智东西2月11日报道,今日,科大讯飞基于全国产算力训练的星火X2大模型正式发布。
星火X2通用能力实现提升,在其公布的数学、推理、语言理解、智能体等能力测评上可以媲美GPT-5.2、Gemini-3-Pro等模型。星火X1.5于2025年11月6日发布,仅三个月后星火系列新旗舰模型就上线了。
科大讯飞官方公众号显示,星火X2通过量化单台昇腾服务器即可运行,其采用293B MoE稀疏架构,结合权重量化、低精度KVCache、VTP(Virtual Tensor Parallel)、分层通信等多种工程化创新,实现了国产大EP并行部署,推理性能相比X1.5提升50%。
智东西实测了一波星火X2发现,新模型在回答数学、推理难题时,拆解问题、规划步骤的思路清晰。
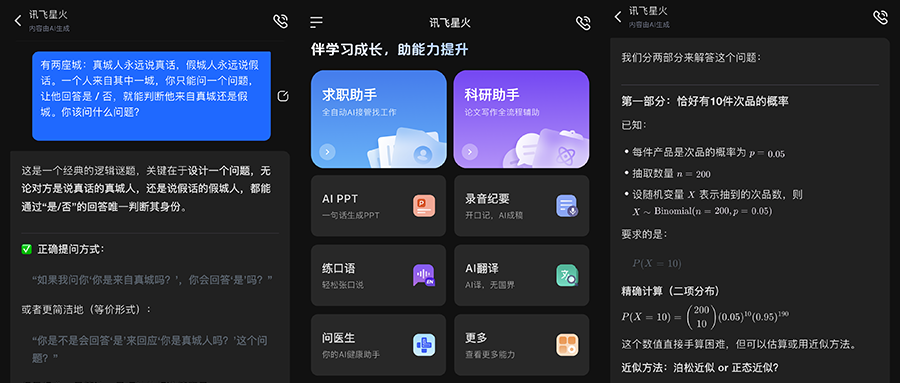
首先,智东西上传了一道设计概率难题,提示词为“某工厂生产的产品次品率为5%,随机抽取200件产品进行检验。求恰好有10件次品的概率,若要保证95%的把握认为次品率不超过5%,至少需要抽取多少件产品?”
