的无效接触位置,导致操作失败。
结论与展望:灵巧操作的未来方向
核心价值与创新启示
分层 RL-MPC 框架的成功,本质是对 “灵巧操作本质” 的深刻洞察与工程化实现,其核心价值体现在三点:
分层推理重构操作逻辑:通过 “接触意图” 接口解耦几何-运动学与接触动力学推理,让 RL 的 “决策灵活性” 与 MPC 的 “执行稳定性” 完美结合,解决了传统方案 “要么学不透、要么不鲁棒” 的矛盾;
物体中心表示赋能泛化:统一的观测设计(几何 + 目标 + 碰撞)与双分支架构,让策略摆脱对特定物体形状的依赖,实现跨未知几何的高效泛化,为 “通用灵巧操作” 提供了可行路径;
虚实迁移壁垒被打破:低层 MPC 的高频重规划与显式物理建模,降低了对模拟精度的依赖——高层 RL 仅学习与几何、运动学相关的决策,无需关注难以建模的接触动力学细节,从而实现零样本虚实迁移。

现存局限与未来探索
当前框架仍有两处关键局限,也是未来的核心研究方向:
依赖精准姿态估计:框架的观测与 MPC 优化均需准确的物体姿态信息,真实场景中姿态跟踪误差(如字母 “I” 的细长形状)会导致操作失败。未来需探索 “感知-规划-控制” 一体化设计,减少对精准姿态估计的依赖;
多末端执行器扩展性不足:离散关键点集合导致接触位置选择的组合复杂度随末端执行器数量(n)指数增长,难以适配多指灵巧手(如n=4或n=5)。未来需优化接触意图表示,采用连续空间建模或注意力机制筛选接触点;
模态扩展与效率优化:当前仅利用视觉与几何信息,未来可融合触觉、力反馈等模态,提升复杂场景(如柔性物体操作)的适应性;同时,可通过模型轻量化、量化等方式优化框架效率,适配边缘计算场景。
总结
分层 RL-MPC 框架的创新之处,在于它没有陷入 “端到端学习” 或 “传统控制” 的非此即彼,而是从人类操作逻辑中汲取灵感,通过结构化分层设计,在几何泛化推箱、3D 重定向等任务中实现了 “数据效率高、鲁棒性强、虚实迁移顺” 的综合优势。它不仅为接触密集型灵巧操作提供了全新技术方案,更验证了 “分层推理 + 结构化接口” 在机器人控制领域的巨大潜力——对于仓储分拣、家庭服务等需要应对多样物体的实际场景,这种兼顾通用性与实用性的框架,为机器人灵巧操作技术的规模化应用奠定了重要基础。