星火X2先拆解了一共有几个问题以及要选择哪一种方式求解,最后给出了恰好有10件次品的概率为12.8%,至少需要抽取59件产品,才能有95%的把握认为次品率不超过5%。

然后,智东西上传了一道推理难题,提示词为“有两座城:真城人永远说真话,假城人永远说假话。一个人来自其中一城,你只能问一个问题,让他回答是 / 否,就能判断他来自真城还是假城。你该问什么问题?”
星火X2在回答时分析了问题可以利用的条件,并列出了几种可能的情况,然后一步步找到最清晰、简洁的问法。

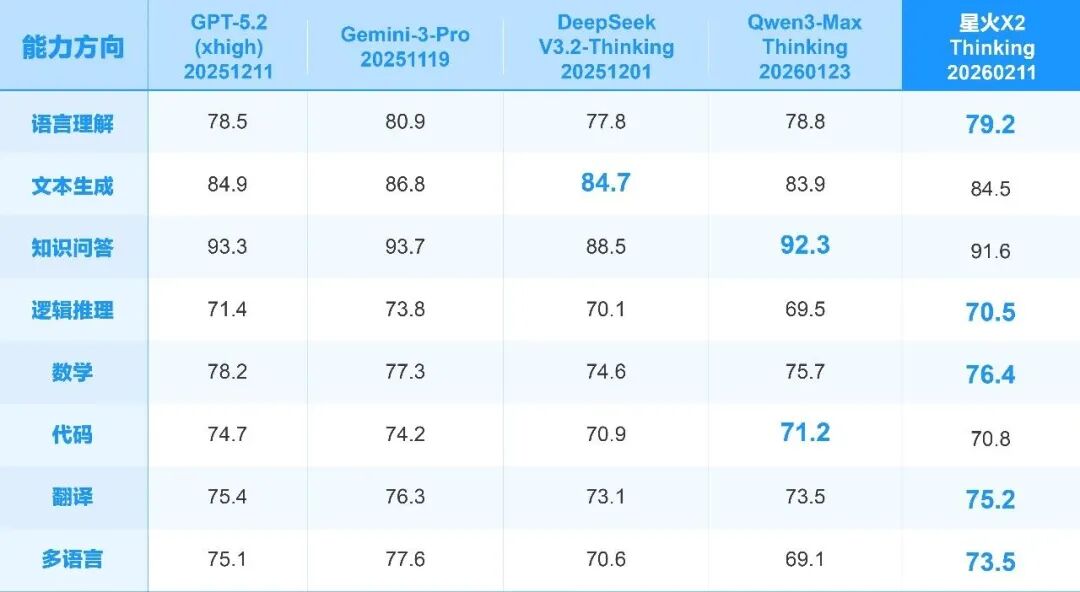
在讯飞公布的多项基准测试成绩中,星火X2在语言理解、逻辑推理、数学、翻译、多语言等方面,均超过了DeepSeek V3.2和Qwen3 Max,且与GPT-5.2和Gemini 3 Pro相比得分差距较小。
外部公开高难任务效果对比上,星火X2在数学领域整体表现较好,仅次于GPT-5.2,在综合知识和复杂问答上,星火X2与GPT-5.2、Gemini-3-Pro、Qwen3-Max差距不大。星火X2的代码和推理能比,相比GPT-5.2、Gemini-3-Pro有一定差距。

面向垂直领域,星火行业大模型在教育、医疗、司法、汽车交互、企业智能体应用等场景的效果也实现了升级。
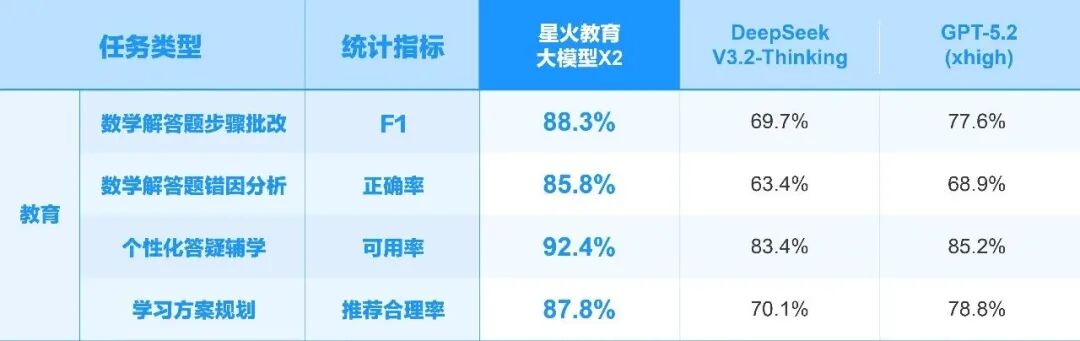
在医疗领域,星火医疗大模型X2在智能健康分析、智能报告解读、运动饮食建议、辅助诊疗、智能用药审核等关键任务上,表现均超越DeepSeek V3.2、GPT-5.2和Qwen3-Max。

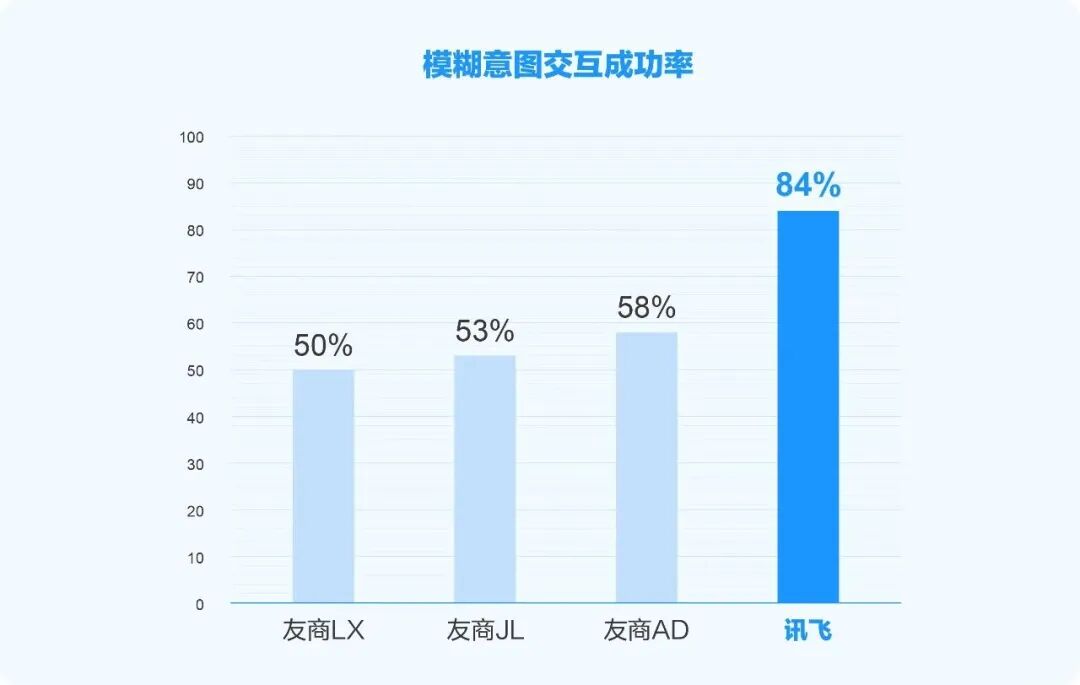
在此基础上,讯飞晓医App在多轮主动问诊、多轮咨询问答、问用药、检查检验单解读、体检报告单解读等健康咨询任务上的表现升级,解答率均超过80%。
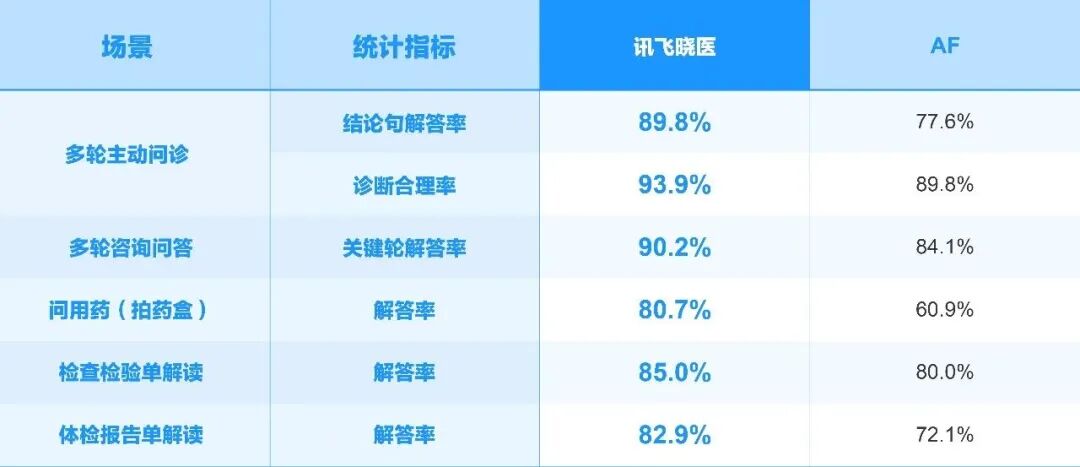
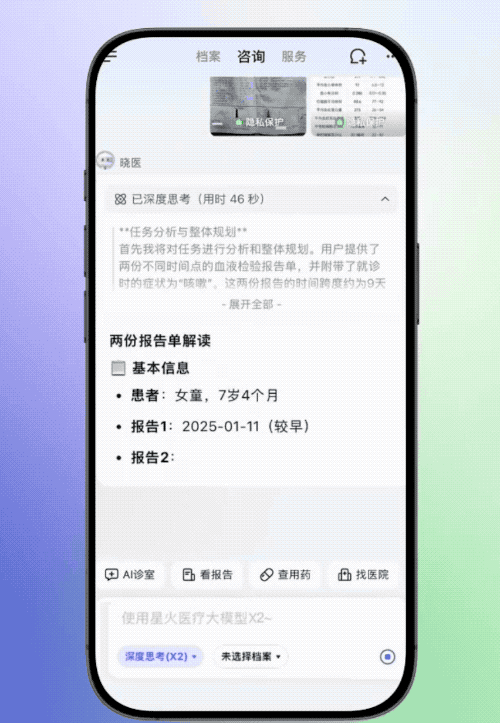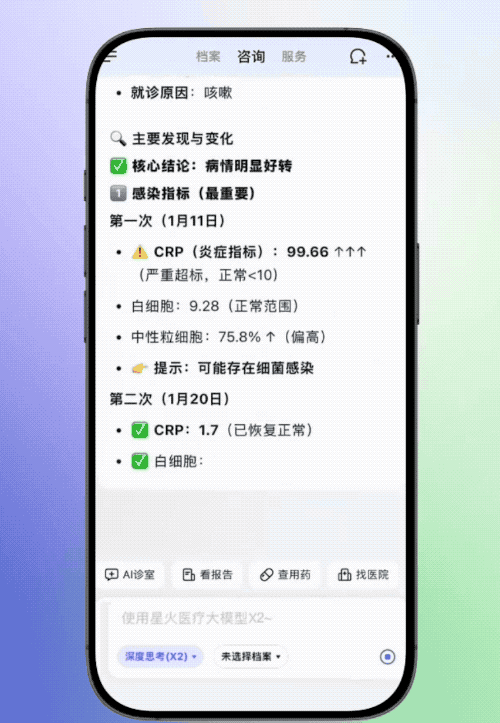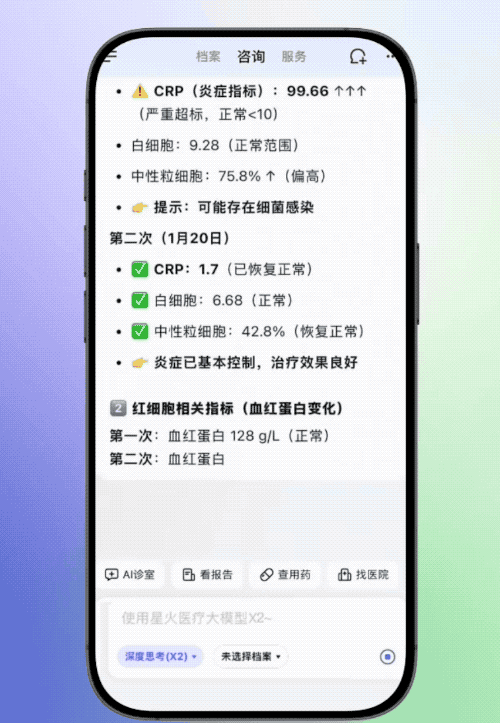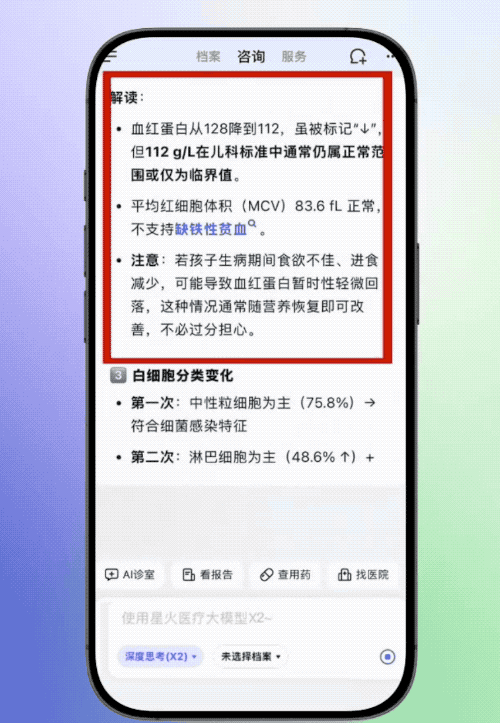
科大讯飞官方放出了讯飞晓医解读检验单的案例,其上传了两份患儿不同时期的血常规结果,讯飞晓医会进行联合解读,动态分析关键指标的变化趋势,结合患儿年龄对检验报告中的不正常数据进行解读。
星火X2的升级得益于其背后的四项工程级技术:
训推采样校准强化学习算法:针对MoE大模型RL训练中的训推分布不一致问题,提出训练与推理概率重采样自适应校准算法,提升强化学习训练准确率和稳定性。
递归式高难数据合成方法:针对高难任务数据稀缺问题,设计多轮迭代式推导的数据合成方案,实现推理错误逐步纠正与收敛,持续构建稀缺型高质量数据,提升模型深度推理准确率。
多阶段RL高吞吐采样方法:设计P/D(Prefill/Decoder)两阶段分离的多阶段推理采样方案,解决国产化平台强化学习高吞吐采样情况下的效率干扰问题,训练效率提升10%。
服务高性能部署优化算法:通过模型轻量化压缩,完成国产机器的单机大EP并行部署,推理性能相比星火X1.5提升50%。